







上午试题详解
大家看完了吧,你用的是哪种方法呢?今天给大家解析下午试题,操作软件:GeoScene Pro,题目如下:
(友情提示:字多图多方法多,建议电脑浏览学习)
作者:Lily


1 整体解题思路
1.1 人口数据模拟与分析
任务要求创建2个文件地理数据库,且数据的坐标系统一设置为CGCS2000 3 Degree GK CM 117E,跟上午的题要求没有太大变化。
要基于pop_density.tif和district.shp数据生成老年人口栅格数据,且街区的人口和老年人口依据该区域中的人口密度进行分摊,这一步不太好理解,我们把它拆分成两句,街区的人口依据该区域中的人口密度进行分摊,以及老年人口依据该区域中的人口密度进行分摊。
街区的人口依据该区域中的人口密度进行分摊
转换成公式
![]()
注意这里汇总街区人口密度是指街区范围内的所有像元人口密度总和,并不代表街区的平均人口密度。
同理:老年人口依据该区域中的人口密度进行分摊
转换成公式
![]()
最终要求得的就是像元老年人口分布。
所以 像元老年人口=街区老年总人口*像元人口密度/汇总街区人口密度
已知 街区老年总人口=街区常住人口*老年人占比
所以 像元老年人口=街区常住人口*老年人占比*像元人口密度/汇总街区人口密度
还可以根据第一个公式
像元老年人口=像元人口*老年人占比
两个方法都可以。
最后根据分析得出的像元老年人口,使用表格显示分区统计方法,记录社区尺度的老年人口,再添加连接,在社区数据中增加老年人口数量。
处理过程中还需要注意街区数据中的老年人占比是文本类型,需要在分析过程中将其转为数字型。
1.2 绿地资源服务价值评估
要计算人均绿地占比,需要统计各社区的绿地面积,观察发现绿地数据与社区数据有相交情况,也就是说存在单个绿地地块跨社区的情况,所以如果采用直接使用空间连接的方式将绿地数据挂接到社区下,再汇总统计社区挂接的绿地的方法,会导致绿地被多次计算,从而出现误差。
可以考虑使用范围内汇总的方式进行统计,或者首先使用相交工具,把绿地全部打断,再进行空间连接或者范围内汇总,得到正确的社区绿地面积。
在得到人均占地面积后,进行归一化,可以根据归一化公式
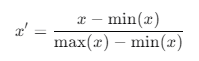
将数据归一化到[0,1]范围。
也可以直接使用标准化工具工具进行归一化。
计算绿地服务价值指数,核心需要计算社区的500米服务区内的老年人口数量,先找到社区中心点,再进行缓冲,随后使用以表格显示分区统计方法,计算各社区服务的老年人数,最后用社区服务的老年人数除以绿地面积得到结果。
要查找排名前500以及后500,在社区中分别对各字段值进行排序,找到并记录第500个的属性值,再根据条件查询,找到标杆社区及优化社区。
1.3 医疗设施可达性分析
将100米范围内的医院合并,有多种方法可以实现,可以直接删除相同项,注意xy容差的设置;使用整合工具,将100米范围内的点都整合到一个位置,再删除相同项;还可以使用聚合点工具,将100米内点聚合到面上,再将中心点做为医院;也可以使用缓冲的方式得到医院缓冲区,将重叠的区域合并,求得合并区的中心点即为合并后的医院;使用基于密度的聚类工具查找100米内的聚类点,将具有相同聚类ID的点进行删除,也可得到合并后医院。
构建网络数据集,将医院作为设施点,社区作为事件点,进行最近设施点分析,得到距离社区最近的医院,输出时使用直线。并采用分级符号,表示线的粗细,对数据进行渲染。
根据最近设施点分析结果,融合相同医院服务的社区。
1.4 服务设施规划选址
要找到邻接社区老年人口之和大于2000的社区,可以选择使用面邻域、生成邻近表、空间权重矩阵等方法,找到相应的邻域社区,再进行老年人口统计;也可以直接使用邻域汇总统计数据工具得到邻域平均值,进而统计邻域老年人口总和;还可以使用模型构建器迭代每一个社区,根据空间关系获取其邻域,再进行汇总统计,进行判断。
以“整体上从服务驿站到目标社区的总距离成本尽可能低”为优化目标,找出满足目标的50 个服务驿站建设点。可以通过网络分析中的位置分配方法,从服务驿站到目标社区说明设施点是社区中心点,需求点也是社区中心点,再根据距离成本最低的要求,在位置分配图层的问题类型中选择最小化加权阻抗即可,设施点数量设置为50。
1.5 适老设施改造成本估算
要计算建筑物老年人口,首先将模拟的老年人口按照住宅区进行分区统计,挂接到各住宅区,再将建筑物与住宅区进行一对一空间连接,使用汇总统计或频数的方法,对住宅区内的建筑物数量进行统计(这里不建议采取范围内汇总的方式,原因在于数据中存在一个建筑物与多个住宅区相交的情况,容易出现重复计算),再将住宅区老年人口与建筑物数量相除得到建筑物老年人口。
使用条件查询得到楼层大于5且老年人口超过5人的住宅楼。
1.6 最终成果制图
按照题目要求的制图方法以及任务制作对应的专题组图。需要添加标题、比例尺、指北针、图例等制图元素。
详细流程如下:
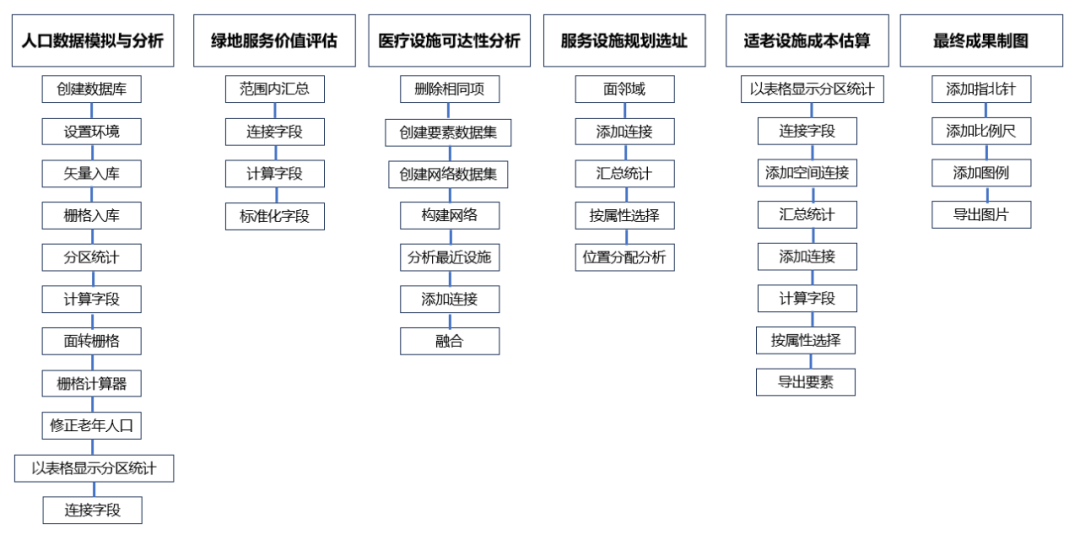
图1 流程图
2 详细步骤
2.1 人口数据模拟与分析
2.1.1 创建数据库
2.1.1.1 创建数据库
打开GeoScene Pro软件,目录视图中,新建结果文件夹,在结果文件夹上右键【新建】|【文件地理数据库】,新建两个数据库,依次命名为“temp_data.gdb”和“result_data.gdb”。
2.1.1.2 设置环境(非必须)
