









作者:老余捞鱼
原创不易,转载请标明出处及原作者。

写在前面的话:Python中的Statsmodels可以极大地简化时间序列分析的过程,这个智能库不仅能处理ARIMA、SARIMA、LSTM等复杂模型,还能轻松进行数据可视化。在这篇文章中,我将分享如何快速上手这一强大的工具,并通过实际案例展示其在数据分析中的应用。无论是初学者还是有经验的量化老手,都能从本文中获得宝贵的知识,提升自己的数据分析能力。
一、什么是 Statsmodels ?
Statsmodels 是一个用于统计建模和经济学的 Python 智能库。它提供了丰富的功能,允许用户进行数据分析、估计统计模型、进行假设检验以及生成各种统计图表。
Statsmodels 特别适合于处理线性回归、时间序列分析、广义线性模型等多种统计方法。同时它支持单变量和多变量的时间序列建模。它内置了很多统计检验方法,可以用来评估模型的假设和性能。
该库的设计旨在为用户提供一个简单易用的接口,同时保持强大的功能和灵活性。而如果你想用 ARIMA 或 SARIMA 模型,它绝对是首选。它还能与 pandas 和 numpy 无缝配合使用。
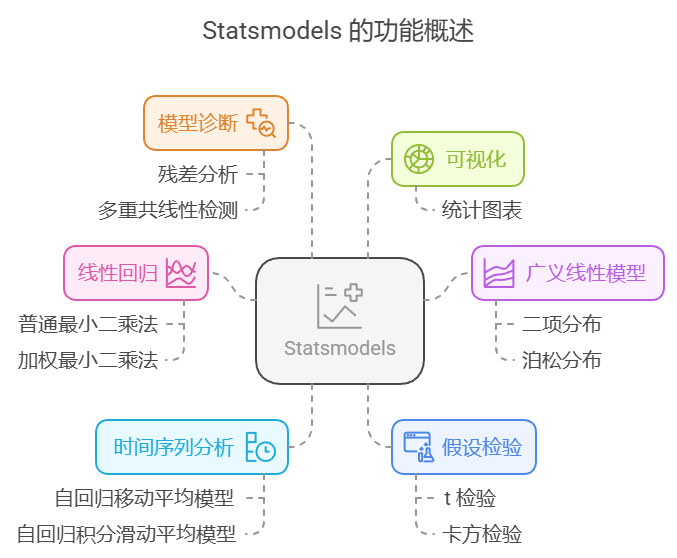
- 线性回归:Statsmodels 提供了多种线性回归模型的实现,包括普通最小二乘法(OLS)和加权最小二乘法(WLS)。
- 广义线性模型:支持多种分布的广义线性模型(GLM),如二项分布、泊松分布等。
- 时间序列分析:提供了对时间序列数据的分析工具,包括自回归移动平均模型(ARMA)、自回归积分滑动平均模型(ARIMA)等。
- 假设检验:Statsmodels 提供了多种统计检验方法,如 t 检验、卡方检验等,帮助用户验证模型的有效性。
- 模型诊断:提供了多种工具用于模型的诊断和评估,包括残差分析和多重共线性检测。
- 可视化:支持生成各种统计图表,帮助用户更好地理解数据和模型。
二、基于 Statsmodels 代码示例
下面这段代码将展示如何使用Python进行时间序列分析、建模和预测。代码涵盖了从数据生成、可视化、分解、平稳性检验、自相关分析、ARIMA模型拟合到LSTM神经网络模型的构建和评估。
2.1 源代码下载
完整源代码请在我的Google Colab中直接使用和下载:
https://colab.research.google.com/drive/1AVOotPzd1zKul4GsDHeJuBWheYPXQpGT?usp=sharing
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.api import SimpleExpSmoothing, Holt, ExponentialSmoothing
from statsmodels.tsa.stattools import adfuller, acf, pacf
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.seasonal import seasonal_decompose
"""
Generate or Load Time Series Data
Simulate a time series with trend and seasonality
"""
"""
Time Series Decomposition
Use seasonal_decompose to split the series into trend, seasonal, and residual components.
