







最近一直想要学习深度学习的内容,想要复现大佬的代码,试了好多有的是不给数据,有的总是跑不通,这一个是已经跑通的一个代码,以上为证,学习最快的方式就是直接实战,大部分的内容都是比较偏向于理论,个人还是偏向于直接跑通代码,这部分代码相对比较容易理解,从头到尾逐行剖析它的每一行代码。
训练文件train.py
import numpy as np
import tensorflow as tf
from utils import get_data, model_LSTM
import matplotlib.pyplot as plt
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping, ReduceLROnPlateau
import os 
刚开始接触的时候对于第三行代码确实没太理解,utils.py相当于是你自己编写的一个程序包,可以把它想象成类似于机器学习中sklearn集成包那种,可以从里边调用许多自己需要的包,本文中的utils.py是由自己进行编写的符合本次项目的一个集成包,但是注意的内容是要放在同一个目录下进行调用。此时从utils.py包中调用的两个包一个是获取数据的方式,一个是自己定义的lstm模型,
此时打开utils.py文件后可以看到已经定义好的两个模型都存在。此时我们的模型的好坏是使用验证损失来衡量的,所以以下这三个参数都是以损失值来衡量的。
ModelCheckpoint: 每个epoch结束后,如果验证损失下降,就自动保存模型权重。这样可以保存训练过程中损失最小的最优模型,在模型训练过程中我们会选择让模型迭代多少次,后一次循环结束之后的损失值小于前一次时便会自动进行保存最好的模型。
EarlyStopping: 当验证损失停止下降时,自动中止训练,防止过拟合,当在一次次的训练过程中损失值一直增长反而不下降时模型便会终止训练,假如损失值没有下降再训练下去也是毫无意义。说到这里可能大家会有一个小的疑问,难道时一次增长之后便停止吗,当然不是了,这个参数也是可以自己进行设置,设置的是patiences参数耐心值,在这个范围之内损失函数没有变化的话模型便会自动停止训练,根据下边的代码可以看到本次设置的是15。
ReduceLROnPlateau: 当验证损失平台期时,自动减小学习率。这样可以帮助训练更快收敛到最优点。这里可能会有疑问既然是减少学习率的话,具体是减少多少呢,本文中的factor为0.5,那样的话是不是可以无限减少呢,当然不是了,下文中的min_lr规定了减小到最低什么程度。
checkpoint = ModelCheckpoint(filepath=checkpoint_save_path,
monitor='val_loss',
verbose=1,
save_weights_only=True,
save_best_only=True)
earlystopping = EarlyStopping(monitor='val_loss',
patience=15,
verbose=1,
mode='auto',
restore_best_weights=True)
rlrop = ReduceLROnPlateau(monitor='val_loss',
patience=5,
factor=0.5,
min_lr=1e-7,
verbose=1)verbose参数在ReduceLROnPlateau回调函数中控制打印日志的详细程度。
它有以下几个取值:
0: 不打印日志,静默模式。
1: 打印一个日志消息来表示学习率下降。
2: 打印日志并显示学习率下降的老值和新值。
save_weights_only参数在ModelCheckpoint回调函数中是这个意思:
设置为True时,只保存模型的权重参数(权重文件),不保存模型的结构信息和编译信息。设置为False时(默认值),会保存整个模型结构、编译信息以及权重等所有信息。使用save_weights_only=True的好处是:保存的文件尺寸更小,重量更轻。常用在云训练场景,可以节约存储空间。只保存权重参数就可以,加载时可使用原模型结构。便于版本控制和权重文件分享。在功能上等同于保存整个模型,但是文件更小。
缺点是:
需要确保加载权重时模型结构保持一致。不保存编译信息,加载时需要重新编译模型。所以,如果只关心模型训练结果,可以设置save_weights_only=True以节省空间。如果需要保存完整模型结构信息,可以保持默认False。一般情况下,ModelCheckpoint常用这个设置来自动收集训练过程中的最佳权重参数。
filepath参数指定ModelCheckpoint回调函数将检查点文件保存的路径。
一些关键点:
filepath可以是目录路径或包含文件名的全路径。如果只指定目录但不指定文件名,它将自动生成文件名规则为'epoch{epoch:02d}-loss{loss:.2f}.h5'。每次触发保存都会覆盖同名文件,所以只会得到最后一个检查点。可以设置save_best_only=True仅保存损失最小的那个检查点。默认情况下,检查点文件将包含模型的结构、权重和优化器状态等完整信息。
min_lr参数是在ReduceLROnPlateau回调函数中使用的,它用于设置学习率的最小值。
具体说:ReduceLROnPlateau会在验证集精度停滞时自动减少学习率。每次减少的比例由factor参数控制,默认是0.1。但减少后学习率不能低于min_lr定义的最小值。所以:min_lr的默认值是0,表示学习率可以降至0。如果设置为1e-7,那么学习率每次减小后,将保证大于或等于1e-7。
monitor参数指定ReduceLROnPlateau和EarlyStopping这两个回调函数要监测的指标。
对于ReduceLROnPlateau,默认监测指标是:monitor='val_loss',即监测验证集上的损失函数(loss)值。当验证集loss值在一定数量的epoch内没有下降,就会触发学习率下调。
而EarlyStopping的默认也是:monitor='val_loss'它会监测验证集loss的变化情况,如果一定 epoch内loss没有下降,就会提前结束训练防止过拟合。
所以:monitor参数允许用户更改监测的指标,如:monitor='val_accuracy',那么二者就会监测验证集上准确率是否在提升等。此外一些常用的指标如:
'accuracy'
'f1_score'
'categorical_accuracy'
'mae'
'mse'
都可以作为替代monitor的选项。
通过修改该参数,可以让回调函数基于其他 mehr指标自动调整学习率和停止训练,更符合实际需要,看你自己最注重的是什么以此来确定衡量函数来判断。
根据以上对各个参数变量的解读,训练模型所需要的整体框架的各个参数便基本确定了,接下来便是开始进行具体的数据输入和训练
if __name__ == "__main__":
time = 144
X_train, y_train, X_test, y_test = get_data(test_num=time)
model = model_LSTM()
tf.keras.utils.plot_model(model, show_shapes=True)
model.compile(
loss=tf.keras.losses.mse,
optimizer=tf.keras.optimizers.Adam(),
)这段代码一般放在if name == "main"下,保证主流程只在直接运行文件时执行,作为单元测试模型的主程序部分,加入if name == "main"这一行代码之后,它后边的代码类似于上文utils.py中定义的函数便不会被调用。
def get_data(step=200, test_num=144):
df = pd.read_csv("../datasets/Training/PV_data_all.csv")
df.drop("t", axis=1, inplace=True)
df.drop(['InclAngle', "Current_V", "Voltage", "Humidity"], axis=1, inplace=True)
sc = MinMaxScaler(feature_range=(-1, 1))
df = sc.fit_transform(df)
df = pd.DataFrame(df)
datasets_X, datasets_y = [], []
for index in range(len(df) - step):
datasets_X.append(np.array(df.iloc[index: index+step, :]))
datasets_y.append(np.array(df.iloc[index + step]))
datasets_X, datasets_y = np.array(datasets_X), np.array(datasets_y)
X_train = datasets_X[:-test_num]
y_train = datasets_y[:-test_num]
X_test = datasets_X[-test_num:]
y_test = datasets_y[-test_num:]
return X_train, y_train, X_test, y_test那具体的获取数据的流程是怎么样的呢,定义的获取数据的函数是如何定义的呢,看上图所示。本文所使用的数据如下图所示。
数据处理过程中首先将不需要的列删掉,以及进行数据标准化转换格式等常规操作。这里设置了测试数据的数量为144,同时设置了步长为200 ,根据索引确定数据X和y.
