







目录
一.项目简介
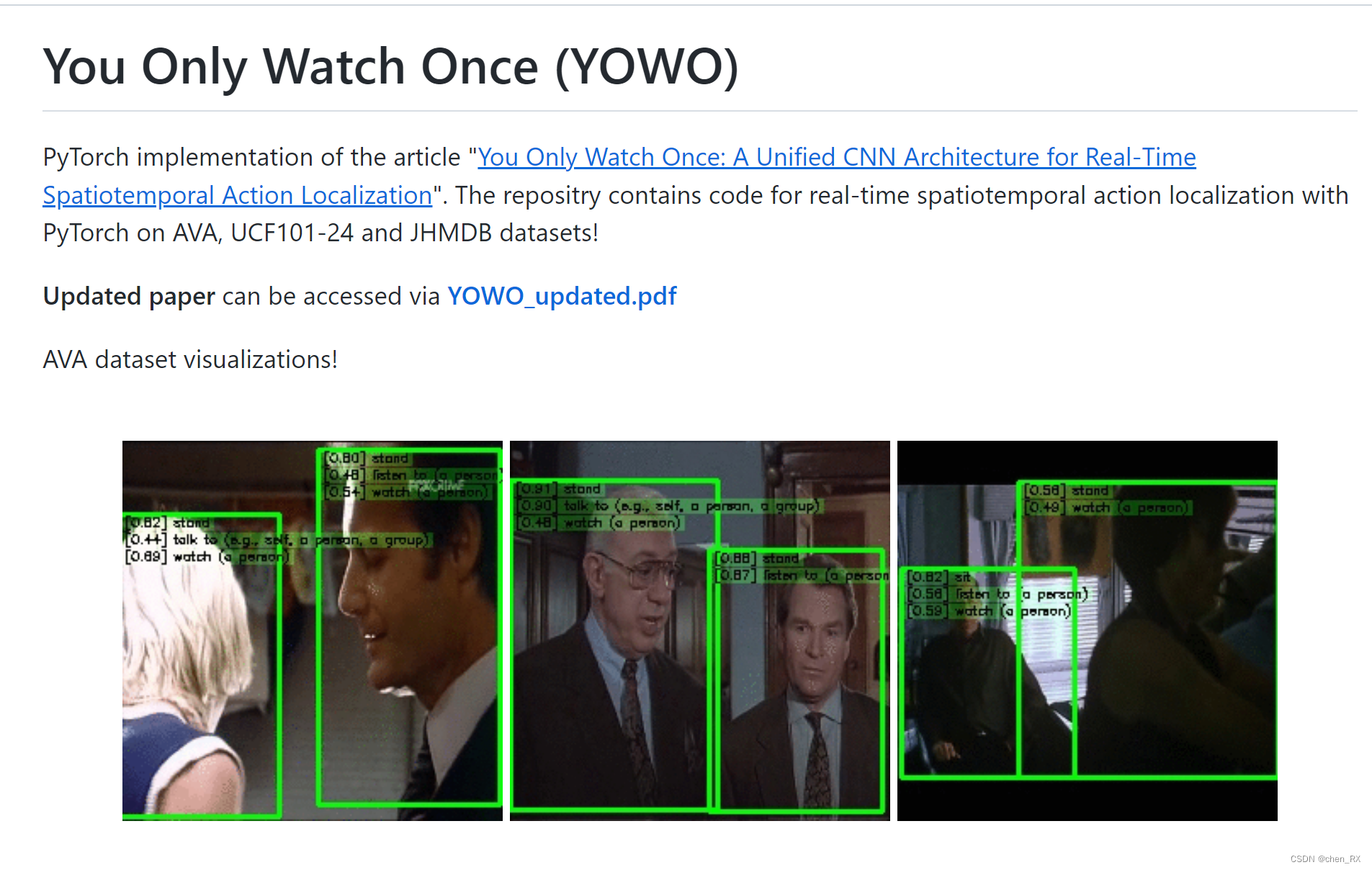
最近看了YOWO的论文,论文提出了一种时空行为检测的单阶段网络架构,并且在UCF101-24和JHDMB上跑出了不错的效果,并且做到了实时检测,这里对论文内容不作赘述,有兴趣的可以去看看原论文。
本文的目的是给大家讲解一下项目代码运行中遇到的问题和解决方法,希望可以帮助到那些看了论文想要快速跑一下项目代码的同学,博主本人也是初入CV领域,讲解若有谬误或遗漏,欢迎各位在评论区批评指正,有讲解不清晰的地方,也可发在评论区讨论。
项目网址:https://github.com/wei-tim/YOWO
二.项目运行
首先,从github上下载项目文件,查看作者的声明可以发现,项目的部署相对比较简单,下载好相关包,准备好数据集后就可以运行main.py文件进行训练和测试,作者也贴心的准备了数据集链接和标注文件。读者可以自行在官网下载。(我使用的是ucf24数据集,随数据集附带了一个pkl格式的标注文件,项目要求提取出trianlist.txt,testlist.txt,testlist_videos.txt和labels文件夹存放标注文件,这几个文件作者提供了)
1. 标注文件的路径问题
关于数据集本身,只需要按照链接下载即可,我使用的是ucf24数据集,随数据集附带了一个pkl格式的标注文件,项目要求提取出trianlist.txt,testlist.txt,testlist_videos.txt和labels文件夹存放标注文件,这几个文件作者都提供了,但就是作者提供的这几个文件出现了问题。在准备好所有文件,运行main.py之后报错,报错的图没有截下来,大致意思是根据trainlist.txt文件找不到labels文件夹下的标注文件。查看项目的源码可以发现,datasets文件夹下clip.py文件中的load_data_detection函数报错说找不到标注文件,查看这个函数可以发现他是这样写的:
labpath = os.path.join(base_path, 'labels', im_split[0], im_split[1] ,'{:05d}.txt'.format(im_ind))这里是根据配置文件中的base文件路径来生成标注文件路径,首先我们需要把groundtruths_ucf文件夹改名为labels文件夹;其次,进入labels文件夹可以看到标注文件的格式为