"""
"""
Check for Stationarity
Use the Augmented Dickey-Fuller (ADF) test to assess stationarity.
"""
"""
Autocorrelation and Partial Autocorrelation
Visualize the ACF and PACF to determine lag dependencies.
"""
"""
Fit an ARIMA Model
Fit an ARIMA model to the data for forecasting.
"""
"""
Tensorflow (Keras) using an LSTM model
"""
# Prepare Data for LSTM
scaler = MinMaxScaler()
df["value"] = scaler.fit_transform(df["value"].values.reshape(-1, 1))
# Plot the Results
plt.figure(figsize=(12, 8))
plt.plot(df.index, scaler.inverse_transform(df["value"].values.reshape(-1, 1)), label="Actual Data", color="Blue")
train_index = df.index[lag:train_size + lag]
plt.plot(train_index, train_predictions_inverse, label="Training Predictions", color="Orange")
test_index = df.index[train_size + lag:]
plt.plot(test_index, y_test_inverse, label="Hold-Out (True Values)", color="Green")
plt.plot(test_index, y_pred_lstm_inverse, label="Testing Predictions", color="Red")
plt.title(f'LSTM Forecast. MAPE: {mape:.3%}')
plt.xlabel("Date")
plt.ylabel("Value")
plt.legend()
plt.grid()
plt.savefig("LSTM_forecast_with_holdout.png")
plt.show()2.2 代码详析
以下是代码的详细分析和总结:
1. 数据生成与可视化
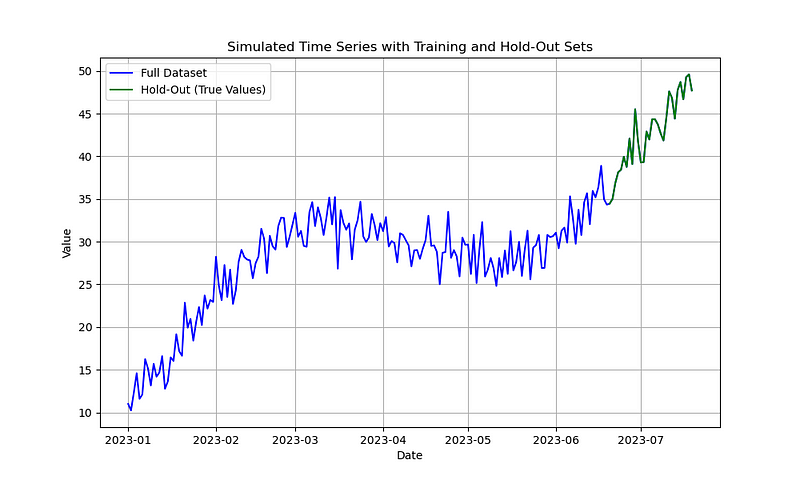
- 数据生成:代码首先生成了一个模拟的时间序列数据,包含趋势、季节性和噪声成分。趋势是线性的,季节性是通过正弦函数生成的,噪声则是正态分布的随机数。
- 数据分割:数据被分为训练集和测试集(hold-out集),测试集包含最后30天的数据。
- 可视化:使用
matplotlib绘制了完整的时间序列数据,并用不同颜色区分训练集和测试集。
总结:这部分代码展示了如何生成模拟的时间序列数据,并通过可视化手段直观地展示数据的趋势和季节性。
2. 时间序列分解
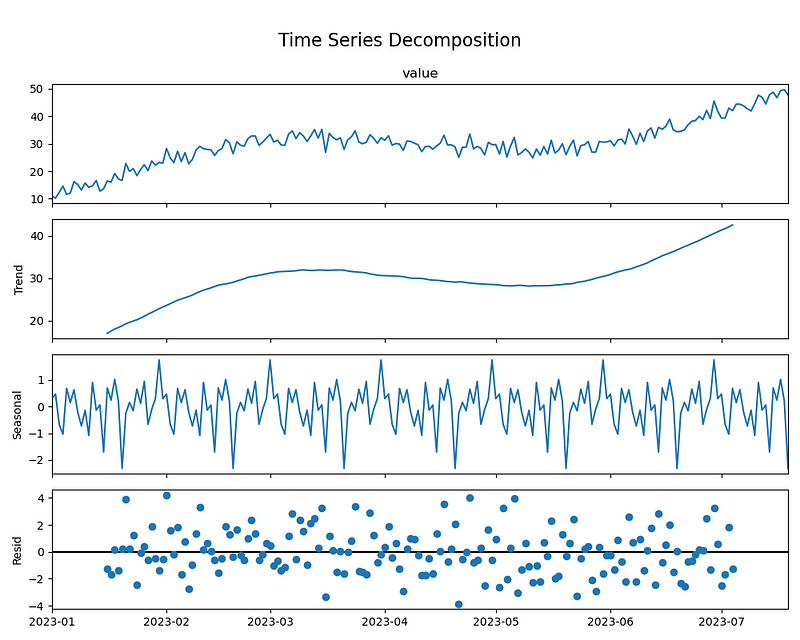
- 分解:使用
seasonal_decompose函数将时间序列分解为趋势、季节性和残差成分。分解模型选择的是加法模型(model="additive"),周期为30天。 - 可视化:绘制了分解后的各个成分(趋势、季节性、残差)。
总结:时间序列分解有助于理解数据的结构,特别是趋势和季节性成分。这对于后续的建模和预测非常重要。
3. 平稳性检验
- ADF检验:使用Augmented Dickey-Fuller (ADF) 检验来检查时间序列的平稳性。ADF检验的零假设是时间序列是非平稳的。
- 结果解释:根据ADF检验的p值判断时间序列是否平稳。如果p值大于0.05,则认为时间序列是非平稳的。
