







知识点
vector补充
vector<int> g;
g.push_back(3);
g.push_back(2);
g.push_back(1);
{ 3, 2, 1}
| |
s.begin() s.end()//均为指向地址
sort(s.begin(),s.end());
int a = 3;b = 4;
swap(a,b);//交换地址,而不是数字
0x 16进制前缀
o 8进制前缀
string补充
string s;//string是特殊的stl
s.push_back('d');
s.pop_back();
s.substr(i,k);//截取字符串
reverse//翻转
二进制
二进制(Binary)是一种基数为2的数制系统,它只使用两个数码来表示数,即0和1。二进制是计算机内部存储和处理数据的基础,因为计算机中的所有信息最终都是以二进制的形式存在和处理的。
二进制的特点
- 基数为2:二进制数系统中,每一位的权值是2的幂次方。例如,在二进制数
1010中,从右到左的每一位分别代表 2 0 2^0 20、 2 1 2^1 21、 2 2 2^2 22、 2 3 2^3 23。 - 仅有两个数码:二进制数只包含0和1两个数码,这使得二进制数在电子电路中易于表示和处理,因为电路的开和关状态可以自然地映射到这两个数码上。
- 转换方便:二进制数与十进制数之间可以方便地进行转换,尽管这种转换在位数较多时可能变得繁琐。此外,二进制数还可以方便地转换为八进制数和十六进制数,这些数制在计算机科学中也经常使用。
二进制数的表示
二进制数可以用一系列的0和1来表示,例如1011、0010等。在书写时,通常不会省略前导的0(尽管在某些上下文中可能会这样做),因为前导0会影响数的值(在二进制中,0010和10虽然看起来不同,但实际上表示的是同一个数)。
二进制数的运算
二进制数的运算包括加法、减法、乘法和除法等,这些运算都遵循与十进制数相似的规则,但需要注意的是,由于二进制数只有0和1两个数码,因此在运算过程中可能会产生进位或借位。
二进制在计算机中的应用
二进制在计算机科学中起着至关重要的作用。计算机中的所有信息,包括程序、数据、指令等,都是以二进制的形式存储在计算机的内存和存储设备中的。此外,计算机内部的逻辑电路也是基于二进制数进行设计和工作的。因此,了解二进制数的表示和运算对于深入理解计算机的工作原理至关重要。
示例
假设我们有一个二进制数1010,我们可以将其转换为十进制数如下:
101
0
(
2
)
=
1
×
2
3
+
0
×
2
2
+
1
×
2
1
+
0
×
2
0
=
8
+
0
+
2
+
0
=
1
0
(
10
)
1010_{(2)} = 1 \times 2^3 + 0 \times 2^2 + 1 \times 2^1 + 0 \times 2^0 = 8 + 0 + 2 + 0 = 10_{(10)}
1010(2)=1×23+0×22+1×21+0×20=8+0+2+0=10(10)
同样地,我们也可以将十进制数转换为二进制数。例如,将十进制数10转换为二进制数,我们得到1010(注意这里的转换可能不是唯一的,因为前导0可以省略,但在这里我们保留了它以便与上面的示例保持一致)。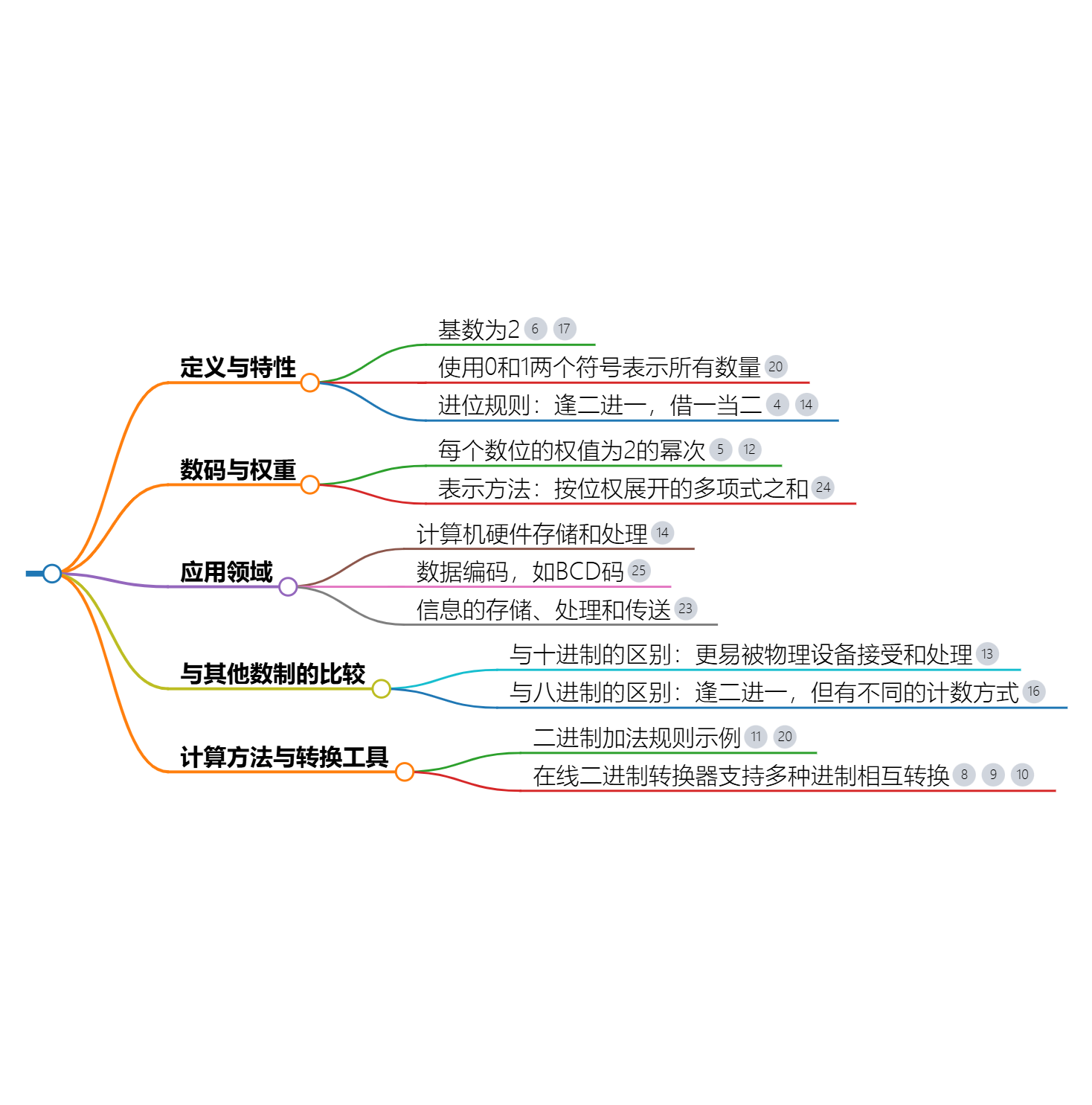
位运算
位运算(Bitwise Operations)是直接在整数的二进制位上进行的操作。这些操作包括与(AND)、或(OR)、异或(XOR)、非(NOT)、左移(Left Shift)和右移(Right Shift)等。位运算在处理大量数据、图形处理、加密解密等领域中非常有用,因为它们通常可以在硬件级别上直接执行,因此执行速度非常快。
下面是几种基本的位运算操作及其说明:
- 与(AND):对两个位进行比较,如果两个位都为1,则结果位为1;否则,结果位为0。符号:
&示例:5 & 3- 5的二进制为
101 - 3的二进制为
011 - 结果的二进制为
001,即十进制的1。
- 5的二进制为
- 或(OR):对两个位进行比较,如果两个位中至少有一个为1,则结果位为1;否则,结果位为0。符号:
|示例:5 | 3- 5的二进制为
101 - 3的二进制为
011 - 结果的二进制为
111,即十进制的7。
- 5的二进制为
- 异或(XOR):对两个位进行比较,如果两个位不相同,则结果位为1;如果两个位相同,则结果位为0。符号:
^示例:5 ^ 3- 5的二进制为
101 - 3的二进制为
011 - 结果的二进制为
110,即十进制的6。
- 5的二进制为
- 非(NOT):是一个一元操作符,它将所有位上的0变成1,1变成0。符号:
~示例:~5(假设在32位整型中)- 5的二进制(在32位整型中表示)为
0000 0000 0000 0000 0000 0000 0000 0101 - 结果的二进制为
1111 1111 1111 1111 1111 1111 1111 1010,即十进制的-6(注意,这里涉及到二进制补码的概念)。
- 5的二进制(在32位整型中表示)为
- 左移(Left Shift):将一个数的各二进制位全部左移若干位,由左侧边缘超出的位将被丢弃,而在右侧边缘新增的位将用0填充。符号:
<<示例:5 << 2- 5的二进制为
101 - 左移2位后,结果为
10100,即十进制的20,即5*2*2。
- 5的二进制为
- 右移(Right Shift):将一个数的各二进制位全部右移若干位,由右侧边缘超出的位将被丢弃。对于无符号数,左侧边缘新增的位将用0填充;对于有符号数,则取决于系统(可能是用0填充,也可能是用符号位填充,即算术右移)。符号:
>>示例:5 >> 2(假设为有符号整数)- 5的二进制为
101 - 右移2位后,结果为
001(算术右移,保持符号位),即十进制的1,即5/2/2。
- 5的二进制为
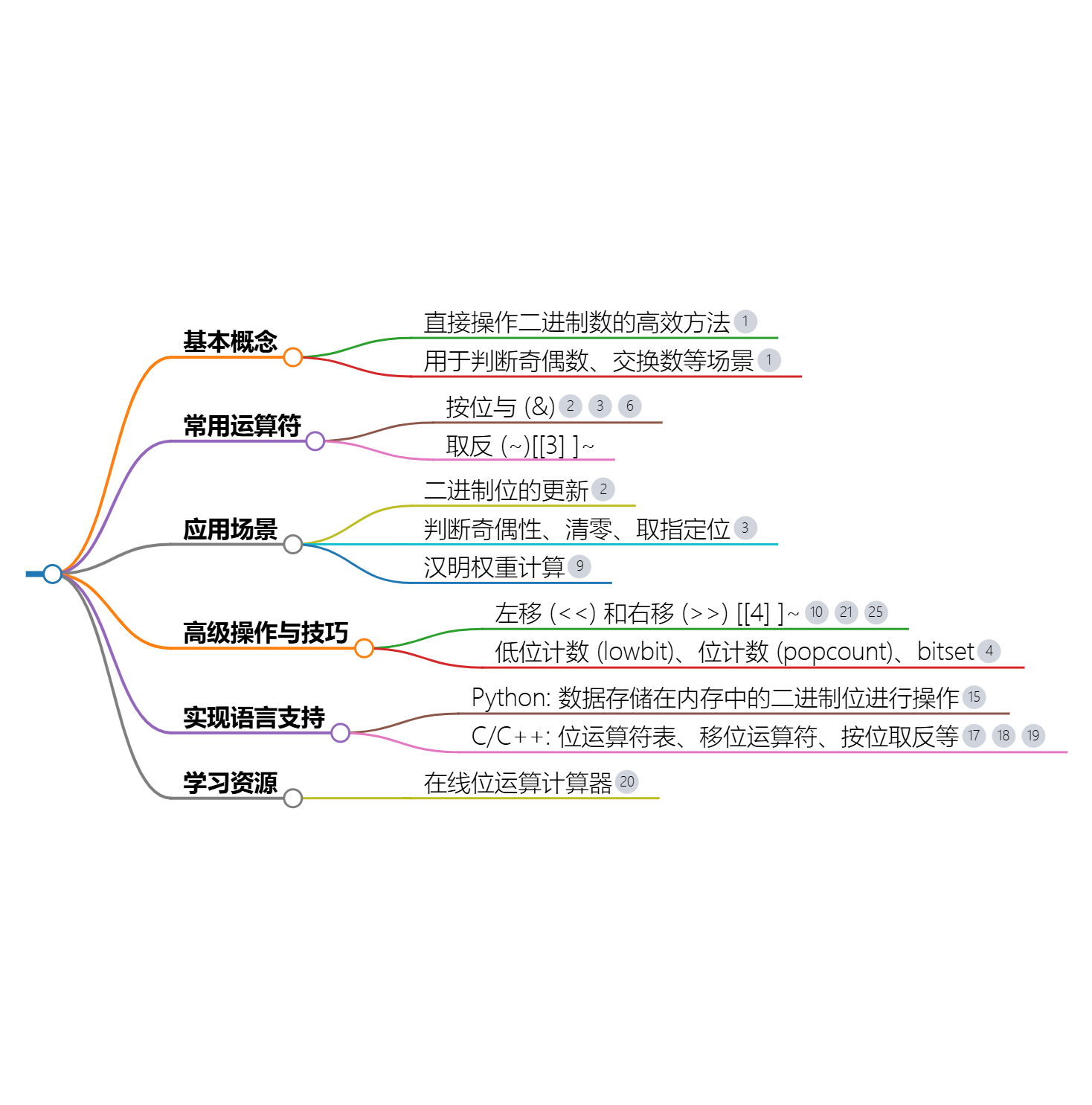
位运算符优先级(从高到低)
- 按位取反(NOT):
~。这是所有位运算符中优先级最高的,它是单目运算符,作用于单个操作数。 - 算术运算符:如加(+)、减(-)、乘(*)、除(/)等。虽然这些不是位运算符,但它们的优先级通常高于大部分位运算符(除了按位取反)。
- 位移运算符:左移(
<<)和右移(>>)。这两个运算符的优先级高于关系运算符和按位与、按位或、按位异或等位运算符,但低于算术运算符。 - 按位与(AND):
&。它用于对两个数的二进制表示进行逐位与操作。 - 按位异或(XOR):
^。它用于对两个数的二进制表示进行逐位异或操作。 - 按位或(OR):
|。它用于对两个数的二进制表示进行逐位或操作。 - 关系运算符:如大于(>)、小于(<)、等于(==)等。这些运算符的优先级低于位移运算符和按位运算符。
注意事项
- 运算符的结合方向:除了按位取反运算符
~的结合方向是自右至左外,其他位运算符的结合方向都是自左至右。 - 优先级可以通过括号
()来改变。在复杂的表达式中,可以使用括号来明确指定运算的顺序。
示例
考虑以下C语言表达式:
int a = 5, b = 3;
int result = ~a & b | b ^ a;
根据优先级规则,这个表达式将按照以下顺序进行计算:
- 首先计算
~a,因为按位取反运算符的优先级最高。 - 然后计算
b ^ a,因为按位异或运算符的优先级高于按位与和按位或。 - 接着计算
~a & b,按位与运算符的优先级高于按位或。 - 最后计算
(~a & b) | (b ^ a),因为按位或运算符的优先级最低。
位运算的使用->奇偶性判断
任何整数的二进制表示中,最低位(即最右边的位)如果是1,则该数是奇数;如果是0,则该数是偶数。
if(n & 1){ //判断奇偶数
cout << "奇数" << endl;
}
else{
cout << "偶数" << endl;
}
if(n>>3 & 1){ //判断n的第四位的奇偶性
cout << "YES" << endl;
}
else{
cout << "NO" << endl;
}
快速幂
快速幂(Fast Exponentiation)算法是一种用于高效计算d形如
a
b
m
o
d
m
a^b \mod m
abmodm 的表达式的方法,其中
a
a
a、
b
b
b 和
m
m
m 是整数,且
b
b
b 可能非常大。该算法通过减少乘法操作的次数来提高效率,其核心思想是利用指数的二进制表示。
算法步骤
- 初始化结果:将结果
result初始化为 1(因为任何数的 0 次方都是 1)。 - 处理底数:将底数
a对模数m取模,以防止a在后续计算中变得过大。 - 循环处理指数:对指数
b进行二进制分解,从最低位到最高位逐位处理。- 如果当前位是 1(即
b为奇数或当前考察的这一位是 1),则将当前的a(或其幂次)乘到result上,并对m取模。 - 将
a平方(即计算 a × a a \times a a×a),并对m取模,为处理下一位做准备。 - 将指数
b右移一位(即b = b >> 1),相当于b除以 2 取整。
- 如果当前位是 1(即
