






本文内容参考为2.1 张量 — 深入浅出PyTorch (datawhalechina.github.io)
2.1.1 简介
几何代数中定义的张量是基于向量和矩阵的推广,比如我们可以将标量视为零阶张量,矢量可以视为一阶张量,矩阵就是二阶张量。
| 张量维度 | 代表含义 |
|---|---|
| 0维张量 | 代表的是标量(数字) |
| 1维张量 | 代表的是向量 |
| 2维张量 | 代表的是矩阵 |
| 3维张量 | 时间序列数据 股价 文本数据 单张彩色图片(RGB) |
张量是现代机器学习的基础。它的核心是一个数据容器,多数情况下,它包含数字,有时候它也包含字符串,但这种情况比较少。因此可以把它想象成一个数字的水桶。
这里有一些存储在各种类型张量的公用数据集类型:
-
3维 = 时间序列
-
4维 = 图像
-
5维 = 视频
例子:一个图像可以用三个字段表示:
(width, height, channel) = 3D
但是,在机器学习工作中,我们经常要处理不止一张图片或一篇文档——我们要处理一个集合。我们可能有10,000张郁金香的图片,这意味着,我们将用到4D张量:
(batch_size, width, height, channel) = 4D
在PyTorch中, torch.Tensor 是存储和变换数据的主要工具。如果你之前用过NumPy,你会发现 Tensor 和NumPy的多维数组非常类似。然而,Tensor 提供GPU计算和自动求梯度等更多功能,这些使 Tensor 这一数据类型更加适合深度学习。三维可以表示时间序列,四维可以表示图像,五维可以表示视频。
2.1.2 创建tensor
在接下来的内容中,我们将介绍几种常见的创建tensor的方法。
-
随机初始化矩阵 我们可以通过
torch.rand()的方法,构造一个随机初始化的矩阵:
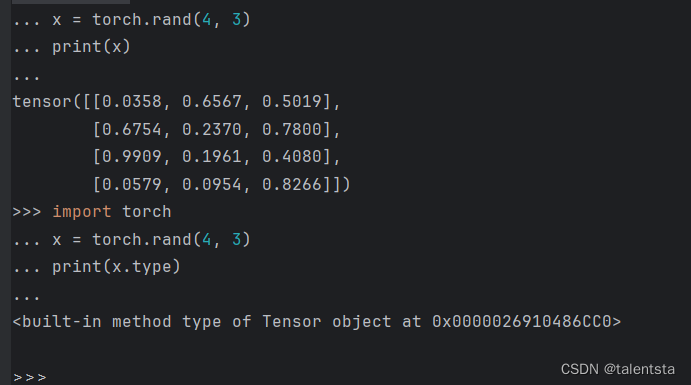
import torch x = torch.rand(4, 3) print(x)
tensor([[0.7569, 0.4281, 0.4722],
[0.9513, 0.5168, 0.1659],
[0.4493, 0.2846, 0.4363],
[0.5043, 0.9637, 0.1469]])
了解以上之后,具体我们应该如何对其进行创建并输入呢,可以参考以上例子。
-
常见的构造Tensor的方法:
| 函数 | 功能 |
|---|---|
| Tensor(sizes) | 基础构造函数 |
| tensor(data) | 类似于np.array |
| ones(sizes) | 全1 |
| zeros(sizes) | 全0 |
| eye(sizes) | 对角为1,其余为0 |
| arange(s,e,step) | 从s到e,步长为step |
| linspace(s,e,steps) | 从s到e,均匀分成step份 |
| rand/randn(sizes) | rand是[0,1)均匀分布;randn是服从N(0,1)的正态分布 |
| normal(mean,std) | 正态分布(均值为mean,标准差是std) |
| randperm(m) | 随机排列 |
.1.3 张量的操作
在接下来的内容中,我们将介绍几种常见的张量的操作方法:
-
加法操作:
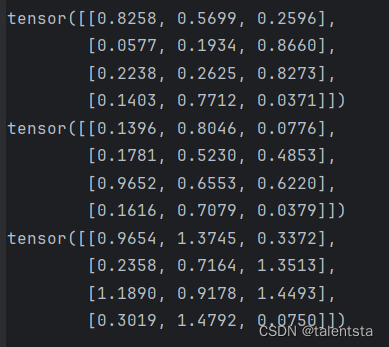
import torch # 方式1 y = torch.rand(4, 3) print(x + y) # 方式2 print(torch.add(x, y)) # 方式3 in-place,原值修改 y.add_(x) print(y)
tensor([[ 2.8977, 0.6581, 0.5856],
[-1.3604, 0.1656, -0.0823],
[ 2.1387, 1.7959, 1.5275],
[ 2.2427, -0.3100, -0.4826]])
tensor([[ 2.8977, 0.6581, 0.5856],
[-1.3604, 0.1656, -0.0823],
[ 2.1387, 1.7959, 1.5275],
[ 2.2427, -0.3100, -0.4826]])
tensor([[ 2.8977, 0.6581, 0.5856],
[-1.3604, 0.1656, -0.0823],
[ 2.1387, 1.7959, 1.5275],
