







1. 原理
模型正则化 Regularization 是通过约束模型参数值的大小实现解决模型方差过大(过拟合)问题的一种标准处理手段。通过模型正则化处理可以在保持模型具有较高复杂度的前提下提高模型的泛化能力。
多项式回归是为了解决输入空间和输出空间非线性关系拟合的问题,随着多项式的幂次越高,拟合度越好。但同时带来了另一个问题,就是模型的过拟合,在训练数据中表现良好的模型,在测试数据中并不理想。研究表明,模型中多项式系数越多越大,导致模型越复杂越容易过拟合,为了缓解多项式回归中的过拟合问题,兼顾误差和模型系数累计值均达到最小,在原有的损失函数中加入多项式系数的影响,即模型正则化,从而衍生出以下三种回归模型。
1.1 岭回归 Ridge Regression
以系数平方和的形式存在于目标函数中,为了调和误差与系数对损失函数的影响程度,引入了一个超参数
使如下目标函数尽可能小:
特点:计算准确,但当特征数量太多时,因不具备特征选择的功能,故整体计算量过大。
1.2 LASSO回归 LASSO Regression
以系数绝对值累计和的形式存在于目标函数中,为了调和误差与系数对损失函数的影响程度,引入了一个超参数
使如下目标函数尽可能小:
特点:具备特征选择的功能,趋向于将一部分值变为0,可能错误的丢弃有用的特征向量,对数据准确性有影响。
1.3 弹性网络回归 Elastic Net
系数平方和与绝对值累计和同时存在于目标函数中,为了调和误差与系数绝对值累计和、系数平方和三者对损失函数的影响程度,引入了两个超参数和
使如下目标函数尽可能小:
特点:综合了上述两种回归方法的优缺点
2. 代码实现
2.1 构造非线性关系数据集
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import Ridge,Lasso,ElasticNet
# 构造非线性关系数据集
np.random.seed(42)
x = np.random.uniform(-3.0, 3.0, size=100)
X = x.reshape(-1, 1)
y = 0.5 * x + 0.3 * x**2 + 3 + np.random.normal(0, 0.5, size=100)
X_train, X_test, y_train, y_test = train_test_split(X, y)2.2 通过管道方法分别封装四种回归模型
这里特意把未进行正则化处理的线性回归(LinearRegression)模型封装到管道函数中,与其余三种正则化回归模型进行对比。
注意,笔者在调用Ridge这个模型的 fit() 方法时,报了一个很诡异的错误:
TypeError: resolve() got an unexpected keyword argument 'sym_pos'
通过反复试验,发现是scikit-learn版本的问题,原来安装的是scikit-learn=1.1.0版本,其余两个回归没问题,调用岭回归的时候就会报错,后来通过升级scikit-learn=1.3.0后解决此问题。
# 封装线性回归LinearRegression
def polynomialRegression(degree):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("std_scaler", StandardScaler()),
("lin_reg", LinearRegression())
])
# 封装岭回归Ridge
def ridgeRegression(degree, alpha):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("std_scaler", StandardScaler()),
("ridge_reg", Ridge(alpha=alpha))
])
# 封装LASSO回归
def lassoRegression(degree, alpha):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("std_scaler", StandardScaler()),
("lasso_reg", Lasso(alpha=alpha))
])
# 封装弹性网络回归 ElasticNet
def eNetRegression(degree, alpha, l1_ratio):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("std_scaler", StandardScaler()),
