






详解tensorRT的高性能部署方案,并附有强大的yolov5、yolox、retinaface、arcface、scrfd、deepsort、alphapose的高性能实现,低耦合,哪来即可用,集成到项目中 repo地址:https://github.com/shouxieai/tensorRT_cpp YoloX-m@640x640 fp16@2080Ti性能:2.54ms / image, 每秒393.54帧
第1章 tensorRT介绍
1.1 tensorRt是什么
答:是:nvdia发布的dnn推理加速引擎。
tensorRT:nvdia发布的dnn推理加速引擎,是针对nvdia系列硬件进行优化加速、实现最大程度的利用GPU资源,提升推理性能。
1.2 tensorrt 方案介绍
Tensorrt构建模型的形式,即需要告知它你模型的架构和权重。那tensorRT提供基于C++接口和Python 接口的构建方案。那tensorrt各个版本有接口说明。通过api 你告诉它你模型需要的参数,结构,权重。
Tensorrt 提供的基础api 接口让你实现加速推理。为了方便起见,他们也提供更高级的使用方式,就是说你只需要把你的模型转换成onnx,它就可以直接转换成tensorrt的API.就是直接调用api,实现整个引擎的编译。
下面是3种常见路径。
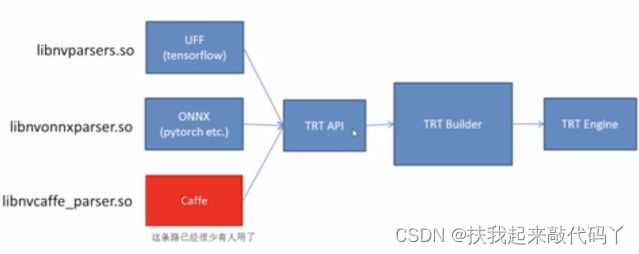
Pytorch 到onnx 是pytorch 维护,也就是有新算子出来由官方维护。 Onnx到engine是 nvdia 来维护,即libnvonnxparser.so不断更新。
那编译也是很简单,就一句话。


第2章:使用TensorRT 的深度学习开发流程:
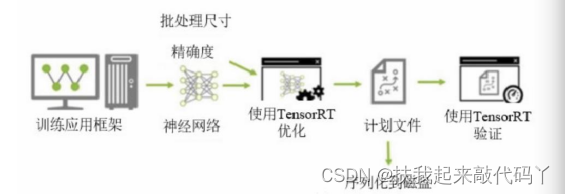
首先需要先训练深度学习网络框架,训练后会生成一个神经网络模型,然后可以指定 Batch-Size 和Precision 使用 TensorRT 进行优化,就是会得到一个优化后的推理引擎,将其序列化到磁盘,在使用时先进行反序列化,之后进行推理验证。
第3章 tensorrt加速优化原理
TensorRT能够加速的原因主要有两点,一方面是支持INT8和FP16的计算;另一方面是对网络结构进行了重构和优化
3.1 TensorRT支持INT8和FP16的计算
深度学习网络在训练时,通常使用 32 位或 16 位数据。TensorRT支持kFLOAT(float32)、kHALF(float16)、kINT8(int8)三种精度的计算,在使用时通过低精度进行网络推理,达到加速的目的。
3.2 TensorRT对网络结构进行了重构和优化
TensorRT对网络结构进行重构,把一些能合并的运算合并在一起,根据GPU的特性做了优化。具体表现在下面4个方面。
1 tensorRT通过解析网络模型将网络中无用的输出层消除以减小计算。
2对于网络结构的垂直整合,即将目前主流神经网络的conv、BN、Relu三个层融合为了一个层,例如将下图1所示的常见的Inception结构重构为图2所示的网络结构。
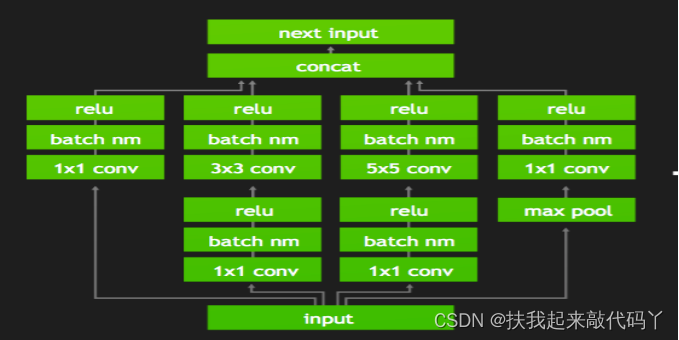
- 对网络的水平组合,水平组合是指将输入为相同张量和执行相同操作的层融合一起,如图2向图3的转化。

4去掉 concat 层,将原需输入 contact 层的直接送入 concat 下一级的操作中,不再单独进行 concat 步骤,相当于减少了一次传输吞吐量去掉concat层(
TensorRT中使用了一个新的操作——Concatenation操作来代替原有的concat层。Concatenation操作实现了多个tensor的拼接,但是采用了更加高效的实现方式,可以有效地减少计算和内存的占用,提高推理的速度和效率。
在TensorRT中,Concatenation操作可以对多个输入tensor进行拼接,并且可以指定拼接的维度,可以实现灵活的拼接操作。同时,TensorRT还支持对Concatenation操作进行多种优化,例如采用分块处理的方式,减少内存占用;采用流水线处理的方式,提高计算效率等等。这些优化可以进一步提高Concatenation操作的效率和性能。
。)
第4章Yolov5 使用tensorrt 部署步骤
4.1 定义

1网络定义是指 TensorRT 中模型的表示。网络定义是张量和运算符的图;
2编译:是指 TensorRT 的模型优化器。构建器将网络定义作为输入,执行与设备无关和针对特定设备的优化,并创建引擎engine.
3 引擎是指由 TensorRT 构建器优化的模型的表示;
4 运行是指 TensorRT 的组件,可在 TensorRT 引擎上执行推理。
4.2模型转换代码解析
4.3 你部署过程中遇到的问题
第5章 部署方案
硬件:基于 jeston tx2 开发板下,进行基于tensorrt 加速部署。
软件:TensorRT + C++的部署方式不仅能过在网络模型方面获得推理加速,而且由于 C++是更偏向底层的语言,因此还能获得语言层面的加速
- 加速实验对比
使用pt 模型速度:

使用engine模型加速后:
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









