






本文本内容来自以上项目,根据对上文的理解写出自己的见解和疑惑,热衷于AI大模型,但对这方面的应用和底层了解较少,一起努力学习。
1 何为Embedding
对于自然语言,因为它的输入是一段文本,在中文里就是一个一个字,或一个一个词,行业内把这个字或词叫Token。如果要使用模型,拿到一段文本的第一件事就是把它Token化。比如可以根据自己的不同喜好或者不同的使用目的划分成不同的字词。
根据下边的文本,我们可以按照不同的划分形式划分成不同的结构。
给定文本:我们相信AI可以让世界变得更美好。
按字Token化:我/们/相/信/A/I/可/以/让/世/界/变/得/更/美/好/。
按词Token化:我们/相信/AI/可以/让/世界/变得/更/美好/。
按Bi-Gram Token化:我们/们相/相信/信A/AI/I可/可以/以让/让世/世界/界变/变得/得更/更美/美好/好。
那自然就有一个新的问题:我们应该怎么选择Token化方式?其实每种不同的方法都有自己的优点和不足,在大模型之前,按词的方式比较常见。但在有了大模型之后,基本都是按字来了,不用再纠结这个点了。
Token化后,第二件事就是要怎么表示这些Token,我们知道计算机只能处理数字,所以要想办法把这些Token给变成计算机「认识」的数字才行。读者不妨思考一下如果要你来做这件事会怎么做。
Token化后,第二件事就是要怎么表示这些Token,我们知道计算机只能处理数字,所以要想办法把这些Token给变成计算机「认识」的数字才行。读者不妨思考一下如果要你来做这件事会怎么做。
其实很简单很直观,把所有字作为一个字典,序号就代表它自己。我们还是以上面的句子为例,假设词表就包含上面那些字,那么词表就可以用一个txt文件存储,内容如下:
我 们 相 信 A I 可 以 让 世 界 变 得 更 美 好 。
一行一个字,每个字作为一个Token,此时,0=我,1=们,……,以此类推。拿中文来说,这个词表可能只要几千行,即使包含各种特殊符号、生僻字,也就2万个多点,我们假设词表大小为N。
接下来我们考虑如何用这些数字来表示一段文本。最简单的方法就是用它的ID直接串起来,这样也不是不行,但这种表示方法的特征是一维的,也就是说只能表示一个特征。这种方法不太符合实际情况,效果也不理想。所以,研究人员就想到另一种表示方法:One-Hot编码。其实,将文本变为数字表示的过程本质上就是一种编码过程。One-Hot的意思是,对每一个字都有N(词表大小)个特征,除了该字的ID位置值为1,其余都为0。我们依然用上面的例子来说明,把整个词表表示为下面的形式:
我 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
们 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
相 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0
信 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0
……下面省略
此时,对每一个Token(字),它的表示就变成了一个一维向量,比如「我」:[1,0,...0],这个向量的长度就是词表的大小N,它被称为「我」这个字的One-Hot表示。
对于一段文本,我们一般会将每个Token的表示结合起来,结合方式可以采用求和或平均。这样,对于任意长度的任意文本,我们都能将其表示为固定大小的向量,非常方便进行各种矩阵或张量(三维以上的数组)计算,这对深度学习至关重要。
举个例子,比如有这么一句话:让世界更美好。现在我们使用刚刚的方法将其表示为一个向量,采用平均的方式。
首先,列出每个字的向量:
让 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0
世 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0
界 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0
更 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0