- 返回结果:当指数
b变为 0 时,循环结束,返回result。
C++ 实现
#include<bies/stdc++.h>
using namespace std;
// 快速幂函数,计算 a^b % m
int fastPower(int a, int b, int mod/* 取模 */) {
int result = 1; // 初始化结果为1
a = a % mod; // 将a对m取模
while (b > 0) {
// 如果b的当前位是1,则将当前的a乘到result上
if (b & 1) { // 等价于 if (b % 2 == 1)
result *= a;
result %= mod;
}
// 将a平方,准备处理下一位
a *= a;
a %= mod;
// b右移一位
b >>= 1; // 等价于 b = b / 2;
}
return result;
}
signed main() {
int a, b, m;
cout << "请输入a, b, m(用于计算a^b % m):" << endl;
cin >> a >> b >> m;
cout << "结果是: " << fastPower(a, b, m) << endl;
return 0;
}
在这个实现中,我们使用了位运算 & 来检查 b 的当前最低位是否为 1(即 b % 2 == 1 的位运算等价形式),并使用了右移运算符 >> 来将 b 右移一位(即 b /= 2 的位运算等价形式)。这些位运算通常比相应的算术运算更快,因此在处理大数时更有效率。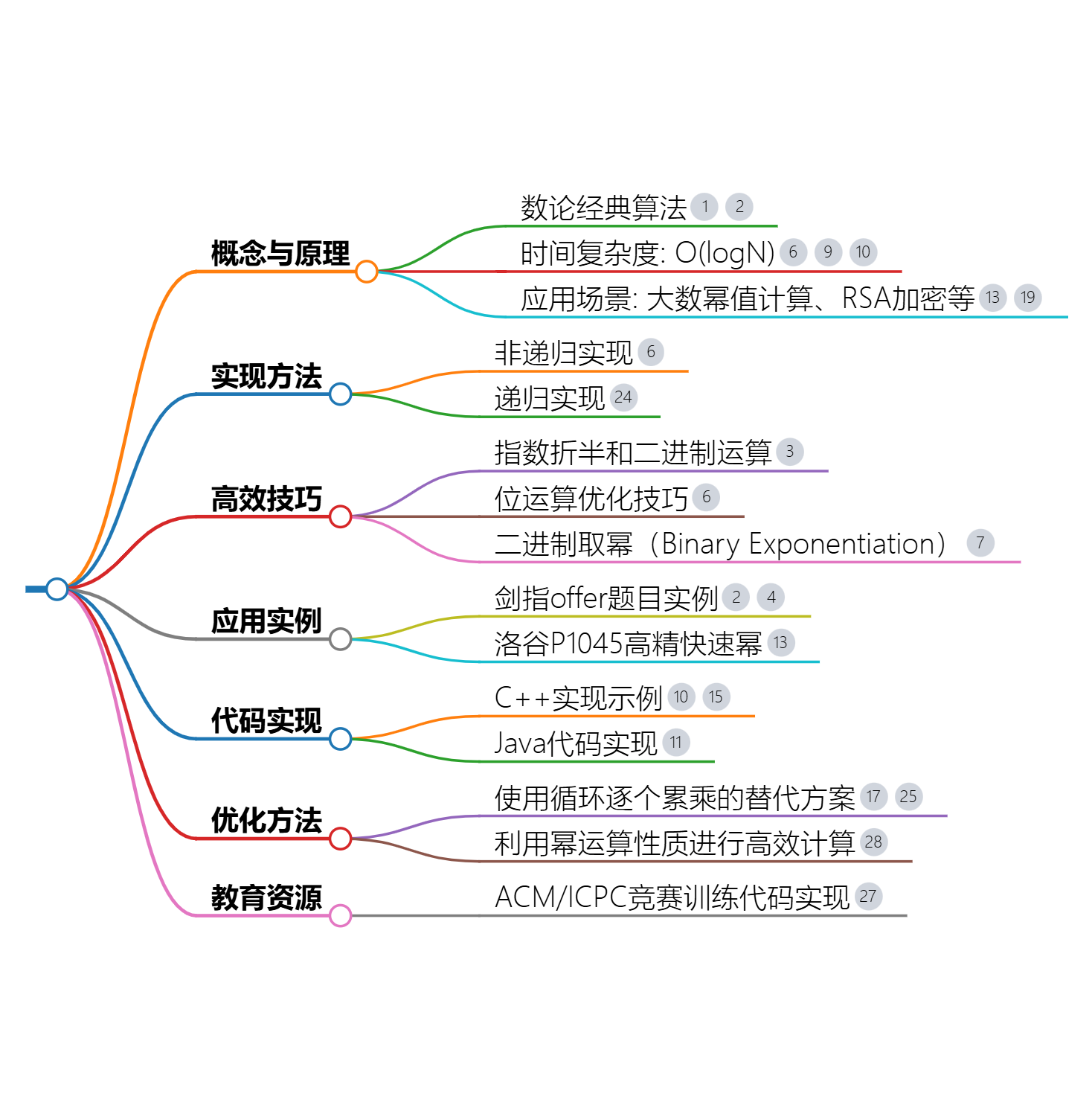
全排列
next_permutation是C++标准模板库(STL)中的一个函数,它用于重新排列给定序列的元素,以生成该序列的下一个字典序排列。
如果序列已经是字典序最大的排列,则该函数将序列重新排列为字典序最小的排列,并返回false表示没有下一个排列;否则,返回true表示成功生成了下一个排列。
基本用法
next_permutation函数的基本用法如下:
#include <algorithm> // 引入next_permutation
// 对于数组
bool next_permutation(It first, It last);
bool next_permutation(It first, It last, Compare comp); // 使用自定义比较函数
// 对于容器(如vector, string等)
bool next_permutation(Container& c);
bool next_permutation(Container& c, Compare comp); // 使用自定义比较函数
其中,It是迭代器类型,Container是容器类型(如std::vector、std::string等),Compare是一个可选的比较函数类型。
使用示例
示例1:数组
#include <iostream>
#include <algorithm>
int main() {
int a[] = {1, 2, 3};
do {
for (int i = 0; i < 3; ++i) {
std::cout << a[i] << ' ';
}
std::cout << '\n';
} while (std::next_permutation(a, a + 3));
return 0;
}
输出将是1 2 3的所有排列。
1 2 3
1 3 2
2 1 3
2 3 1
3 1 2
3 2 1
示例2:vector
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> v = {1, 2, 3};
do {
for (int i = 0; i < v.size(); ++i) {
std::cout << v[i] << ' ';
}
std::cout << '\n';
} while (std::next_permutation(v.begin(), v.end()));
return 0;
}
输出同样是1 2 3的所有排列。
应用场景
next_permutation在多种场景中都非常有用,包括但不限于:
- 排列组合:用于生成某个集合的所有排列。
- 字典序排序:可以按照字典序对集合进行排序。
- 算法优化:在搜索算法中,可以用来遍历状态空间,从而优化算法性能。
- 算法竞赛:在编程竞赛中,常用于解决与排列相关的问题。
- 数学问题:可以用来解决寻找全排列中满足特定条件的排列等数学问题。
总之,next_permutation是C++中处理排列问题的一个强大工具,能够显著提高编码效率和代码的可读性。
分治算法
分治算法(Divide and Conquer Algorithm)是一种非常重要的算法设计策略,它将一个复杂的大问题分解成若干个规模较小的子问题,递归地解决这些子问题,并将子问题的解合并起来,从而得到原问题的解。这种策略在处理大规模数据时特别有效,因为它能够并行地处理多个子问题,从而提高算法的效率。
分治算法的基本步骤
分治算法通常包含三个主要步骤:
- Divide(分):将原问题分解为若干个规模较小、相互独立、与原问题形式相同的子问题。
- Conquer(治):递归地解决这些子问题。如果子问题的规模足够小,则直接解决。
- Merge(合并):将子问题的解合并成原问题的解。
分治算法的特点
- 递归性:分治算法通常通过递归的方式实现,将大问题分解为小问题,再解决小问题。
- 并行性:分治算法可以并行地处理多个子问题,这允许多个CPU或多台计算机同时处理它们,从而提高算法的效率。
- 独立性:子问题之间通常是相互独立的,没有重叠和依赖,这有助于并行处理。
分治算法的应用
分治算法在计算机科学和算法设计中有着广泛的应用,可以解决许多实际问题。以下是一些典型的应用:
- 排序算法:
- 归并排序:递归地将原数组划分为两个子数组,分别进行排序,然后合并两个有序的子数组。
- 快速排序:选择一个基准值,将数组分为两个子数组,分别小于和大于基准值,然后递归地对这两个子数组进行排序。
- 搜索算法:
- 二分搜索:在有序数组中,将搜索区间分成两个子区间,然后递归地在其中一个子区间中进行搜索,直到找到目标元素或者子区间为空。
- 求解最大子数组问题:将数组分成两个子数组,分别求解左右子数组的最大子数组,然后再考虑跨越中点的最大子数组,最后将这三种情况的最大值作为整个数组的最大子数组。
- 矩阵乘法:将两个矩阵分成四个子矩阵,然后递归地进行矩阵乘法,最后将四个子矩阵的结果合并成一个矩阵。
分治算法的优点
- 降低问题复杂度:通过将大问题分解成多个小问题,每个小问题都更容易解决,从而降低了整体的算法复杂度。这通常是通过递归实现的,每一步都将问题规模减半(或其他比例),使得问题更易于处理。
- 并行化潜力:由于分治策略将问题分解为多个独立的子问题,这些子问题可以并行处理。在多核处理器或分布式计算环境中,这种并行性可以显著提高算法的执行效率。
- 结构清晰:分治算法的结构通常非常清晰,遵循“分而治之”的原则,使得算法的设计和实现都更加直观和易于理解。
- 适用性广:分治策略适用于许多类型的问题,包括排序、搜索、图论、字符串处理等多个领域。
分治算法的缺点
- 递归深度:对于某些问题,分治算法可能会产生较深的递归调用栈,这可能会消耗大量的内存资源,甚至导致栈溢出错误。在某些情况下,可能需要通过迭代或其他优化技术来避免这个问题。
- 额外开销:在分解问题和合并解的过程中,可能会产生一些额外的开销。例如,在归并排序中,需要额外的空间来存储临时数组,以便在合并过程中进行元素比较和移动。这些额外开销可能会降低算法的整体效率。
- 子问题依赖性:虽然分治策略通常假设子问题是相互独立的,但在某些情况下,子问题之间可能存在依赖关系。如果忽略这些依赖关系,可能会导致错误的解。因此,在设计分治算法时,需要仔细考虑子问题之间的依赖关系。
- 并行化挑战:虽然分治算法具有潜在的并行性,但在实际实现并行化时可能会遇到一些挑战。例如,如何有效地分配子任务到不同的处理器上、如何处理子任务之间的通信和同步等问题都需要仔细考虑。
- 适用性限制:虽然分治策略适用于许多类型的问题,但并不是所有问题都适合采用分治策略。在某些情况下,可能需要采用其他算法设计策略来解决问题。
样例
//对数组a,下标范围在[ns,ne)的元素进行归并排序
void MergeSort(int*a,int ns,int ne)
{
//1.递归终止条件
//半开区间中只有1个元素,这时一定有序
if(ne-ns==1)
return;
//2.二分法,取中间位置
//对2个子数组进行分开排序
int m=ns+(ne-ns)/2; //取中间位置
MergeSort(a,ns,m); //左半区间归并排序 [ns,m)
MergeSort(a,m,ne); //右半区间归并排序 [m,ne)
//3.合并
//1)依次取出子数组的元素,进行合并
int *ta=new int[ne-ns];//定义一个临时数组
