






1.自制ucf数据集请看这位博主
yowov3时2023的一篇开源时空检测模型,可用于监控动作识别。
2.模型部署
2.1安装必要的库
Hope1337/YOWOv3 (github.com)大家按照源码安装就行
2.2 下载权重文件。
首先按照官网下载预训练权重文件(共三个)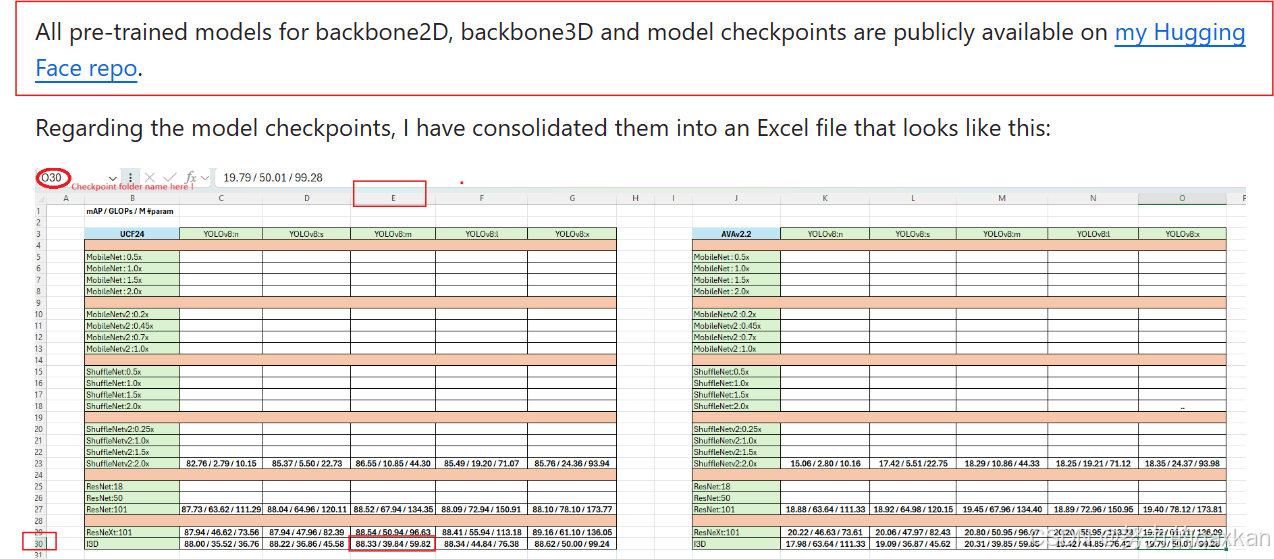
根据自己的需要,按照上图excel表格选择不同大小backbone2D(本文yolov8m),bockbone3D(本文I3D),和预训练ema_epoch_7权重文件。

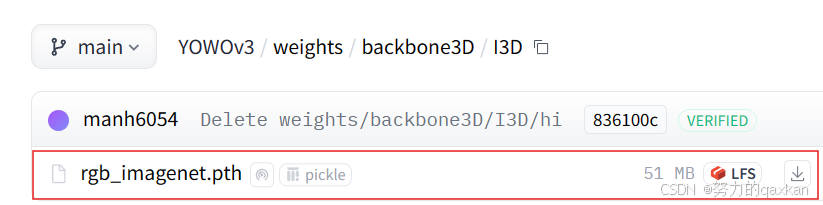
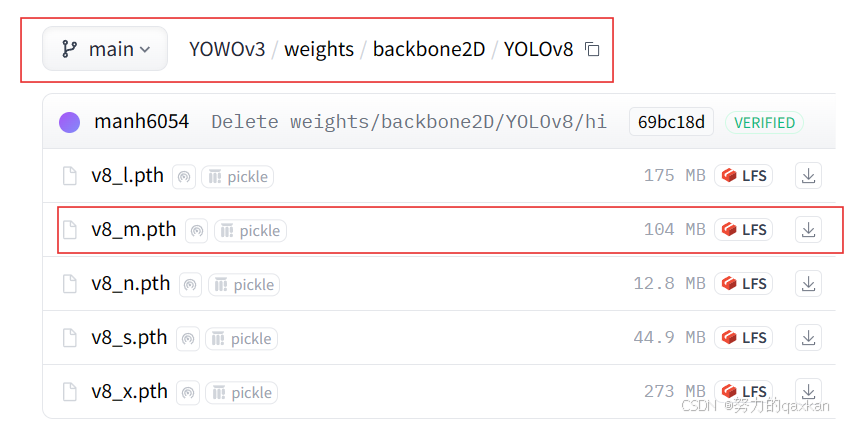
权重文件分别放在:
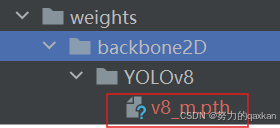
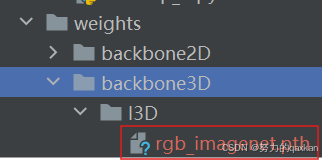
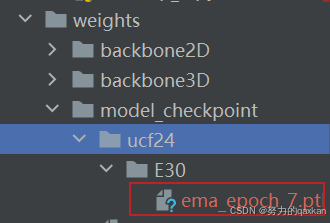
自制数据集放在:
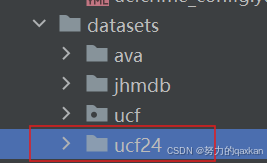
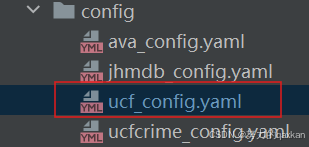
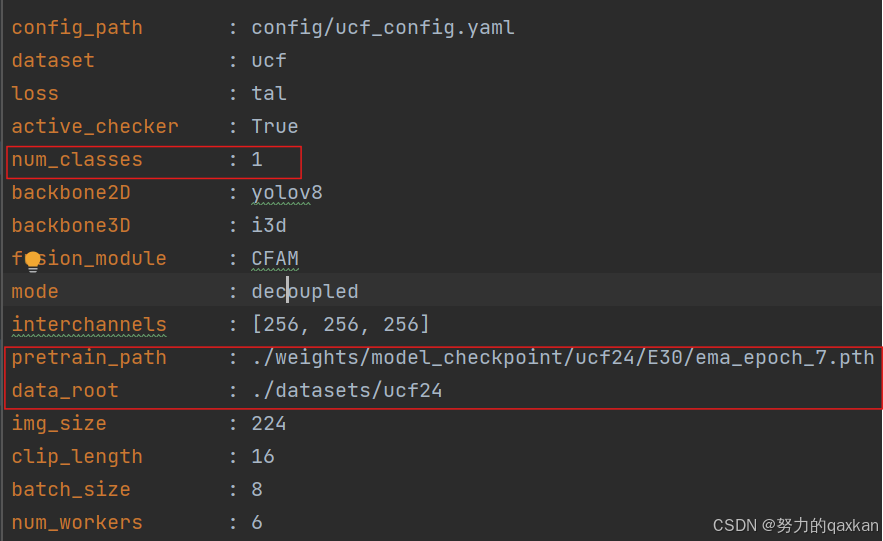
2.2 修改ucf_config.yaml文件
修改为自己的类别标签,num_classes修改为自己数据集的类别数,pretrain_path,data_root 修改为自己保存的预训练模型权重地址和数据集存放地址。
2.3 修改load_data.py文件(重要!)