切换到【分析】菜单栏,点击【地理处理】|【环境】。
设置【当前工作空间】和【临时工作空间】均为temp_data.gdb。
图2 环境设置
2.1.2 调整坐标系
GeoScene Pro中加载所有数据。
2.1.2.1 矢量入库
点击【工具箱】|【数据管理工具】|【投影和变换】|【批量投影】,输入要素类或数据集为全部shape文件,输出工作空间为“temp_data.gdb”,输出坐标系为“CGCS2000_3_Degree_GK_CM_117E”。
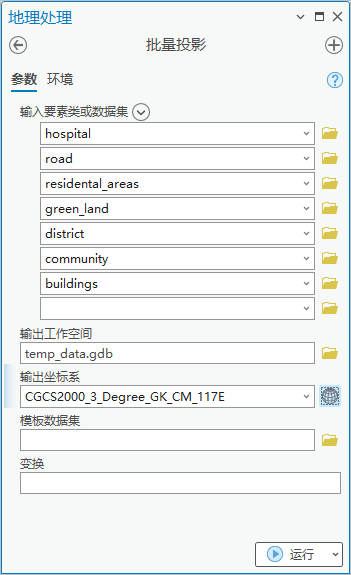
图3 批量投影
2.1.2.2 栅格入库
点击【工具箱】|【数据管理工具】|【投影和变换】|【栅格投影】|【投影栅格】,输入栅格为“pop_density.tif”,输出栅格数据集为“pop_density”,输出坐标系为“CGCS2000_3_Degree_GK_CM_117E”,输出像元大小为5。
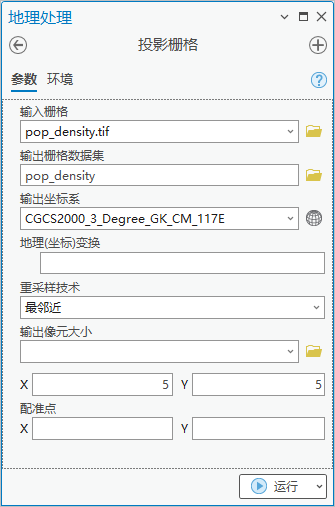
图4 投影栅格
移除地图视图中所有图层,加载temp_data.gdb中的所有数据。
2.1.3 分摊老年人口
方法1:
1. 点击【工具箱】|【空间分析工具】|【区域分析】|【分区统计】,输入栅格数据或要素区域数据为“district”,区域字段为“name”,输入赋值栅格为“pop_density”,输出栅格为“街区人口密度汇总”,统计类型为“总和”。
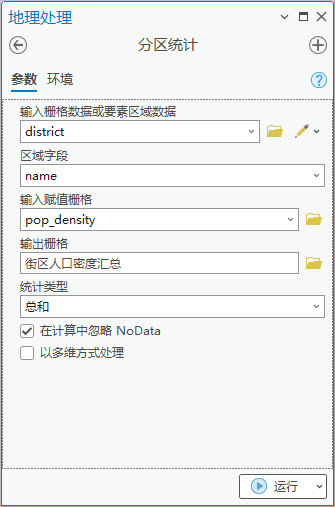
图5 分区统计
其结果如下图:
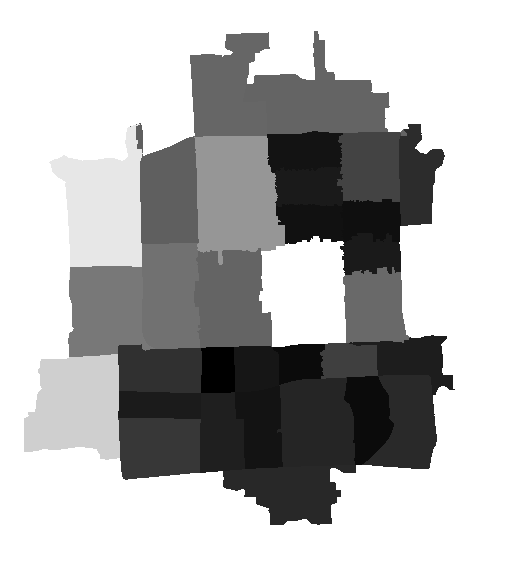

图6 街区人口密度汇总(最大最小拉伸法渲染)
2.点击【工具箱】|【数据管理工具】|【字段】|【计算字段】,输入表为“district”,字段名称(现有或新建)为“老年人占比”,字段类型为“浮点型(32 位浮点型)”,表达式为老年人占比= !老年人![0:4]。
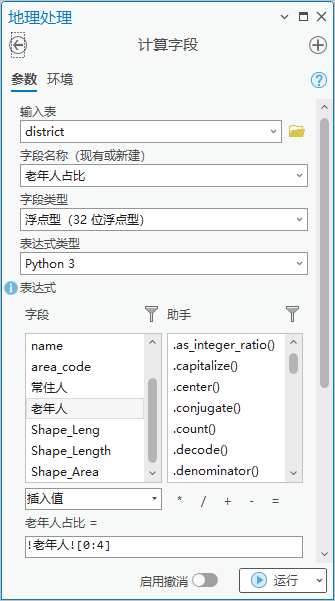
图7 计算字段
3. 点击【工具箱】|【数据管理工具】|【字段】|【计算字段】,输入表为“district”,字段名称(现有或新建)为“老年人数量”,字段类型为“浮点型(32 位浮点型)”,表达式为老年人数量= !常住人! * !老年人占比!/100。
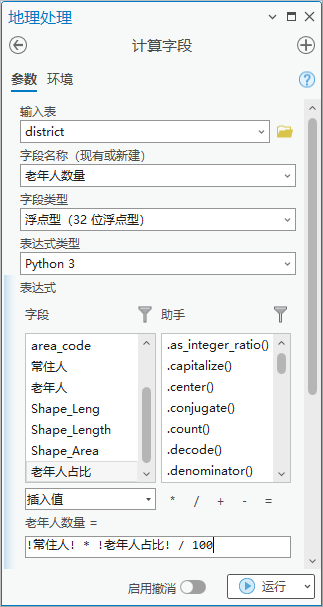
图8 计算字段
各街区老年人口如下:
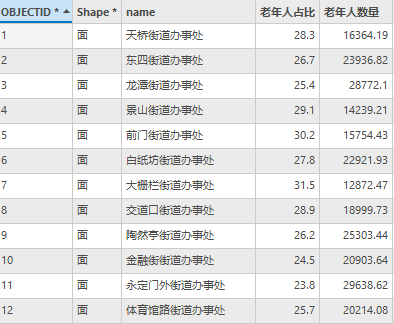
图9 District属性表(部分)
4.点击【工具箱】|【转换工具】|【转为栅格】|【面转栅格】,输入要素为“district”,值字段为“老年人数量”,输出栅格数据集为“老年人数量”,像元大小为5。
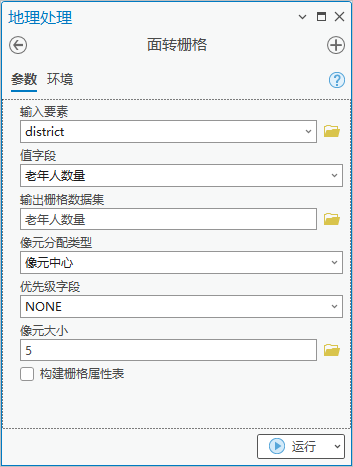
图10 面转栅格
运行结果如下图:
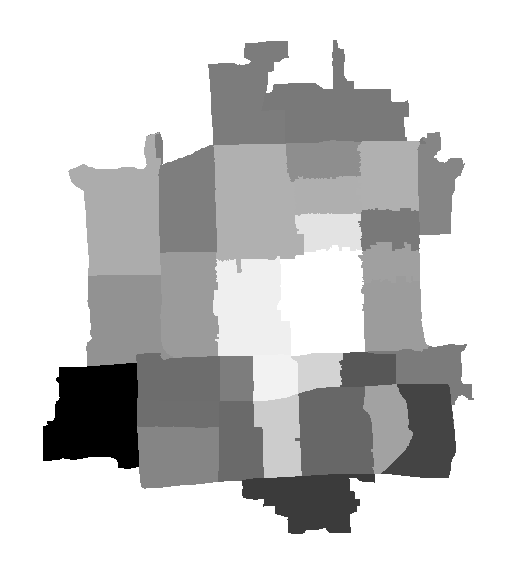

图11 老年人数量(最大最小拉伸法渲染)
5.点击【工具箱】|【空间分析工具】|【地图代数】|【栅格计算器】,算法为"pop_density" / "街区人口密度汇总" * "老年人数量",输出栅格为“老年人口分布”。
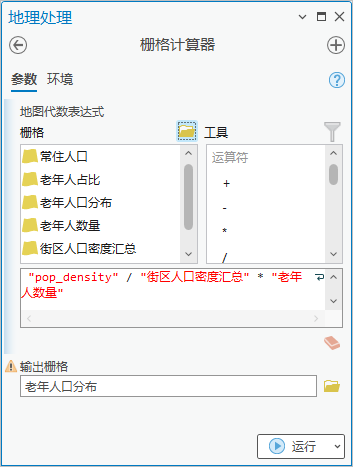
图12 栅格计算器
结果如下图所示:

图13 老年人口分布(最小最大拉伸法渲染)
方法2:
同方法1的1、2步。
3.点击【工具箱】|【转换工具】|【转为栅格】|【面转栅格】,输入要素为“district”,值字段为“老年人占比”,输出栅格数据集为“老年人占比”,像元大小为5。
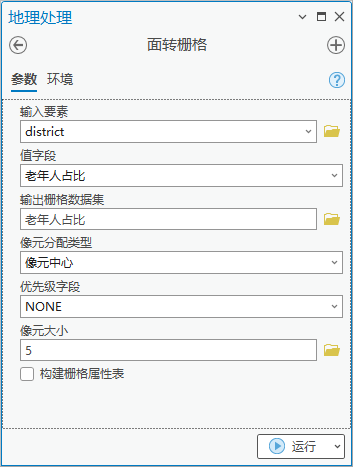
图14 面转栅格
结果如下:
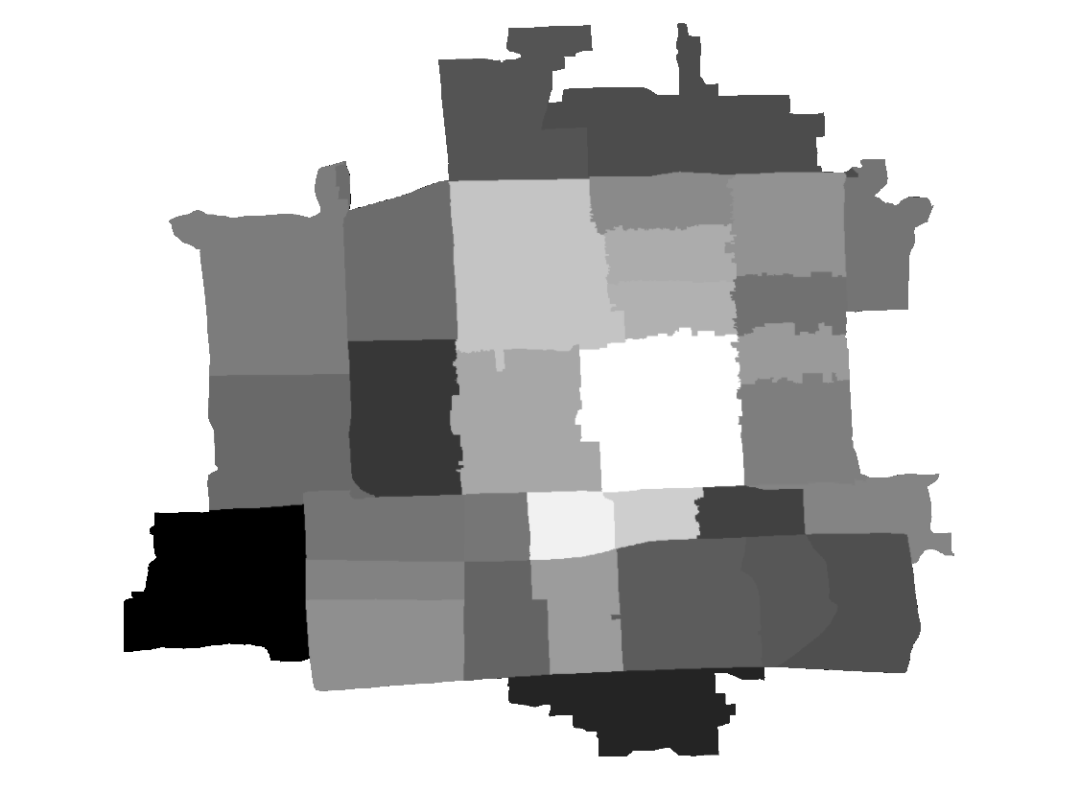
图15 老年人占比(最大最小拉伸法渲染)
4.点击【工具箱】|【转换工具】|【转为栅格】|【面转栅格】,输入要素为“district”,值字段为“常住人”,输出栅格数据集为“街区常住人口”,像元大小为5。
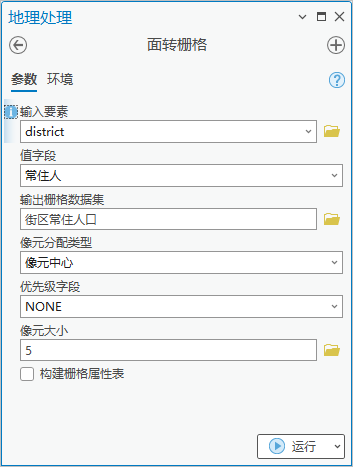
图16 面转栅格
结果如下:
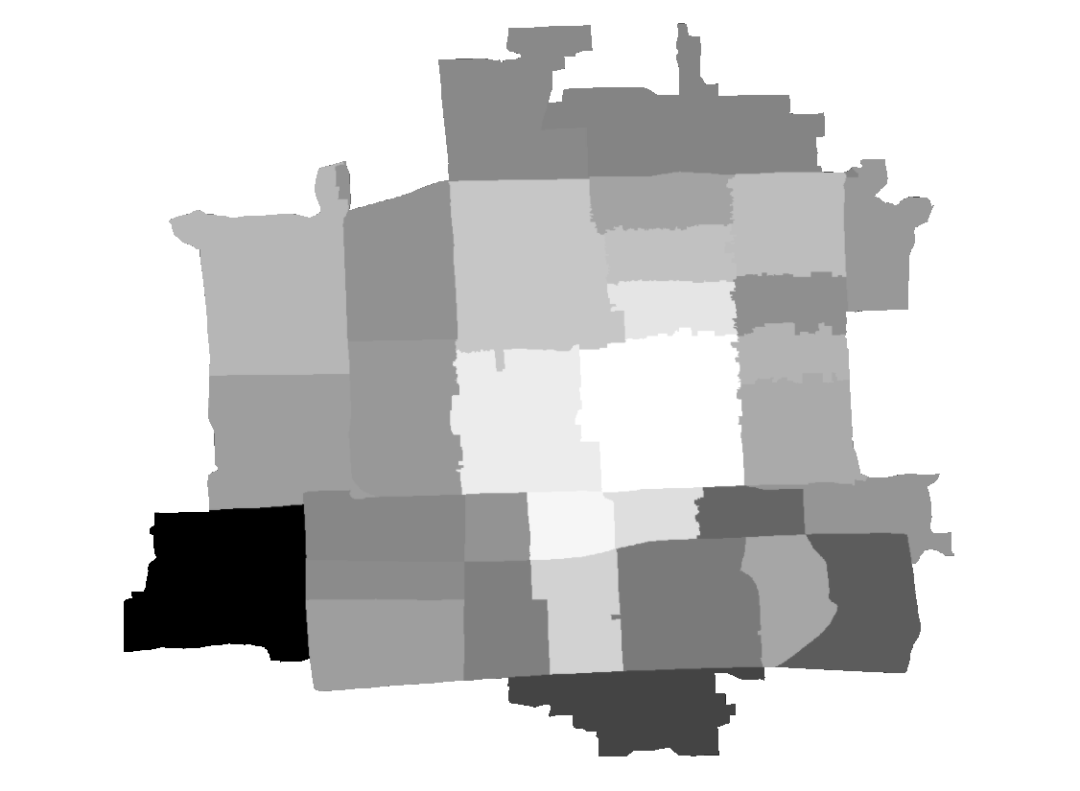

图17 街区常住人口(最大最小拉伸法渲染)
5. 点击【工具箱】|【空间分析工具】|【地图代数】|【栅格计算器】,算法为"pop_density" / "街区人口密度汇总" * "街区常住人口",输出栅格为“人口分布”,得出各像元的人口数量。
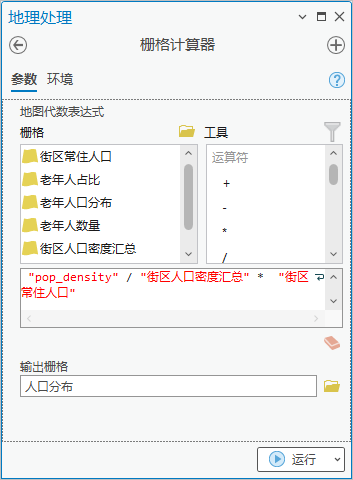
结果如下:

图18 人口分布(最大最小拉伸法渲染)
6. 点击【工具箱】|【空间分析工具】|【地图代数】|【栅格计算器】,算法为"人口分布" * "老年人占比"/100,输出栅格为“老年人口分布2”,得出各像元的人口数量。
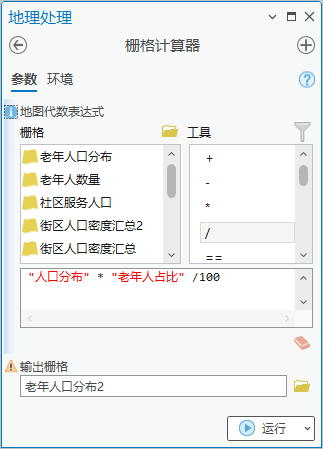
图19 栅格计算器
结果如下图所示:


图20 老年人口分布2(最大最小拉伸法渲染)
生成的老年人口分布中有空值,这会导致下一步统计社区老年人口时,部分社区结果为空,与实际情况不符,需要将空值转为0值,参与计算。