int nl=ns,nr=m; //左半边的子数组和右边的子数组下标
int nt=0; //临时数组的下标
for(;;){
//左半区间[ns,m),右半区间[m,ne)
if(nl>=m || nr>=ne)
break;
if(a[nl]<=a[nr]){ //左边的小
ta[nt]=a[nl]; //取左边元素
nl++; //左半部下标右移
nt++; //临时数组的下标右移
}
else{ //右边的小
ta[nt]=a[nr]; //取右边元素
nr++; //右半部下标右移
nt++; //临时数组的下标右移
}
}
//2)如果左半区间没取完,就放到临时数组
while(nl<m)
ta[nt++]=a[nl++];
//3)如果右半区间没取完,就放到临时数组
while(nr<ne)
ta[nt++]=a[nr++];
//4)临时数组赋值给数组a
for(int i=0;i<ne-ns;i++)
a[ns+i]=ta[i];
//5)释放临时空间
delete[] ta;
}
#include <iostream>
using namespace std;
//对数组a,下标范围在[ns,ne)的元素进行归并排序
void MergeSort(int*a,int ns,int ne);
void print(int*a,int n);
int main()
{
int a[]={4,1,10,15,37,79,24,11,91,
2,18,9,45,21,52,83,98,90};
int n=sizeof(a)/sizeof(*a);
MergeSort(a,0,n);
print(a,n);
return 0;
}
void print(int *a,int n)
{
for(int i=0;i<n;i++)
cout<<a[i]<<" ";
cout<<endl;
}
深度优先搜索
深度优先搜索(Depth-First Search,DFS)和广度优先搜索(Breadth-First Search,BFS,或称为宽度优先搜索)是基本的暴力技术,常用于解决图、树的遍历问题。
DFS通过沿着树的深度尽可能深地搜索树的分支,当节点的所有边都被探寻过之后,回溯到发现该节点的那条边的起始节点。
实现步骤
- 初始化:
- 创建一个标记数组来表示每个节点的访问状态,并进行初始化。通常使用布尔数组或整型数组来记录每个节点是否被访问过。
- 选择数据结构:
- 可以选择递归或栈作为搜索的数据结构。递归是实现DFS的一种简单方式,而栈则适用于需要显式管理路径的情况。
- 搜索过程:
- 从起始节点开始,如果该节点未被访问过,则标记为已访问,并继续对它的第一个未访问的邻接节点进行递归调用或入栈操作。
- 当当前节点没有更多的未访问邻接节点时,回溯到上一个节点,继续对其邻接节点进行相同的操作,直到所有可达节点都被访问过为止。
搜索与回溯
void dfs(int x){
if(x == 0) return;
cout << x << endl;
//向下搜
dfs(x-1);
//回溯
cout << x << endl;
return;
}
全排列
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define endl "\n"
int vis[10010],n;
void dfs(vector<int> g,int cnt){
if(cnt == n){
for(int i = 0 ;i < n; i++){
cout << g[i] << " ";
}
cout << endl;
return;
}
for(int i = 1 ; i <= n; i++){
if(vis[i]) continue;//已经标记就跳过
g.push_back(i);
vis[i] = 1;//标记
dfs(g, cnt + 1);
g.pop_back();
vis[i] = 0;//取消标记
}
}
signed main(){
cin >> n;
dfs({},0);
return 0;
}
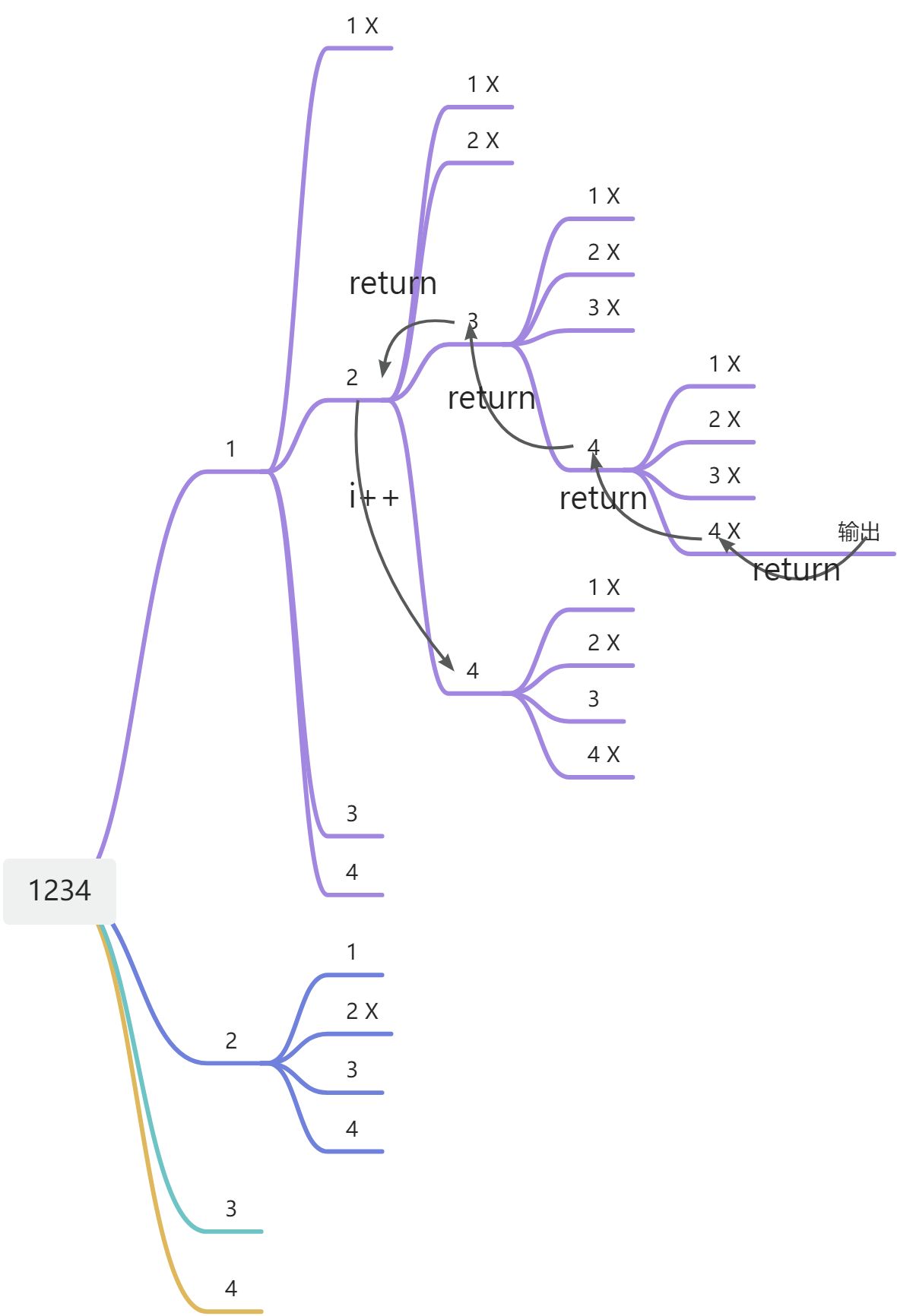
示例代码(递归实现)
#include <iostream>
#include <vector>
using namespace std;
// 定义图的邻接表
vector<vector<int>> graph;
// 标记数组,用于记录节点是否被访问过
vector<bool> visited;
void DFS(int vertex) {
visited[vertex] = true;
cout << vertex << " ";
for (int neighbor : graph[vertex]) {
if (!visited[neighbor]) {
DFS(neighbor);
}
}
}
int main() {
int vertices = 6; // 假设图中有6个顶点
graph.resize (vertices);
visited.resize (vertices, false);
// 添加一些边以构建示例图
graph[0].push_back(1);
graph[0].push_back(2);
graph[1].push_back(3);
graph[2].push_back(4);
graph[2].push_back(5);
graph[4].push_back(5);
cout << "DFS Traversal: ";
DFS(0); // 从顶点0开始遍历
return 0;
}
示例代码(栈实现)
#include <iostream>
#include <vector>
#include <stack>
using namespace std;
// 定义图的邻接表和栈
vector<vector<int>> graph;
stack<int> s;
void DFS(int vertex) {
visited[vertex] = true;
cout << vertex << " ";
for (int neighbor : graph[vertex]) {
if (!visited[neighbor]) {
s.push (neighbor);
}
}
}
int main() {
int vertices = 6; // 假设图中有6个顶点
graph.resize (vertices);
visited.resize (vertices, false);
// 添加一些边以构建示例图
graph[0].push_back(1);
graph[0].push_back(2);
graph[1].push_back(3);
graph[2].push_back(4);
graph[2].push_back(5);
graph[4].push_back(5);
cout << "DFS Traversal (Stack): ";
while (!s.empty ()) {
int currentVertex = s.top ();
s.pop ();
if (!visited[currentVertex]) {
cout << currentVertex << " ";
visited[currentVertex] = true;
for (int neighbor : graph[currentVertex]) {
if (!visited[neighbor]) {
s.push (neighbor);
}
}
}
}
return 0;
}
应用场景
在C++中,深度优先搜索(DFS)和广度优先搜索(BFS)是两种常用的图遍历算法,它们各有优缺点和适用场景。
深度优先搜索(DFS)
特点:
- 内存使用较少:由于DFS是通过递归调用栈来实现的,因此它占用的内存相对较少。
- 速度较慢:由于DFS需要不断回溯,导致其运行速度较慢。
- 适合解决需要找到路径的问题:例如在迷宫游戏中寻找出口路径时,DFS可以有效地找到一条可行路径。
适用场景:
- 图的连通性检测:用于判断一个图是否连通。
- 寻找所有可能的解决方案:例如在解决八数码问题时,DFS可以用来找到所有可能的解决方案。
- 路径查找:如在迷宫游戏中寻找从起点到终点的路径。
广度优先搜索(BFS)
特点:
- 速度快:由于BFS使用队列来保存未被访问的节点,并按层次顺序进行访问,因此其运行速度较快。
- 内存使用较多:由于BFS需要存储更多的节点信息,因此它占用的内存较多。
- 适合解决最短路径问题:在图中寻找从起点到终点的最短路径时,BFS是一个很好的选择。
适用场景:
- 最短路径问题:例如在社交网络中寻找两个用户之间的最短关系链。
- 图的层次遍历:如在树形结构中按层次遍历节点。
- 无回溯操作的需求:在某些情况下,不需要回溯操作,可以直接按层次顺序处理问题。
总结
- DFS适合于内存有限且需要找到路径的情况,但速度较慢。
- BFS适合于需要快速找到最短路径或按层次遍历的情况,但内存使用较多。
深度优先搜索(DFS)在C++中的性能优化技巧有哪些?
