









提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
UNet是一种广泛用于图像分割任务的卷积神经网络,适用于需要精确定位和多尺度特征提取的任务,例如医学图像分割。
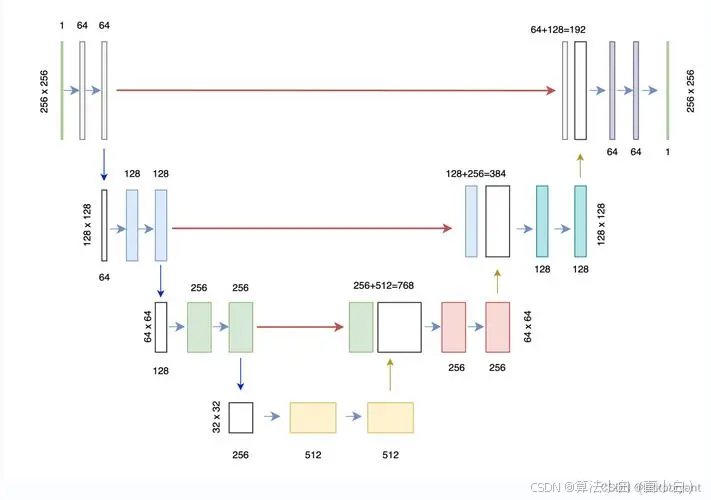

一、带有VGG块的UNet网络结构
class VGGBlock(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super().__init__()
self.relu = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(in_channels, middle_channels, 3, padding=1)
self.bn1 = nn.BatchNorm2d(middle_channels)
self.conv2 = nn.Conv2d(middle_channels, out_channels, 3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
return out
class UNet(nn.Module):
def __init__(self, num_classes, input_channels=3, **kwargs):
super().__init__()
nb_filter = [32, 64, 128, 256, 512]
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)#scale_factor:放大的倍数 插值
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1])
self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2])
self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3])
self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4])
self.conv3_1 = VGGBlock(nb_filter[3]+nb_filter[4], nb_filter[3], nb_filter[3])
self.conv2_2 = VGGBlock(nb_filter[2]+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv1_3 = VGGBlock(nb_filter[1]+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv0_4 = VGGBlock(nb_filter[0]+nb_filter[1], nb_filter[0], nb_filter[0])
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def forward(self, input):
x0_0 = self.conv0_0(input)
x1_0 = self.conv1_0(self.pool(x0_0))
x2_0 = self.conv2_0(self.pool(x1_0))
x3_0 = self.conv3_0(self.pool(x2_0))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)], 1))
x2_2 = self.conv2_2(torch.cat([x2_0, self.up(x3_1)], 1))
x1_3 = self.conv1_3(torch.cat([x1_0, self.up(x2_2)], 1))
x0_4 = self.conv0_4(torch.cat([x0_0, self.up(x1_3)], 1))
output = self.final(x0_4)
return output
VGGBlock类
VGGBlock类定义了一个简单的卷积块,由两个卷积层、批量归一化层(Batch Normalization)和ReLU激活函数组成。具体结构如下:
- conv1: 首先对输入进行卷积操作,使用了3x3的卷积核,并通过
padding=1保证卷积前后的图像尺寸不变。 - bn1: 对卷积后的输出进行批量归一化,提升训练的稳定性。
- ReLU激活: 使用ReLU激活函数引入非线性,提高网络的表达能力。
- conv2: 进行第二次卷积操作。
- bn2: 对第二次卷积的结果进行批量归一化。
- ReLU激活: 再次通过ReLU激活函数。
UNet类
UNet类定义了一个基于VGGBlock的UNet模型。UNet模型通常用于需要高分辨率输出的任务,通过编码器(下采样)和解码器(上采样)进行逐步的特征提取和恢复。以下是各部分的作用:
-
编码器部分:
- 由五个
VGGBlock组成的卷积层,分别对输入进行不同深度的特征提取。 pool操作用于对特征图进行下采样,每次将图像尺寸缩小一半。- 五个卷积层的特征通道分别为32、64、128、256和512,对应更深层的特征。
- 由五个
-
解码器部分:
- 通过
Upsample进行上采样,恢复特征图的空间分辨率,使用bilinear插值。 - 在上采样后的特征图与对应深度的编码特征进行拼接(
torch.cat),保证解码过程可以利用编码器中提取到的高分辨率信息。 - 解码器中也使用