美 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0
好 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0
。 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
然后针对每一列取平均,结果为:0 0 0 0 0 0 0 1/7 1/7 1/7 0 0 1/7 1/7 1/7 1/7。不难发现,对任两句话,只要其中包含的字不完全一样,最终得到的向量表示也不会完全一样。
根据上边对各个字的表示的话,我们可以看到每个字所表示的权重都是相同的,每个字并无不同。其实在实际应用中我们知道每个字出现的频率是不同的,有的字是常用,有的不经常用。
当然,在实际使用时,往往不会这么简单的用1/0来表示,因为每个字在句子中的作用是不一样的,所以一般会给不同的Token赋予不同的权重。最常见的方法是使用在句子中出现的频率,那些高频的(但不是「的」「更」这样的虚词)被认为是重要的。更多可以参考【相关文献1】。
这种方法不错,在深度学习之前很长一段时间里都是这样的,不过它有两个很大的问题:
- 数据维度太高:太高的维度会导致向量在空间中聚集在一个非常狭窄的角落,模型难以训练。
- 数据稀疏,向量之间缺乏语义上的交互(语义鸿沟):比如「我爱吃苹果」和「我爱用苹果」,前者是水果,后者是手机,怎么判断出来的呢?根据上下文。但由于现在这种表示方式,导致上下文之间是孤立的,所以模型学不到这个知识点。还有类似「我喜欢你」和「你喜欢我」这样会得到同样的表示,但其实是不同的意思。注①
如果每句话都和以上的表达一样的话,那每一个字在表示时只有一个序号不为0,维度就会很高,所以此时为了解决以上的问题,就有了我们所说的Embedding方法。
- 把特征固定在某一个维度D,比如256、300、768等等,这个不重要,总之不再是词表那么大的数字。这就避免了维度过高的问题。
- 利用自然语言文本的上下文关系学习一个稠密表示。也就是说,每个Token的表示不再是预先算好的了,而是在过程中学习到的,元素也不再是很多个0,而是每个位置都有一个小数,这D个小数构成了一个Token表示。至于D个特征到底是什么,不知道,也不重要。我们只需要知道这D个小数就表示这个Token。
还是继续以前面的例子来说明,这时候词表的表示变成下面这样了:
固定在一个维度之后,每个字横向的长度便不再为了进行匹配转而会和句子中词的长度相同,而是在规定的维度之内
我 0.xxx0, 0.yyy0, 0.zzz0, ... D个小数
们 0.xxx1, 0.yyy1, 0.zzz1, ... D个小数
相 0.xxx2, 0.yyy2, 0.zzz2, ... D个小数
信 0.xxx3, 0.yyy3, 0.zzz3, ... D个小数
……下面省略
这些小数怎么来的?简单,随机来的。就像下面这样:
In [15]:
import numpy as np
In [16]:
rng = np.random.default_rng(42) # 词表大小N=16,维度D=256 table = rng.uniform(size=(16, 256)) table.shape
Out[16]:
(16, 256)
In [17]:
table
Out[17]:
array([[0.77395605, 0.43887844, 0.85859792, ..., 0.24783956, 0.23666236,
0.74601428],
[0.81656876, 0.10527808, 0.06655886, ..., 0.11585672, 0.07205915,
0.84199321],
[0.05556792, 0.28061144, 0.33413004, ..., 0.00925978, 0.18832197,
0.03128351],
...,
[0.50647331, 0.22303613, 0.94414565, ..., 0.79202324, 0.40169878,
0.72247782],
[0.9151384 , 0.80071297, 0.39044651, ..., 0.03994193, 0.79502741,
0.28297954],