2.1.4 统计社区老年人口
1.点击【工具箱】|【空间分析工具】|【地图代数】|【栅格计算器】,算法为Con(IsNull("老年人口分布") ,0,"老年人口分布"),输出栅格为“修正后老年人口分布”,环境设置中掩膜为“community”。
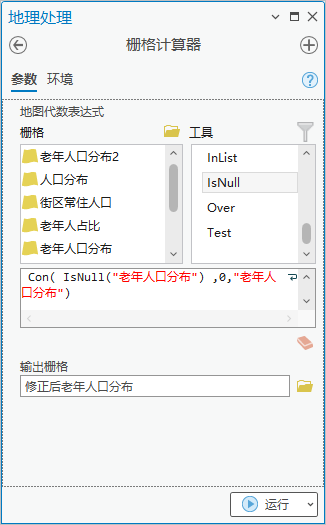
图21 栅格计算器
结果如下


图22 修正后老年人口分布
2.使用【工具箱】|【空间分析工具】|【区域分析】|【以表格显示分区统计】,输入栅格数据或要素区域数据为“community”,区域字段为“OBJECTID”,输入赋值栅格为“修正后老年人口分布”,输出表为“社区老年人口”,统计类型为“总和”。用于统计社区范围内老年人口。
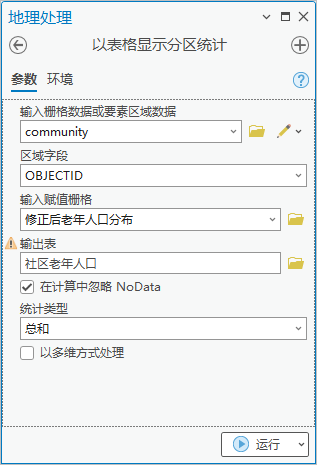
图23 以表格显示分区统计
其结果如下
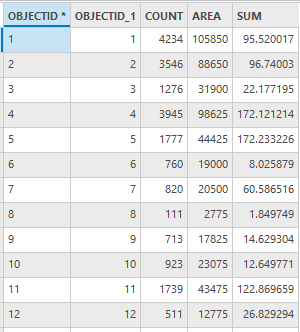
图24 社区老年人口属性表(部分)
SUM字段为社区老年人口数量。
3.点击【工具箱】|【数据管理工具】|【连接和关联】|【连接字段】,输入表为“community”,输入连接字段为“OBJECTID”,连接表为“社区老年人口”,连接表字段为“OBJECTID_1”,选择传输字段为“SUM”。将社区图层与社区老年人口挂接,获取老年人口信息。
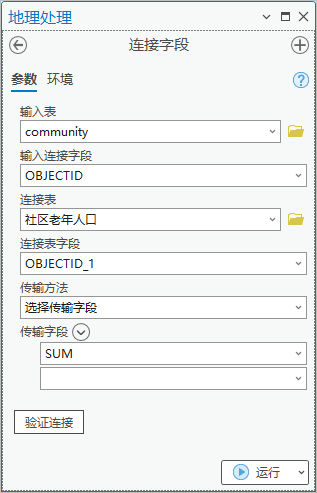
图25 连接字段
4.打开“community”属性表,将SUM字段中属性值为NULL的数据改为0。
5.【数据】菜单栏中,点击【数据设计】|【字段】,在字段视图中,修改SUM字段名称为老年人口,并保存。
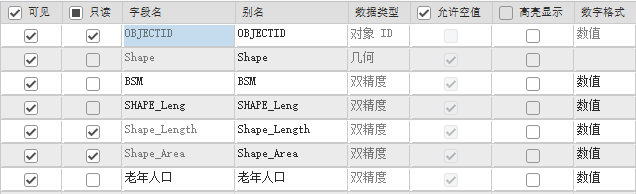
图26 编辑字段
最终的属性表如下:
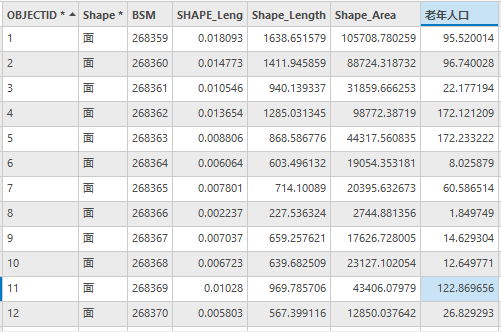
图27 Community属性表(部分)
2.2 绿地资源服务价值评估
2.2.1 人均绿地占比指数
2.2.1.1 计算人均绿地比
方法1:
1.点击【工具箱】|【分析工具】|【统计数据】|【范围内汇总】,输入面为“community”,输入汇总要素为“green_land”,输出要素类为“社区内绿地”,汇总字段为shape_area,统计数据为“总和”,(或者勾选“添加形状汇总属性” ,区别在于结果单位不同)。
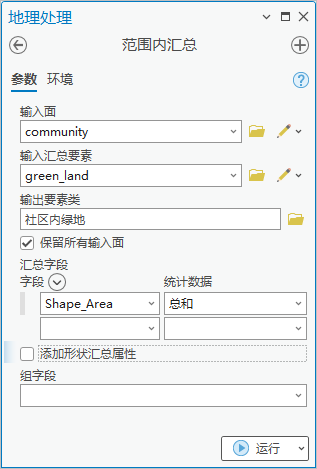
图28 范围内汇总
2. 点击【工具箱】|【数据管理工具】|【连接和关联】|【连接字段】,输入表为“community”,输入连接字段为“BSM”,连接表为“社区内绿地”,连接表字段为“BSM”,选择传输字段为“SUM shape_area”。(输入连接字段也可以选择OBJECTID)
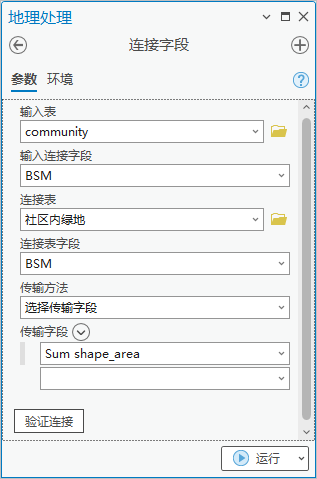
图29 连接字段
3. 修改SUM shape_area字段名称为绿地面积。
4.点击【工具箱】|【数据管理工具】|【字段】|【计算字段】,输入表为“community”,字段名称(现有或新建)为“人均绿地占比指数”,字段类型为“浮点型(32 位浮点型)”,表达式为人均绿地占比指数= !绿地面积! / !老年人口!。
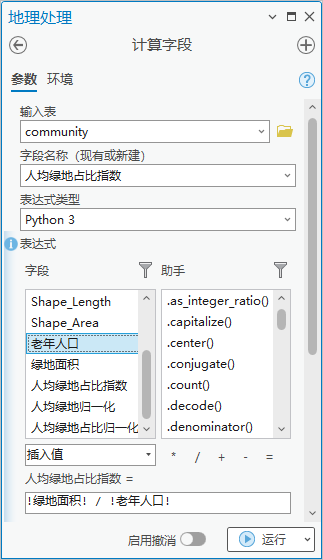
图30 计算字段
5.计算结果中有部分数据为空,原因在于人口数据为0,将值补为0,保存数据。
当前属性表如下:
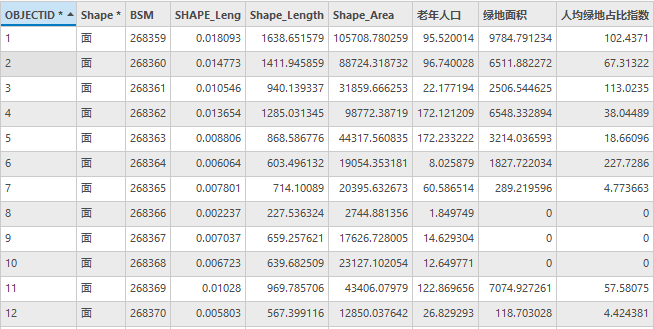
图31 Community属性表(部分)
方法2:
1. 点击【分析工具】|【叠加分析】|【相交】工具,输入要素为“green land”和“community”,输出要素类为“社区内绿地”。
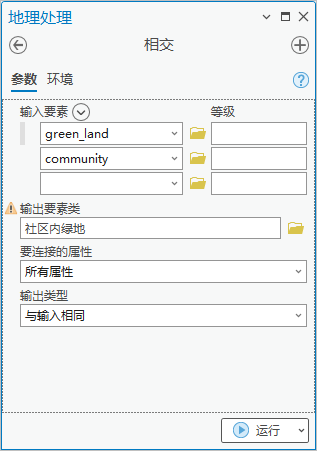
图32 相交
2.点击【工具箱】|【分析工具】|【统计数据】|【汇总统计数据】,输入表为“社区内绿地”,输出表为“社区内绿地汇总”,统计字段shape_area,统计类型为“总和”,案例分组字段为BSM字段(案例分组字段也可使用OBJECTID字段)。
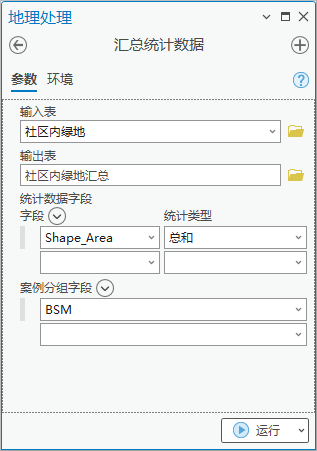
图33 汇总统计数据
3. 点击【工具箱】|【数据管理工具】|【连接和关联】|【连接字段】,输入表为“community”,输入连接字段为“BSM”,连接表为“社区内绿地汇总”,连接表字段为“BSM”,选择传输字段为“SUM_shape_area”。
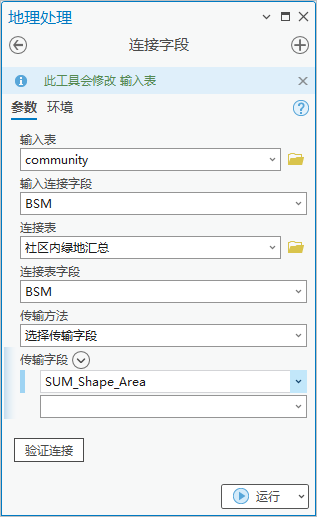
图34 连接字段
连接字段后属性表如下:
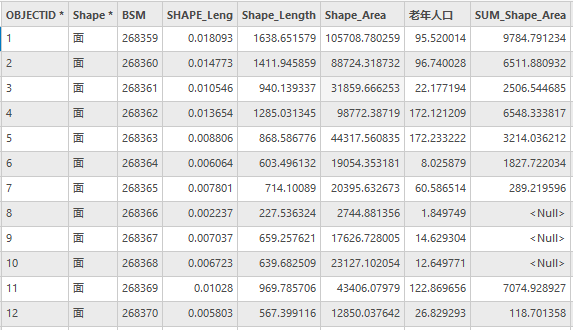
图35 Community属性表(部分)
之后的步骤与方法1的3-5步相同。
2.2.1.2 归一化
方法1:
观察人均绿地占比指数字段数据范围,得到最大值为1566.63513184,最小值为0。
点击【工具箱】|【数据管理工具】|【字段】|【计算字段】,输入表为“community”,字段名称(现有或新建)为“人均绿地归一化”,字段类型为“浮点型(32 位浮点型)”,表达式为人均绿地归一化= !人均绿地占比指数! / 1566.63513184。