VGGBlock进行卷积处理,特征通道逐渐减少,逐步恢复图像。
- 通过
-
最终输出层:
- 最终使用一个1x1的卷积层(
final),将通道数降到目标类别数,输出每个像素点的分类结果。
- 最终使用一个1x1的卷积层(
作用
- 编码器-解码器结构: UNet的核心思想是通过编码器提取多尺度特征,然后通过解码器恢复空间信息,这使得它特别适合于像素级别的任务,如图像分割。
- 特征拼接: 编码器和解码器之间通过跳跃连接(skip connection)拼接特征,确保高分辨率的信息不会在下采样过程中丢失。
- 多通道卷积: 使用不同通道数的卷积层可以捕获不同尺度和深度的特征,从而提高模型的表达能力。
总体来说,这个UNet模型可以用于需要精确分割的图像任务,比如医学影像中的组织或病灶区域分割。
二、带有预训练DenseNet201的UNet模型
class UNetWithPretrainedDenseNet(nn.Module):
def __init__(self, num_classes=1, input_channels=3, pretrained_model_path='/data/zwt/Unet++/densenet201.pth'):
super(UNetWithPretrainedDenseNet, self).__init__()
# 加载 DenseNet201 预训练模型
densenet = models.densenet201(weights=None) # 使用 DenseNet201
if pretrained_model_path:
densenet.load_state_dict(torch.load(pretrained_model_path))
# 输入通道不为3时,使用自定义的卷积层
if input_channels != 3:
self.first_conv = nn.Conv2d(input_channels, 64, kernel_size=7, stride=2, padding=3, bias=False)
else:
self.first_conv = densenet.features.conv0
# 编码器部分 (调整为 DenseNet201 的输出通道数)
self.encoder1 = nn.Sequential(self.first_conv, densenet.features.norm0, densenet.features.relu0, densenet.features.pool0) # [batch, 64, H/4, W/4]
self.encoder2 = densenet.features.denseblock1 # [batch, 256, H/4, W/4]
self.trans1 = densenet.features.transition1 # [batch, 128, H/8, W/8]
self.encoder3 = densenet.features.denseblock2 # [batch, 512, H/8, W/8]
self.trans2 = densenet.features.transition2 # [batch, 256, H/16, W/16]
self.encoder4 = densenet.features.denseblock3 # [batch, 1024, H/16, W/16]
self.trans3 = densenet.features.transition3 # [batch, 512, H/32, W/32]
self.encoder5 = densenet.features.denseblock4 # [batch, 1920, H/32, W/32] # DenseNet201 特征图输出是 1920 个通道
# Dropout 概率
# self.dropout = nn.Dropout(p=0.2) # 引入 Dropout,丢弃概率为 0.5
# 解码器部分 (调整通道数)
self.up4 = nn.ConvTranspose2d(1920, 1024, kernel_size=2, stride=2) # [batch, 1024, H/16, W/16]
self.conv4 = nn.Conv2d(1920, 1024, kernel_size=3, padding=1) # 拼接后 [batch, 1920, H/16, W/16]
self.up3 = nn.ConvTranspose2d(1024, 512, kernel_size=2, stride=2) # [batch, 512, H/8, W/8]
self.conv3 = nn.Conv2d(768, 512, kernel_size=3, padding=1) # 拼接后 [batch, 768, H/8, W/8]
self.up2 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2) # [batch, 256, H/4, W/4]
self.conv2 = nn.Conv2d(384, 256, kernel_size=3, padding=1) # 拼接后 [batch, 512, H/4, W/4]
self.up1 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2) # [batch, 128, H/2, W/2]
self.conv1 = nn.Conv2d(192, 128, kernel_size=3, padding=1) # 拼接后 [batch, 192, H/2, W/2]
