




 本文详细介绍了一元线性回归的算法原理,包括最小二乘估计和极大似然估计,以及如何通过梯度法求解权重和截距。随后扩展到多元线性回归,强调了向量表达和使用numpy库加速计算。重点讲解了优化问题中的凸集和梯度概念在求解中的应用。
本文详细介绍了一元线性回归的算法原理,包括最小二乘估计和极大似然估计,以及如何通过梯度法求解权重和截距。随后扩展到多元线性回归,强调了向量表达和使用numpy库加速计算。重点讲解了优化问题中的凸集和梯度概念在求解中的应用。
一、一元线性回归
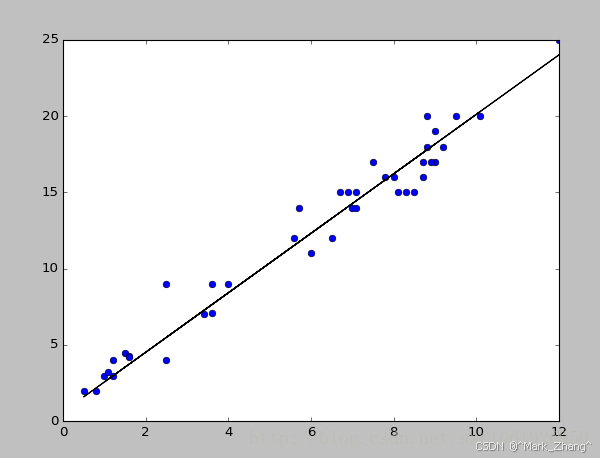
1.1 算法原理
目的:仅仅通过一个变量预测因变量
举个例子:仅仅通过发量判断程序员水平
此时表示函数:
y = ω\omegaωx + b
1.2 线性回归中的估计
1.2.1 最小二乘估计
目的:基于军方误差最小化来进行模型求解的方法:
对于函数 y = ω\omegaωx + b ,我们定义如下公式求解误差:
E(w,b)=∑i=1m(yi−f(xi))2=∑i=1m(yi−(wxi+b))2=∑i=1m(yi−wxi−b)2\begin{aligned} E_{(w,b)}& =\sum_{i=1}^{m}\left(y_i-f(x_i)\right)^2 \\ &=\sum_{i=1}^m\left(y_i-(wx_i+b)\right)^2 \\ &=\sum_{i=1}^m\left(y_i-wx_i-b\right)^2 \end{aligned}E(w,b)=i=1∑m(yi−f(xi))2=i=1∑m(yi−(wxi+b))2=i=1∑m(yi−wxi−b)2
从几何角度理解就是当前数据点的y坐标值跟用于拟合的函数上同横坐标对应的纵坐标的差值的平方。
1.2.2 极大似然估计
目的:用于估计概率分布的参数值,个人感觉有点像生物学中的抽样调查。
举个例子:要调查学校中的雌性生物和雄性生物的比例,并不是将所有生物都捉起来,而是抽取其中的一部分进行统计。
公式如下:
L(θ)=∏i=1nP(xi;θ)L(\theta)=\prod_{i=1}^nP(x_i;\theta)L(θ)=∏i=1nP(xi;θ)
其中θ\thetaθ是未知数,这个概率是关于θ\thetaθ的函数,称L(θ\thetaθ)为样本的似然函数。使得函数取到最大值的θ∗\theta^*θ∗就是θ\thetaθ的估计值。
1.3 求解 ω\omegaω 和 b
大家都知道机器学习问题主要解决的就是优化问题,由此衍生出来的数学理论目的也是求解优化问题。
先验知识
凸集:集合D⊂RnD\subset\mathbb{R}^nD⊂Rn,如果对任意的x,y∈Dx,\boldsymbol{y}\in Dx,y∈D与任意的α∈[0,1]\alpha\in[0,1]α∈[0,1], 有αx+(1−α)y∈D\alpha\boldsymbol{x}+(1-\alpha)\boldsymbol{y}\in Dαx+(1−α)y∈D