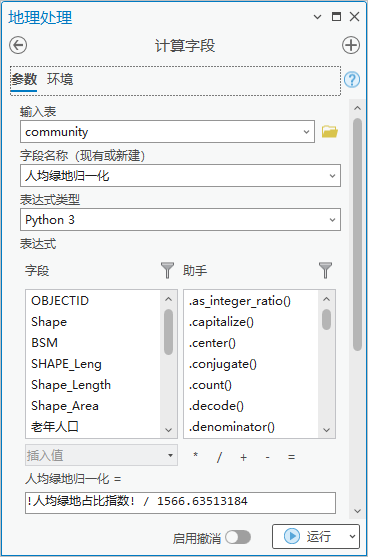
图36 计算字段
结果如下:
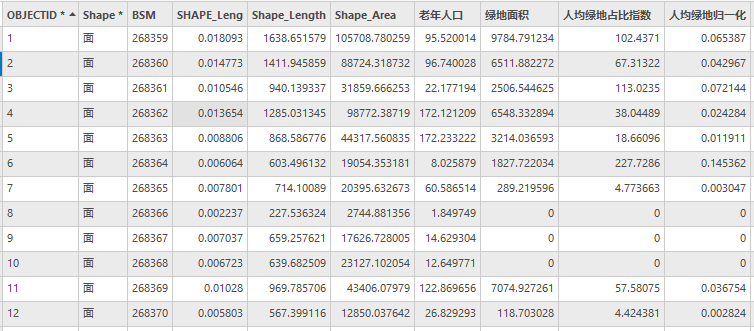
图37 Community属性表(部分)
方法2:
点击【工具箱】|【数据管理工具】|【字段】|【标准化字段】,输入表为“community”,标准化方法为“最小值 - 最大值”,要标准化的字段为“人均绿地占比指数”,输出字段为“人均绿地占比归一化”。
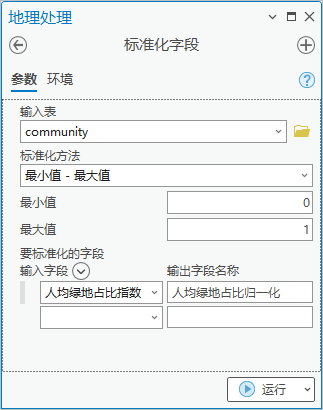
图38 标准化字段
2.2.2 绿地服务价值指数
2.2.2.1 统计目标服务人群
1. 点击【工具箱】|【数据管理工具】|【要素】|【要素转点】,输入要素为“community”,输出要素类为“community中心点”,勾选“内部”。
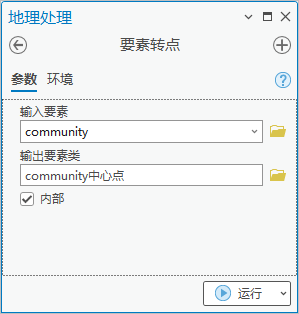
图39 要素转点
2.点击【工具箱】|【分析工具】|【邻近分析】|【缓冲区】,输入要素为“community中心点”,输出要素类为“服务区”,距离为500米。
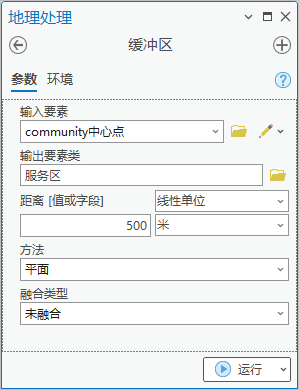
图40 缓冲区
3.使用【工具箱】|【空间分析工具】|【区域分析】|【以表格显示分区统计】,输入栅格数据或要素区域数据为“服务区”,区域字段为“ORIG_FID”,输入赋值栅格为“修正后老年人口分布”,输出表为“社区服务老年人口”,统计类型为“总和”。统计服务区内老年人口。
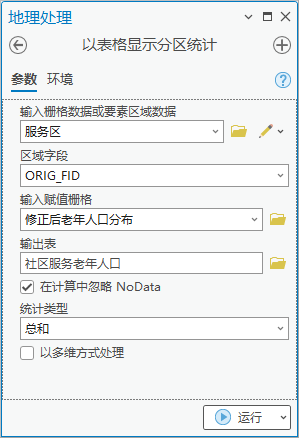
图41 以表格显示分区统计
其结果如下
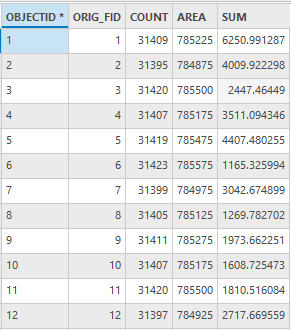
图42 社区服务老年人口属性表(部分)
SUM字段为社区服务老年人口数量。
4. 点击【工具箱】|【数据管理工具】|【连接和关联】|【连接字段】,输入表为“community”,输入连接字段为“OBJECTID”,连接表为“社区服务老年人口”,连接表字段为“ORIG_FID”,选择传输字段为“SUM”。社区图层连接社区服务老年人口字段。
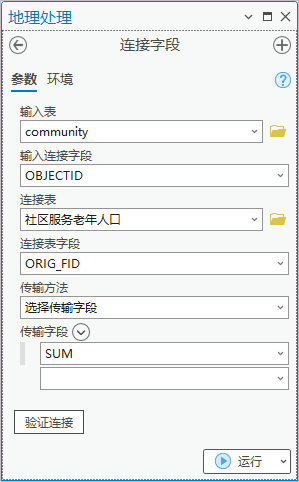
图43 连接字段
5.【数据】菜单栏中,点击【数据设计】|【字段】, 修改SUM字段名称为服务老年人口,并保存,结果如下。
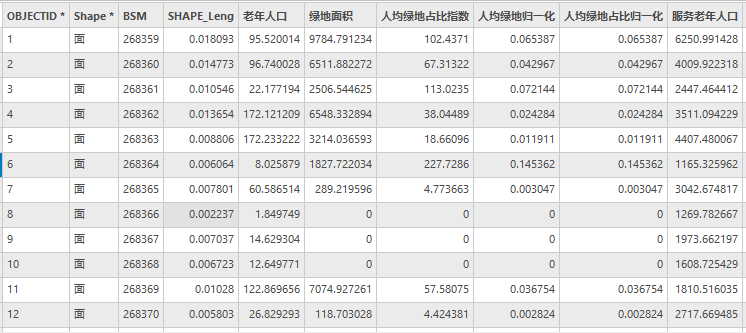
图44 Community属性表(部分)
2.2.2.2 计算绿地服务价值
点击【工具箱】|【数据管理工具】|【字段】|【计算字段】,输入表为“community”,字段名称(现有或新建)为“绿地服务价值指数”,字段类型为“浮点型(32 位浮点型)”,表达式为绿地服务价值指数= ex(!服务老年人口!,!绿地面积!)。
代码为
def ex(a,b):if (b==0):return 0else:return a/b
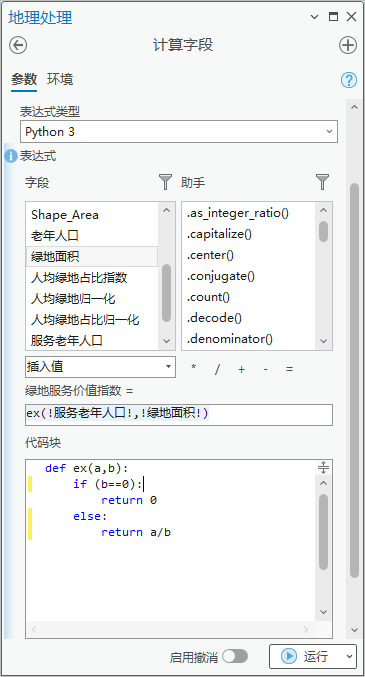
图45 计算字段
其计算结果如下:
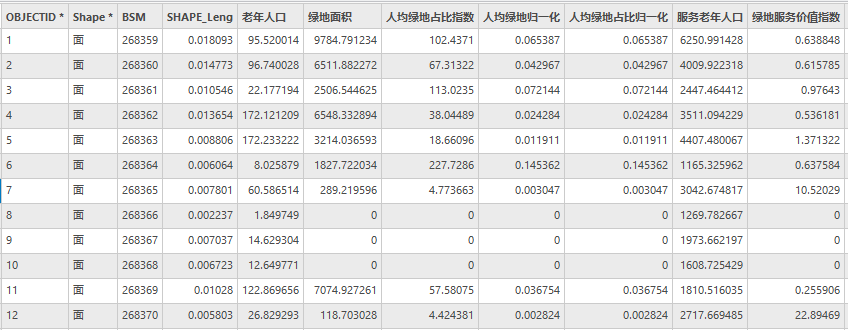
图46 Community属性表(部分)
2.2.3 查找社区
2.2.3.1 查找排名前500社区
1.打开community属性表,对人均绿地占比指数进行降序排列,记录第500项数值为15.96234131,同样方法找到绿地服务价值指数的第500项为11.65918159。
2.点击【工具箱】|【数据管理工具】|【图层和表视图】|【按属性选择图层】,输入图层为“community”,表达式为 Where 人均绿地占比指数 大于或等于 15.96234131 And 绿地服务价值指数 大于或等于11.65918159。
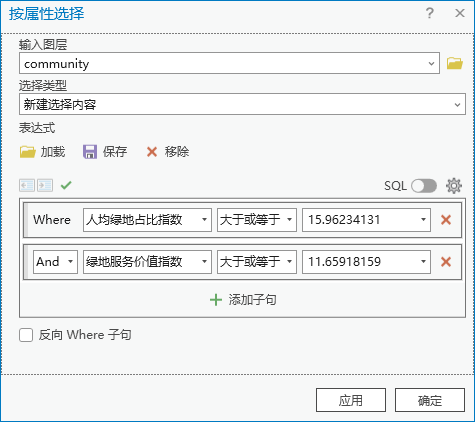
图47 按属性选择图层
共有34条记录被选中。
3.点击【工具箱】|【数据管理工具】|【字段】|【计算字段】,输入表为“community”,字段名称(现有或新建)为“社区类型”,字段类型为“文本”,表达式为社区类型=“标杆社区”。
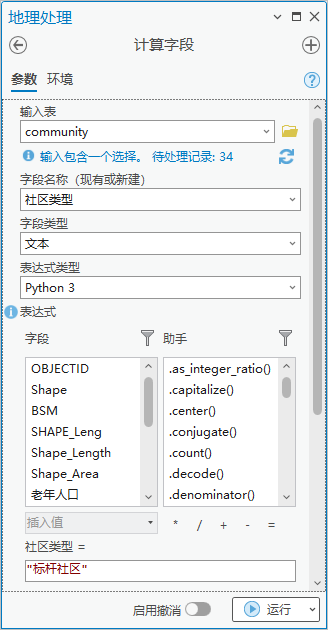
图48 计算字段
2.2.3.2 查找排名后500社区
同样的方法找到后500名,这里不在赘述。后500名的两个指标均为0,共有814个要素。
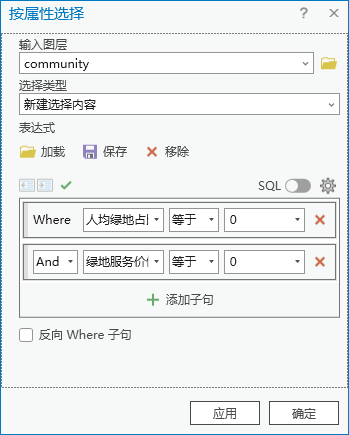
图49 按属性选择
并将选中的500个要素补充社区类型为优化社区。
2.2.3.3 分类渲染
切换到【要素图层】菜单栏,点击【绘制】|【符号系统】|【唯一值】。
字段选择“社区类型”,依次为优化社区和标杆社区选择蓝色和绿色。效果如下:
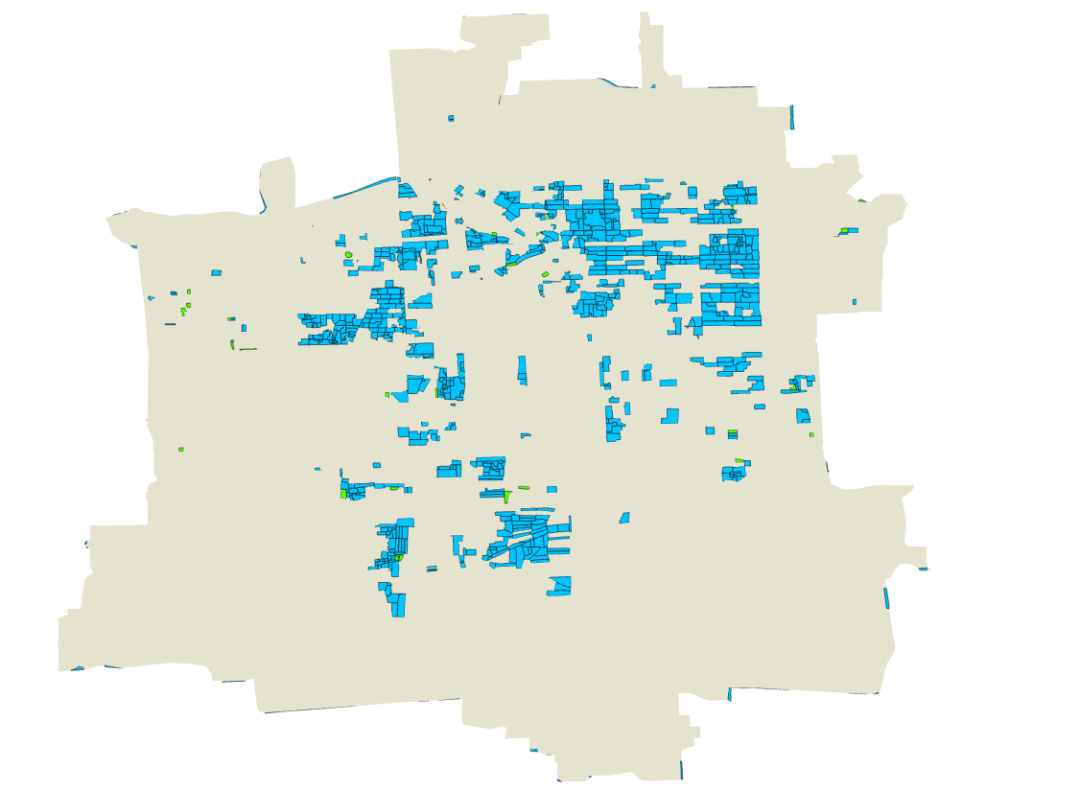

图50 按社区类型分类渲染
2.3 医疗设施可达性分析
2.3.1 医院合并
方法1:
点击【工具箱】|【数据管理工具】|【常规】|【删除相同项】,输入数据集为“hospital”,字段为“shape”,xy容差为100米。
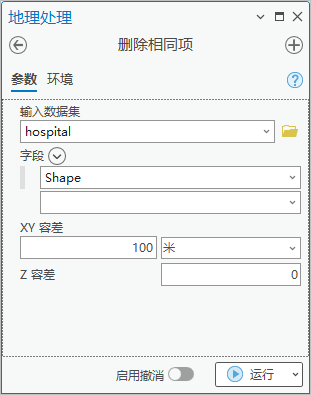