索引从0到len(df)-step设置范围的原因是:df中的数据点数量为len(df)
每个被提取出来的序列样本的长度为step个数据点
所以序列样本的第一个数据点的索引必须小于len(df)-step
举个简单例子:
如果df总长度是10个点:
len(df) = 10
取每序列3个点作为一个样本(step=3)
那么:
第一个样本可以是点0-2,索引从0提取
第二个样本可以是点1-3,索引从1提取
第三个样本可以是点2-4,索引从2提取
但是第四个样本点3-5就超出了df范围。
所以最大索引只能是len(df)-step,也就是10-3=7
这就是为什么设置索引范围从0到len(df)-step的原因:
保证每次提取的序列范围始终在原始数据df范围内
提取完所有可能的序列样本不会溢出原始数据
这个设置很重要,可以正确和完整地从时序数据中分段提取样本
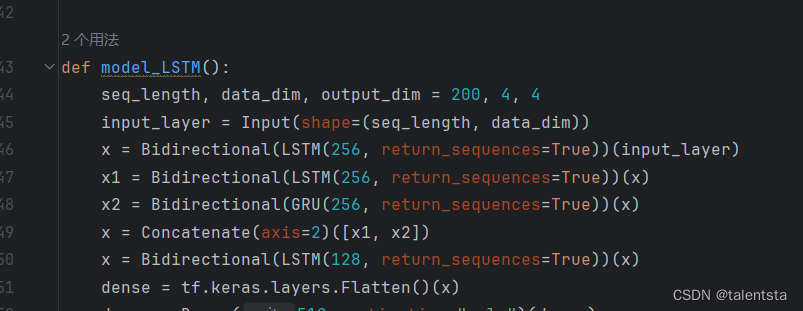
def model_LSTM():
seq_length, data_dim, output_dim = 200, 4, 4
input_layer = Input(shape=(seq_length, data_dim))
x = Bidirectional(LSTM(256, return_sequences=True))(input_layer)
x1 = Bidirectional(LSTM(256, return_sequences=True))(x)
x2 = Bidirectional(GRU(256, return_sequences=True))(x)
x = Concatenate(axis=2)([x1, x2])
x = Bidirectional(LSTM(128, return_sequences=True))(x)
dense = tf.keras.layers.Flatten()(x)
dense = Dense(512, activation="relu")(dense)
dense = Dropout(0.2)(dense)
dense = Dropout(0.2)(dense)
output = Dense(output_dim)(dense)
model = tf.keras.Model(inputs=input_layer, outputs=output)
return model此时定义的LSTM模型结构如上图所示
这段代码定义了一个基于LSTM和Bidirectional的时序模型:
Input定义输入序列的长度和维度,第一个Bidirectional-LSTM层返回序列,加深特征提取,第二个Bidirectional-LSTM层再进行一次提取,一个Bidirectional-GRU层提取另一种特征,Concatenate层把LSTM和GRU提取的特征拼接在一起,第三个Bidirectional-LSTM层进行整合,Flatten层展平多维输入为一维,后面是标准Dense层结构进行分类任务
主要特点:
使用Bidirectional可以从前向和后向流提取特征,拼接LSTM和GRU提取不同特征联合,3层LSTM提取深层次时间特征,最后 Dense层作为分类器,该模型充分利用LSTM various能力进行序列建模并实现了前向后向拼接多路网络设计,是一种相对完整的时序分类模型定义方式。
Bidirectional意为双向的。在定义LSTM层时使用了Bidirectional参数,它可以让LSTM模型具有双向学习能力:
标准的RNN只能从输入序列的第一个时间步开始依次向后处理每个时间步的特征,但实际上后续时间步的信息也可能对当前时间步预测结果有帮助。Bidirectional LSTM可以同时用前向网络和后向网络来处理输入序列:前向网络从第一个时间步开始依次处理输入;后向网络从最后一个时间步开始依次处理输入;两网结果通过拼接相加,得到每个时间步的完整表示。这样实际上让模型学习输入序列的双向上下文信息:前向网络学习前向上下文;后向网络学习后向上下文;两者融合可以学习更完整的序列表示。所以使用Bidirectional LSTM可以充分利用序列中不同时间步的关联信息,借此提升模型学习和推理效果。它成为RNN在许多序列任务上的首选结构之一。
checkpoint_save_path = "./checkpoint/LSTM.weights.h5"
if os.path.exists(checkpoint_save_path + ".index"):
print("load the model".center(50, "-"))
model.load_weights(checkpoint_save_path)
这段代码是用于加载已有预训练模型权重的:
首先定义了权重保存文件的路径为checkpoint_save_path,判断这个路径下是否存在".index"文件(Keras自动生成的文件)。如果存在,说明这套权重文件之前已经保存过,打印一句提示语句,中心对齐长度为50的"-",起示意作用,然后直接调用model.load_weights(filepath),将权重文件加载到模型
作用:
检查指定路径是否有保存的模型权重,如果有,直接加载这套权重初始化模型
这样可以实现:
从上次训练得出的权重加载模型,继续训练,避免从零开始,加快收敛,对已有模型做微调等使用,这在模型训练过程中迭代和微调很有用。通过预训练权重的载入,可以在保留学习信息的基础上优化模型,而不是从零开始训练。
callbacks = [checkpoint, earlystopping, rlrop]
history = model.fit(X_train, y_train, epochs=100, batch_size=64, validation_split=0.2, callbacks=callbacks)
callbacks列表的作用是把各种回调函数传给model.fit().需要注意几点:回调函数都定义好了,如checkpoint, earlystopping, rlrop等。将它们收集到一个列表callbacks中。在调用model.fit()时,会通过callbacks参数传入这个列表。batch_size=64:设置每个训练批次(batch)的数据量大小为64个样本。区分批训练和全量训练,可以减小内存占用。
plan = 1
if plan == 1:
pred = []
X_pred = X_test[0]
pred_0 = np.array(model.predict(X_pred.reshape(1, 200, 4)))
pred.append(pred_0[0])
for i in range(time-1):
X_pred = np.vstack((X_pred[1:], pred_0))
pred_0 = np.array(model.predict(X_pred.reshape(1, 200, 4)))[0]
pred.append(pred_0)
pred = np.array(pred)
feature_list = ["AmbiTemp", "Irradiance", "ModuleTemp", "TruePower"]
plt.figure(figsize=(20, 12))
for index in range(4):
plt.subplot(2, 2, index+1)
y_pred = pred[:, index]
y_test_show = y_test[:time, index]
plt.plot(y_test_show, label="{}_true".format(feature_list[index]))
plt.plot(y_pred, label="{}_pred".format(feature_list[index]))
plt.legend()
plt.savefig("./pred_1.png")
if plan == 1:
pred = np.array(model.predict(X_test))
feature_list = ["AmbiTemp", "Irradiance", "ModuleTemp", "TruePower"]
plt.figure(figsize=(20, 12))
for index in range(4):
plt.subplot(2, 2, index + 1)
y_pred = pred[:, index]
y_test_show = y_test[:, index]
plt.plot(y_test_show, label="{}_true".format(feature_list[index]))
plt.plot(y_pred, label="{}_pred".format(feature_list[index]))
plt.legend()
plt.savefig("./pred_2.png")这段代码实现了两种LSTM模型在测试数据上的预测方式,并可视化对比结果:
第一个if块(plan=1):
使用时序预测的方式循环预测,每次使用前面步的预测值作为后面步的输入
图片命名为pred_1.png
第二个if块(plan=1):
直接使用模型 predict()接口批量预测整个测试集
图片命名为pred_2.png
主要区别:
第一种循环预测考虑时序关系,但可能会累积误差
第二种直接批量预测考虑全局信息,但忽略时序
两种方式结果画在一张图中可视化对比:
性能是否一致
预测曲线是否平滑或者是否存在震荡
这样可以评估两种预测策略在时序任务中的表现,选择更适合的方式。
是LSTM和其他RNN模型评估的常用方法。















 1737
1737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