[ 2.2427, -0.3100, -0.4826]])
-
索引操作:(类似于numpy)
需要注意的是:索引出来的结果与原数据共享内存,修改一个,另一个会跟着修改。如果不想修改,可以考虑使用copy()等方法
import torch x = torch.rand(4,3) # 取第二列 print(x[:, 1])
tensor([-0.0720, 0.0666, 1.0336, -0.6965])
y = x[0,:] y += 1 print(y) print(x[0, :]) # 源tensor也被改了了
tensor([3.7311, 0.9280, 1.2497]) tensor([3.7311, 0.9280, 1.2497])
-
维度变换 张量的维度变换常见的方法有
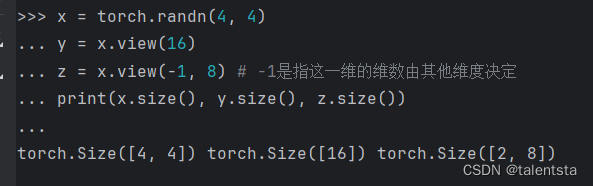
torch.view()和torch.reshape(),下面我们将介绍第一中方法torch.view():
x = torch.randn(4, 4) y = x.view(16) z = x.view(-1, 8) # -1是指这一维的维数由其他维度决定 print(x.size(), y.size(), z.size())
torch.Size([4, 4]) torch.Size([16]) torch.Size([2, 8])
注: torch.view() 返回的新tensor与源tensor共享内存(其实是同一个tensor),更改其中的一个,另外一个也会跟着改变。(顾名思义,view()仅仅是改变了对这个张量的观察角度)
x += 1 print(x) print(y) # 也加了了1
tensor([[ 1.3019, 0.3762, 1.2397, 1.3998],
[ 0.6891, 1.3651, 1.1891, -0.6744],
[ 0.3490, 1.8377, 1.6456, 0.8403],
[-0.8259, 2.5454, 1.2474, 0.7884]])
tensor([ 1.3019, 0.3762, 1.2397, 1.3998, 0.6891, 1.3651, 1.1891, -0.6744,
0.3490, 1.8377, 1.6456, 0.8403, -0.8259, 2.5454, 1.2474, 0.7884])
上面我们说过torch.view()会改变原始张量,但是很多情况下,我们希望原始张量和变换后的张量互相不影响。为为了使创建的张量和原始张量不共享内存,我们需要使用第二种方法torch.reshape(), 同样可以改变张量的形状,但是此函数并不能保证返回的是其拷贝值,所以官方不推荐使用。推荐的方法是我们先用 clone() 创造一个张量副本然后再使用 torch.view()进行函数维度变换 。
注:使用 clone() 还有一个好处是会被记录在计算图中,即梯度回传到副本时也会传到源 Tensor 。 3. 取值操作 如果我们有一个元素 tensor ,我们可以使用 .item() 来获得这个 value,而不获得其他性质:
import torch x = torch.randn(1) print(type(x)) print(type(x.item()))
<class 'torch.Tensor'> <class 'float'>
PyTorch中的 Tensor 支持超过一百种操作,包括转置、索引、切片、数学运算、线性代数、随机数等等
2.1.4 广播机制
当对两个形状不同的 Tensor 按元素运算时,可能会触发广播(broadcasting)机制:先适当复制元素使这两个 Tensor 形状相同后再按元素运算。
x = torch.arange(1, 3).view(1, 2) print(x) y = torch.arange(1, 4).view(3, 1) print(y) print(x + y)
tensor([[1, 2]])
tensor([[1],
[2],
[3]])
tensor([[2, 3],
[3, 4],
[4, 5]])
由于x和y分别是1行2列和3行1列的矩阵,如果要计算x+y,那么x中第一行的2个元素被广播 (复制)到了第二行和第三行,⽽y中第⼀列的3个元素被广播(复制)到了第二列。如此,就可以对2个3行2列的矩阵按元素相加。















 624
624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