而上面那行代码是以 '/' 连接路径名,我们应改为 '_'连接
# labpath = os.path.join(base_path, 'labels', im_split[0], im_split[1] ,'{:05d}.txt'.format(im_ind))
labpath = base_path + '/' + 'labels' + '/' + im_split[0] + '_' + im_split[1] + '_' + '{:05d}.txt'.format(im_ind)这样就能正确读取标注文件
2.标注文件问题
经过上面的修改过后,我发现问题依然存在,检查后发现标签路径格式已经没有问题了,问题在于给定的标签文件夹labels中没有训练数据的标签。
打开这几个文件一看,有非常明显的错误,标注文件仅有测试视频的标注,训练文件没有标注,因此训练无法进行(大家可以尝试把ucf24.yaml文件中的训练文件路径改为测试文件的路径,会发现训练又可以进行了,这其实就是因为作者给的标注文件只标了测试数据集)
由于ucf24自带了一个yaml文件,里面有标注信息,因此我自己编写了一个脚本可以生成该项目所需的相关文件
import pickle
import pprint
import os
file_path = r"D:\Programs\python\PythonProject\DeepLearning\MyProjects\data\ucf24\UCF101v2-GT.pkl"
save_path = r"D:\Programs\python\PythonProject\DeepLearning\MyProjects\data\ucf24\annotations"
if not os.path.exists(save_path):
os.mkdir(save_path)
def read_pkl(file_path):
assert os.path.exists(file_path), 'File not found!'
