






论文阅读与源码解析:Masked Generative Distillation
论文地址:https://arxiv.org/pdf/2205.01529
GitHub项目地址:https://github.com/yzd-v/MGD
motivation
以前的基于特征的蒸馏方法通常使学生尽可能地模仿教师的输出,因为教师的特征具有更强的表示能力。然而,我们认为没有必要直接模仿老师来提高学生特征的表征能力。用于蒸馏的特征通常通过深度网络通常是高阶语义信息。特征像素已经在一定程度上包含了相邻像素的信息。因此,如果我们可以使用部分像素通过简单的块来恢复教师的完整特征,这些使用像素的表征能力也可以得到改善。从这个角度来看,我们提出了掩蔽生成蒸馏(MGD),这是一种简单有效的基于特征的蒸馏方法。
method
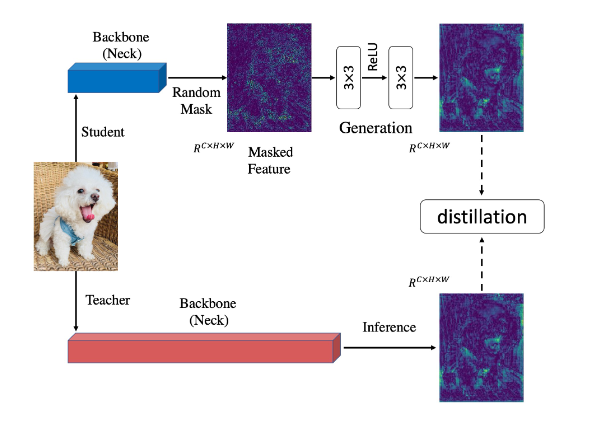
- 作者将学生生成的特征随机屏蔽掉一定的像素值,也就是把它变成0,
- 然后通过两个三乘三的卷积层,中间有一个非线性激活函数,这样就可以通过邻近的像素值来恢复原来的被屏蔽掉位置的像素值,
- 最后与教师生成的特征进行对齐。
源码解读
损失函数以det/mmdet/distillation/losses/mgd.py文件为例子进行解读
在forward函数中
def forward(self, preds_S, preds_T):
"""Forward function.
Args:
preds_S(Tensor): Bs*C*H*W, student's feature map
preds_T(Tensor): Bs*C*H*W, teacher's feature map
"""
# 首先判断学生网络和教师网络生成的特征在空间维度和通道维度是否一致
# 如果在空间维度不同就会报错
assert preds_S.shape[-2:] == preds_T.shape[-2:]
# 通道维度不同的话,就会让学生特征通过一个一乘以卷积来与教师网络的通道对齐
if self.align is not None:
preds_S = self.align(preds_S)
# 计算作者定义的MGD损失
loss = self.get_dis_loss(preds_S, preds_T)*self.alpha_mgd
return loss
接下来我们重点看作者定义的损失函数是怎么计算的
def get_dis_loss(self, preds_S, preds_T):
# 定义损失函数为均方误差损失,计算方式是把所有对应的位置求和
loss_mse = nn.MSELoss(reduction='sum')
N, C, H, W = preds_T.shape
device = preds_S.device
# 生成一个tensor,里面值在0到1之间
mat = torch.rand((N,1,H,W)).to(device)
# 如果mat里面的值大于作者定义的数,那么就为0,否则为1
# 这个相当于在空间维度生成了一个只有0或者1的tensor,并且0的比率是可以作者指定的
mat = torch.where(mat>1-self.lambda_mgd, 0, 1).to(device)
# 将生成的mask tensor与学生特征对应位置相乘,相当于在学生特征空间位置中随机屏蔽掉一些特征值
masked_fea = torch.mul(preds_S, mat)
# 将屏蔽的特征通过卷积层从邻近位置未被屏蔽掉的特征来生成屏蔽掉的特征
new_fea = self.generation(masked_fea)
# 计算生成的学生特征与教师特征的均方误差损失
dis_loss = loss_mse(new_fea, preds_T)/N
return dis_loss















 652
652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