总结:平稳性是许多时间序列模型(如ARIMA)的前提条件。ADF检验帮助确定是否需要差分或其他转换来使序列平稳。
4. 自相关和偏自相关分析
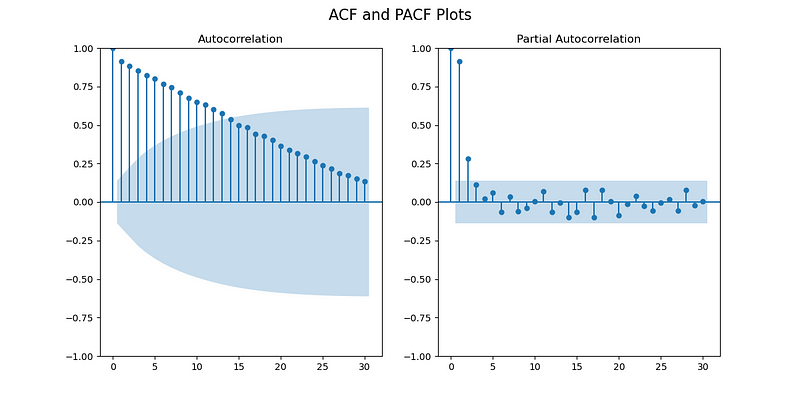
- ACF和PACF图:绘制了自相关函数(ACF)和偏自相关函数(PACF)图,用于分析时间序列的自相关结构。
- 滞后选择:ACF和PACF图可以帮助确定ARIMA模型中的滞后阶数(p和q)。
总结:ACF和PACF图是选择ARIMA模型参数的重要工具,能够帮助识别时间序列中的自相关和偏自相关模式。
5. ARIMA模型拟合
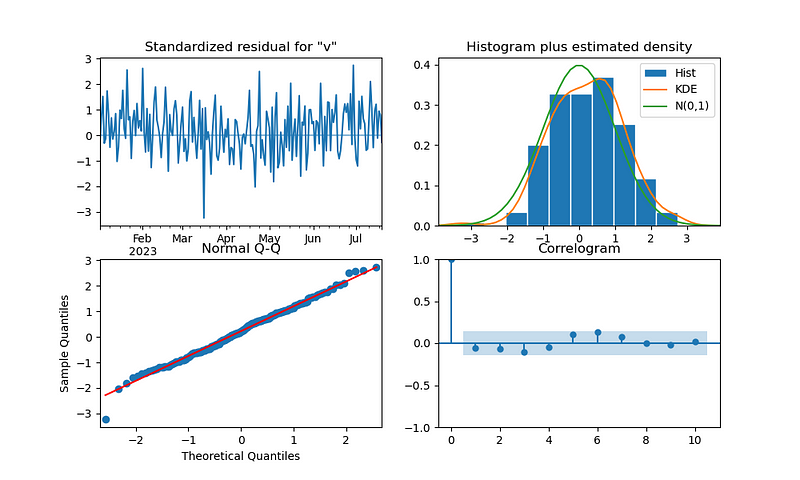
- 模型拟合:使用ARIMA(2,1,2)模型拟合时间序列数据。ARIMA模型的参数为(p=2, d=1, q=2),其中d=1表示对数据进行一阶差分。
- 模型诊断:绘制了残差图,包括残差分布、QQ图、自相关图等,用于评估模型的拟合效果。
总结:ARIMA模型是经典的时间序列预测模型,适用于线性时间序列数据。模型诊断图可以帮助评估模型的残差是否符合白噪声假设。
6. LSTM神经网络模型
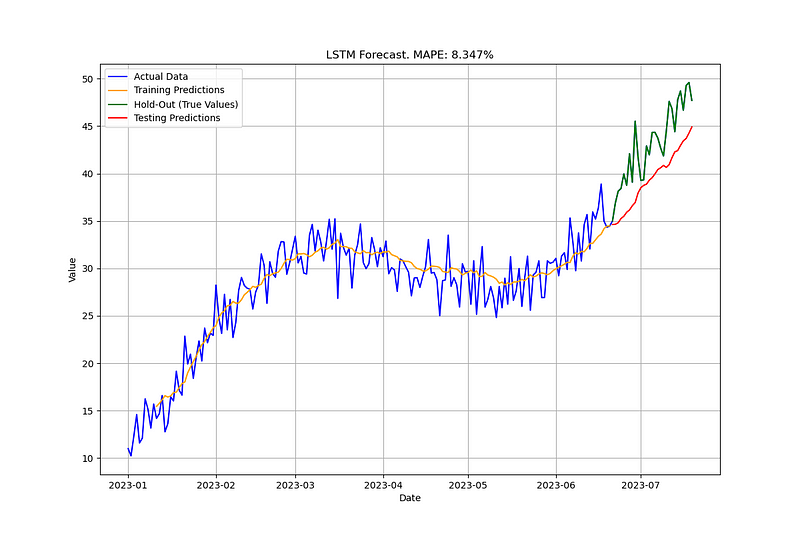
- 数据预处理:使用
MinMaxScaler对数据进行归一化处理,并将数据转换为适合LSTM模型的格式(即带有时间滞后的特征)。 - 模型构建:构建了一个简单的LSTM模型,包含一个LSTM层和一个全连接层。
- 模型训练与预测:模型在训练集上进行训练,并在测试集上进行预测。使用均方误差(MSE)作为损失函数,Adam优化器进行优化。
- 模型评估:计算了测试集上的平均绝对百分比误差(MAPE),并绘制了实际值与预测值的对比图。
总结:LSTM是一种适用于时间序列预测的深度学习模型,特别适合处理非线性时间序列数据。通过LSTM模型,可以捕捉到时间序列中的复杂模式,但需要更多的数据和计算资源。