data_list = []
with open(file_path, 'rb') as f:
while True:
try:
data = pickle.load(f, encoding='latin')
data_list.append(data)
except EOFError:
break
return data_list
def generate_train_and_labels_file(train: bool, videos: list, annotations: list):
assert type(videos) == list and type(annotations) == dict
if train:
trainlist_file = os.path.join(save_path, 'trainlist.txt')
annotations_dir = os.path.join(save_path, 'labels')
if not os.path.exists(annotations_dir):
os.mkdir(annotations_dir)
train_file = open(trainlist_file, 'a+')
for video in videos:
ann = annotations[video]
part1, part2 = video.split('/')[0], video.split('/')[1]
for key, val in ann.items(): # key: class id, val: list of frames, nframes * 5
for idx, labels in enumerate(val): # val可能出现多个人物,因此需分别对每个人物的标注进行处理
for label in labels:
if idx == 0: # 仅在第一次循环中生成 trainlist.txt 文件
trainline = video + '/' + '{:05d}.txt'.format(int(label[0])) + '\n'
train_file.write(trainline)
labelfile = part1 + '_' + part2 + '_' + '{:05d}.txt'.format(int(label[0]))
label_path = os.path.join(annotations_dir, labelfile) # label path
labelline = str(int(key+1))
for x in label[1:]:
labelline += ' {:d}'.format(int(x)) # label info type: class, Xmin, Ymin, Xmax, Ymax
labelline += '\n'
with open(label_path, 'a+') as f:
f.write(labelline)
f.close()
train_file.close()
else:
testlist_file = os.path.join(save_path, 'testlist.txt')
annotations_dir = os.path.join(save_path, 'labels')
videolist = os.path.join(save_path, 'testlist_videos.txt')
if not os.path.exists(annotations_dir):
os.mkdir(annotations_dir)
test_file = open(testlist_file, 'a+')
video_file = open(videolist, 'a+')
for video in videos:
videoline = video + '\n'
video_file.write(videoline)
ann = annotations[video]
part1, part2 = video.split('/')[0], video.split('/')[1]
for key, val in ann.items(): # key: class id, val: list of frames, nframes * 5
for idx, labels in enumerate(val):
for label in labels:
if idx == 0:
testline = video + '/' + '{:05d}.txt'.format(int(label[0])) + '\n'
test_file.write(testline)
labelfile = part1 + '_' + part2 + '_' + '{:05d}.txt'.format(int(label[0]))
label_path = os.path.join(annotations_dir, labelfile) # label path
labelline = str(int(key)+1)
for x in label[1:]:
labelline += ' {:d}'.format(int(x)) # label info type: frame id, Xmin, Ymin, Xmax, Ymax
labelline += '\n'
with open(label_path, 'a+') as f:
f.write(labelline)
f.close()
test_file.close()
video_file.close()
if __name__ == '__main__':
data = read_pkl(file_path)[0]
labels = data['labels']
train_videos = data['train_videos'][0]
test_videos = data['test_videos'][0]
nframes = data['nframes']
gttubes = data['gttubes']
generate_train_and_labels_file(train=True, videos=train_videos, annotations=gttubes)
generate_train_and_labels_file(train=False, videos=test_videos, annotations=gttubes)file_path需要指定到官方的pkl标注文件,save_path为生成的一系列文件的存储位置
目前我碰到的问题就是这么两个,归根结底是标注文件的问题,我感觉可能是作者不小心放错了标注文件,可能未来会被修复。
3.训练
训练时需要修改配置文件,我用的ucf24,需要修改cfg/ucf24.yaml文件,主要是指定文件路径
训练时需要采用的预训练模型都可以在https://github.com/wei-tim/YOWO上面下载,你也可以下载预训练好的YOWO模型。

我这里没有用预训练的YOWO模型,训练了一轮大概3,4个小时(batch_size=16, 两张3080Ti),估计训练5个epoch足够了。
三. 总结
(1)单阶段的行为检测是一个十分新颖的方向,目前对这个方向的研究工作很少,这一方法也未经过充分的验证,充满了不确定性,这一领域仍有许多工作要做,未来单阶段的目标检测是否能如yolo那般改变行为检测的研究现状也未可知,总之这是一个十分有意思的创新。
(2)YOWO的项目代码结构相对清晰,适合深入了解其算法实现,其设计思想可谓承袭了许多之前的优秀工作,在ucf24和JHMDB上也取得了不错的效果。
四. 参考文献
[1] Köpüklü O, Wei X, Rigoll G. You Only Watch Once: A Unified CNN Architecture for Real-Time Spatiotemporal Action Localization[J]. arXiv, 2021.

















 5886
5886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