# 最后一层卷积输出
self.final_conv = nn.Conv2d(128, num_classes, kernel_size=1)
def forward(self, x):
# 编码部分
x1 = self.encoder1(x) # [batch, 64, H/4, W/4]
x2 = self.encoder2(x1) # [batch, 256, H/4, W/4]
x2 = self.trans1(x2) # [batch, 128, H/8, W/8]
x3 = self.encoder3(x2) # [batch, 512, H/8, W/8]
x3 = self.trans2(x3) # [batch, 256, H/16, W/16]
x4 = self.encoder4(x3) # [batch, 1024, H/16, W/16]
x4 = self.trans3(x4) # [batch, 512, H/32, W/32]
x5 = self.encoder5(x4) # [batch, 1920, H/32, W/32]
# 解码部分,逐步上采样
d4 = self.up4(x5) # 上采样
d4 = F.interpolate(d4, size=x4.shape[2:], mode='bilinear', align_corners=True) # 调整尺寸
d4 = torch.cat([d4, x4], dim=1) # 拼接来自编码器的 x4 (1024 + 896 = 1920)
d4 = self.conv4(d4) # 卷积
# d4 = self.dropout(d4)
d3 = self.up3(d4) # 上采样
d3 = F.interpolate(d3, size=x3.shape[2:], mode='bilinear', align_corners=True) # 调整尺寸
d3 = torch.cat([d3, x3], dim=1) # 拼接来自编码器的 x3 (512 + 256 = 768)
d3 = self.conv3(d3) # 卷积
# d3 = self.dropout(d3)
d2 = self.up2(d3) # 上采样
d2 = F.interpolate(d2, size=x2.shape[2:], mode='bilinear', align_corners=True) # 调整尺寸
d2 = torch.cat([d2, x2], dim=1) # 拼接来自编码器的 x2
d2 = self.conv2(d2) # 卷积
# d2 = self.dropout(d2)
d1 = self.up1(d2) # 上采样
d1 = F.interpolate(d1, size=x1.shape[2:], mode='bilinear', align_corners=True) # 调整尺寸
d1 = torch.cat([d1, x1], dim=1) # 拼接来自编码器的 x1
d1 = self.conv1(d1) # 卷积
# d1 = self.dropout(d1)
# 最后输出
out = self.final_conv(d1) # 最后一层卷积
out = F.interpolate(out, size=x.shape[2:], mode='bilinear', align_corners=True) # 上采样到输入尺寸
return out
类 UNetWithPretrainedDenseNet
UNetWithPretrainedDenseNet类是一个结合了预训练的DenseNet201作为编码器部分的UNet网络。DenseNet是一种广泛用于计算机视觉任务的卷积神经网络,其优势在于特征的高效传递,Dense块可以让特征图在网络中共享,从而有效提高模型性能并减少过拟合。
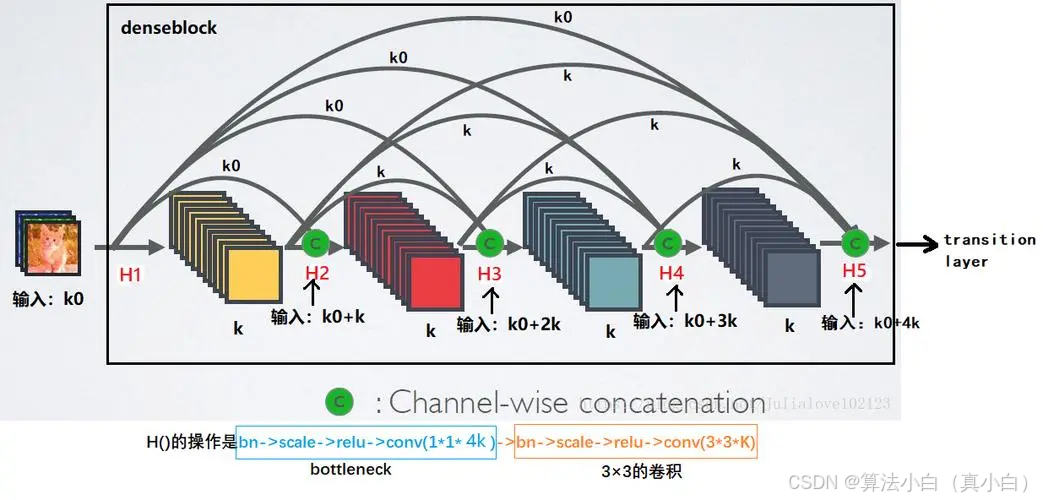
编码器部分
编码器部分基于DenseNet201的预训练模型,使用了DenseNet201的各个卷积块(Dense Blocks)提取多尺度特征。DenseNet的特点是每一层的输入是所有之前层的输出的拼接,这使得DenseNet能够更好地复用特征,避免梯度消失。
self.encoder1: 首先应用卷积和池化操作,从输入图像中提取初步特征。self.encoder2到self.encoder5: 使用DenseNet的四个稠密块(Dense Block)和过渡层(Transition Layer)逐步进行特征提取和下采样,生成深度越来越高的特征图。每一个稠密块都输出多个通道,最后一层输出1920个通道的特征图。
解码器部分
解码器部分负责通过上采样和卷积逐步恢复图像的空间分辨率,并结合编码器中的多尺度特征。该部分采用了经典的UNet解码器设计,通过上采样、特征拼接和卷积恢复分辨率。
up4到up1: 通过反卷积(ConvTranspose2d)或双线性插值(F.interpolate)将特征图逐步上采样,同时与编码器部分对应层的特征拼接。比如在d4阶段,特征图从深度为1920的编码器输出经过上采样恢复到高分辨率后,与编码器中的x4拼接。conv4到conv1: 每次拼接后的特征图经过卷积层进行进一步处理,调整特征图的深度并整合信息。
最后一层卷积
self.final_conv: 通过一个1x1的卷积层将解码器输出的通道数调整为类别数(即分割图的最终输出维度),并使用双线性插值将结果恢复到原始输入图像的尺寸。
模型的前向传播 forward
