







1. 交叉验证原理
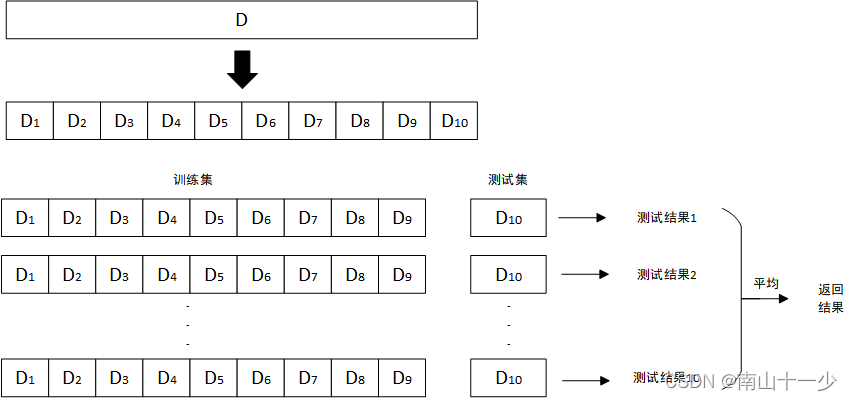
交叉验证法先将数据集D划分为k个大小相似的互斥子集,每个子集都尽可能保持数据分布的一致性,然后每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集,这样可以获得k组训练和测试并返回k个测试结果。
以k=10为例的10折交叉验证,其训练集和测试集数据分布如下所示:
2. 交叉验证应用
在寻找超参数的过程中,为了评判模型的最终性能,通常把数据集分为训练数据和测试数据,测试数据是完全不参与模型训练的独立数据,一般通过 sklearn 自带的 train_test_split 方法进行随机分配,测试数据占比20%为经验值,剩下的80%数据作为训练数据。
训练数据又细分为训练数据和验证数据,这两份数据都会参与到模型的训练,首先由训练数据训练出模型,然后通过验证数据对模型进行性能评判,从而找到最佳超参数。训练数据和验证数据分配存在随机性,容易出现过拟合的现象,即找到的最佳超参数在测试数据集中表现并不良好。为了加大训练次数,提高模型的稳定性,所以需要对数据进行多次分隔多次训练。即使用交叉验证的方法进行多次训练。
训练数据:参与模型训练
验证数据:参与模型训练,调整超参数使用的数据集
测试数据:不参与模型训练,作为衡量最终模型性能的数据集
3. 利用交叉验证寻找超参数的代码实现
利用 cross_val_score(knn_clf, X_train, y_train, cv=cv)方法将数据进行交叉分割并传入模型中进行训练,参数依次为:
knn_clf:待训练的模型
X_train:待分割的输入空间数据集
y_train:待分割的输出空间数据集
cv:分割份数k,也称为k折交叉验证
cross_val_score 方法返回k个元素的list集合,即k份数据训练了k次分别得到的k个模型评分,将这个list元素求平均,就得到当前超参数组合下模型的平均评分,次评分具备稳定性,减弱了数据随机性对模型评价的影响。
利用for循环构造了一堆超参数值,通过以上方法不断循环训练,得到每组超参数的平均模型评分,找到最佳得分和对应的超参数组合,则实现了交叉验证法寻找超参数的应用,
Fitting 5 folds for each of 60 candidates, totalling 300 fits
交叉验证,将数据分成5份,10+5*10=60个参数,共训练300次
找到最佳参数组合和模型性能评分为:
best_score=0.9666666666666668, best_weights=distance, best_k=5, best_p=4
# -*- coding: UTF-8 -*-
from sklearn import datasets
from sklearn.model_selection import cross_val_score, GridSearchCV, train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
def CrossValidationTest(X_train, y_train, cv):
best_score, best_weights, best_k, best_p = 0, 0, 0, 0
for k in range(1, 11):
for p in range(1, 6):
knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=k, p=p)
scores = cross_val_score(knn_clf, X_train, y_train, cv=cv)
score = np.mean(scores)
if score > best_score:
best_score, best_weights, best_k, best_p = score, "distance", k, p
for p in range(1, 6):
knn_clf = KNeighborsClassifier(weights="uniform", n_neighbors=k)
scores = cross_val_score(knn_clf, X_train, y_train, cv=cv)
score = np.mean(scores)
if score > best_score:
best_score, best_weights, best_k, best_p = score, "distance", k, "null"
print("best_score={}, best_weights={}, best_k={}, best_p={}".format(best_score,best_weights, best_k, best_p))
4. sklearn网格搜索对交叉验证的使用
GridSearchCV网格搜索超参数方法其源码就是使用了交叉验证方法,默认cv=5,下面通过使用上述同样的数据进行网格搜索超参数:
Fitting 5 folds for each of 60 candidates, totalling 300 fits
交叉验证,将数据分成5份,10+5*10=60个参数,共训练300次
找到最佳参数组合和模型性能评分为:
best_score = 0.9666666666666668, best_estimator={'n_neighbors': 5, 'p': 4, 'weights': 'distance'}
代码实现如下:
def GridSearchTest(X_train, y_train,cv):
"""
Fitting 5 folds for each of 60 candidates, totalling 300 fits
交叉验证,将数据分成5份,10+5*10=60个参数,共训练300次
"""
param_grid = [
{
'weights': ['uniform'], # 不考虑距离权重的模式
'n_neighbors': [i for i in range(1, 11)] # 邻近点的个数
},
{
'weights': ['distance'], # 考虑距离权重的模式
'n_neighbors': [i for i in range(1, 11)],
'p': [i for i in range(1, 6)] # 明可夫斯基距离参数 p = (0:曼哈顿距离, 1:欧拉距离)
}
]
knn_clf = KNeighborsClassifier() # 实例化 KNN 算法
grid_search = GridSearchCV(knn_clf, param_grid, n_jobs=-1, verbose=2,cv=cv) # n_jobs=-1 最大并行训练
grid_search.fit(X_train, y_train) # 针对训练数据进行最佳超参数搜索
best_estimator = grid_search.best_params_ # 这就是最终得到的最佳参数
best_score = grid_search.best_score_ # 使用上诉训练到的最佳参数得到的分类得分
print("best_score = {}, best_estimator={}".format(best_score, best_estimator))
if __name__ == '__main__':
iris = datasets.load_iris()
data = iris.data # 特征数据
target = iris.target # 标签数据
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=666)
CrossValidationTest(X_train, y_train,5)
GridSearchTest(X_train, y_train,5)5. 结论
本文通过讲述k折交叉验证的原理,并基于sklearn提供的方法进行交叉验证的应用,实现了KNN邻近模型的超参数寻找,并针对同样的数据集使用网格搜索的方法寻找超参数,试验证明两种方法得到的超参数组合和模型性能评分结果一致。通过源码可知悉,网格搜索的底层实现就是使用到了交叉验证方法。















 5773
5773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