在C++中,深度优先搜索(DFS)的性能优化技巧主要包括以下几个方面:
剪枝技术是深度优先搜索中的重要优化手段。通过剪除那些冗余且无效的搜索路径,可以显著减少计算量和时间消耗。例如,在探索过程中,如果发现某个分支不可能导致目标状态,则可以提前终止该分支的进一步探索。
在一些特定的搜索问题中,搜索树的各个层次、各个分支之间的顺序不是固定的。不同的搜索顺序会产生不同的搜索树形态,其规模大小也相差甚远。因此,合理安排搜索顺序可以有效减少搜索空间,提高搜索效率。
迭代加深是一种逐步增加搜索深度的方法。每次选取一个分支进行深入搜索,并不断调整搜索深度以确保找到最优解。这种方法可以在保证找到全局最优解的同时,避免过度深入无效区域。
记忆化搜索通过记录每个状态的搜索结果,在重复遍历一个状态时直接检索并返回结果,从而避免了重复计算。这类似于对图进行深度优先遍历时,标记一个节点是否已经被访问过。记忆化的加强版可以理解为动态规划的一部分。
如何在C++中实现深度优先搜索时处理循环边和自环?
在C++中实现深度优先搜索(DFS)时处理循环边和自环,可以通过记录每个节点的父节点来检测环路。具体步骤如下:
- 初始化:为每个节点设置一个父节点指针,初始时所有节点的父节点都指向
-1或NULL。 - 遍历节点:从根节点开始,递归地访问其子节点。在访问每个子节点时,将当前节点作为其父节点。
- 检测环路:如果在访问某个节点时发现该节点已经存在一个父节点,并且这个父节点不是当前正在访问的节点,则说明存在环路。
以下是一个简单的C++代码示例,展示了如何使用上述方法检测环路:
#include <iostream>
#include <vector>
using namespace std;
// 检测环路的函数
bool detectCycle(vector<vector<int>>& graph, int node, int parent, vector<int>& visited) {
visited[node] = 1; // 标记当前节点已访问
for (int child : graph[node]) {
if (visited[child] == 0) { // 如果子节点未被访问过
if (detectCycle(graph, child, node, visited)) {
return true;
}
} else if (child != parent) { // 如果子节点已被访问且不是父节点,则存在环
return true;
}
}
visited[node] = 2; // 标记当前节点已完全处理
return false;
}
// 主函数
int main() {
int n;
cin >> n;
vector<vector<int>> graph(n);
// 构建图
for (int i = 0; i < n - 1; ++i) {
int u, v;
cin >> u >> v;
graph[u].push_back(v);
graph[v].push_back(u); // 对于无向图
}
vector<int> visited(n, 0); // 初始化访问数组
// 调用检测环路的函数
bool hasCycle = detectCycle(graph, 0, -1, visited);
if (hasCycle) {
cout << "存在环" << endl;
} else {
cout << "不存在环" << endl;
}
return 0;
}
在这个例子中,我们首先读取图的节点数和边,然后构建图的邻接表表示。接着,我们调用detectCycle函数来检测是否存在环。如果存在环,则返回true;否则,返回false。
在C++中实现深度优先搜索时,如何有效地管理和存储访问状态数组以避免内存泄漏?
在C++中实现深度优先搜索(DFS)时,有效地管理和存储访问状态数组以避免内存泄漏的关键在于合理使用数据结构和控制访问状态的范围。根据,我们可以通过一个布尔数组visited[VeNum]来标记每个顶点的访问状态,其中VeNum是图中顶点的数量。当一个顶点被访问时,将其状态设为true,未访问过的顶点则保持false。
为了有效管理内存并避免泄漏,可以采取以下策略:
- 限制搜索深度:正如所述,通过设置一个最大深度限制,当达到该深度时停止搜索,可以减少不必要的内存使用。这不仅有助于控制内存使用,还能提高算法的效率。
- 重用对象:在某些情况下,可以考虑重用已经创建的对象,而不是每次都需要创建新的对象。这可以减少内存分配和释放的次数,从而降低内存泄漏的风险。
- 使用对象池:对象池是一种常见的技术,用于减少频繁创建和销毁对象的开销。通过预先分配一定数量的对象,并在需要时从池中获取,可以有效管理内存使用。
- 避免临时对象:尽量减少临时对象的创建,因为这些对象可能不会被立即销毁,从而导致内存泄漏。可以通过优化代码逻辑,减少不必要的临时变量创建。
- 并行化:对于大规模数据集,可以考虑将搜索任务并行化,以减少单个线程的内存压力。这需要确保数据的一致性和同步机制的正确实现。
- 减少不必要的拷贝:在处理数据结构时,尽量避免不必要的数据拷贝操作。例如,在复制图的邻接表时,可以直接复制指针而不是整个节点。
- 优化数据结构:选择合适的数据结构对于提高内存使用效率至关重要。例如,使用邻接表而不是邻接矩阵来表示图,可以显著减少空间占用。
- 应用剪枝技术:在搜索过程中,通过剪枝技术减少无效路径的探索,可以减少内存使用和计算时间。
- 启发式搜索:在某些问题中,可以使用启发式函数来指导搜索方向,减少无效搜索的次数,从而节省内存和时间。
深度优先搜索在解决实际问题(如网络爬虫、社交网络分析等)中的应用案例有哪些?
深度优先搜索(DFS)在解决实际问题中有着广泛的应用,特别是在网络爬虫和社交网络分析等领域。以下是具体的案例分析:
- 社交网络分析:
- 节点遍历与搜索:在社交网络中,DFS可以用于遍历用户节点,找到特定用户的路径或关系链。
- 关键节点识别与影响力分析:通过DFS算法,可以识别出在网络中具有重要影响力的节点,这对于理解网络结构和进行精准营销等有重要意义。
- 子图发现:DFS还可以用于发现网络中的子图结构,帮助识别紧密连接的群体或社区。
- 网络爬虫:
- 深度优先搜索策略:在实现网络爬虫时,DFS算法可以帮助快速到达目标深度的页面,从而提高爬取效率。
- 递归与非递归实现:DFS可以通过递归和非递归两种形式实现,适应不同的编程需求和场景。
解题集
10 进制转 x 进制
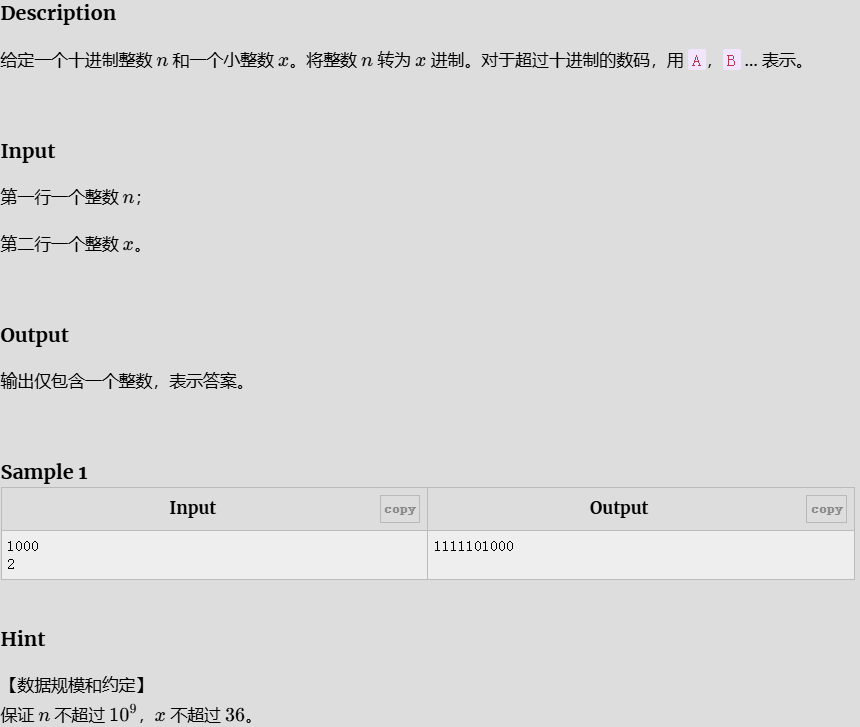
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define endl "\n"
const int N = 1e6 + 10;
const double eps =1e-4;
signed main(){
ios::sync_with_stdio(false);
cin.tie(nullptr);cout.tie(nullptr);
int n, x; cin >> n >> x;
stack<char> s;
while (n > 0) {
int tmp = n % x;
if (tmp >= 10) {
s.push('A' + tmp - 10);
}
else {
s.push('0' + tmp - 0);
}
n /= x;
}
while (!s.empty()) {
cout << s.top();
s.pop();
}
return 0;
}
x 进制转 10 进制
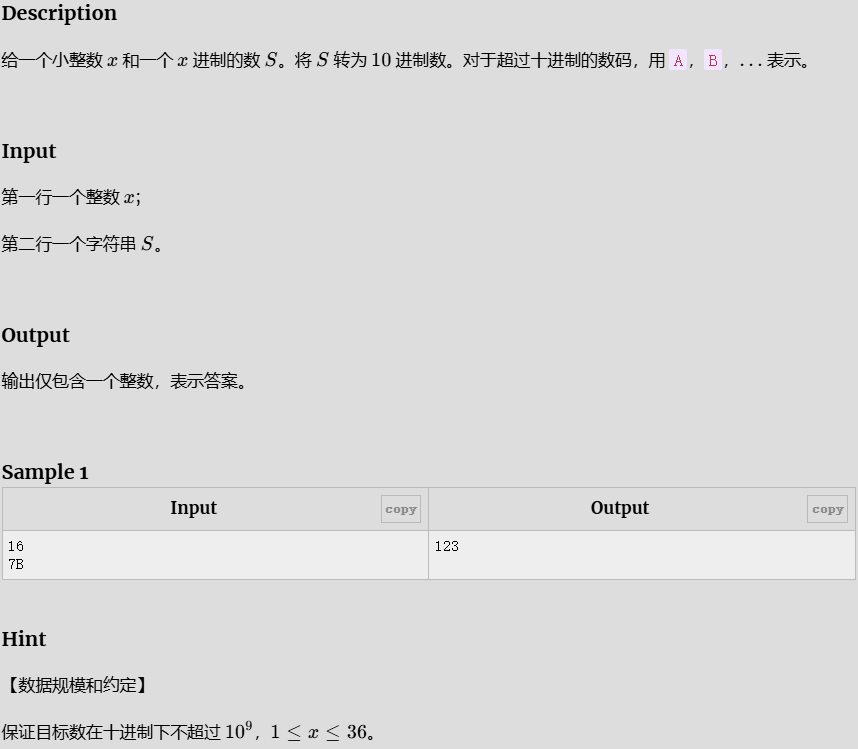
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define endl "\n"