在前向传播过程中,模型首先通过DenseNet的编码器部分提取特征,然后逐步通过解码器进行上采样和拼接,最后输出与输入图像相同尺寸的分割图。具体步骤如下:
- 编码阶段: 输入图像依次通过编码器的不同层,逐步进行特征提取和下采样,生成多个尺度的特征图。
- 解码阶段: 从最深的特征图开始,逐步通过上采样和拼接恢复图像的分辨率,结合编码器各层的多尺度特征,保证精细的定位信息。
- 输出阶段: 最终通过卷积层和插值操作生成与输入相同尺寸的分割图。
作用
- DenseNet的使用: 该模型使用DenseNet201作为编码器,这种预训练模型能够很好地提取深层次的图像特征,尤其适合复杂的图像分割任务。
- 特征拼接: 编码器和解码器之间通过跳跃连接(skip connection)拼接特征,使得高分辨率的信息不会在下采样过程中丢失,从而提升分割精度。
- 上采样与卷积: 解码器部分通过上采样和卷积逐步恢复空间分辨率,并在每一步拼接编码器的特征图,实现精准的图像重建。
应用场景
该模型适用于图像分割任务,特别是需要从预训练模型中提取深层特征的任务,如医学影像分割、遥感影像处理等。DenseNet201作为编码器使得该模型在提取高层次特征时具有良好的表现,而UNet结构则保证了分割的精度。
三、结合预训练的ResNet50作为编码器的UNet网络架构
class UNetWithPretrainedResNet50(nn.Module):
def __init__(self, num_classes=1, input_channels=3, pretrained_model_path='/app/resnet50.pth'):
super(UNetWithPretrainedResNet50, self).__init__()
# 加载 ResNet50 预训练模型
resnet = models.resnet50(weights=None)
if pretrained_model_path:
resnet.load_state_dict(torch.load(pretrained_model_path))
else:
resnet = models.resnet50(pretrained=True) # 使用 torchvision 自带的预训练模型
# 如果输入通道数不为3,修改第一个卷积层
if input_channels != 3:
self.first_conv = nn.Conv2d(input_channels, 64, kernel_size=7, stride=2, padding=3, bias=False)
else:
self.first_conv = resnet.conv1
# ResNet50 编码器层
self.encoder1 = nn.Sequential(self.first_conv, resnet.bn1, resnet.relu, resnet.maxpool) # 输出: [batch, 64, H/4, W/4]
self.encoder2 = resnet.layer1 # 输出: [batch, 256, H/4, W/4] (Bottleneck)
self.encoder3 = resnet.layer2 # 输出: [batch, 512, H/8, W/8] (Bottleneck)
self.encoder4 = resnet.layer3 # 输出: [batch, 1024, H/16, W/16] (Bottleneck)
self.encoder5 = resnet.layer4 # 输出: [batch, 2048, H/32, W/32] (Bottleneck)
# 解码器部分,使用卷积和上采样
self.up4 = nn.ConvTranspose2d(2048, 1024, kernel_size=2, stride=2)
self.conv4 = nn.Conv2d(2048, 1024, kernel_size=3, padding=1)
self.up3 = nn.ConvTranspose2d(1024, 512, kernel_size=2, stride=2)
self.conv3 = nn.Conv2d(1024, 512, kernel_size=3, padding=1)
self.up2 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(512, 256, kernel_size=3, padding=1)
self.up1 = nn.ConvTranspose2d(256, 64, kernel_size=2, stride=2)
self.conv1 = nn.Conv2d(128, 64, kernel_size=3, padding=1)
# 最后一层卷积
self.final_conv = nn.Conv2d(64, num_classes, kernel_size=1)
def forward(self, x):
# 编码部分
x1 = self.encoder1(x) # [batch, 64, H/4, W/4]
x2 = self.encoder2(x1) # [batch, 256, H/4, W/4]
x3 = self.encoder3(x2) # [batch, 512, H/8, W/8]
x4 = self.encoder4(x3) # [batch, 1024, H/16, W/16]
x5 = self.encoder5(x4) # [batch, 2048, H/32, W/32]