图51 删除相同项
这种方法将保留医院的原始位置,共计338个医院被保留,且包含对应属性。后续演示均使用该方法得到的结果做为合并后的医院。
方法2:
1.点击【工具箱】|【数据管理工具】|【要素类】|【整合】,输入要素为“hospital”,环境中设置xy容差为100米。
图52 整合
2.点击【工具箱】|【数据管理工具】|【常规】|【删除相同项】,输入数据集为“hospital”,字段为“shape”。
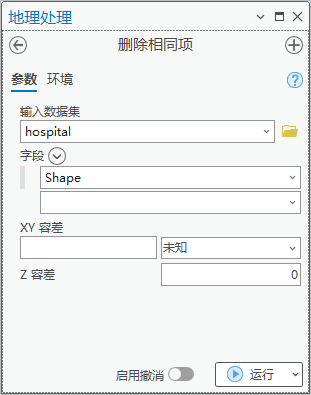
图53 删除相同项
这种方法将调整医院的原始位置,共计219个医院被保留。
方法3:
1.点击【工具箱】|【制图工具】|【制图综合】|【聚合点】,输入要素为“hospital”,输出要素类为“hospital聚合”,聚合距离为100米。
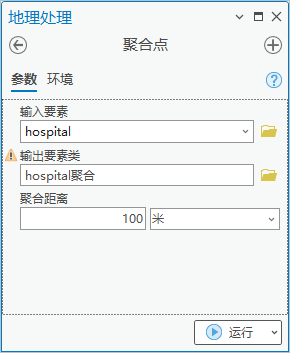
图54 聚合点
生成53个聚合面。
2.点击【工具箱】|【数据管理工具】|【要素】|【要素转点】,输入要素为“hospital聚合”,输出要素类为“hospital聚合点”,勾选“内部”。
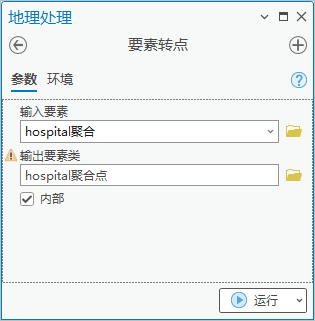
图55 要素转点
3. 点击【工具箱】|【数据管理工具】|【图层和表视图】|【按位置选择图层】,输入图层为“hospital”,关系选择“位于”,选择要素为“hospital聚合”,选中聚合面覆盖的医院。
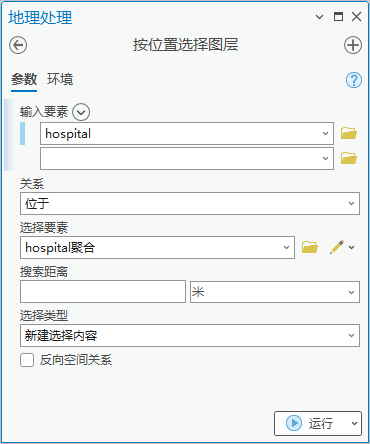
图56 按位置选择图层
4.删除聚合面覆盖的医院,删除后剩余281个要素。
5. 点击【工具箱】|【数据管理工具】|【常规】|【合并】,输入数据集为“hospital”和“hospital聚合点”,输出数据集为“合并后hospital”,共计334 个医院。
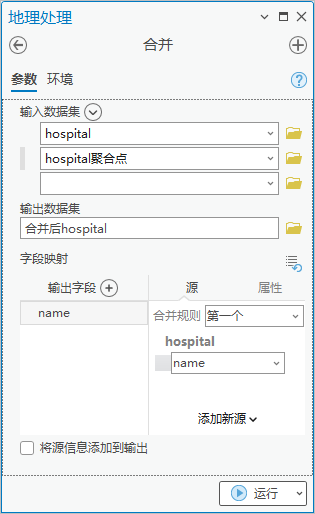
图57 合并
方法4:
1.点击【工具箱】|【分析工具】|【邻近分析】|【缓冲区】,输入要素为“hospital”,输出要素类为“hospital缓冲”,距离为100米。
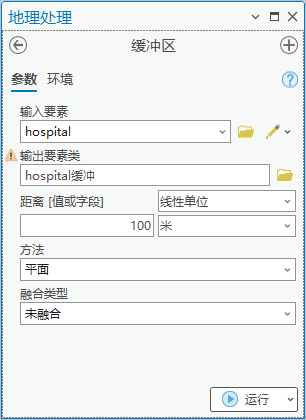
图58 缓冲区
2. 点击【工具箱】|【数据管理工具】|【栅格综合】|【融合】,输入要素为“hospital缓冲”,输出要素类为“hospital缓冲融合”,取消创建多部件要素。
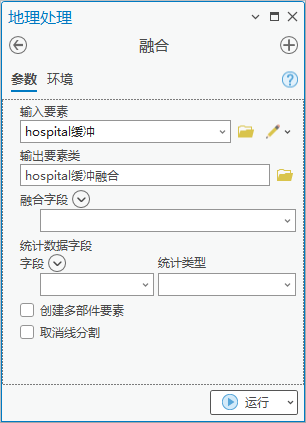
图59 融合
3. 点击【工具箱】|【数据管理工具】|【要素】|【要素转点】,输入要素为“hospital缓冲融合”,输出要素类为“hospital点”,勾选“内部”。
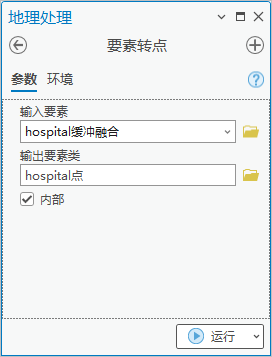
图60 要素转点
会得到241个医院。
方法5:
1.点击【工具箱】|【空间统计工具】|【聚类分布制图】|【基于密度的聚类】,输入点要素为“hospital”,输出要素为“hospital密度聚类”,聚类方法为“定义的距离”,每个聚类的最小要素数为2,搜索距离为100米。
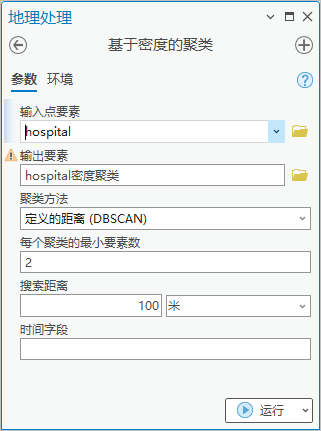
图61 基于密度的聚类
得到的聚类结果如下:
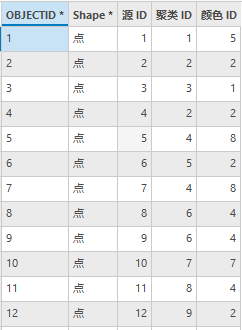
聚类ID字段表示点所属的聚类,如果属性值为-1表示未聚类。
2. 点击【工具箱】|【数据管理工具】|【图层和表视图】|【按属性选择图层】,输入图层为“hospital密度聚类”,表达式为 Where 聚类ID 不等于 -1。选中可以聚类的要素。
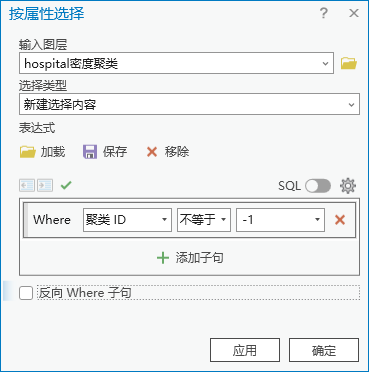
图62 按属性选择图层
3. 点击【工具箱】|【数据管理工具】|【常规】|【删除相同项】,输入数据集为“hospital密度聚类”,字段为“聚类ID”。即聚类的要素只保留一个。
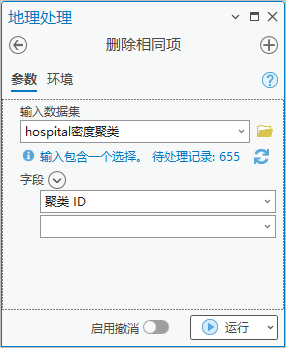
图63 删除相同项
这种方法得到的合并后医院要素共计285个。
各种方法得到的医院分布如下:





图64 不同方法医院分布
2.3.2 社区与医院连接
2.3.2.1 构建网络数据集
1.点击【工具箱】|【数据管理工具】|【工作空间】|【创建要素数据集】,输出地理数据库为“temp_data.gdb”,要素数据集名称为roads,坐标系为“CGCS2000_3_Degree_GK_CM_117E”。
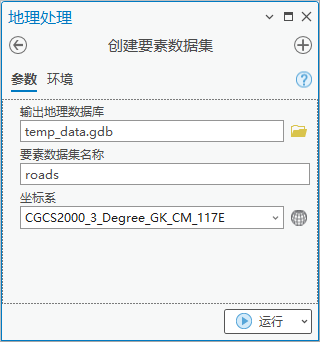
图65 创建要素数据集
2.目录视图中,将road要素拽到roads数据集中。
3.点击【工具箱】|【网络分析工具】|【网络数据集】|【创建网络数据集】,目标要素数据集为“roads”, 网络数据集名称为“道路”,勾选road为源要素类,高程模型为“无高程”。
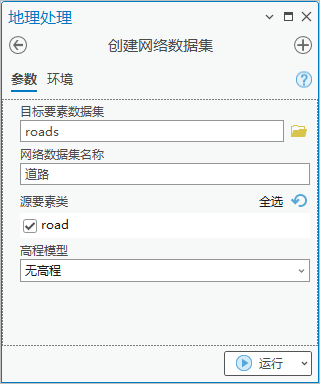
图66 创建网络数据集
4.目录中打开道路数据集的属性,【源设置】中【组连通性】改为【任意节点】。
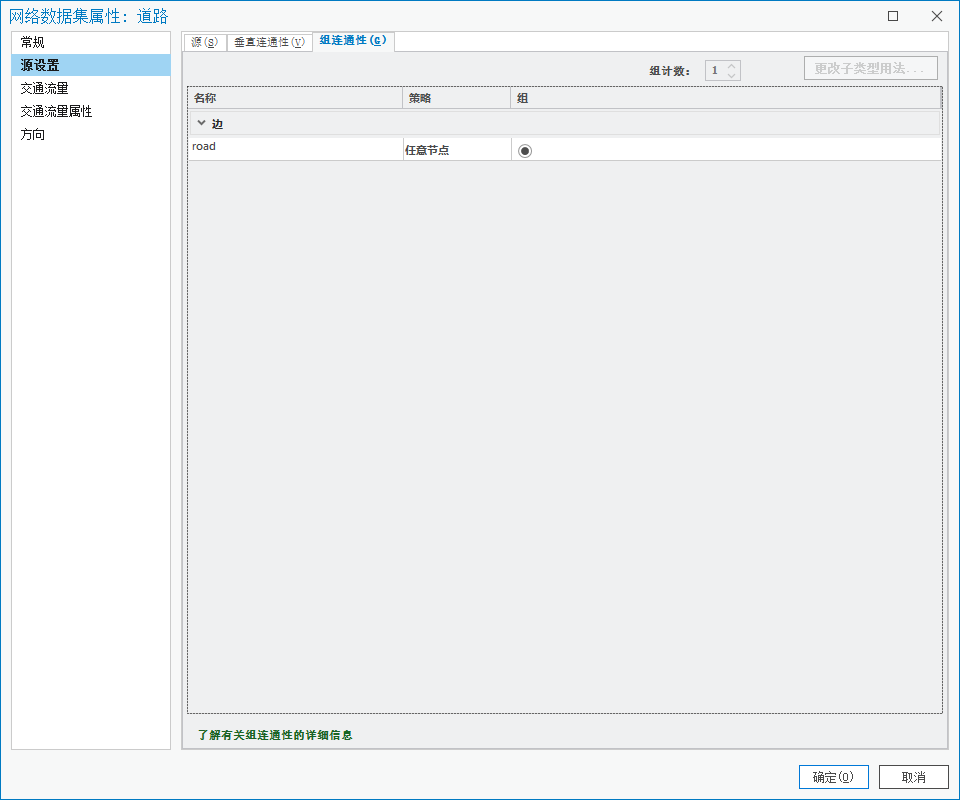
图67 设置网络数据集属性
