






论文阅读与源码解析:MixMAE: Mixed and Masked Autoencoder for Efficient Pretraining of Hierarchical Vision Transformers
论文地址:https://arxiv.org/pdf/2205.13137
GitHub项目地址:https://github.com/Sense-X/MixMIM
motivation
现有的MIM方法将一部分输入标记替换为特殊的[MASK]符号,旨在恢复原始图像补丁。
但是,使用[MASK] 符号会导致两个问题:
- 预训练中使用的 [MASK] 符号从未出现在微调阶段,导致预训练微调不一致。2. 预训练网络在处理信息量较少的 [MASK] 符号时浪费了大量的计算,使得预训练过程效率低下。当使用较大的掩蔽率时,需要会导致训练的轮次要很多。例如,在 SimMIM [51] 中,在预训练期间使用了 60% 的掩蔽率,即 60% 的输入标记被替换为 [MASK] 符号。因此,SimMIM 需要相对更多的 epoch(即 800 个)进行预训练。
method
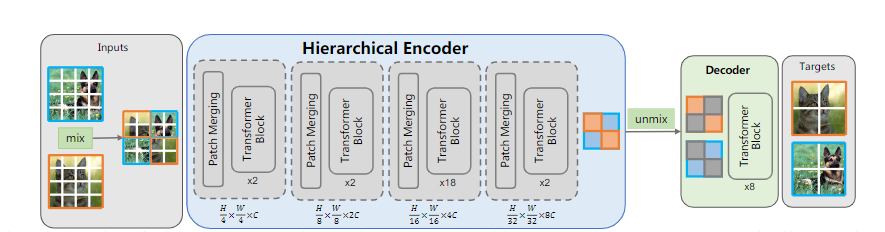
这篇论文采用的方法是
- 将一张图像分成一个个patch,然后将两张图像进行不同位置进行混合
- 将混合的图片输入到Swin Transformer中提取特征
- 利用mask位置将混合图片中属于同一张图片对应位置的特征分离出来,剩余的位置加上可学习的参数mask tokens
- 输入到标准的ViT中让mask tokens去提取的特征中查询,恢复被屏蔽掉的部分
源码解读
预训练代码在models_mixmim.py文件中
整体流程我们可以查看MixMIM中的forward函数
def forward(self, x, mask_ratio=0.5):
# 由于Swin Transformer在不同的stage会进行下采样,也就是patch merging
# 所以生成四个不同大小的mask,这四个mask掩蔽的位置是相同的,只是(h,w)不同
# 以便于在不同阶段筛选出属于同一张图片的特征
mask_s1, mask_s2, mask_s3, mask_s4 = self.random_masking(x, mask_ratio)
# 将mixed图片输入到Swin Transformer里面进行提取特征
z = self.forward_encoder(x, mask_s1, mask_s2, mask_s3, mask_s4)
# 将提取的特征unmix,加入mask tokens输入到Transfomer里面恢复图像
x_rec = self.forward_decoder(z, mask_s4)
# 计算恢复的图像与原始图像的Loss
loss = self.forward_loss(x, x_rec, mask_s4)
return loss, x_rec, mask_s4

这个就是我将生成的四个mask显示出来的效果图,可以看出他们只是图片大小不同,被掩蔽掉的位置是相同的
关键代码
# 在forward_encoder中
x = x * (1. - mask_s1) + x.flip(0) * mask_s1
作者通过将x乘以互补的mask从而将x分成两部分,然后对其中一部分的第一维度进行flip操作,就是将一个batch里面的图片从顺序排列变成了逆序排列,将两部分加起来,也就实现了mix操作。
# 在forward_decoder中
mask_tokens = self.mask_token.expand(B, L, -1)
x1 = x * (1 - mask) + mask_tokens * mask
x2 = x * mask + mask_tokens * (1 - mask)
x = torch.cat([x1, x2], dim=0)
将mask_tokens扩大跟x相同的维度,然后将mix的图片分离出来,在空白的地方加入mask_tokens,再把两个tensor进行拼接操作,相当于输入encoder里面的batch_size为4,在decoder里面的batch_size就为8了,这也是这篇论文收敛速度快的原因之一,因为实际上一张图片是被完整的输入的encoder中的,只是一部分在这个batch里面,另外一部分在另一个batch里面,被分开了而已。
# 在forward_loss中
x1_rec = x_rec[:B//2]
x2_rec = x_rec[B//2:]
unmix_x_rec = x1_rec * mask + x2_rec.flip(0) * (1 - mask)
loss_rec = (unmix_x_rec - target) ** 2
loss_rec = loss_rec.mean()
首先将8个batch分成两部分,然后将mask_tokens生成的特征合并成一张完整的图片,再与原始图片计算损失。















 3489
3489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