# 解码部分
d4 = self.up4(x5) # 上采样后的 d4 可能尺寸与 x4 不匹配
d4 = F.interpolate(d4, size=x4.shape[2:], mode='bilinear', align_corners=True) # 调整 d4 尺寸与 x4 一致
d4 = torch.cat([d4, x4], dim=1) # 拼接来自编码器的 x4 输出 [batch, 2048, H/16, W/16]
d4 = self.conv4(d4) # [batch, 1024, H/16, W/16]
d3 = self.up3(d4)
d3 = F.interpolate(d3, size=x3.shape[2:], mode='bilinear', align_corners=True) # 调整 d3 尺寸与 x3 一致
d3 = torch.cat([d3, x3], dim=1) # 拼接来自编码器的 x3 输出 [batch, 1024, H/8, W/8]
d3 = self.conv3(d3) # [batch, 512, H/8, W/8]
d2 = self.up2(d3)
d2 = F.interpolate(d2, size=x2.shape[2:], mode='bilinear', align_corners=True) # 调整 d2 尺寸与 x2 一致
d2 = torch.cat([d2, x2], dim=1) # 拼接来自编码器的 x2 输出 [batch, 512, H/4, W/4]
d2 = self.conv2(d2) # [batch, 256, H/4, W/4]
d1 = self.up1(d2)
d1 = F.interpolate(d1, size=x1.shape[2:], mode='bilinear', align_corners=True) # 调整 d1 尺寸与 x1 一致
d1 = torch.cat([d1, x1], dim=1) # 拼接来自编码器的 x1 输出 [batch, 128, H/2, W/2]
d1 = self.conv1(d1) # [batch, 64, H/2, W/2]
# 最终输出层
out = self.final_conv(d1) # [batch, num_classes, H/2, W/2]
# 上采样到输入的原始尺寸
out = F.interpolate(out, size=x.shape[2:], mode='bilinear', align_corners=True)
return out
类 UNetWithPretrainedResNet50
UNetWithPretrainedResNet50类将ResNet50作为编码器部分,结合UNet的上采样结构进行解码。这种组合能够充分利用ResNet50的强大特征提取能力,同时通过UNet的解码器结构恢复图像的细节。
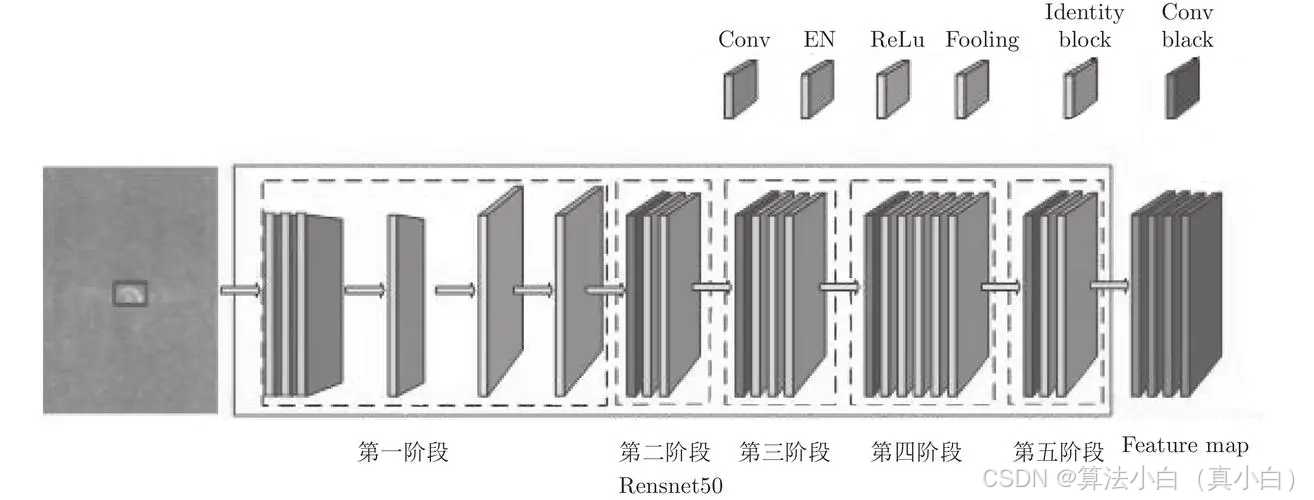
编码器部分
编码器部分基于ResNet50的预训练模型,通过逐层卷积提取输入图像的特征,同时下采样以减少空间分辨率。
self.first_conv: 如果输入通道数不是3,则定义一个自定义卷积层,否则使用ResNet50的第一层卷积。self.encoder1: 第一层编码器使用了ResNet50的第一层卷积、批量归一化(BatchNorm)、ReLU激活和最大池化层。输出是尺寸为H/4, W/4,通道数为64的特征图。self.encoder2到self.encoder5: 使用ResNet50的各个残差块提取特征,逐层下采样。每层的通道数逐步增加(256, 512, 1024, 2048),分辨率逐步减小。
解码器部分
解码器部分通过反卷积层(ConvTranspose2d)进行上采样,并结合编码器对应层的特征图恢复分辨率。具体操作包括:
up4到up1: 每次通过反卷积进行上采样,然后与编码器相应层的输出进行拼接(torch.cat),确保解码器能够同时利用低层次(高分辨率)和高层次(高语义)信息。- 卷积操作(
conv4到conv1): 每次拼接后的特征图通过卷积操作调整通道数,进一步整合拼接后的信息。
解码器的目的是逐步恢复图像的空间分辨率,同时保留编码器中的细节信息,使得模型在进行图像分割时能够获得精确的分割结果。
最后一层卷积
self.final_conv: 使用1x1卷积将解码器输出的通道数调整为目标类别数(即分割的类别数),得到每个像素的分类结果。
前向传播 forward
前向传播中,输入图像首先通过ResNet50的编码器部分提取特征,然后通过解码器逐步进行上采样,最后生成分割图。流程如下:
-
编码部分:
- 输入图像经过ResNet50的编码器提取多层次特征,逐步下采样。
x1到x5是每一层的输出,代表不同深度和分辨率的特征图。
-
解码部分:
- 从最深的特征图
x5开始,逐步通过反卷积上采样,并拼接编码器中对应的特征图。 - 例如,
d4是从x5上采样后的特征图,并与x4拼接,然后经过卷积进行处理。 - 通过上采样和拼接的操作,解码器能够同时利用高层次的语义信息和低层次的细节信息。
- 从最深的特征图
-
最终输出:
- 最终输出经过1x1卷积调整通道数,并通过双线性插值将其上采样回输入图像的原始尺寸。
作用
- ResNet50的使用: 该模型通过ResNet50的残差结构进行特征提取。ResNet50在较深的网络中能够保持梯度的稳定性,并且其预训练模型可以在多种任务上表现出色,适合图像分割任务中的高效特征提取。