Tips:也可以提前将道路数据打断,再构建网络数据集。
5.点击【工具箱】|【网络分析工具】|【网络数据集】|【构建网络】,输入网络数据集为“道路”。完成网络数据集构建。
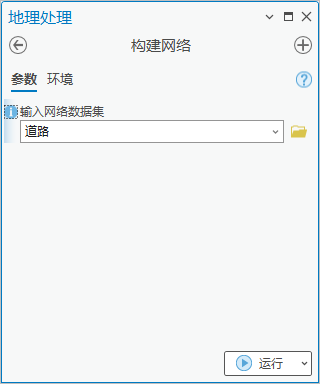
图68 构建网络
2.3.2.2 分析最近设施
1. 切换到【分析】菜单栏,点击【工作流】|【网络分析】|【最近设施点】。

图69 创建最近设施点图层组
2.切换到【最近设施点图层】菜单栏,点击【输入数据】|【导入设施点】,输入网络分析图层为“最近设施”,子图层为“设施点”,输入位置为“hospital”(合并后的医院)
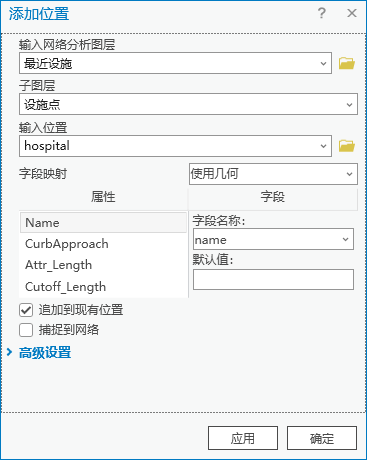
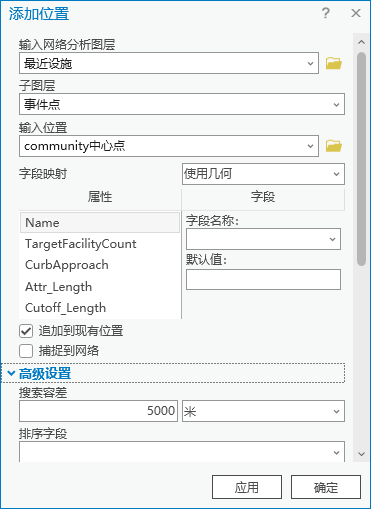
图70 添加位置
3.同样方法设置导入事件点。
4.切换到【最近设施点图层】菜单栏,点击【输出几何】|【直线】。
5.切换到【最近设施点图层】菜单栏,点击【分析】|【运行】,结果如下图。
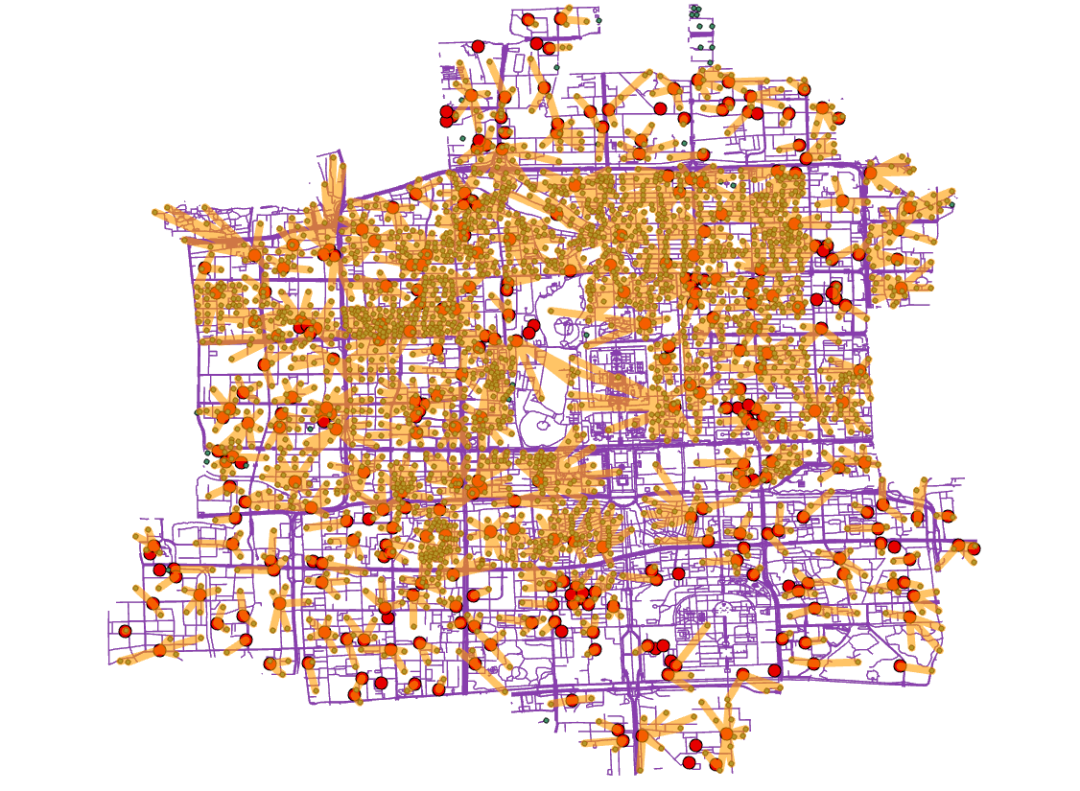
图71 最近设施分析结果
放大局部如下:
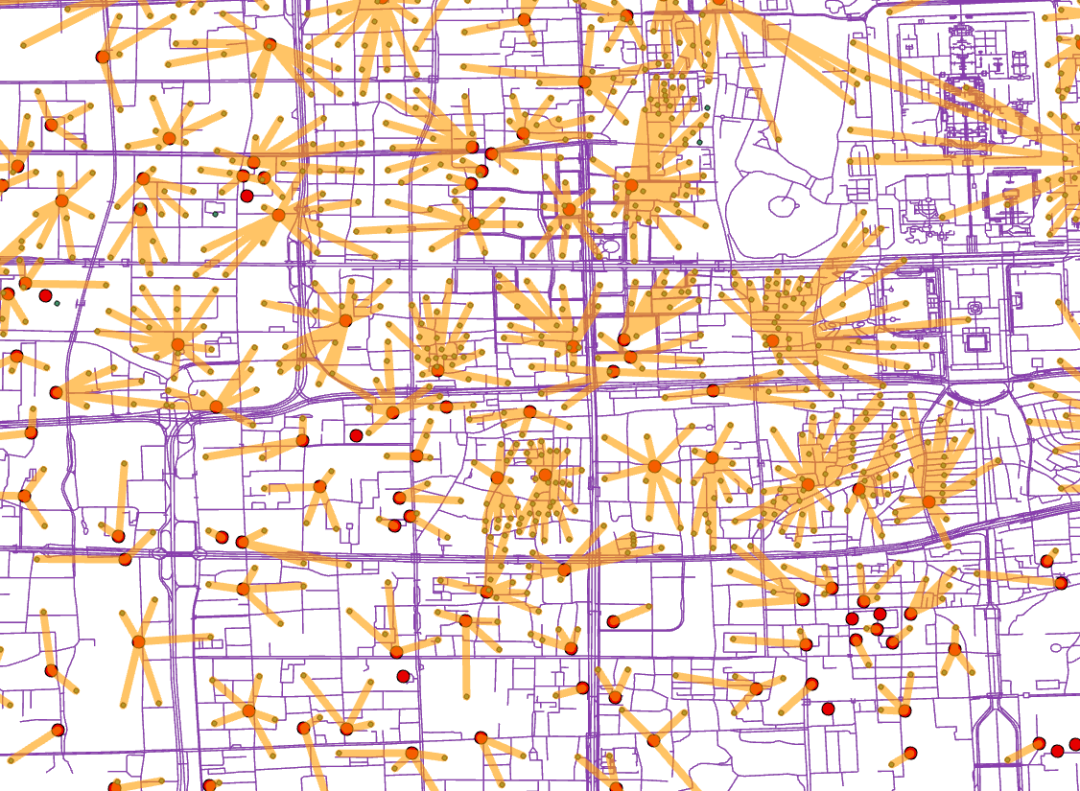
图72 最近设施分析结果(局部)
其属性表如下
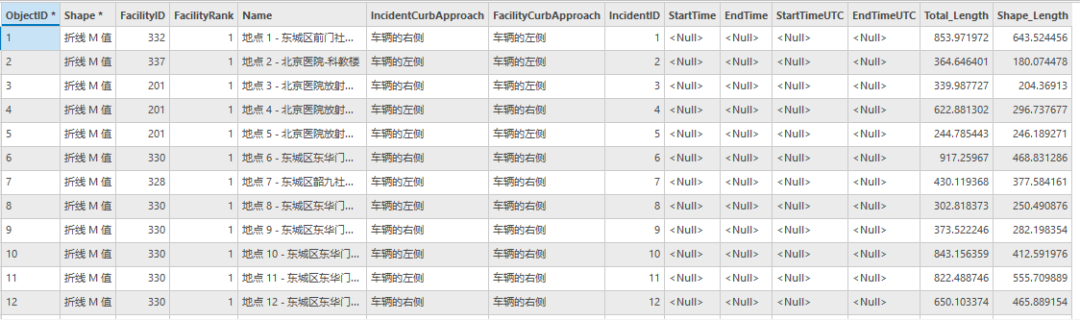
图73 路径属性表(部分)
FacilityID表示设施点即医院的唯一ID,IncidentID表示社区中心点唯一ID。Total_Length表示路线长度。需要注意医院的唯一ID跟hospital图层的唯一ID不同,原因在于hospital图层删除过相同项。
PS:选择不同的合并医院的方法,或者构建网络时对数据进行了提前打断处理等操作,都会导致得到的最近设施点分析结果不同。
2.3.2.3 绘制社区医院关系图
【要素图层】菜单栏中,点击【绘制】|【符号系统】|【分级符号】。字段选择“Total_length”,选择方法及配色。
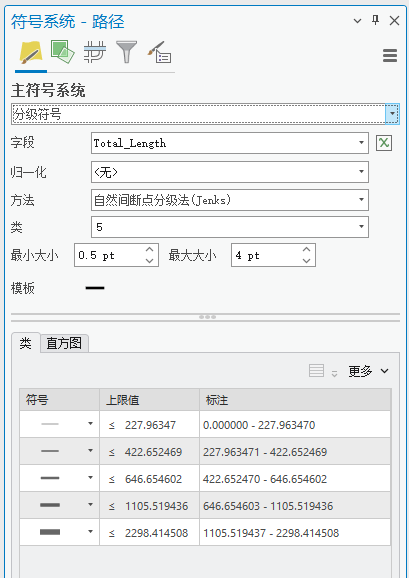
图74 符号设置
结果如下图所示:
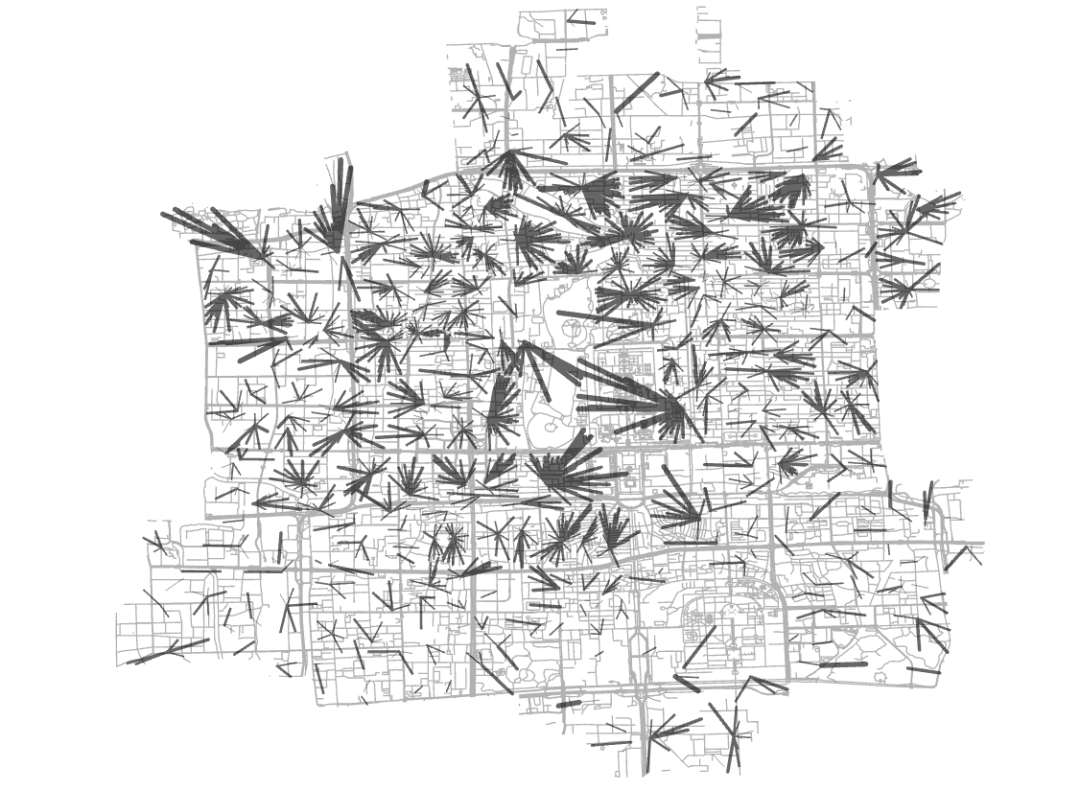
图75 社区医院关系连线
2.3.3 构建医疗服务圈
1.点击【工具箱】|【数据管理工具】|【连接和关联】|【添加连接】,输入表为“community”,输入连接字段为“OBJECTID”,连接表为“路径”,连接表字段为“IncidentID”。将community图层挂接上路径,路径中包含医院信息。
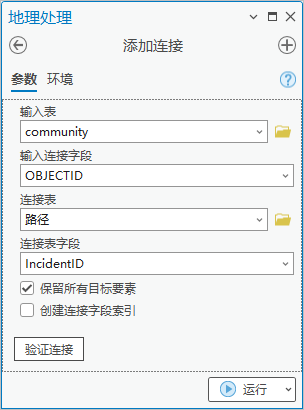
图76 添加连接
PS:路径中的IncidentID表示事件点ID,也就是“community中心点”的OBJECTID,与“community”的OBJECTID一致。
2. 点击【工具箱】|【数据管理工具】|【栅格综合】|【融合】,输入要素为“community”,输出要素类为“医疗服务圈”,融合字段为“FacilityID”。
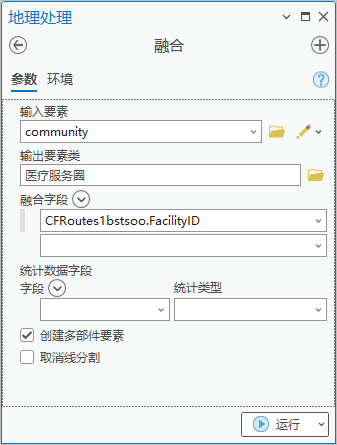
图77 融合
融合后结果如下:
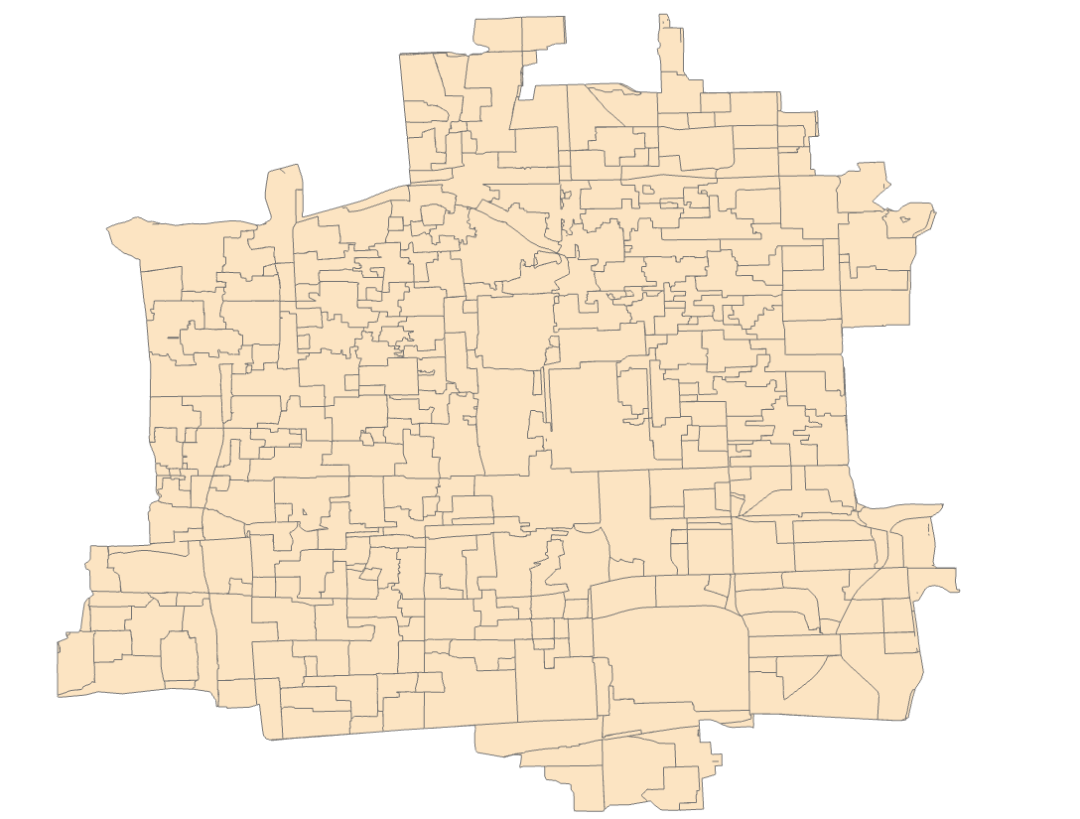
图78 医疗服务圈分布
共计300个服务圈。属性表中没有包含医院名称,可以通过与设施点图层进行连接获取到对应的医院名称。
2.4 服务设施规划选址
2.4.1 查找社区
方法1:
1.点击【工具箱】|【分析工具】|【邻近分析】|【面邻域】,输入要素为“community”,输出表为“community邻域”,勾选“包括区域重叠”和“包括邻域关系的两侧”。
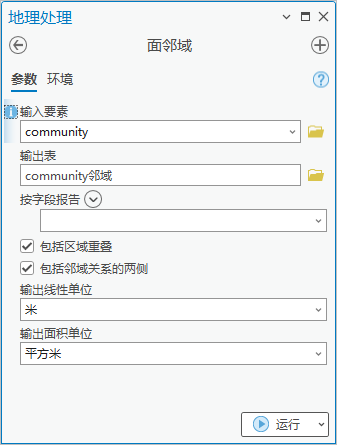
图79 面邻域
其表结构如下:
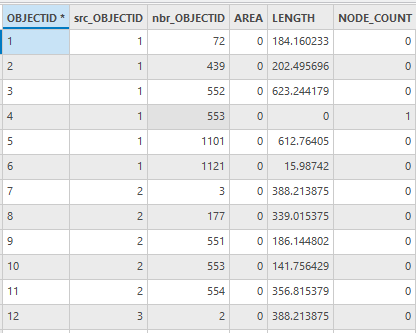
图80 community邻域表(部分)
Src_OBJECTID字段表示研究对象ID,nbr _OBJECTID字段表示邻近对象ID。得到社区的邻接社区。
2. 点击【工具箱】|【数据管理工具】|【连接和关联】|【添加连接】,输入表为“community邻域”,输入连接字段为“nbr_OBJECTID”,连接表为“community”,连接表字段为“OBJECTID”。得到社区的各邻接社区老年人口。
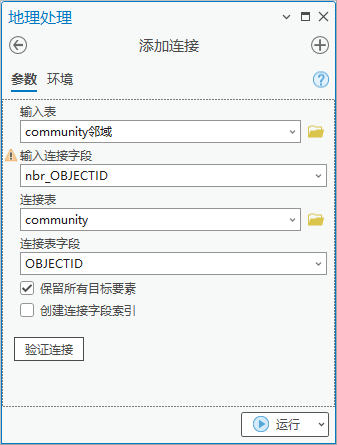
图81 添加连接
3.点击【工具箱】|【分析工具】|【统计数据】|【汇总统计数据】,输入表为“community邻域”,输出表为“community邻域人口”,统计字段老年人口,统计类型为“总和”,案例分组字段为src_OBJECTID字段。用于汇总社区的邻接社区总的老年人口。
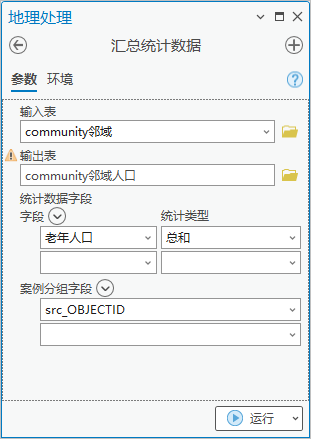
结果如下:
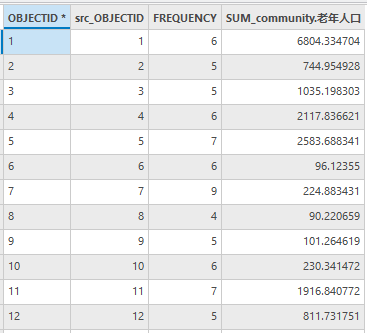
图82 community邻域人口属性表(部分)
4.点击【工具箱】|【数据管理工具】|【连接和关联】|【连接字段】,输入表为“community”,输入连接字段为“OBJECTID”,连接表为“community邻域人口”,连接表字段为“src_OBJECTID”,选择传输字段为“老年人口”。
