






线性回归
给定由d个属性描述的示例,其中
是
在第
个属性上的取值,线性模型(linear model)试图学得一个通过属性的线性组合来进行预测的函数,即
一般用向量形式写成
其中为已知输入特征向量,
和
学得之后,模型就可以确定。
一元线性回归算法原理
给定数据集,其中
,
。"线性回归“试图学得一个线性模型以尽可能准确地预测实值输出标记。
我们先考虑一种最简单的情形:输入属性的数目只有一个。为便于讨论此时我们忽略关于属性的下标,即,其中
。
举一个通过【发际线高度】预测【计算机水平】的例子。
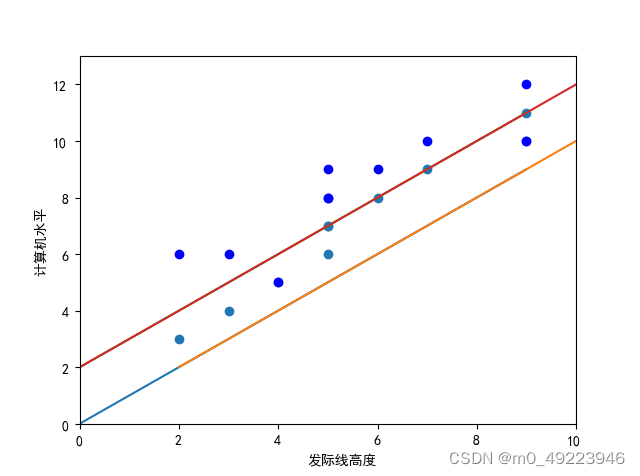
如何确定w和b呢?显然,关键在于如何衡量与
之间的差别。
画出样本点的分布图后,我们要找出所有样本点到最终模型最近的一条直线,这里我们用样本值减去预测值得到预测误差,在求平方获得正误差。基于均方误差最小化来进行模型求解的方法称为最小二乘法:
均方误差是回归任务中最常用的性能度量,因此我们可试图让均方误差最小化,即
确定了和
的最小值便确定了模型。
多元线性回归算法原理
还是这个例子,现在我们加入另外几个影响发际线高度的特征。
仅通过【发际线高度】预测【计算机水平】:
+二值离散特征【颜值】(好看:1,不好看:0)
+有序的多值离散特征【饭量】(小:1,中:2,大:3)
+无序的多值离散特征【肤色】(黄:[1, 0, 0],黑:[0, 1, 0], 白:[0, 0, 1])
此时我们试图学得
这称为多元线性回归(multivariate linear regression)。
为了便于讨论,我们把和
吸收入向量形式
,把
扩充到
中,
令,则
由最小二乘法可得
接下来对上式进行向量化,便于使用numpy等矩阵加速库加速计算。
把数据集D表示为一个大小的矩阵
,
则
最终可化为
类似于一元线性回归的均方误差最小化,多元形式可写为
计算出的最优解,模型便得以确定。















 1821
1821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