- 多层次特征拼接: 编码器和解码器之间的跳跃连接(skip connection)使得模型可以同时使用不同分辨率的特征,确保解码器在恢复图像时能够保留足够的细节。
- 上采样与卷积: 解码器部分通过上采样和卷积逐步恢复图像的分辨率,结合编码器的高分辨率信息,使得最终的分割结果能够精确地对应输入图像中的目标物体。
应用场景
这个模型适用于各种图像分割任务,如医学图像分割、遥感图像处理和自动驾驶中的道路标记分割等场景。ResNet50作为编码器能够捕获丰富的语义信息,而UNet解码器的上采样结构则保证了分割的空间精度。
四、结合了DenseNet121、ASPP模块和残差块的深度网络 SARUNetDeep
class SEBlock(nn.Module):
def __init__(self, in_channels, reduction=16):
super(SEBlock, self).__init__()
self.global_avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Linear(in_channels, in_channels // reduction)
self.fc2 = nn.Linear(in_channels // reduction, in_channels)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
batch_size, channels, _, _ = x.size()
y = self.global_avg_pool(x).view(batch_size, channels)
y = F.relu(self.fc1(y))
y = self.sigmoid(self.fc2(y)).view(batch_size, channels, 1, 1)
return x * y
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
self.se = SEBlock(out_channels)
# 如果输入和输出通道不一致,需要使用额外的卷积来调整维度
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out = self.se(out)
out += self.shortcut(x)
out = F.relu(out)
return out
class ASPP(nn.Module):
def __init__(self, in_channels, out_channels):
super(ASPP, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1)
self.conv3_1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=2, dilation=2)
self.conv3_2 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=3, dilation=3)
self.conv3_3 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=4, dilation=4)
self.global_avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv1x1_output = nn.Conv2d(out_channels * 5, out_channels, kernel_size=1)
def forward(self, x):
size = x.shape[2:]
out1 = F.relu(self.conv1(x))
out2 = F.relu(self.conv3_1(x))
out3 = F.relu(self.conv3_2(x))
out4 = F.relu(self.conv3_3(x))
out5 = F.relu(self.conv1(self.global_avg_pool(x)))
out5 = F.interpolate(out5, size=size, mode='bilinear', align_corners=True)
out = torch.cat([out1, out2, out3, out4, out5], dim=1)
return F.relu(self.conv1x1_output(out))
class SARUNetDeep(nn.Module):
def __init__(self, num_classes=1, input_channels=1, pretrained_model_path='/data/zwt/Unet++/densenet121.pth'):
super(SARUNetDeep, self).__init__()
# 加载 DenseNet121 预训练模型
densenet = models.densenet121(weights=None)
if pretrained_model_path:
densenet.load_state_dict(torch.load(pretrained_model_path))
# 修改DenseNet的第一个卷积层,将输入通道调整为1(灰度图像)
self.encoder = nn.Sequential(
nn.Conv2d(input_channels, 64, kernel_size=7, stride=2, padding=3, bias=False), # 改为1通道输入