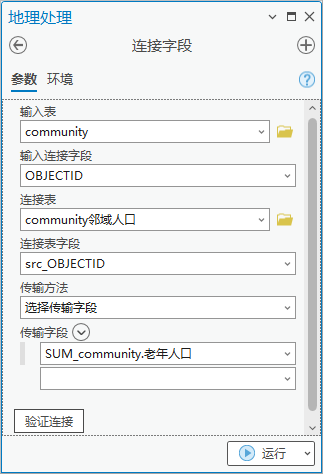
图83 添加字段
5. 【数据】菜单栏中,点击【数据设计】|【字段】,在字段视图中,修改字段SUM_community.老年人口名称为邻接社区老年人口,并保存。
6. 点击【工具箱】|【数据管理工具】|【图层和表视图】|【按属性选择图层】,输入图层为“community”,表达式为 Where 老年人口 大于 300 And 邻接社区老年人口 大于2000。
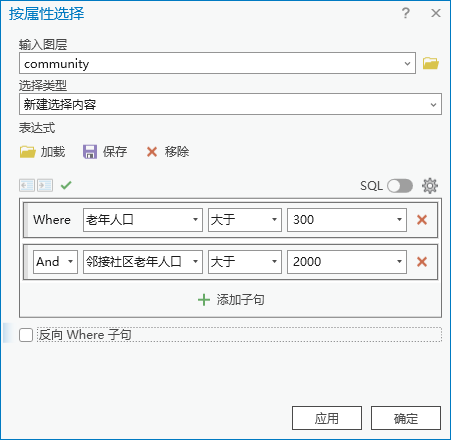
图84 按属性选择
结果共计441个符合条件的社区。
7.点击【工具箱】|【转换工具】|【转出至地理数据库】|【导出要素】工具,输入要素为“community”,输出要素类命名为“符合条件社区”。
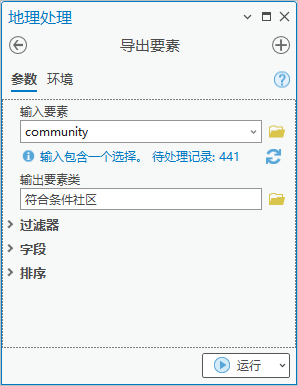
图85 导出要素
结果如下图所示
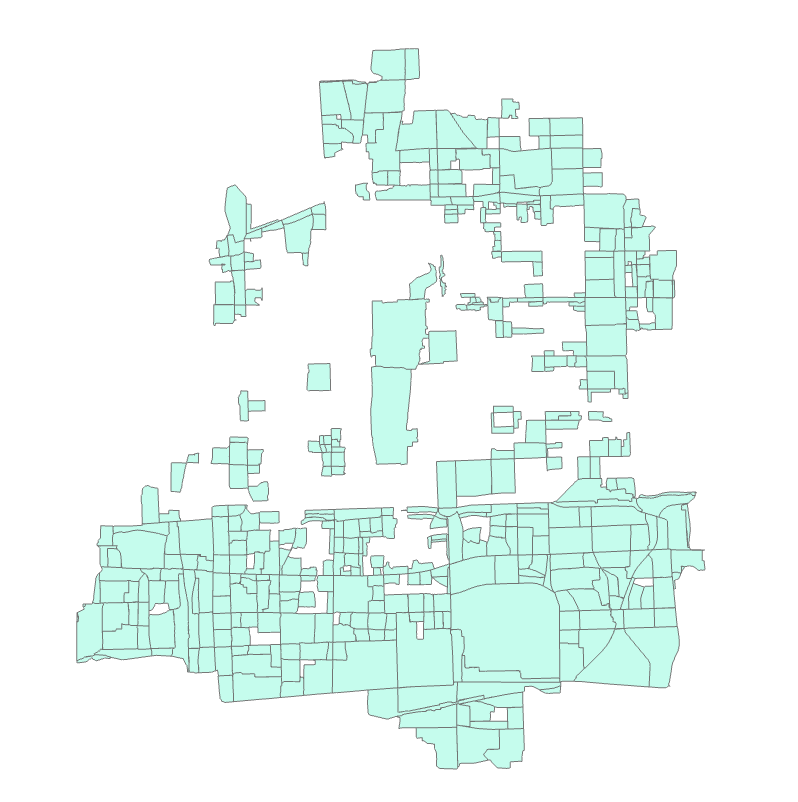
图86 符合条件社区
方法2:
点击【工具箱】|【分析工具】|【邻近分析】|【生成近邻表】,输入要素为“community”,邻近要素为“community”,输出表为“community近邻”,搜索半径为0米,取消勾选“仅查找最近的要素”。
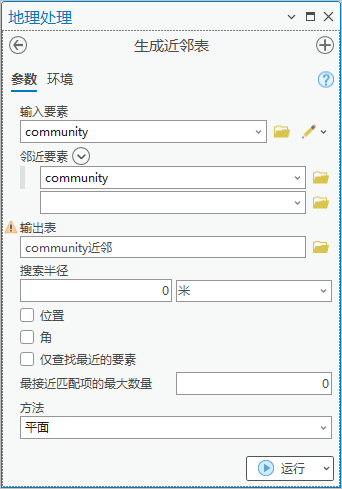
图87 生成近邻表
其表结构如下:
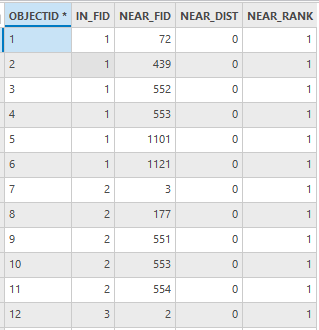
图88 community近邻表(部分)
IN_FID字段表示研究对象ID ,NEAR_FID字段表示邻近对象ID。
后续步骤与方法1的2-8不相同,这里就不在赘述。
方法3:
1. 点击【工具箱】|【空间统计工具】|【度量地理分布】|【邻域汇总统计数据】,输入要素为“community”,分析字段选择“老年人口”,输出要素为“community邻域老年人口”,部分汇总统计数据为“平均值”,邻域类型为“邻域边拐角”。
得到邻域社区的平均老年人口。
2.点击【工具箱】|【数据管理工具】|【字段】|【计算字段】,输入表为“community邻域老年人口”,字段名称(现有或新建)为“邻域老年人口”,字段类型为“浮点型(32 位浮点型)”,表达式为邻域老年人口= !老年人口_Mean! * !老年人口_NNBRS!。(平均老年人口*邻域数量)
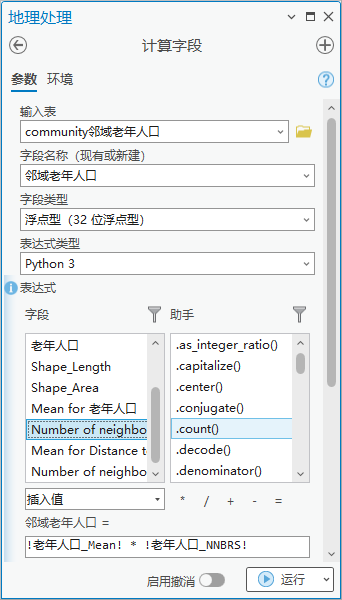
图89 计算字段
得到的各社区邻域老年人口如下:
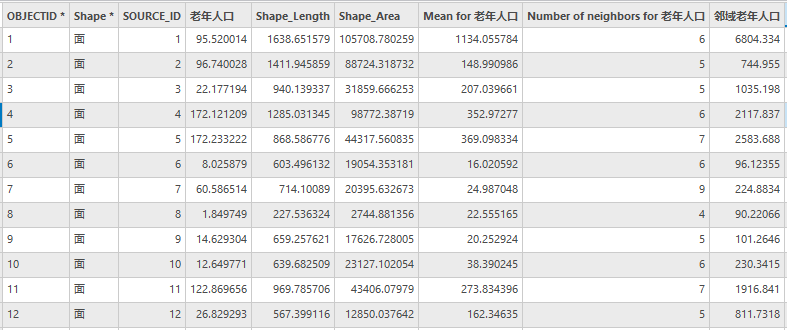
图90 community邻域老年人口属性表(部分)
后续步骤与方法1中4-8步相同。
方法4:
1.点击【工具箱】|【数据管理工具】|【字段】|【计算字段】,输入表为“community”,字段名称(现有或新建)为“唯-ID”,字段类型为“短整型(16 位整型)”,表达式为唯-ID =! community.OBJECTID!。
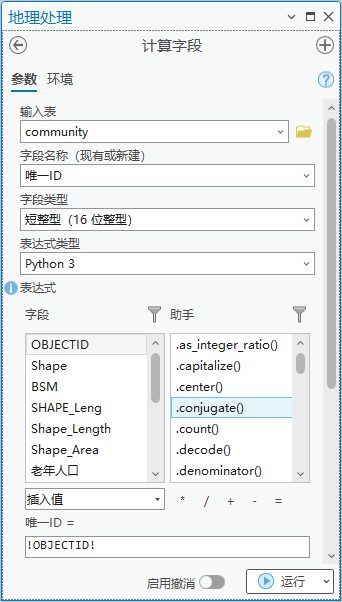
图91 计算字段
2.点击【工具箱】|【空间统计工具】|【空间关系建模】|【生成空间权重矩阵】|,输入要素类为“community”,唯- ID 字段为 “唯-ID”,输出空间权重矩阵文件指定其位置。空间关系的概念化选择“邻接边拐角”,其余参数保持不变。
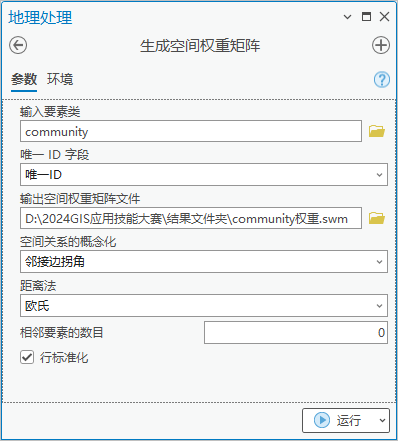
图92 生成空间权重矩阵
3.点击【工具箱】|【空间统计工具】|【实用工具】|【将空间权重矩阵转换为表】。
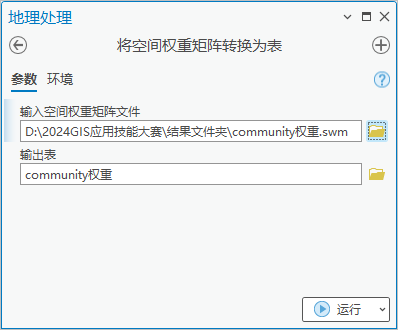
图93 将空间权重矩阵转换为表
打开权重结果表,表中包含唯一ID、NID(邻居ID),WEIGHT(权重大小)。
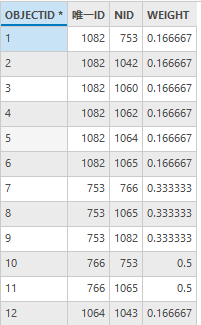
图94 权重表(部分)
2-8步与方法1相同。
方法5:
选择模型构建器,首先选出社区老年人口大于300的,再使用迭代要素选择遍历每一个要素,然后判断其周围社区老年人口之和是否大于2000,对符合条件的进行输出,再对输出的要素进行合并。
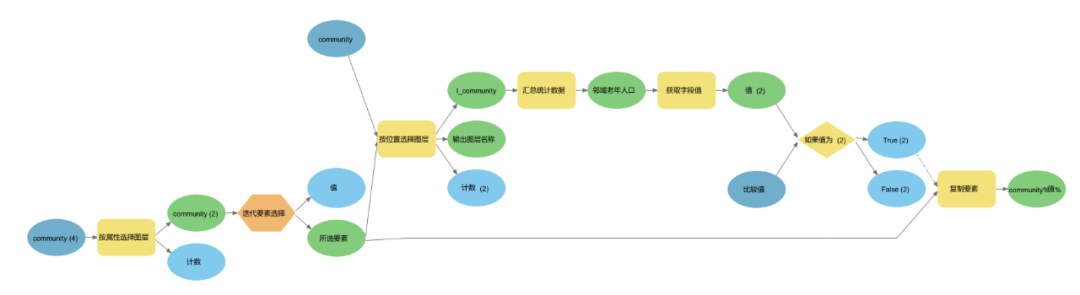
图95 模型构建器
2.4.2 查找服务驿站
1.切换到【分析】菜单栏,点击【工作流】|【网络分析】|【位置分配】。

图96 位置分配
2.切换到【位置分配】菜单栏,点击【输入数据】|【导入设施点】,输入网络分析图层为“位置分配”,子图层为“设施点”,输入位置为“community中心点”
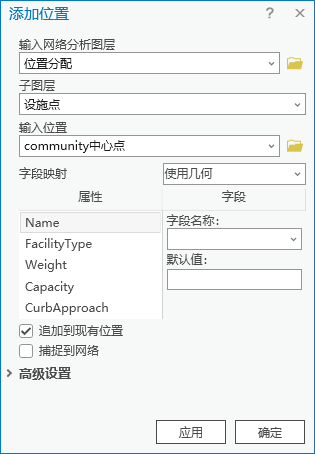
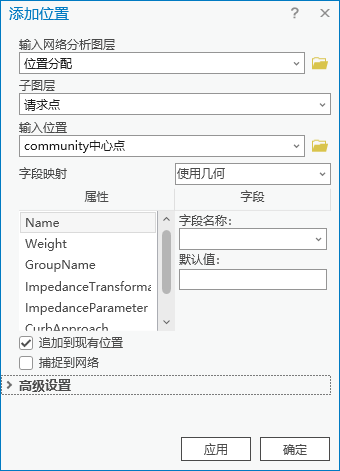
图97 添加位置
3.同样方法设置导入请求点。
4.切换到【位置分配】菜单栏,点击【出行设置】|【设施点】为50。点击【分析】|【运行】,结果如下图。
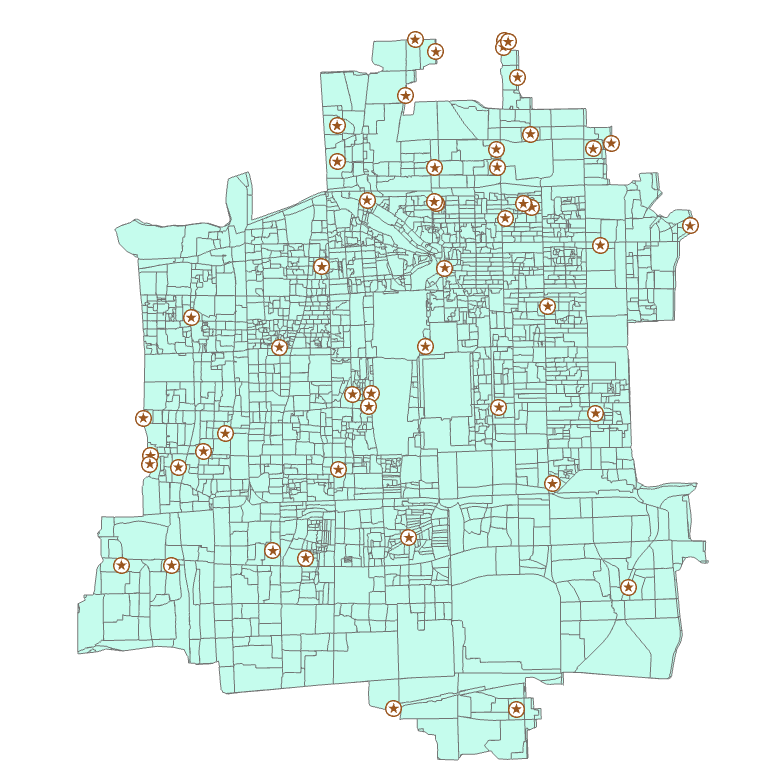
图98 位置分配结果
PS:网络数据集生成的方法不同,会导致位置分配的结果不同。
2.5 适老设施改造成本估算
2.5.1 计算建筑物老年人口