const int N = 1e6 + 10;
const double eps =1e-4;
//int a[N];
//vector <int> a;
signed main(){
ios::sync_with_stdio(false);
cin.tie(nullptr);cout.tie(nullptr);
int n;
string s;
cin >> n >> s;
int sum = 0;
for (char x:s){
sum *= n;
if(x>='A'&&x<='Z'){
sum += (int) (x - 'A' + 10);
}
else
sum += (int)(x - '0');
}
cout << sum << endl;
return 0;
}
快速幂
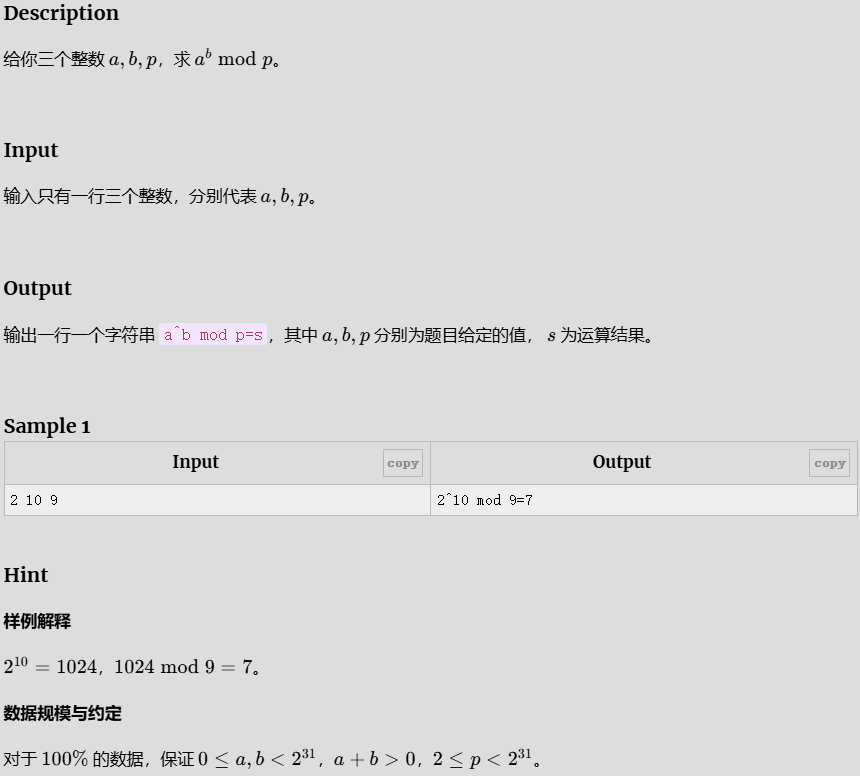
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define endl "\n"
const int N = 1e6 + 10;
const double eps =1e-4;
//int a[N];
//vector <int> a;
int fastPower(int a, int b, int mod/* 取模 */) {
int result = 1; // 初始化结果为1
a = a % mod; // 将a对m取模
while (b > 0) {
// 如果b的当前位是1,则将当前的a乘到result上
if (b & 1) { // 等价于 if (b % 2 == 1)
result *= a;
result %= mod;
}
// 将a平方,准备处理下一位
a *= a;
a %= mod;
// b右移一位
b >>= 1; // 等价于 b = b / 2;
}
return result;
}
signed main() {
int a, b, m;
cin >> a >> b >> m;
printf("%d^%d mod %d=%d", a, b, m, fastPower(a, b, m));
return 0;
}
P1571 眼红的Medusa

//map法
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define endl "\n"
const int N = 1e6 + 10;
const double eps =1e-4;
//int a[N];
//vector <int> a;
int a[N];
map<int, bool> mp;
signed main(){
ios::sync_with_stdio(false);
cin.tie(nullptr);cout.tie(nullptr);
int n, m, b;
cin >> n >> m;
for (int i = 0; i < n; i++){
cin >> a[i];
}
for (int i = 0; i < m; i++){
cin >> b;
mp[b]=true;
}
for (int i = 0; i < n;i++){
if(mp[a[i]]){
cout << a[i] << " ";
}
}
return 0;
}
// 二分法
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define endl "\n"
const int N = 1e6 + 10;
const double eps =1e-4;
int a[N],b[N];
//vector <int> a;
int bin_search(int *a, int n, int x);
signed main(){
ios::sync_with_stdio(false);
cin.tie(nullptr);cout.tie(nullptr);
int n, m;
cin >> n >> m;
for (int i = 0; i < n; i++){
cin >> a[i];
}
for (int i = 0; i < m; i++){
cin >> b[i];
}
sort(b, b + m);
for (int i = 0; i < n; i++){
int x = a[i];
int l = bin_search(b, m, x);
if(x==b[l]){
cout << x << " ";
}
}
return 0;
}
int bin_search(int *a, int n, int x){ //a[0]~a[n-1]是单调递增的
int l = 0, r = n; //注意:不是 n-1
while (l < r) {
int mid = (l + r)/2;
//int mid = (l + r) >> 1;
if (a[mid] >= x) r = mid;
else l = mid + 1;
} //终止于left = right
return l; //特殊情况:a[n-1] < x时,返回n
}
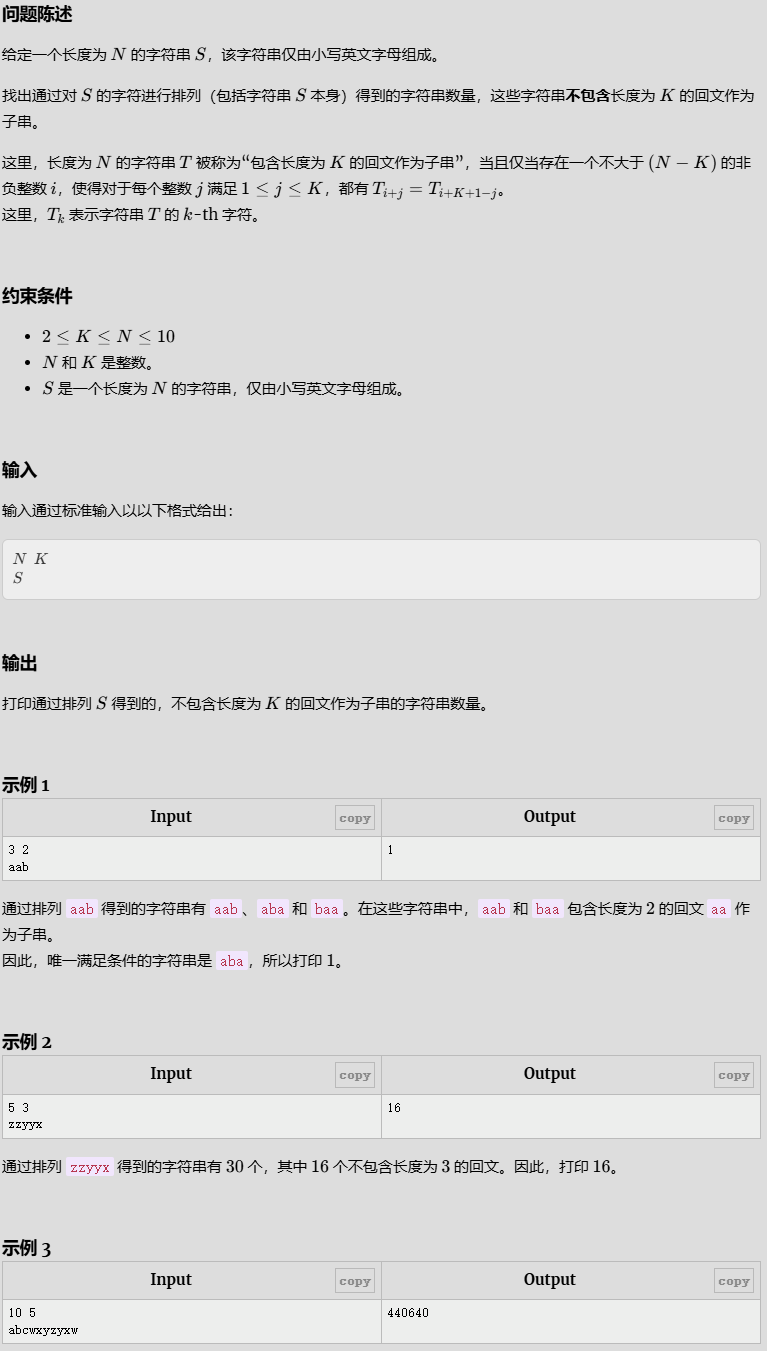
Avoid K Palindrome 2
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define endl "\n"
const int N = 1e6 + 10;
const double eps =1e-4;
char a[N];
//vector <int> a;
signed main(){
ios::sync_with_stdio(false);
cin.tie(nullptr);cout.tie(nullptr);
int n, k;
cin >> n >> k;
for (int i = 0; i < n;i++){
cin >> a[i];
}
sort(a, a + n);
int num = 0;
do{
bool flag = 0;//判断整体有没有回文
for (int i = 0; i < n;i++){//检查字符串中是否有回文
bool flog = 1;//判断这个片段有没有回文
for (int j = i,v=j+k-1; j <= v; j++,v--)//双指针
{
if(a[j]!=a[v]){
flog = 0;
break;
}
}
if(flog){
flag = 1;
break;
}
}
if(!flag)num++;
} while (next_permutation(a, a+n));
cout << num << endl;
return 0;
}
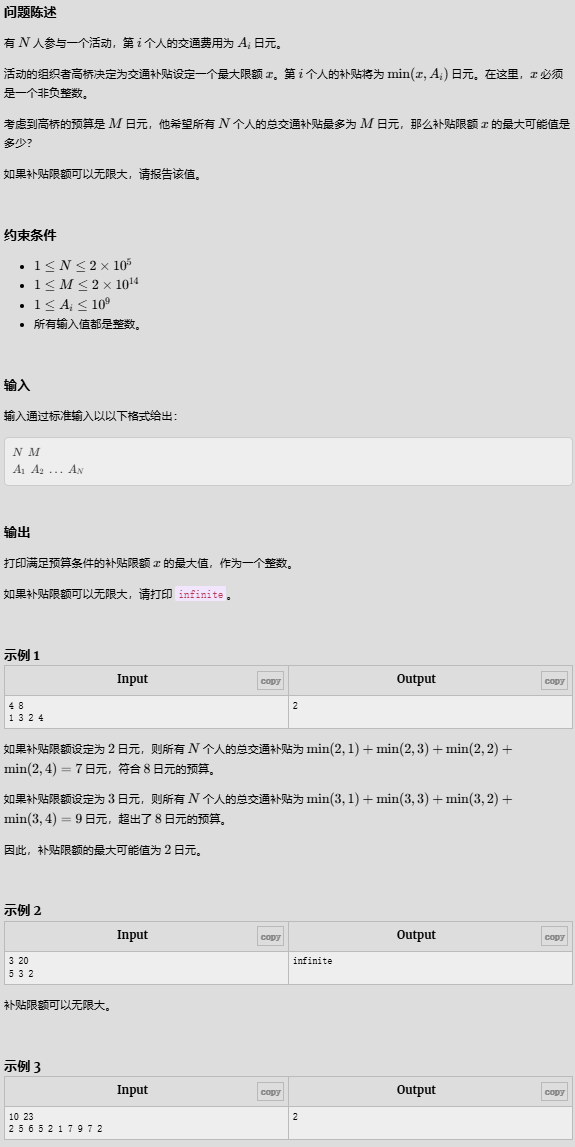
Transportation Expenses
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define endl "\n"
const int N = 1e6 + 10;
const double eps =1e-4;
int a[N];
signed main(){
ios::sync_with_stdio(false);
cin.tie(nullptr);cout.tie(nullptr);
int n, m;
cin >> n >> m;
int sum = 0;
for (int i = 1; i <= n;i++){
cin >> a[i];
sum += a[i];
}
sort(a + 1, a + n + 1);
if(sum<=m){
cout << "infinite" << endl;
return 0;
}
int cnt = m/n;