*list(densenet.features.children())[1:-1]
)
# 在DenseNet输出之后,添加一个卷积层将1024个通道降到64个通道
self.conv_to_64 = nn.Conv2d(1024, 64, kernel_size=1, stride=1)
# 调整残差块,通道数从64开始逐步增加,最终达到1024
self.res_block1 = ResidualBlock(64, 128) # 输入64,输出128
self.res_block2 = ResidualBlock(128, 256) # 输入128,输出256
self.res_block3 = ResidualBlock(256, 512) # 输入256,输出512
self.res_block4 = ResidualBlock(512, 1024) # 输入512,输出1024
# ASPP模块,输入1024通道
self.aspp = ASPP(1024, 512)
# Decoder部分,开始上采样并逐步减少通道数
self.upconv1 = nn.ConvTranspose2d(512 + 512, 512, kernel_size=2, stride=2)
self.res_block5 = ResidualBlock(512, 512)
self.upconv2 = nn.ConvTranspose2d(512 + 256, 256, kernel_size=2, stride=2)
self.res_block6 = ResidualBlock(256, 256)
self.upconv3 = nn.ConvTranspose2d(256 + 128, 128, kernel_size=2, stride=2)
self.res_block7 = ResidualBlock(128, 128)
self.upconv4 = nn.ConvTranspose2d(128 + 64, 64, kernel_size=2, stride=2)
self.res_block8 = ResidualBlock(64, 64)
# 最终卷积层,用于生成分割图像,输出单通道
self.conv_final = nn.Conv2d(64, num_classes, kernel_size=1)
def forward(self, x):
# print(f"Input shape: {x.shape}")
# Encoder 部分
x1 = self.encoder(x) # DenseNet特征提取,输出1024通道
# print(f"After encoder: {x1.shape}")
# 将1024通道通过卷积调整为64通道
x1 = self.conv_to_64(x1)
# print(f"After conv_to_64: {x1.shape}")
x2 = F.max_pool2d(x1, 2) # 下采样
x2 = self.res_block1(x2) # 输入64,输出128
# print(f"After res_block1: {x2.shape}")
x3 = F.max_pool2d(x2, 2) # 下采样
x3 = self.res_block2(x3) # 输入128,输出256
# print(f"After res_block2: {x3.shape}")
x4 = F.max_pool2d(x3, 2) # 下采样
x4 = self.res_block3(x4) # 输入256,输出512
# print(f"After res_block3: {x4.shape}")
x5 = F.max_pool2d(x4, 2) # 下采样
x5 = self.res_block4(x5) # 输入512,输出1024
# print(f"After res_block4: {x5.shape}")
# ASPP模块处理最深的特征,输入为1024通道
x_aspp = self.aspp(x5)
# print(f"After ASPP: {x_aspp.shape}")
# 上采样ASPP输出,使其大小与x4匹配
x_aspp = F.interpolate(x_aspp, size=x4.shape[2:], mode='bilinear', align_corners=True)
# print(f"After upsampling ASPP output: {x_aspp.shape}")
# Decoder 部分,逐步上采样并拼接
x_up1 = self.upconv1(torch.cat([x4, x_aspp], dim=1)) # 拼接x4,输入512+512通道
# print(f"After upconv1 and concatenation: {x_up1.shape}")
x_up1 = self.res_block5(x_up1) # 输出512
# print(f"After res_block5: {x_up1.shape}")
x_up2 = self.upconv2(torch.cat([x3, x_up1], dim=1)) # 拼接x3,输入256+512通道
# print(f"After upconv2 and concatenation: {x_up2.shape}")
x_up2 = self.res_block6(x_up2) # 输出256
# print(f"After res_block6: {x_up2.shape}")
x_up3 = self.upconv3(torch.cat([x2, x_up2], dim=1)) # 拼接x2,输入128+256通道