("elasticnet_reg", ElasticNet(alpha=alpha, l1_ratio=l1_ratio))
])2.3 封装模型得分和图像函数
# 模型训练得分及图形展示
def modeScore(model):
model.fit(X_train, y_train)
y_predict = model.predict(X_test)
score = mean_squared_error(y_test, y_predict)
print(score)
X_plot = np.linspace(-3, 3, 100).reshape(100, 1)
y_plot = model.predict(X_plot)
plt.scatter(X, y, color='b')
plt.plot(X_plot, y_plot, color='r')
plt.axis([-3, 3, 0, 6])
plt.show()
return score2.4 运行结果
# 运行
if __name__ == "__main__":
modeScore(polynomialRegression(20))
modeScore(ridgeRegression(20, 0.01))
modeScore(lassoRegression(20, 0.01))
modeScore(eNetRegression(20, 0.01, 0.5))通过对比发现,当统一参数degree=20时,线性回归LinearRegression在训练阶段表现出较好的拟合程度,但在测试阶段,其方差结果不敬人意。
LinearRegression mean_squared_error = 9.853052442122733
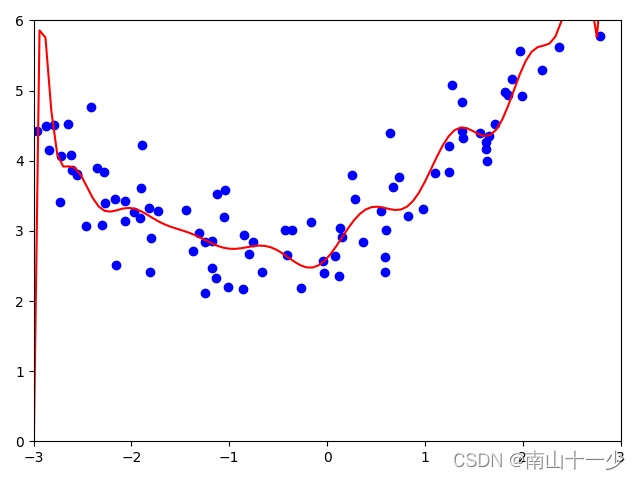
而其余三个正则化后的回归模型兼顾了拟合效果,并在测试阶段能够表现出更佳的方差表现
Ridge mean_squared_error = 0.253209514046839
Lasso mean_squared_error = 0.24692213540618904
ElasticNet mean_squared_error = 0.2585000641800718
这里三个模型的超参数笔者只是给出了一个粗略的估计值,很明显其效果非常显著,方差值远远小于未正则化的线性回归模型,当然也可以通过参数搜索的方法找到更好的超参数使模型更加精准。
笔者以弹性网络回归为例,寻找最佳超参数,代码如下:
def bestScore():
min_score, alpha, l1_ratio = 10, 0, 0
for i in np.arange(0, 10, 0.01):
for j in np.arange(0, 1, 0.01):
reg = eNetRegression(20, i, j)
reg.fit(X_train, y_train)
y_predict = reg.predict(X_test)
score = mean_squared_error(y_test, y_predict)
if score < min_score:
min_score, alpha, l1_ratio = score, i, j
print("min_score = {}, alpha = {}, l1_ratio = {}".format(min_score, alpha, l1_ratio))
min_score = 0.2468100322378766, alpha = 0.02, l1_ratio = 0.99
不难看出,以上代码寻找到的超参数,兼顾其测试数据集中的方差最小,并在训练集中拟合程度表现最好。
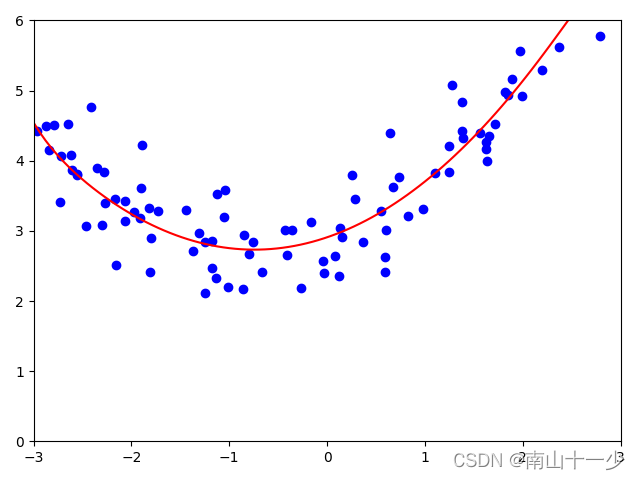
3. 结论
本文讲解了模型正则化的原理,以及在多项式回归中的应用,模型正则化能够有效的抑制多项式回归的过拟合问题。通过未经过正则化的多项式回归与三种不同形式的正则化回归模型做对比,实验证明,正则化回归后的模型能够更好的抑制过拟合问题,并在测试数据集中有更好的表现。















 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