for (int i = 1; i < n; i++)
{
m -= a[i];
int res = m / (n - i);
cnt = max(cnt, res);
}
cout << cnt << endl;
return 0;
}
外星密码

#include<bits/stdc++.h>
using namespace std;
#define int long long
#define endl "\n"
const int N = 1e6 + 10;
const double eps =1e-4;
//int a[N];
//vector <int> a;
string str;
string rep(string s)
{
int t=0;
for(int i=0;s[i];i++)
{
if(isdigit(s[i]))t=(t<<3)+(t<<1)+(s[i]^48);
else break;
}
string x="",y="";
for(int i=s.size()-1;i>=0;i--)
{
if(isalpha(s[i]))x+=s[i];
else break;
}
reverse(x.begin(),x.end());
while(t--)y+=x;
return y;
}
signed main()
{
cin>>str;
while(true)
{
int l=-1,r=-1;
for(int i=str.size()-1;i>=0;i--)
{
if(str[i]=='[')
{
l=i;
break;
}
}
if(l==-1)break;
for(int i=l;str[i];i++)
{
if(str[i]==']')
{
r=i;
break;
}
}
string ns="";
for(int i=l+1;i<r;i++)ns+=str[i];
str=str.replace(l,r-l+1,rep(ns));
}
cout<<str;
return 0;
}
地毯填补问题
题目描述
相传在一个古老的阿拉伯国家里,有一座宫殿。宫殿里有个四四方方的格子迷宫,国王选择驸马的方法非常特殊,也非常简单:公主就站在其中一个方格子上,只要谁能用地毯将除公主站立的地方外的所有地方盖上,美丽漂亮聪慧的公主就是他的人了。公主这一个方格不能用地毯盖住,毯子的形状有所规定,只能有四种选择(如图):
并且每一方格只能用一层地毯,迷宫的大小为
2
k
×
2
k
2^k\times 2^k
2k×2k 的方形。当然,也不能让公主无限制的在那儿等,对吧?由于你使用的是计算机,所以实现时间为
1
1
1 秒。
输入格式
输入文件共
2
2
2 行。
第一行一个整数
k
k
k,即给定被填补迷宫的大小为
2
k
×
2
k
2^k\times 2^k
2k×2k(
0
<
k
≤
10
0\lt k\leq 10
0<k≤10);
第二行两个整数
x
,
y
x,y
x,y,即给出公主所在方格的坐标(
x
x
x 为行坐标,
y
y
y 为列坐标),
x
x
x 和
y
y
y 之间有一个空格隔开。
输出格式
将迷宫填补完整的方案:每一补(行)为
x
y
c
x\ y\ c
x y c(
x
,
y
x,y
x,y 为毯子拐角的行坐标和列坐标,
c
c
c 为使用毯子的形状,具体见上面的图
1
1
1,毯子形状分别用
1
,
2
,
3
,
4
1,2,3,4
1,2,3,4 表示,
x
,
y
,
c
x,y,c
x,y,c 之间用一个空格隔开)。
样例 #1
样例输入 #1
3
3 3
样例输出 #1
5 5 1
2 2 4
1 1 4
1 4 3
4 1 2
4 4 1
2 7 3
1 5 4
1 8 3
3 6 3
4 8 1
7 2 2
5 1 4
6 3 2
8 1 2
8 4 1
7 7 1
6 6 1
5 8 3
8 5 2
8 8 1
提示
spj 报错代码解释:
- c c c 越界;
- x , y x,y x,y 越界;
- ( x , y ) (x,y) (x,y) 位置已被覆盖;
- ( x , y ) (x,y) (x,y) 位置从未被覆盖。
upd 2023.8.19
\text{upd 2023.8.19}
upd 2023.8.19:增加样例解释。
样例解释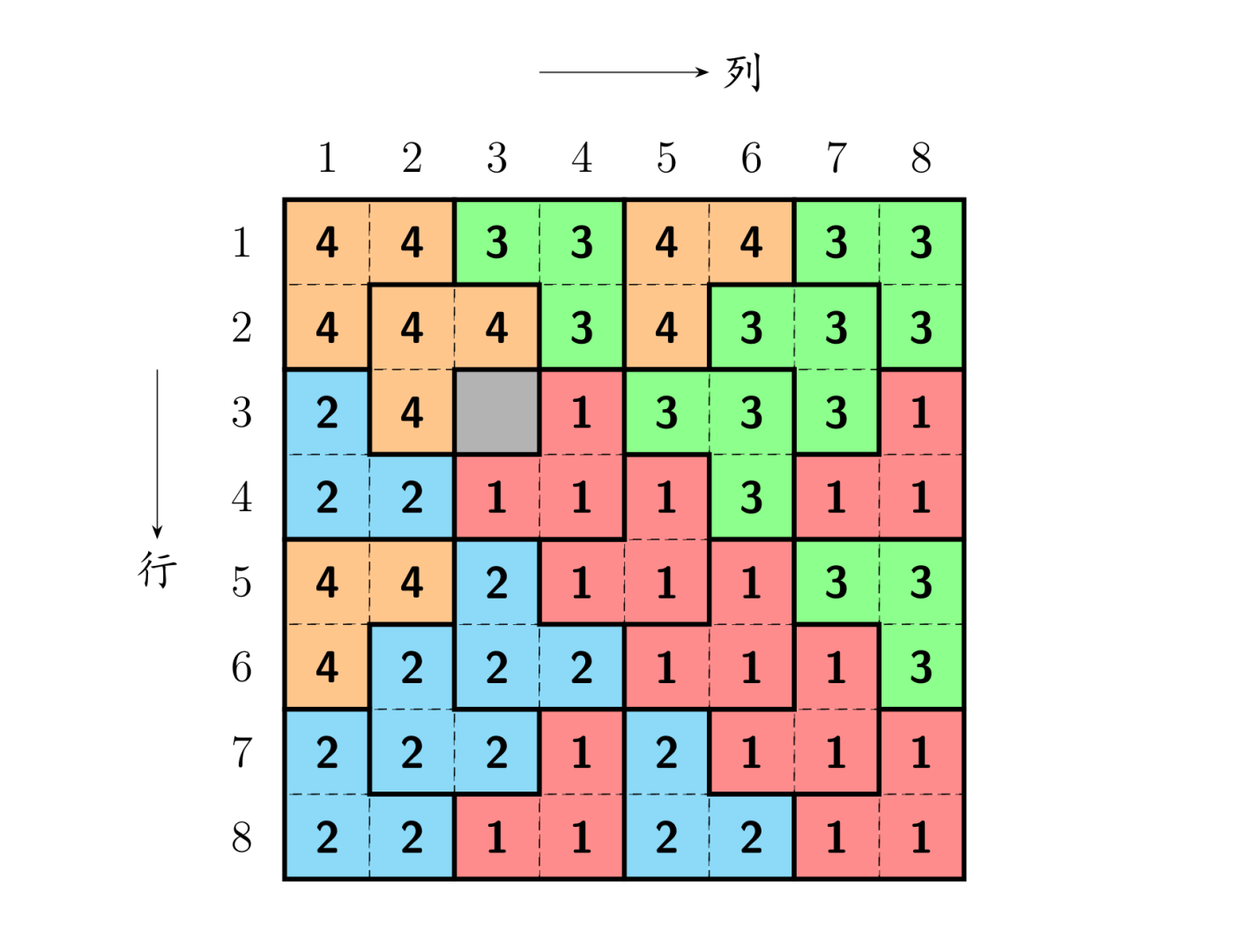
#include<cstdio>
typedef long long ll;
ll x,y,len; int k;
ll fun(int k)
{
ll sum=1;
for(int i=1;i<=k;++i) sum*=2;
return sum;
}
void solve(ll x,ll y,ll a,ll b,ll l)
{
if(l==1) return;
if(x-a<=l/2-1 && y-b<=l/2-1)
{
printf("%lld %lld 1\n",a+l/2,b+l/2);
solve(x,y,a,b,l/2);
solve(a+l/2-1,b+l/2,a,b+l/2,l/2);
solve(a+l/2,b+l/2-1,a+l/2,b,l/2);
solve(a+l/2,b+l/2,a+l/2,b+l/2,l/2);
}
else if(x-a<=l/2-1 && y-b>l/2-1)
{
printf("%lld %lld 2\n",a+l/2,b+l/2-1);
solve(a+l/2-1,b+l/2-1,a,b,l/2);
solve(x,y,a,b+l/2,l/2);
solve(a+l/2,b+l/2-1,a+l/2,b,l/2);
solve(a+l/2,b+l/2,a+l/2,b+l/2,l/2);
}
else if(x-a>l/2-1 && y-b<=l/2-1)
{
printf("%lld %lld 3\n",a+l/2-1,b+l/2);
solve(a+l/2-1,b+l/2-1,a,b,l/2);
solve(a+l/2-1,b+l/2,a,b+l/2,l/2);
solve(x,y,a+l/2,b,l/2);
solve(a+l/2,b+l/2,a+l/2,b+l/2,l/2);
}
else
{
printf("%lld %lld 4\n",a+l/2-1,b+l/2-1);
solve(a+l/2-1,b+l/2-1,a,b,l/2);
solve(a+l/2-1,b+l/2,a,b+l/2,l/2);
solve(a+l/2,b+l/2-1,a+l/2,b,l/2);
solve(x,y,a+l/2,b+l/2,l/2);
}
}
int main()
{
scanf("%d %lld %lld",&k,&x,&y);
len=fun(k);
solve(x,y,1,1,len);
return 0;
}
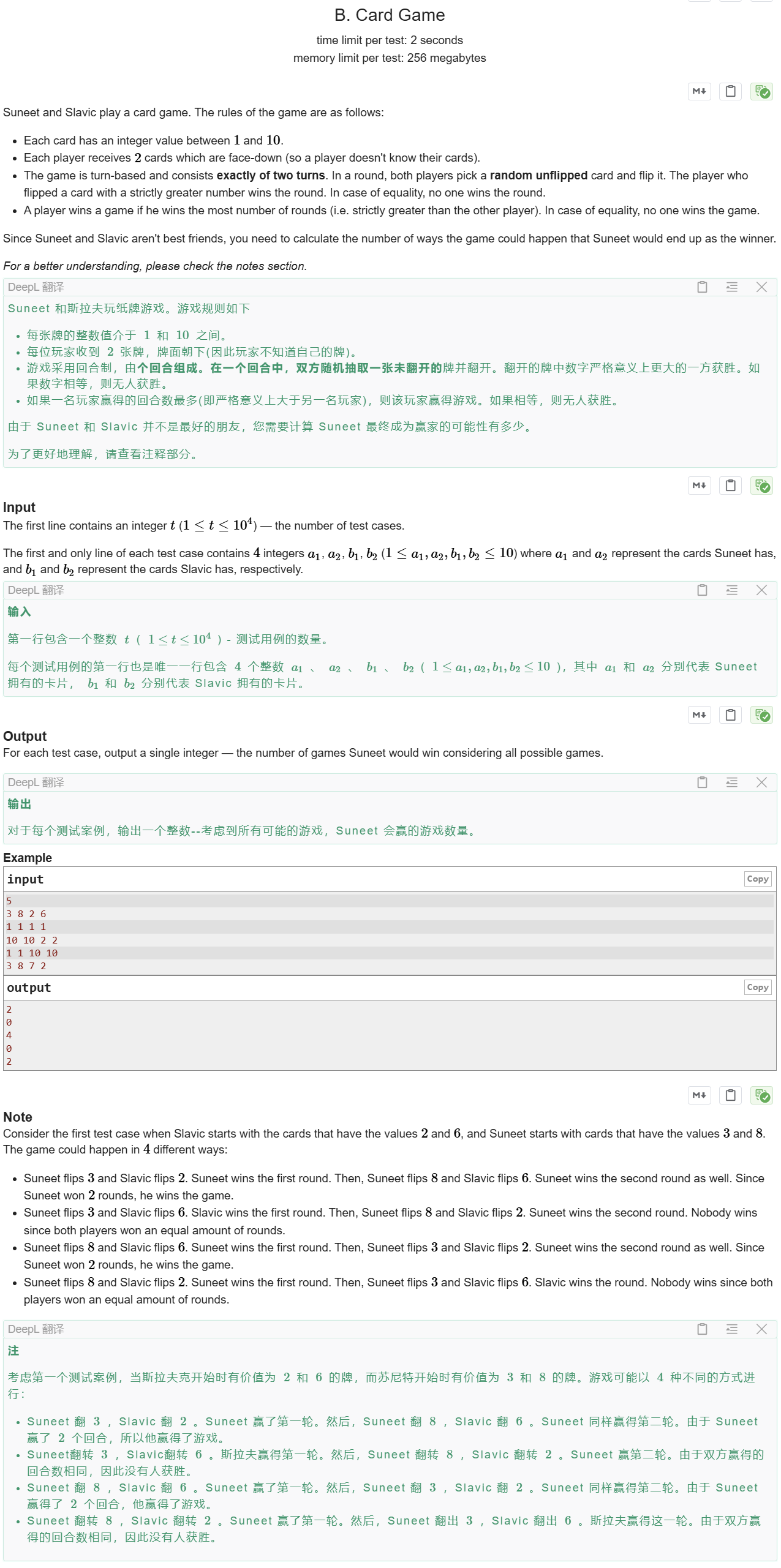
Card Game
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define endl "\n"
const int N = 1e6 + 10;
const double eps =1e-4;
//int a[N];
//vector <int> a;
signed main(){
ios::sync_with_stdio(false);
cin.tie(nullptr);cout.tie(nullptr);
int n;
cin >> n;
for (int i = 0; i < n;i++){
int a1, a2, b1, b2;
cin >> a1 >> a2 >> b1 >> b2;
int cnt = 0;
if(a1>b1&&a2>b2){
cnt++;}
else if(a1==b1&&a2>b2){