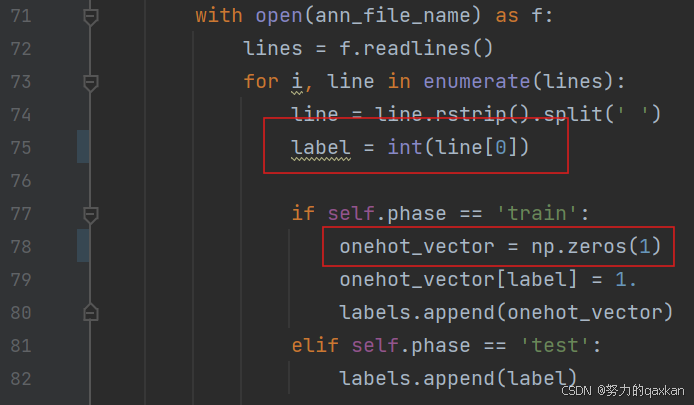
第一处和yowov2一样,原始ucf数据集标签类别是从1开始的,而我们用labelimg标注的自制ucf24数据集标签是从0开始的(如果你的类别标签是从1开始的就不需要更改),yowov3 加载数据label的时候还是会减去1变为负数,会导致报错。
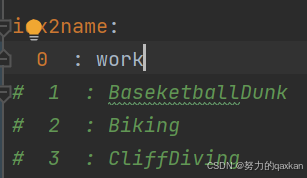
第二处需要根据自制数据集有多少个类别作更改,保持与numclasses一致(本文只有work一种类别)
2.4训练(更改训练时自动验证保存map50最高模型文件)
此时已经可以开始训练,使用官网python main.py --mode train --config config/ucf_config.yaml命令
但是呢,这个模型最蠢的地方在于他的源码只能先训练,并保存所有epoch的权重文件,验证需要在训练完毕后再单独挨个运行python main.py -m eval -cf config/ucf_config.yaml命令验证权重文件map50。

那我必须不能接受!
修改train.py文件为以下:轻松实现每个epoch后进行自动验证,并只保存map50最高的epoch权重文件,且检查若训练100个epoch后,模型map50未上升,自动终止训练,防止过拟合。
import torch
import torch.utils.data as data
import torch.nn as nn
import torchvision
import torchvision.transforms.functional as FT
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import time
import xml.etree.ElementTree as ET
import os
import cv2
import random
import sys
import glob
from math import sqrt
from utils.gradflow_check import plot_grad_flow
from utils.EMA import EMA
import logging
from utils.build_config import build_config
from datasets.ucf.load_data import UCF_dataset
from datasets.collate_fn import collate_fn
from datasets.build_dataset import build_dataset
from model.TSN.YOWOv3 import build_yowov3
from utils.loss import build_loss
from utils.warmup_lr import LinearWarmup
import shutil
from utils.flops import get_info
from utils.box import non_max_suppression, box_iou
from evaluator.eval import compute_ap
import tqdm
from datasets.ucf.transforms import UCF_transform
def train_model(config):
# Save config file
#######################################################
source_file = config['config_path']
destination_file = os.path.join(config['save_folder'], 'config.yaml')
shutil.copyfile(source_file, destination_file)
#######################################################
# create dataloader, model, criterion
####################################################
dataset = build_dataset(config, phase='train')
dataloader = data.DataLoader(dataset, config['batch_size'], True, collate_fn=collate_fn
, num_workers=config['num_workers'], pin_memory=True)
model = build_yowov3(config)
get_info(config, model)
model.to("cuda")
model.train()
criterion = build_loss(model, config)
#####################################################
# optimizer = optim.AdamW(params=model.parameters(), lr= config['lr'], weight_decay=config['weight_decay'])
g = [], [], [] # optimizer parameter groups
bn = tuple(v for k, v in nn.__dict__.items() if "Norm" in k) # normalization layers, i.e. BatchNorm2d()
for v in model.modules():
for p_name, p in v.named_parameters(recurse=0):
if p_name == "bias": # bias (no decay)
g[2].append(p)
elif p_name == "weight" and isinstance(v, bn): # weight (no decay)
g[1].append(p)
else:
g[0].append(p) # weight (with decay)
optimizer = torch.optim.AdamW(g[0], lr=config['lr'], weight_decay=config['weight_decay'])
optimizer.add_param_group({"params": g[1], "weight_decay": 0.0})
optimizer.add_param_group({"params": g[2], "weight_decay": 0.0})
warmup_lr = LinearWarmup(config)
adjustlr_schedule = config['adjustlr_schedule']
acc_grad = config['acc_grad']
max_epoch = config['max_epoch']
lr_decay = config['lr_decay']
save_folder = config['save_folder']
torch.backends.cudnn.benchmark = True
cur_epoch = 1
loss_acc = 0.0
ema = EMA(model)