2.3 代码总结
这段代码展示了从数据生成到模型预测的完整时间序列分析流程,涵盖了传统统计模型(ARIMA)和现代深度学习模型(LSTM)。我尽量让代码结构清晰,适合初学者学习和参考。
- 数据生成与可视化:代码展示了如何生成模拟的时间序列数据,并通过可视化手段展示数据的趋势和季节性。
- 时间序列分解:通过分解时间序列,可以更好地理解数据的结构。
- 平稳性检验:ADF检验帮助确定时间序列是否平稳,这对于选择合适的模型非常重要。
- 自相关分析:ACF和PACF图帮助确定ARIMA模型的参数。
- ARIMA模型:ARIMA模型适用于线性时间序列数据,模型诊断图帮助评估模型的拟合效果。
- LSTM模型:LSTM模型适用于非线性时间序列数据,能够捕捉复杂的模式,但需要更多的数据和计算资源。
三、应用于股票的分析工具
上面这段代码我进行改造并应用到特斯拉(Tesla)股票分析上,并根据股票数据的特点进行一些调整和优化。
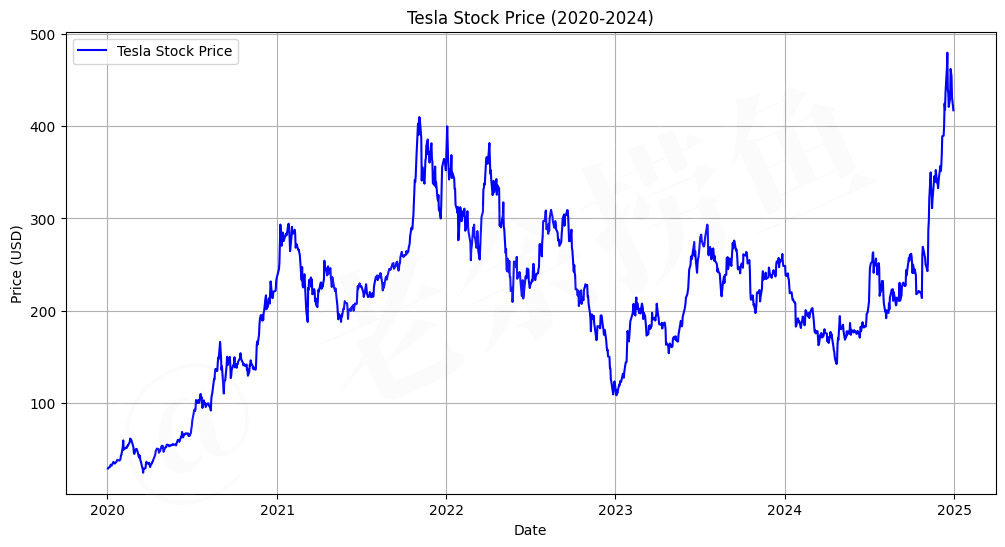
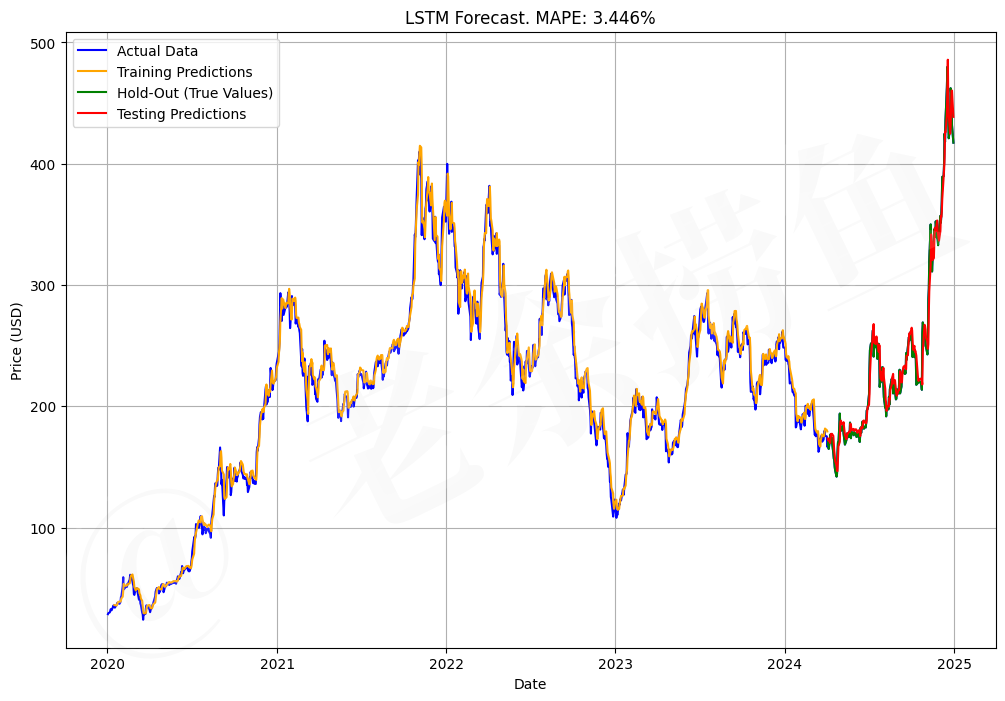
3.1 代码说明
- 数据获取:使用
yfinance下载特斯拉股票数据。 - 数据预处理:处理缺失值、对数转换和差分。
- 可视化:绘制股票价格、时间序列分解图、ACF和PACF图。
- 平稳性检验:使用ADF检验检查数据是否平稳。
- ARIMA模型:拟合ARIMA模型并输出诊断图。
- LSTM模型:构建、训练和评估LSTM模型,并可视化预测结果。
3.2 注意事项
这段代码可以应用于特斯拉股票分析,但需要根据股票数据的特点进行调整。ARIMA模型适合捕捉线性趋势,而LSTM模型适合捕捉非线性模式。通过结合两种模型,可以更好地预测股票价格。不过,需要注意的是,股票市场具有高度随机性,模型的预测结果仅供参考,实际投资决策需谨慎。
- 股票市场的随机性:股票价格受多种因素影响(如新闻、政策、市场情绪等),传统时间序列模型可能难以捕捉这些非线性关系。