cnt++;
}
else if(a1>b1&&a2==b2){
cnt++;
}
if(a1>b2&&a2>b1){
cnt++;
}
else if(a1==b2&&a2>b1){
cnt++;
}
else if(a1>b2&&a2==b1){
cnt++;
}
cout<<cnt*2<<endl;
}
return 0;
}
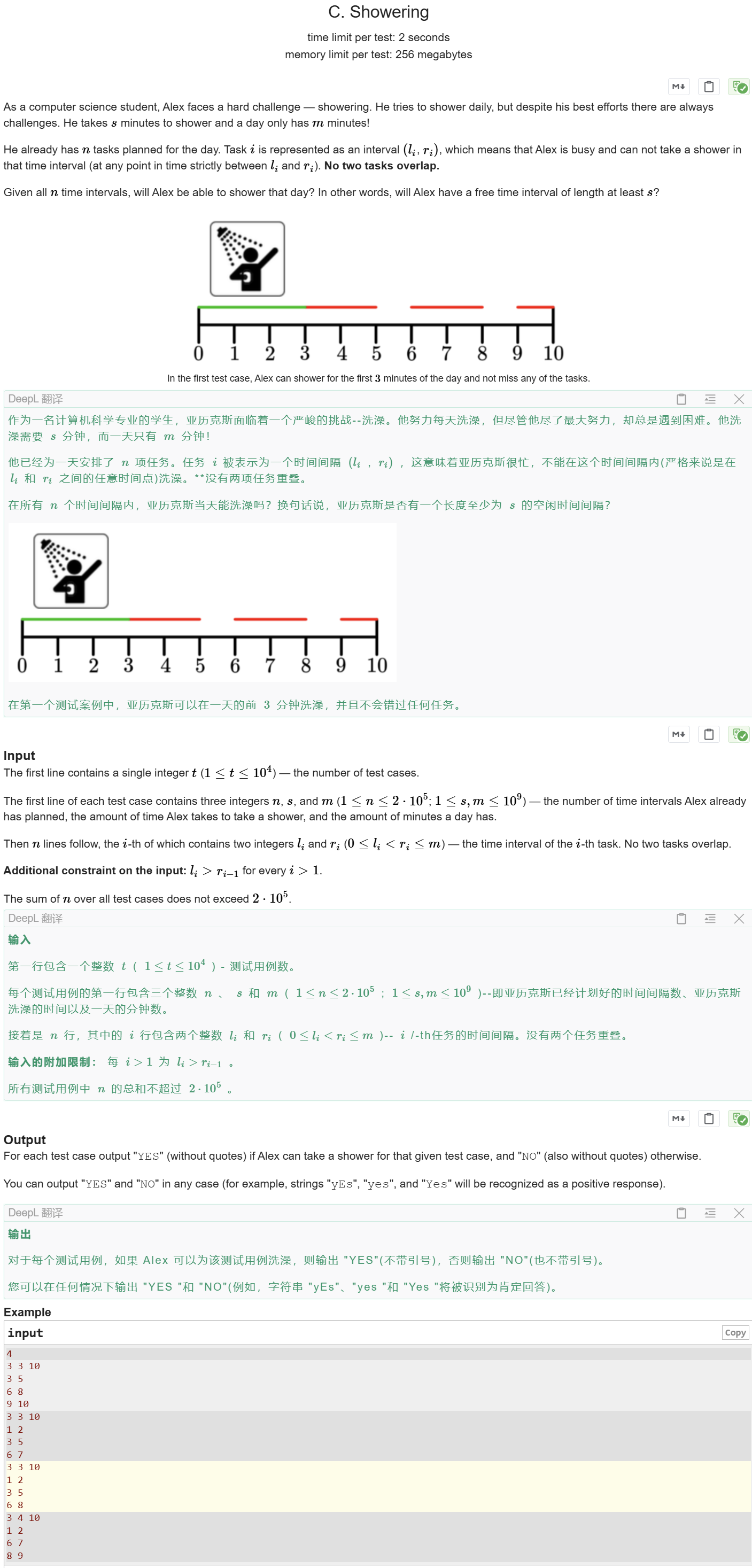
Showering
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define endl "\n"
const int N = 1e6 + 10;
const double eps =1e-4;
int a[N][2];
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);cout.tie(nullptr);
int t; cin >> t;
while (t--) {
int n, s, m; cin >> n >> s >> m;
for (int i = 1; i <= n; i++) {
cin >> a[i][0] >> a[i][1];
}
if (a[1][0] >= s) {
cout << "YES" << "\n"; continue;
}
if (m - a[n][1] >= s) {
cout << "YES" << "\n"; continue;
}
int l = a[1][0], r = a[1][1];
int flag = 0;
for (int i = 2; i <= n; i++) {
if (a[i][0] - r >= s) {
flag = 1; break;
}
l = a[i][0], r = a[i][1];
}
if (flag == 1) {
cout << "YES" << "\n";
}
else {
cout << "NO" << "\n";
}
}
return 0;
}
Slavic’s Exam
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define endl "\n"
const int N = 1e6 + 10;
const double eps =1e-4;
string canFormSubsequence(const string& s, const string& t) {
string result = s; // 复制s到result,以便修改
int j = 0; // t的指针
bool flag = 0;
for (int i = 0; i < result.size() && j < t.size(); ++i) {
if (result[i] == '?' || result[i] == t[j]) {
// 如果result[i]是'?'或者已经匹配上了t[j],则替换'?'为t[j](如果它是'?'的话)
if (result[i] == '?') {
result[i] = t[j];
}
++j; // 移动t的指针
if(j==t.size()){
j = 0;
flag = 1;
}
}
// 如果result[i]不是'?'且不等于t[j],则继续遍历result,不需要替换
}
// 检查是否所有的t中的字符都被匹配了
if (flag) {
return "YES\n" + result;
} else {
return "NO";
}
}
signed main() {
int T;
cin >> T;
cin.ignore(); // 忽略T后面的换行符
while (T--) {
string s, t;
getline(cin, s); // 读取整行作为s
getline(cin, t); // 读取整行作为t
cout << canFormSubsequence(s, t) << endl;
}
return 0;
}
小雷的算式
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define endl "\n"
const int N = 1e6 + 10;
const double eps =1e-4;
// int a[N];
vector <int> a;
bool cmp(int a, int b){
return a > b;
}
signed main(){
ios::sync_with_stdio(false);
cin.tie(nullptr);cout.tie(nullptr);
string s;
getline(cin, s);
int cnt = 0, sum = 0;
for (int i = 0; i < s.size();i++)
{
char x = s[i];
if(x>='0'&&x<='9'){
cnt = cnt * 10 + (int)(x - '0');
}
if(x=='+'||i == s.size()-1){
a.push_back(cnt);
sum += cnt;
cnt = 0;
}
}
int len = a.size();
sort(a.begin(), a.end(),cmp);
for (int i = 0; i < a.size(); i++)
{
cout << a[i] << (i < (len - 1) ? "+" : "\n");
}
cout << sum << endl;
return 0;
}
聪明且狡猾的恶魔
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define endl "\n"
const int N = 1e6 + 10;
const double eps =1e-4;
//int a[N];
//vector <int> a;
signed main(){
ios::sync_with_stdio(false);
cin.tie(nullptr);cout.tie(nullptr);
int t;
cin >> t;
while(t--){
int x, n;
cin >> x >> n;
int num1 = (n-1) / 2;
x -= num1;
cout << x << endl;
}
return 0;
}
小雷的神奇电脑
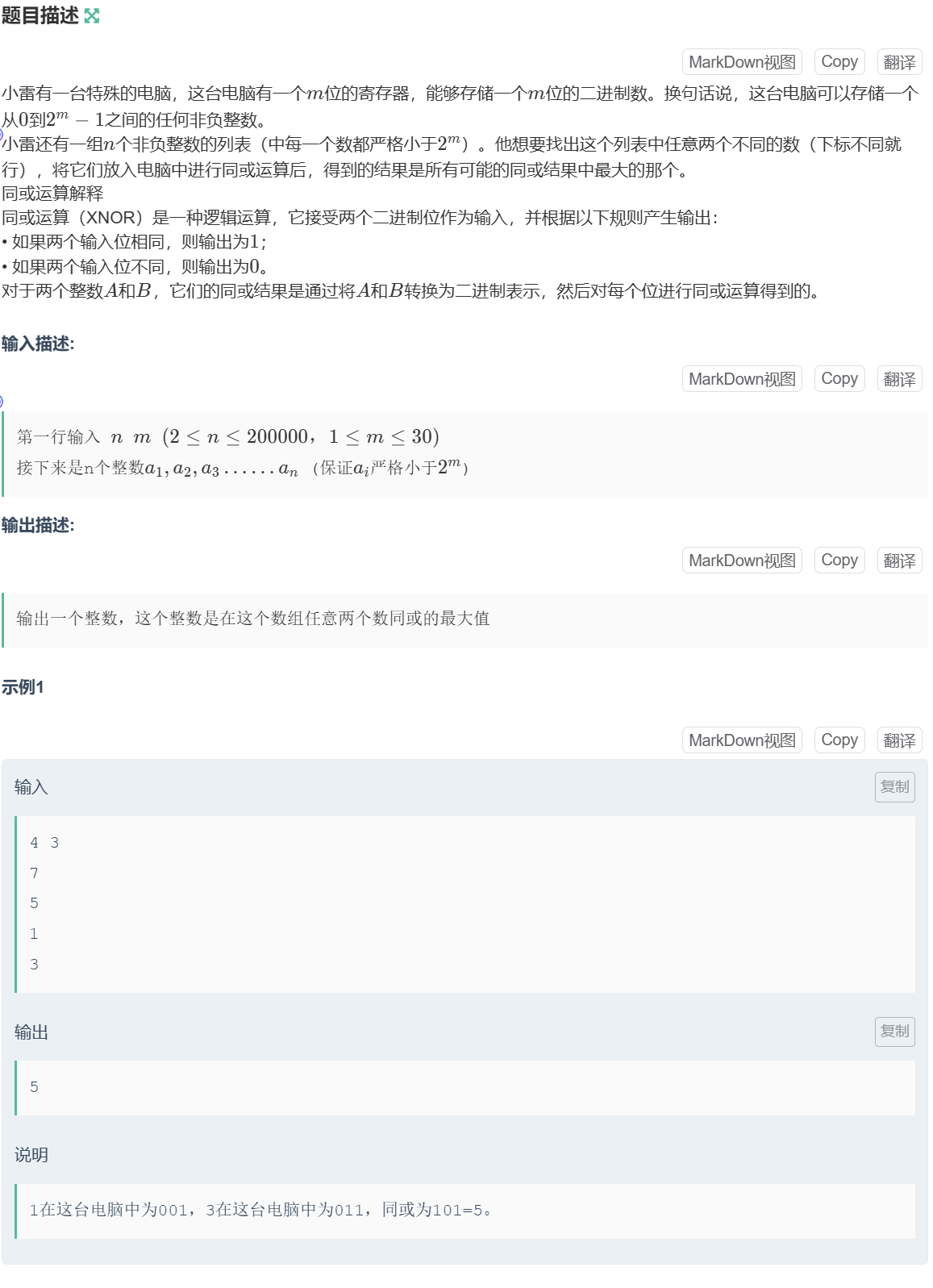
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define P pair<int,int>
const int mod = 1e9 + 7, inf = 1e17;
void run(){
int n, m;
cin >> n >> m;
vector<int> a(n);
for(int i=0;i<n;i++){
cin >> a[i];
}
sort(a.begin(), a.end());
int ans = 0, res = (1ll << m) - 1;
for(int i=0;i<n-1;i++){
ans = max(ans,res - (a[i] ^ a[i + 1]));
}
cout << ans << '\n';
}
signed main(){
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
int T = 1;
// cin >> T;
while(T --) run(); return 0;
}
N皇后问题

思路
两个坐标是否为对角线
(x1,y1) ,(x2,y2)
- x1 - y1 == x2 - y2 ?