梯度:梯度 (多元函数的一阶导数) : 设n元函数f(x)f(\boldsymbol{x})f(x)对自变量x=(x1,x2,...,xn)T\boldsymbol{x}=(x_1,x_2,...,x_n)^{\mathrm{T}}x=(x1,x2,...,xn)T的各分量xix_ixi的偏导数∂f(x)∂xi(i=1,...,n)\frac{\partial f(x)}{\partial x_i}(i=1,...,n)∂xi∂f(x)(i=1,...,n)都存在,则称函数f(x)f(\boldsymbol{x})f(x)在xxx处一阶可导,并称向量∇f(x)=[∂f(x)∂x1∂f(x)∂x2⋮∂f(x)∂xn]\left.\nabla f(\boldsymbol{x})=\left[\begin{array}{c}\frac{\partial f(\boldsymbol{x})}{\partial x_1}\\\frac{\partial f(\boldsymbol{x})}{\partial x_2}\\\vdots\\\frac{\partial f(\boldsymbol{x})}{\partial x_n}\end{array}\right.\right]∇f(x)=∂x1∂f(x)∂x2∂f(x)⋮∂xn∂f(x) 为函数f(x)f(\boldsymbol{x})f(x)在x\boldsymbol{x}x处的一阶导数或梯度。
这里我们一般就使用列矩阵(分母型)
求解
凸充分性定理:若f˙:Rn→R\dot{f}:\mathbb{R}^n\to\mathbb{R}f˙:Rn→R是凸函数,且f(x)f(\boldsymbol{x})f(x)一阶连续可微,则x∗x^*x∗是全局解的充分必要条件是∇f(x∗)=0\nabla f(x^*)=\mathbf{0}∇f(x∗)=0
所以,∇E(w,b)=0\nabla E_{(w,b)}=\mathbf{0}∇E(w,b)=0的点即为最小值点,也即∇E(w,b)=[∂E(w,b)∂w∂E(w,b)∂b]=[00]\left.\nabla E_{(w,b)}=\left[\begin{array}{c}\frac{\partial E(w,b)}{\partial w}\\\frac{\partial E(w,b)}{\partial b}\end{array}\right.\right]=\left[\begin{array}{c}0\\0\end{array}\right]∇E(w,b)=[∂w∂E(w,b)∂b∂E(w,b)]=[00]
先对bbb进行求导和化简:
∂E(w,b)∂b=2(mb−∑i=1m(yi−wxi))=0mb−∑i=1m(yi−wxi)=0b=1m∑i=1m(yi−wxi)b=1m∑i=1myi−w⋅1m∑i=1mxi=yˉ−wxˉ\begin{gathered} \frac{\partial E_{(w,b)}}{\partial b} =2\left(mb-\sum_{i=1}^m\left(y_i-wx_i\right)\right)=0 \\ mb-\sum_{i=1}^{m}{(y_i-wx_i)}=0 \\ b=\frac{1}{m}\sum_{i=1}^{m}(y_{i}-wx_{i})\\ b=\frac1m\sum_{i=1}^my_i-w\cdot\frac1m\sum_{i=1}^mx_i=\bar{y}-w\bar{x} \end{gathered}∂b∂E(w,b)=2(mb−i=1∑m(yi−wxi))=0mb−i=1∑m(yi−wxi)=0b=m1i=1∑m(yi−wxi)b=m1i=1∑myi−w⋅m1i=1∑mxi=yˉ−wxˉ
把b=yˉ−wxˉb=\bar{y}-w\bar{x}b=yˉ−wxˉ代入上式可得:
w∑i=1mxi2=∑i=1myixi−∑i=1m(yˉ−wxˉ)xi\begin{gathered}w\sum_{i=1}^mx_i^2=\sum_{i=1}^my_ix_i-\sum_{i=1}^m(\bar{y}-w\bar{x})x_i\end{gathered}wi=1∑mxi2=i=1∑myixi−i=1∑m(yˉ−wxˉ)xi
进一步推导可以得到:
w=∑i=1myixi−xˉ∑i=1myi∑i=1mxi2−1mt=∑i=1myi(xi−xˉ)∑i=1mxi2−1mt1∑i=1mxi)2(∑i=1mxi)2w=\frac{\sum_{i=1}^my_ix_i-\bar{x}\sum_{i=1}^my_i}{\sum_{i=1}^mx_i^2-\frac1{mt}}=\frac{\sum_{i=1}^my_i(x_i-\bar{x})}{\sum_{i=1}^mx_i^2-\frac1{mt}\frac1{\sum_{i=1}^mx_i)^2}(\sum_{i=1}^mx_i)^2}w=∑i=1mxi2−mt1∑i=1myixi−xˉ∑i=1myi=∑i=1mxi2−mt1∑i=1mxi)21(∑i=1mxi)2∑i=1myi(xi−xˉ)
二、多元线性回归
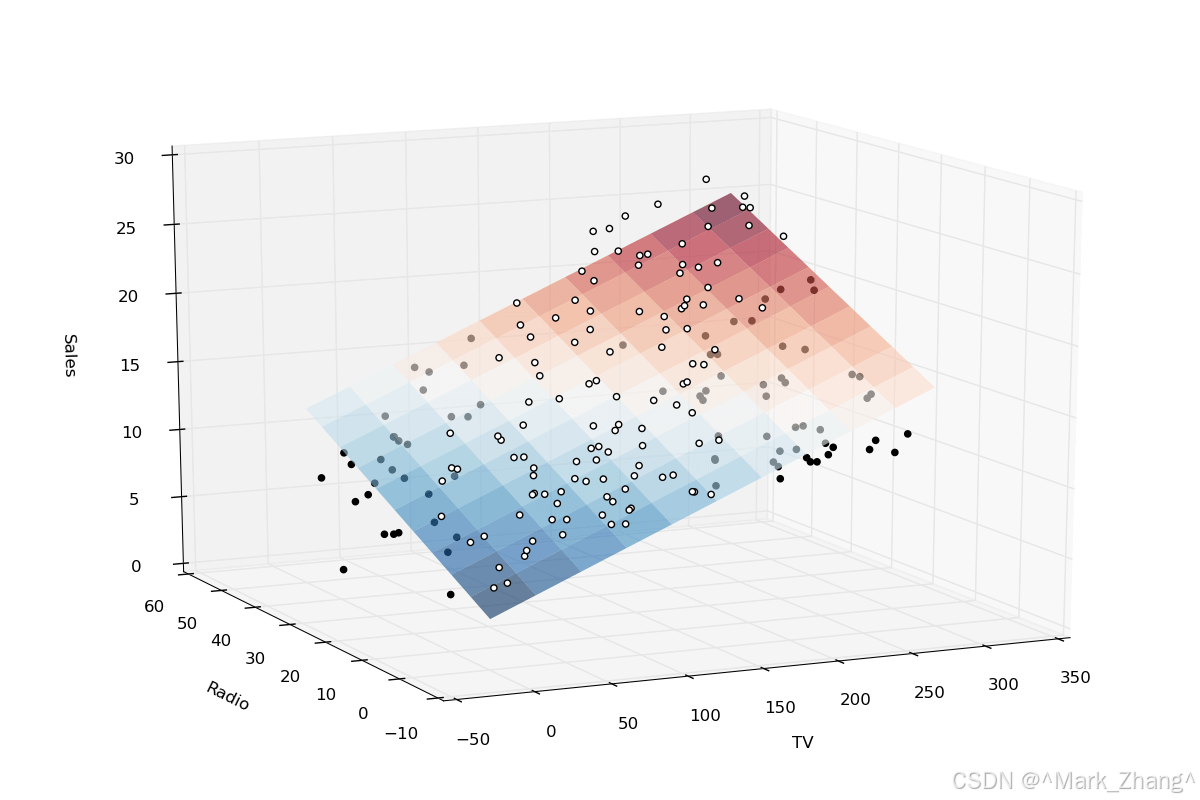
2.1 算法原理
在一元线性回归的基础上加了多值离散特征
举个栗子:在前面的通过发亮判断程序员水平的基础上增加了其他变量,比如增加了颜值(好、差)、代码量项目经历(少、中、多)等。
此时原来的函数变成了:
y = ω1\omega_1ω1x1 + ω2\omega_2ω2x2 + ω3\omega_3ω3x3 + ω4\omega_4ω4x4 + ω5\omega_5ω5x5 + ω6\omega_6ω6x6 + b
2.2 公式推导
对于多元变量,我们为了能够用numpy库进行运算加速,采用向量表达的方式。
f(xi)=wTxi+bf(\boldsymbol{x}_i)=\boldsymbol{w}^\mathrm{T}\boldsymbol{x}_i+bf(xi)=wTxi+b
也就是:
f(xi)=w1xi1+w2xi2+...+wdxid+wd+1⋅1f\left(\boldsymbol{x}_{i}\right)=w_{1}x_{i1}+w_{2}x_{i2}+...+w_{d}x_{id}+w_{d+1}\cdot1f(xi)=w1xi1+w2xi2+...+wdxid+wd+1⋅1
由最小二乘法可得Ew^=∑i=1m(yi+f(x^i))2=∑i=1m(yi−w^Tx^i)2\begin{aligned}\text{由最小二乘法可得}\\E_{\hat{\boldsymbol{w}}}&=\sum_{i=1}^m{(y_i+f(\hat{\boldsymbol{x}}_i))^2}=\sum_{i=1}^m\left(y_i-\hat{\boldsymbol{w}}^\mathrm{T}\hat{\boldsymbol{x}}_i\right)^2\end{aligned}由最小二乘法可得Ew^=i=1∑m(yi+f(x^i))2=i=1∑m(yi−w^Tx^i)2
接下来就是求解ω^∗{\hat\omega}^*ω^∗使得这个函数取最值。(证明过程略,本人太菜暂时还没懂>_<)

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