- 模型选择:ARIMA适合线性关系,而LSTM适合非线性关系。可以尝试结合两种模型的优点。
- 特征工程:除了收盘价,还可以加入其他特征(如成交量、技术指标等)来提高模型性能。
- 过拟合问题:LSTM模型容易过拟合,尤其是在数据量较少时。可以通过正则化、Dropout等方法缓解。如果数据量较大,LSTM模型的训练时间可能较长。
3.3 工具下载
股票分析工具请在我的Google Colab中申请使用和下载:
https://colab.research.google.com/drive/19GZKiNyPSHwFSWNIYsWVlsMm7Gf7lTut?usp=sharing
四、观点总结
本文介绍了如何使用 Python 中的 statsmodels 库进行时间序列分析,并通过模拟数据和实际案例展示了时间序列分解、检验平稳性、自相关与部分自相关分析、ARIMA 模型和 LSTM 模型的应用。
statsmodels是一套强大的统计建模工具,对时间序列分析提供了丰富的支持。- 时间序列分解有助于理解数据中的趋势、季节性和残差成分。
- 平稳性检验是时间序列分析的关键步骤,可以通过 ADF 检验来进行。
- ARIMA 模型是时间序列预测的常用方法,但在某些情况下可能需要通过调整模型参数或使用其他模型来提高预测准确性。
- LSTM 模型在处理复杂的时间序列数据时,通常能提供与传统统计方法相比更好的预测结果。
- 实际案例表明,不同的时间序列模型适用于不同的数据特性,选择合适的模型对于获得准确预测至关重要。
感谢您阅读到最后,希望这篇文章为您带来了新的启发和实用的知识!如果觉得有帮助,请不吝点赞和分享,您的支持是我持续创作的动力。祝您投资顺利,收益长虹!如果对文中内容有任何疑问,欢迎留言,我会尽快回复!
本文内容仅限技术探讨和学习,不构成任何投资建议。



















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