# print(f"After upconv3 and concatenation: {x_up3.shape}")
x_up3 = self.res_block7(x_up3) # 输出128
# print(f"After res_block7: {x_up3.shape}")
x_up4 = self.upconv4(torch.cat([x1, x_up3], dim=1)) # 拼接x1,输入64+128通道
# print(f"After upconv4 and concatenation: {x_up4.shape}")
x_up4 = self.res_block8(x_up4) # 输出64
# print(f"After res_block8: {x_up4.shape}")
# 最终卷积层输出分割结果
output = self.conv_final(x_up4)
# print(f"Output shape: {output.shape}")
# 使用F.interpolate将输出上采样回输入图像的尺寸(512x512)
output = F.interpolate(output, size=(512, 512), mode='bilinear', align_corners=True)
# print(f"Resized output shape: {output.shape}")
return output
类 SARUNetDeep
该网络由DenseNet121作为特征提取器,并结合了残差块(Residual Block)和ASPP(空洞空间金字塔池化)模块,在编码器中提取多尺度特征后,通过解码器逐步上采样进行图像恢复。
编码器部分
编码器基于DenseNet121的预训练模型,提取输入图像的多层次特征。编码器部分的特征图深度逐步增加,最终输出1024通道的深层次特征。
- DenseNet121: DenseNet的特点是通过Dense块实现高效的特征复用,每层的输入是之前所有层的输出。这种特性使得DenseNet能够更好地捕获图像中的细节信息。
- 在代码中,
self.encoder通过修改DenseNet121的第一层卷积来适应单通道(灰度图像)输入。
- 在代码中,
conv_to_64: 在DenseNet输出1024通道后,添加一个1x1卷积层,将通道数减少到64,为后续的残差块处理做准备。
ASPP模块
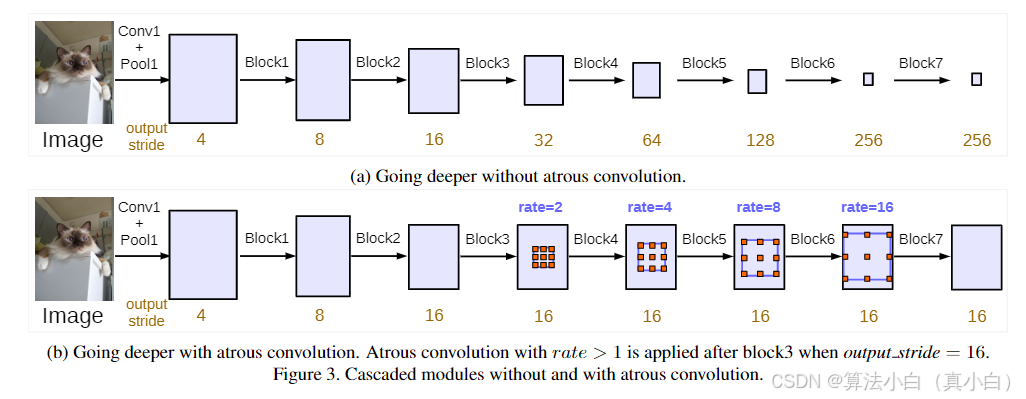
ASPP模块(Atrous Spatial Pyramid Pooling)用于捕捉多尺度信息,特别是能够在不增加计算复杂度的情况下扩大感受野。
- 空洞卷积: ASPP模块使用不同的空洞率(dilation rates)进行卷积操作,这样可以在多尺度上提取特征,从而提高对多尺寸物体的分割能力。
- 全局平均池化:
global_avg_pool部分通过全局池化操作进一步提取图像的全局上下文信息,增强分割的全局理解。
ASPP模块的输出经过多个卷积操作后,通过插值调整大小与之前的编码器特征图匹配,再输入到解码器部分。
解码器部分
解码器部分通过反卷积层(转置卷积)逐步上采样恢复图像的分辨率,并结合对应编码器层的特征进行拼接,从而增强高分辨率信息的利用。
upconv1到upconv4: 每层通过反卷积进行上采样,然后拼接来自编码器的特征图。该操作保证了高分辨率和低分辨率特征的结合,保留了语义信息的同时恢复了细节。- 残差块: 在每次上采样后的特征图通过残差块进行进一步处理。残差块的优势在于缓解深层网络中的梯度消失问题,能够更好地捕获图像的细节。
最后一层卷积
conv_final: 使用一个1x1的卷积层将通道数调整为目标类别数,即分割任务中的类别数。
前向传播 forward
在前向传播过程中,网络首先通过DenseNet121的编码器部分提取多尺度特征,然后通过ASPP模块进行多尺度处理,最后通过解码器逐步上采样,生成与输入图像相同分辨率的分割图。
- 编码阶段: 输入图像首先经过DenseNet121的编码器部分,生成1024通道的特征图。
- ASPP处理: 编码器输出通过ASPP模块进行多尺度特征提取。
- 解码阶段: ASPP输出通过解码器逐步上采样,每次上采样时与对应的编码器层特征拼接,最后逐步恢复图像的空间分辨率。
- 输出阶段: 最终的输出经过卷积层生成单通道或多通道的分割图,并通过双线性插值调整到与输入图像相同的尺寸。
作用
- DenseNet121的使用: DenseNet121能够高效地提取深层次的图像特征,同时通过特征复用提高模型的表现力,适合复杂的图像分割任务。
- ASPP模块: ASPP模块能够有效地捕获多尺度信息,特别是在分割不同大小的物体时表现出色。它通过空洞卷积扩大感受野,增强网络对全局信息的理解。
- 残差块: 残差块能够缓解深层网络中的梯度消失问题,使网络能够在更深的层次上捕捉图像的细节信息。
- 跳跃连接(skip connection): 编码器和解码器之间的跳跃连接将低分辨率特征和高分辨率特征结合起来,有效提高了分割的精度。
应用场景
SARUNetDeep适用于各种图像分割任务,尤其是需要捕捉多尺度信息的场景,如医学图像分割、遥感影像处理和自动驾驶中的道路标记分割等。DenseNet121与ASPP模块的结合使其能够处理复杂场景中的分割任务。


















 2442
2442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