# 增加best_map50,后续用于判断保存map50最高的epoch权重
global best_map50
global no_improvement_count
best_map50 = 0.0
no_improvement_count = 0
# 用于保存上一个epoch的模型路径
prev_save_path_ema = None
prev_save_path = None
# 增加 no_improvement_count计数器判断,模型在100轮中,map50未有增高,则自动停止训练,防止过拟合
while (cur_epoch <= max_epoch) and (no_improvement_count < 100):
cnt_pram_update = 0
for iteration, (batch_clip, batch_bboxes, batch_labels) in enumerate(dataloader):
batch_size = batch_clip.shape[0]
batch_clip = batch_clip.to("cuda")
for idx in range(batch_size):
batch_bboxes[idx] = batch_bboxes[idx].to("cuda")
batch_labels[idx] = batch_labels[idx].to("cuda")
outputs = model(batch_clip)
targets = []
for i, (bboxes, labels) in enumerate(zip(batch_bboxes, batch_labels)):
nbox = bboxes.shape[0]
nclass = labels.shape[1]
target = torch.Tensor(nbox, 5 + nclass)
target[:, 0] = i
target[:, 1:5] = bboxes
target[:, 5:] = labels
targets.append(target)
targets = torch.cat(targets, dim=0)
loss = criterion(outputs, targets) / acc_grad
loss_acc += loss.item()
loss.backward()
# plot_grad_flow(model.named_parameters()) #model too large, can't see anything!
# plt.show()
if (iteration + 1) % acc_grad == 0:
cnt_pram_update = cnt_pram_update + 1
if cur_epoch == 1:
warmup_lr(optimizer, cnt_pram_update)
nn.utils.clip_grad_value_(model.parameters(), clip_value=2.0)
optimizer.step()
optimizer.zero_grad()
ema.update(model)
print("epoch : {}, update : {}, loss = {}".format(cur_epoch, cnt_pram_update, loss_acc), flush=True)
# 更改logging.txt为追加模式(“a”),可记录所有epoch loss信息
with open(os.path.join(config['save_folder'], "logging.txt"), "a") as f:
# 添加换行符,便于阅读
f.write("epoch : {}, update : {}, loss = {}\n".format(cur_epoch, cnt_pram_update, loss_acc))
loss_acc = 0.0
if cur_epoch in adjustlr_schedule:
for param_group in optimizer.param_groups:
param_group['lr'] *= lr_decay
# 进行验证(eval函数会将模型设置为验证模式)
map50, mean_ap = eval(config, model)
# 判断是否为当前最佳模型并保存
if cur_epoch == 1:
# 保存第一个epoch的模型
save_path_ema = os.path.join(save_folder, "ema_epoch_" + str(cur_epoch) + ".pth")
torch.save(ema.ema.state_dict(), save_path_ema)
prev_save_path_ema = save_path_ema
save_path = os.path.join(save_folder, "epoch_" + str(cur_epoch) + ".pth")
torch.save(model.state_dict(), save_path)
prev_save_path = save_path
best_map50 = map50
elif map50 > best_map50:
best_map50 = map50
print("New best model found at epoch {} with map50: {}".format(cur_epoch, best_map50), flush=True)
# 保存当前最佳模型(一个ema后model,一个原始model)
save_path_ema = os.path.join(save_folder, "ema_epoch_" + str(cur_epoch) + ".pth")
torch.save(ema.ema.state_dict(), save_path_ema)
save_path = os.path.join(save_folder, "epoch_" + str(cur_epoch) + ".pth")
torch.save(model.state_dict(), save_path)
# 删除上一个epoch的模型文件(如果存在)
if prev_save_path_ema and prev_save_path:
os.remove(prev_save_path_ema)
os.remove(prev_save_path)
# 更新上一个保存路径
prev_save_path_ema = save_path_ema
prev_save_path = save_path
# 计数器(map50有增高则重置为0)
no_improvement_count = 0
else:
no_improvement_count += 1
# 验证完成后重新设置模型为训练模式
model.train()
print("New best model save epoch {} with map50: {}".format(cur_epoch, best_map50), flush=True)
cur_epoch += 1
# print("Best map50: {} at model path: {}".format(best_map50,save_path_ema), flush=True)
@torch.no_grad()
#eval函数新增model参数,用于接受每个epoch训练后的模型进行验证
def eval(config, model):
dataset = build_dataset(config, phase='test')