[0.68255979, 0.64272531, 0.65262805, ..., 0.18645529, 0.21927175,
0.32320729]])
在模型训练过程中,会根据不同的上下文不断地更新这个参数,最后模型训练完后得到的这个矩阵就是Token的表示。有不同的上下文的话出现的概率就不同,所以参数会不断更新。我们完全可以把它当成一个黑盒子,输入一个X,根据标签Y不断更新参数,最终就得到一组参数,这些参数的名字就叫「模型」。
这种表示方法在深度学习早期(2013-2015年左右)比较流行,不过由于这个矩阵训练好后就固定不变了,这在有些时候就不合适。比如「你好坏」这句话在不同的情况下可能完全是不同的意思。
我们知道,句子才是语义的最小单位,因此相比Token,我们其实更加关注和需要句子的表示,我们期望可以根据不同上下文动态地获得句子表示。这中间当然经历了比较多的探索,一直到如今的大模型时代,对模型输入任意一句话,它都能给我们返回一个非常不错的表示,而且依然是固定长度的向量。
如果对这方面感兴趣,可以进一步阅读【相关文献2】和【相关文献3】。
我们总结一下,Embedding本质就是一组稠密向量,用来表示一段文本(可以是字、词、句、段等),获取到这个表示后,我们就可以进一步做一些任务。大家不妨先思考一下,当给定任意句子并获得到它的固定长度的语义表示时,我们可以干什么?我们在下一节将先介绍一下OpenAI提供的接口,以及一些后面任务可能用到的概念。
但是此时我在使用openai官方接口的话提示是已经过期,并且需要再充值才能用,所以此时我便选用了使用智谱AI的官方接口来进行调用,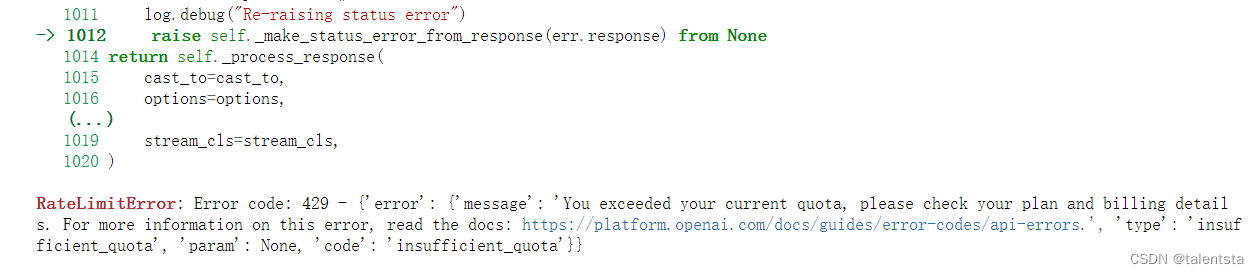

选择智谱AI调用后进入其官方平台便可很快的申请到api
# GLM
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="") # 请填写您自己的APIKey
messages = [{"role": "system", "content": "你是一个乐于解答各种问题的助手,你的任务是为用户提供专业、准确、有见地的建议。"},
{"role": "user", "content": "请你介绍一下Datawhale。"},]
response = client.chat.completions.create(
model="glm-4", # 请选择参考官方文档,填写需要调用的模型名称
messages=messages, # 将结果设置为“消息”格式
stream=True, # 流式输出
)
full_content = '' # 合并输出
for chunk in response:
full_content += chunk.choices[0].delta.content
print('回答:\n' + full_content)具体调用方式可参考以上调用方式,以下是官方给出的调用方法,智谱AI开放平台 (bigmodel.cn)
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="") # 请填写您自己的APIKey
response = client.chat.completions.create(
model="glm-4", # 填写需要调用的模型名称
messages=[
{"role": "system", "content": "你是一个乐于解答各种问题的助手,你的任务是为用户提供专业、准确、有见地的建议。"},
{"role": "user", "content": "我对太阳系的行星非常感兴趣,特别是土星。请提供关于土星的基本信息,包括其大小、组成、环系统和任何独特的天文现象。"},
],
stream=True,
)
for chunk in response:
print(chunk.choices[0].delta)以下分别是运行成功的截图,
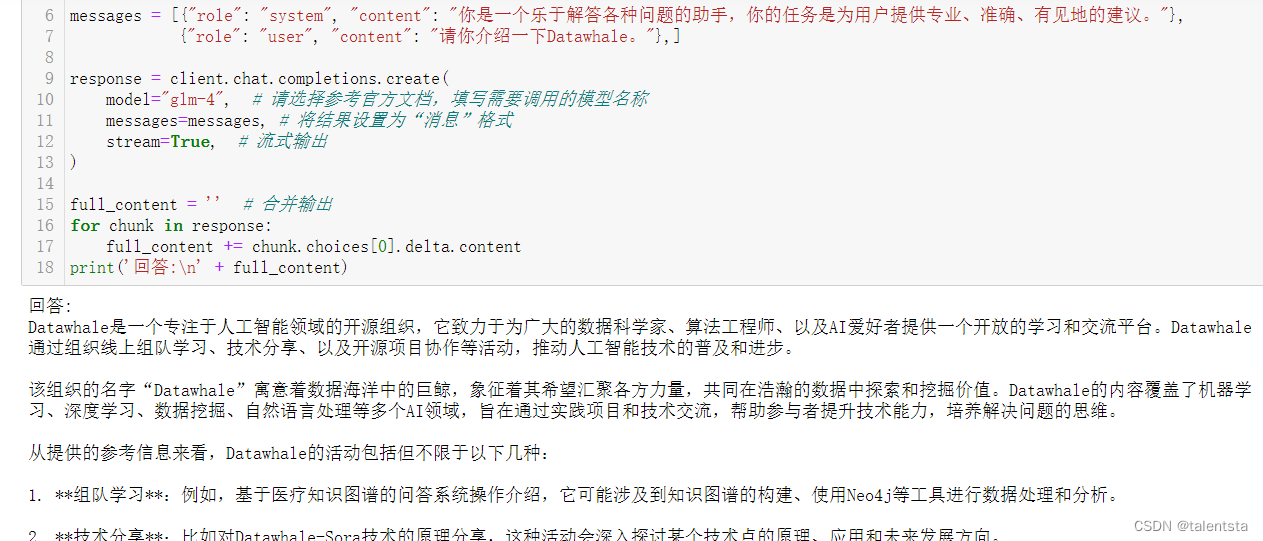
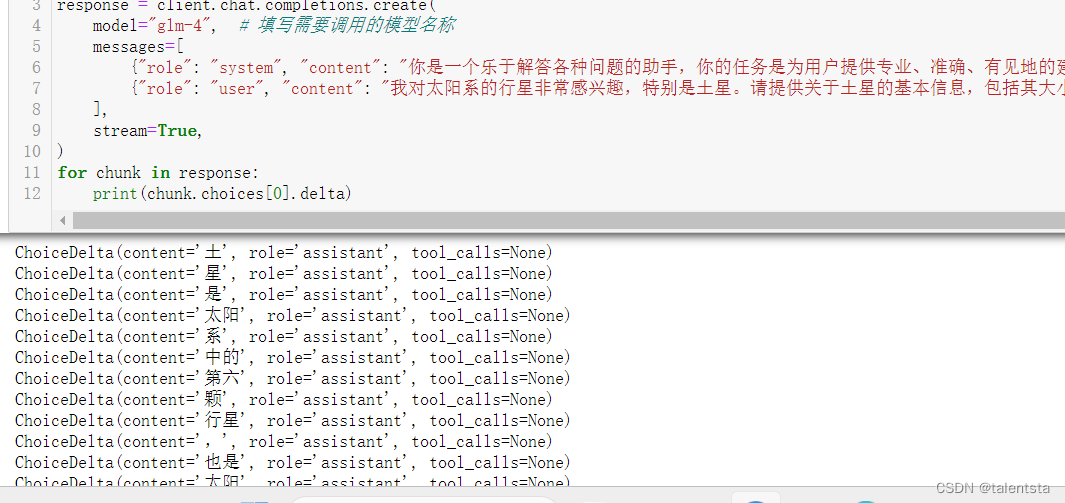















 1029
1029

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