- x1 + y1 == x2 + y2 ?
#include<bits/stdc++.h>
#include<iostream>
#include<vector>
#include<cstdlib>
#include<stdio.h>
using namespace std;
#define int long long
#define endl "\n"
#define vll vector<long long>
#define fi first
#define se second
#define pub push_back
#define pob pop_back
const int N = 1e6 + 10;
const double eps =1e-4;
const int mod1 = 998244353;
const int maxlen = 11;
int n;//N <= maxlen;
vector<int> tm;//存储皇后的列坐标
//输出每种可能下的每个皇后的列坐标
int vis[maxlen][maxlen] = { 0 };
int cnt = 0;
int CNT = 0;
bool flag = 0;
void doAdd(int r, int c, int n, int val) {//标记(坐标,边界,标记数)
if (r < 0 || r >= n) {
return;
}
if (c < 0 || c >= n) {
return;
}
vis[r][c] += val;
}
void add(int r, int c, int n, int val) {//这种二维打标记的方法真的很nice
int i;
for (int i = 0; i < n; i++) {
doAdd(r, i, n, val);//行全标记
doAdd(i, c, n, val);//列全标记
}
for (int i = 0; i < n; i++) {//对角线标记
doAdd(r + i, c + i, n, val);//右下
doAdd(r - i, c - i, n, val);//左上
doAdd(r + i, c - i, n, val);//左上
doAdd(r - i, c + i, n, val);//右下
}
}
void dfs(int dep, int maxdep) {
int i;
if (dep == maxdep) {//到底了
cnt++;
if (!tm.empty()) {
for (auto x : tm) {
printf("%5d", x);//输出格式
}
flag = 1;//存在
cout << endl;
}
return;
}
for (i = 0; i < maxdep; i++) {
if (vis[dep][i] == 0) {
tm.push_back(i + 1);
add(dep, i, maxdep, 1);//标记
dfs(dep + 1, maxdep);
tm.pop_back();
add(dep, i, maxdep, -1);
}
}
}
signed main() {
cin >> n;
dfs(0, n);
if (!flag) {
cout << "no solute!" << endl;
}
}
拆分自然数
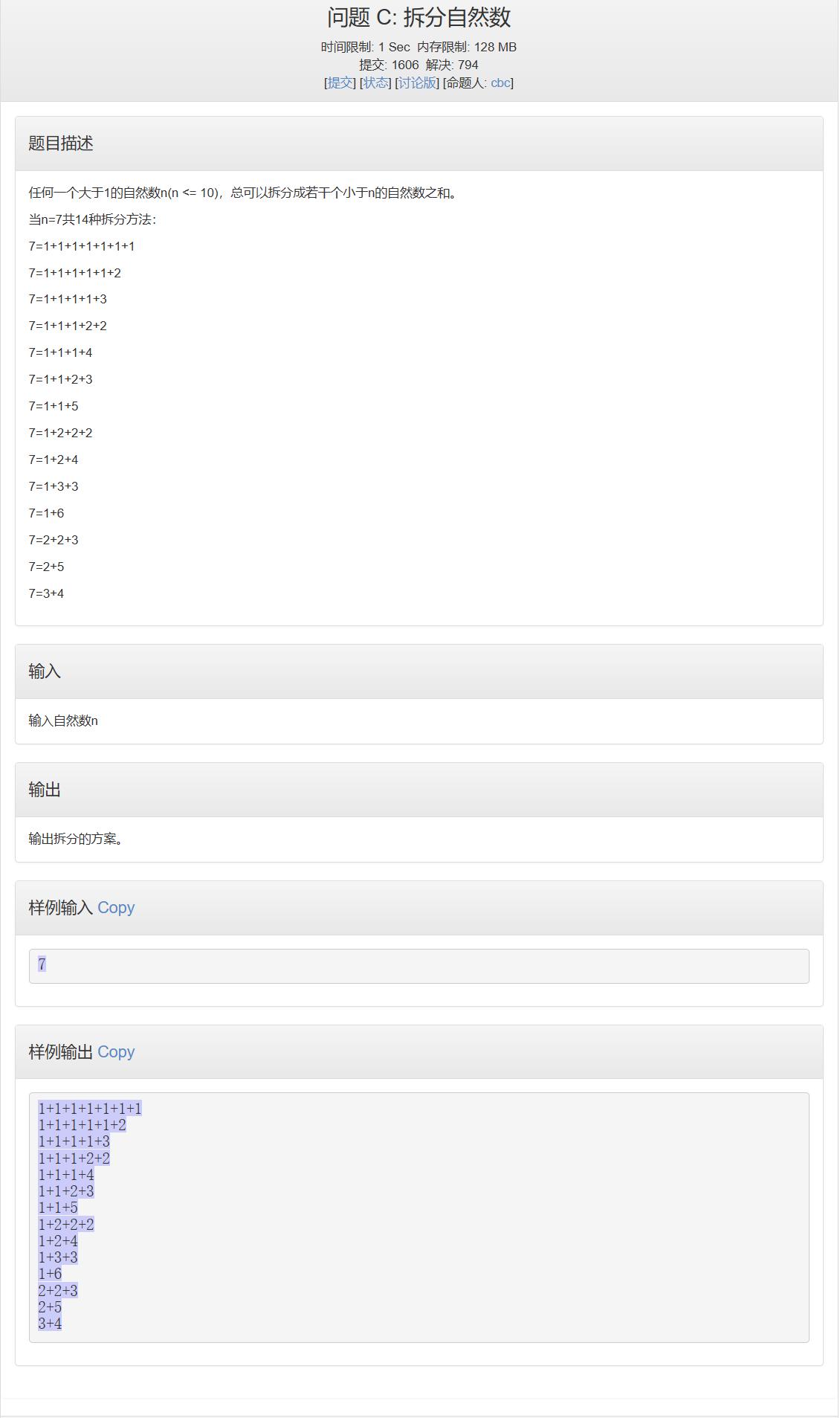
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define endl "\n"
#define vll vector<long long>
const int N = 1e6 + 10;
const double eps =1e-4;
const int mod1 = 998244353;
//int a[N];
//vll a;
int n;
void dfs(int x, int mx, vll g){
if(x==n){
if (g.size()<=1)
{
return;//免掉最后一个单数
}
for (int i = 0; i < g.size(); i++)
{
cout << g[i] << "+\n"[i == g.size() - 1];
}
return;
}
for (int i = 1; i <= n; i++)
{
if (x + i > n || i < mx) continue;//比前面的数大
g.push_back(i);
dfs(x + i, i, g);
g.pop_back();
}
}
signed main(){
ios::sync_with_stdio(false);
cin.tie(nullptr);cout.tie(nullptr);
cin >> n;
dfs(0, 0, {});
return 0;
}
8连通迷宫
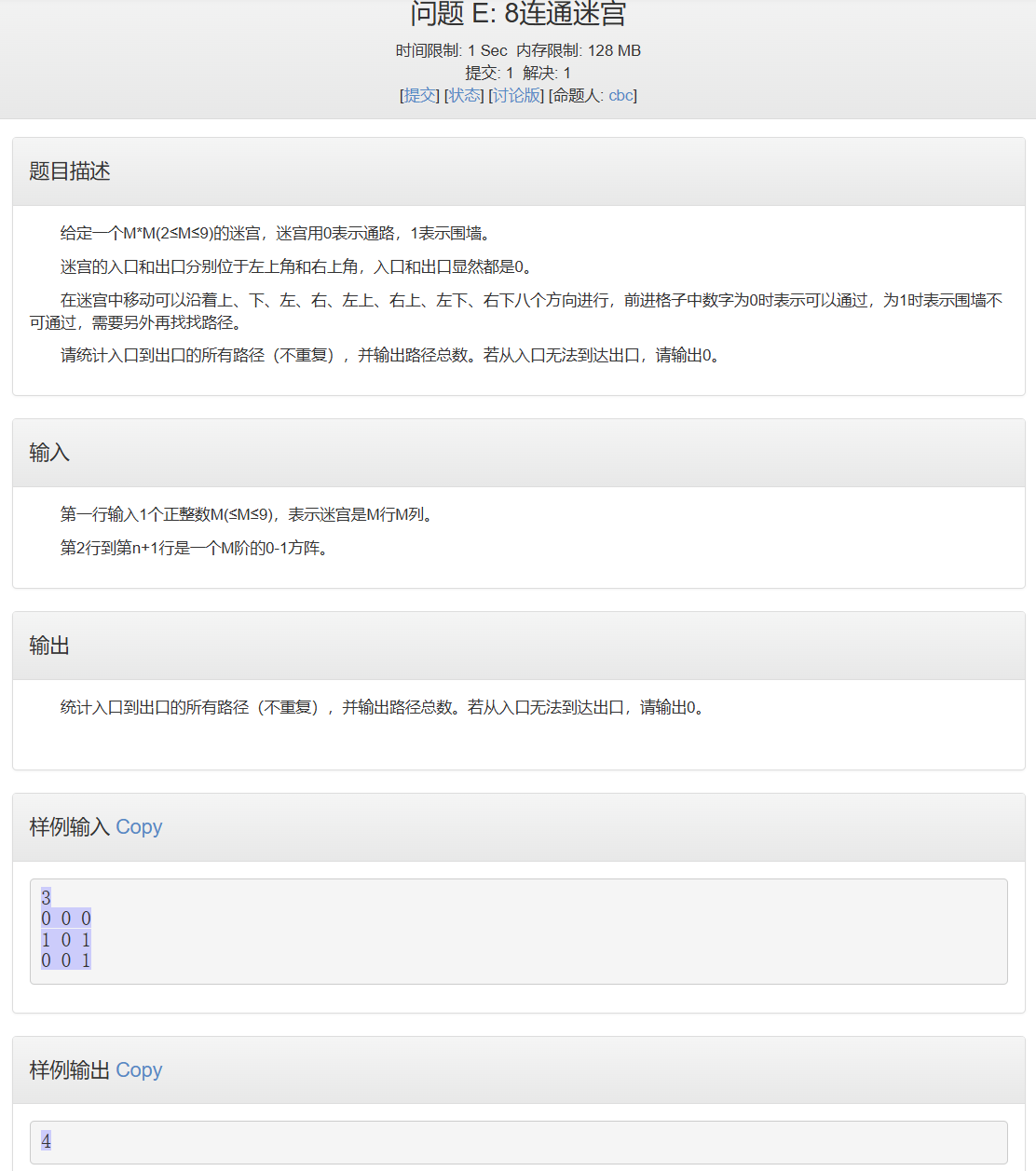
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define endl "\n"
const int N = 1e6 + 10;
const double eps =1e-4;
const int mod1 = 998244353;
//8连走迷宫
//迷宫的入口和出口分别位于左上角和右上角
int a[1000][1000],vis[1000][1000];
int n,ans;
//上下左右八方向移动
int dx[] = {0, 0, 1, -1, 1, 1, -1, -1};
int dy[] = {1, -1, 0, 0, 1, -1, 1, -1};
void dfs(int x,int y){
if (x == 1 && y == n){//出口
ans ++;
return;
}
for (int i = 0; i < 8; i++){
int xt = x + dx[i];
int yt = y + dy[i];
if (a[xt][yt] == 1 || vis[xt][yt] == 1 || xt < 1 || yt < 1 || xt > n || yt > n) continue;
vis[xt][yt] = 1;
dfs(xt, yt);
vis[xt][yt] = 0;
}
}
signed main(){
ios::sync_with_stdio(false);
cin.tie(nullptr);cout.tie(nullptr);
cin >> n;
for (int i = 1; i <= n; i++){
for (int j = 1; j <= n; j++){
cin >> a[i][j];
}
}
vis[1][1] = 1;
dfs(1, 1);
cout << ans << endl;
return 0;
}















 7911
7911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