# 若cuda显存不足,可自己设置batchsize,默认32.
dataloader = data.DataLoader(dataset, 32, False, collate_fn=collate_fn
, num_workers=6, pin_memory=True)
#直接接收训练后的model进行验证,不再使用build_yow0v3(config)初始化加载模型
model.eval()
model.to("cuda")
# Configure
# iou_v = torch.linspace(0.5, 0.95, 10).cuda() # iou vector for mAP@0.5:0.95
iou_v = torch.tensor([0.5]).cuda()
n_iou = iou_v.numel()
m_pre = 0.
m_rec = 0.
map50 = 0.
mean_ap = 0.
metrics = []
p_bar = tqdm.tqdm(dataloader, desc=('%10s' * 3) % ('precision', 'recall', 'mAP'))
for batch_clip, batch_bboxes, batch_labels in p_bar:
batch_clip = batch_clip.to("cuda")
targets = []
for i, (bboxes, labels) in enumerate(zip(batch_bboxes, batch_labels)):
target = torch.Tensor(bboxes.shape[0], 6)
target[:, 0] = i
target[:, 1] = labels
target[:, 2:] = bboxes
targets.append(target)
targets = torch.cat(targets, dim=0).to("cuda")
height = config['img_size']
width = config['img_size']
# Inference
outputs = model(batch_clip)
# NMS
targets[:, 2:] *= torch.tensor((width, height, width, height)).cuda() # to pixels
outputs = non_max_suppression(outputs, 0.005, 0.5)
# Metrics
for i, output in enumerate(outputs):
labels = targets[targets[:, 0] == i, 1:]
correct = torch.zeros(output.shape[0], n_iou, dtype=torch.bool).cuda()
if output.shape[0] == 0:
if labels.shape[0]:
metrics.append((correct, *torch.zeros((3, 0)).cuda()))
continue
detections = output.clone()
# util.scale(detections[:, :4], samples[i].shape[1:], shapes[i][0], shapes[i][1])
# Evaluate
if labels.shape[0]:
tbox = labels[:, 1:5].clone() # target boxes
# tbox[:, 0] = labels[:, 1] - labels[:, 3] / 2 # top left x
# tbox[:, 1] = labels[:, 2] - labels[:, 4] / 2 # top left y
# tbox[:, 2] = labels[:, 1] + labels[:, 3] / 2 # bottom right x
# tbox[:, 3] = labels[:, 2] + labels[:, 4] / 2 # bottom right y
# util.scale(tbox, samples[i].shape[1:], shapes[i][0], shapes[i][1])
correct = np.zeros((detections.shape[0], iou_v.shape[0]))
correct = correct.astype(bool)
t_tensor = torch.cat((labels[:, 0:1], tbox), 1)
iou = box_iou(t_tensor[:, 1:], detections[:, :4])
correct_class = t_tensor[:, 0:1] == detections[:, 5]
for j in range(len(iou_v)):
x = torch.where((iou >= iou_v[j]) & correct_class)
if x[0].shape[0]:
matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1)
matches = matches.cpu().numpy()
if x[0].shape[0] > 1:
matches = matches[matches[:, 2].argsort()[::-1]]
matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
correct[matches[:, 1].astype(int), j] = True
correct = torch.tensor(correct, dtype=torch.bool, device=iou_v.device)
metrics.append((correct, output[:, 4], output[:, 5], labels[:, 0]))
# Compute metrics
metrics = [torch.cat(x, 0).cpu().numpy() for x in zip(*metrics)] # to numpy
if len(metrics) and metrics[0].any():
tp, fp, m_pre, m_rec, map50, mean_ap = compute_ap(*metrics)
# Print results
print('%10.3g' * 3 % (m_pre, m_rec, mean_ap), flush=True)
# Return results
model.float() # for training
return map50, mean_ap
结束!


















 2603
2603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