2.5.1.1 统计住宅区面老年人口
1.加载residental_areas数据及修正后老年人口分布数据。
2.使用【工具箱】|【空间分析工具】|【区域分析】|【以表格显示分区统计】,输入栅格数据或要素区域数据为“residental_areas”,区域字段为“OBJECTID”,输入赋值栅格为“修正后老年人口分布”,输出表为“住宅区老年人口”,统计类型为“总和”。
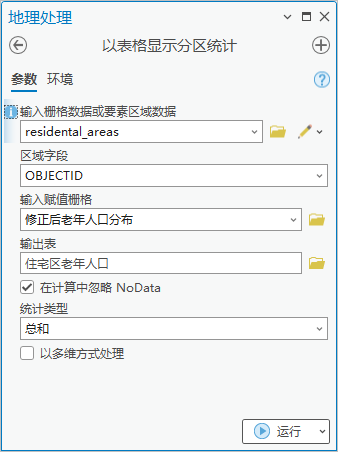
图99 以表格显示分区统计
其结果如下
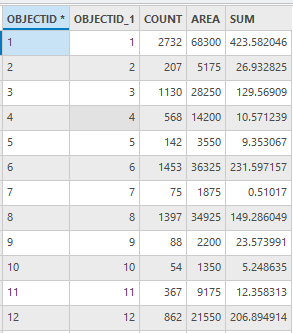
图100 住宅区老年人口表(部分)
SUM字段为住宅区老年人口数量。
3. 点击【工具箱】|【数据管理工具】|【连接和关联】|【连接字段】,输入表为“residental_areas”,输入连接字段为“OBJECTID”,连接表为“社区老年人口”,连接表字段为“OBJECTID_1”,选择传输字段为“SUM”。
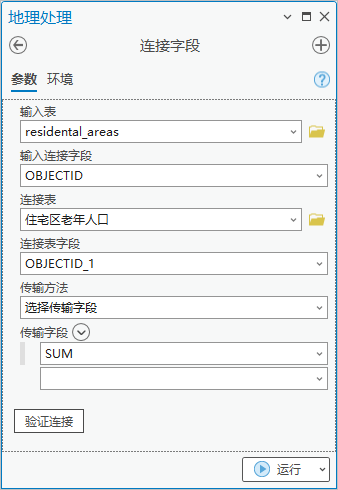
图101 连接字段
4.打开“residental_areas”属性表,将SUM字段中属性值为NULL的数据改为0。
5. 【数据】菜单栏中,点击【数据设计】|【字段】,在字段视图中,修改字段SUM名称为老年人口,并保存。
结果如下图所示
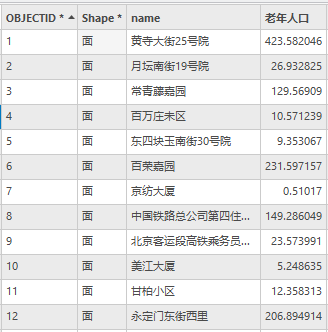
图102 residental_areas属性表(部分)
2.5.1.2 住宅区面连接建筑物
点击【工具箱】|【数据管理工具】|【连接和关联】|【添加空间连接】,目标要素为“buildings”,连接要素为“residental_areas”,匹配选项选“相交”。
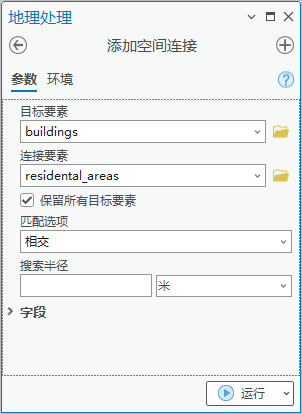
图103 添加空间连接
2.5.1.3 老年人口分配
1.点击【工具箱】|【分析工具】|【统计数据】|【汇总统计数据】,输入表为“buildings”,输出表为“buildings统计”,统计字段“name”,统计类型为“计数”。用于统计住宅区建筑物数量。
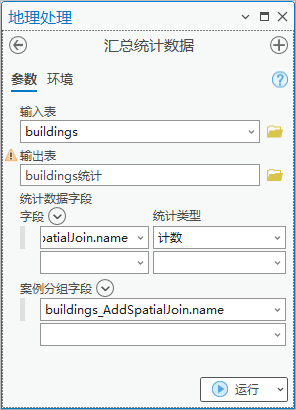
图104 汇总统计数据
结果如下图所示:

图105 buildings统计属性表(部分)
PS:也可以使用【工具箱】|【分析工具】|【统计数据】|【频数】工具。
2.点击【工具箱】|【数据管理工具】|【连接和关联】|【添加连接】,输入表为“buildings”,输入连接字段为“name”,连接表为“buildings统计”,连接表字段为“name”。将buildings图层挂接上buildings统计表中的建筑物数量信息。
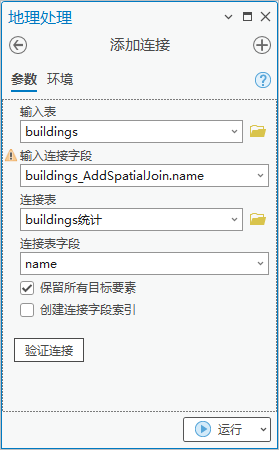
图106 添加连接
3.点击【工具箱】|【数据管理工具】|【字段】|【计算字段】,输入表为“buildings”,字段名称(现有或新建)为“建筑物老年人口”,字段类型为“浮点型(32 位浮点型)”,表达式为建筑物老年人口= !buildings_AddSpatialJoin.老年人口! / !buildings统计.FREQUENCY!。
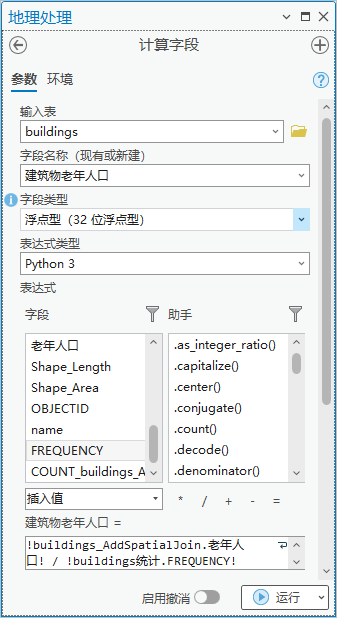
图107 计算字段
得到各建筑物老年人数量,如下图所示(部分建筑物老年人口为空,即不在住宅区范围内)
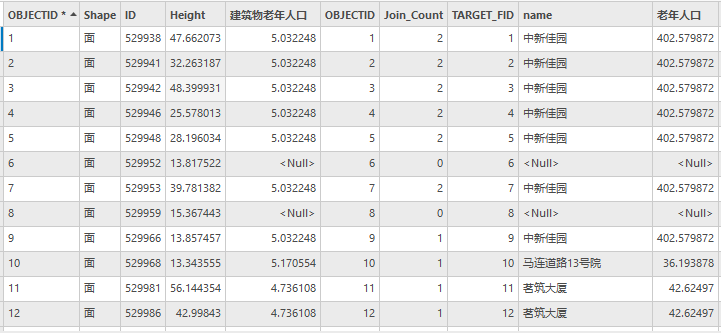
图108 Buildings属性表(部分)
2.5.2 查找需要安装电梯的住宅楼
方法1:
2.5.2.1 计算住宅楼层数
点击【工具箱】|【数据管理工具】|【字段】|【计算字段】,输入表为“buildings”,字段名称(现有或新建)为“楼层数”,字段类型为“短整型(16 位整型)”,表达式为楼层数= !buildings.Height! / 3。
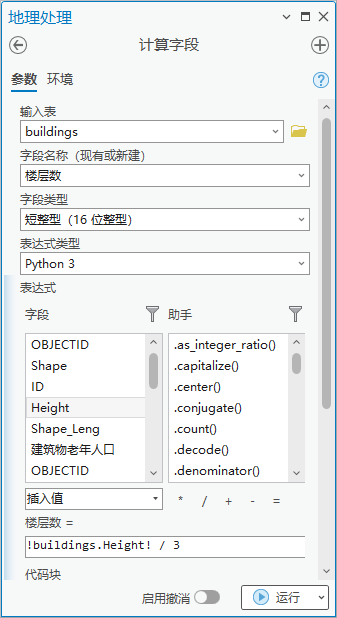
图109 计算字段
2.5.2.2 查找住宅楼
1.点击【工具箱】|【数据管理工具】|【图层和表视图】|【按属性选择图层】,输入图层为“buildings”,表达式为 Where 楼层数 大于5 And 建筑物老年人口 大于 5。
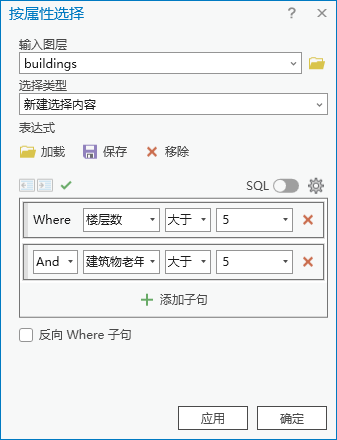
图110 按属性选择
结果共计5515个。
方法2:
点击【工具箱】|【数据管理工具】|【图层和表视图】|【按属性选择图层】,输入图层为“buildings”,表达式为 Where height 大于15 And 建筑物老年人口 大于 5。
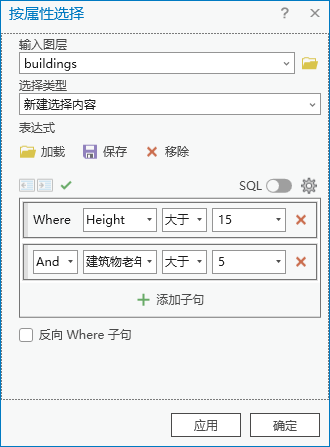
图111 按属性选择
2.5.2.3 导出住宅楼
点击【工具箱】|【转换工具】|【转出至地理数据库】|【导出要素】工具,输入要素为“buildings”,输出要素类命名为“需安装电梯住宅楼”。
图112 导出要素
符合条件的住宅楼分布如下
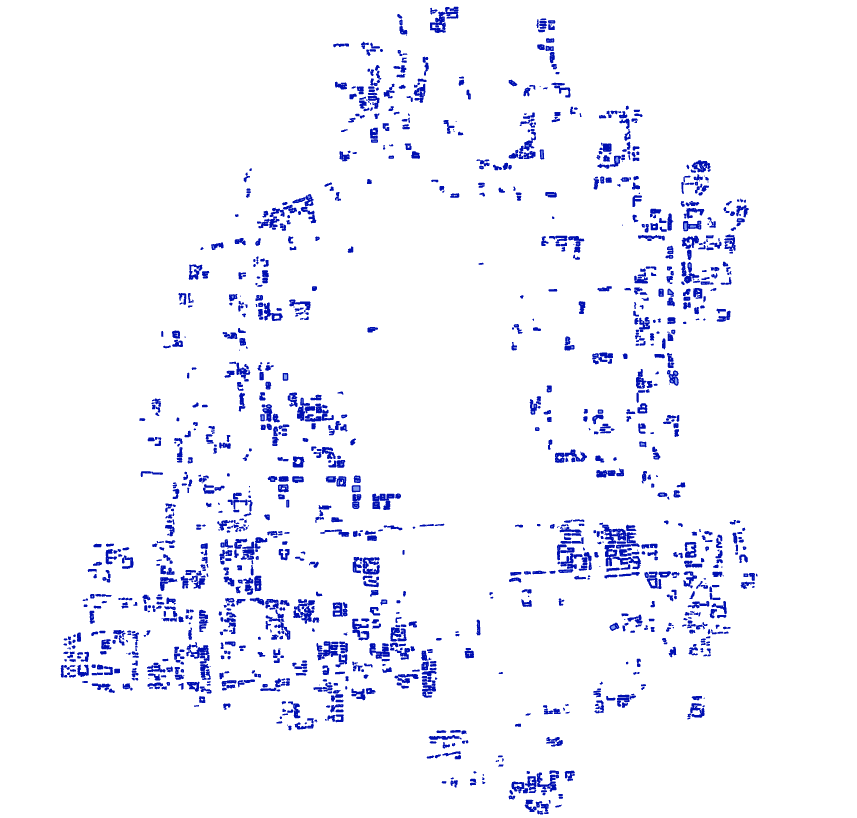
图113 需安装电梯的住宅楼分布
其属性表如下图所示
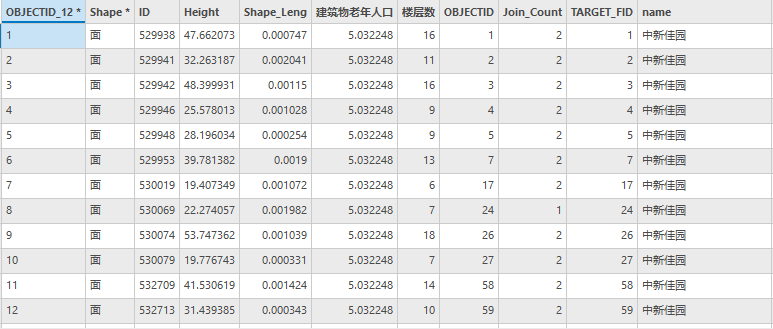
图114 需安装电梯的住宅楼属性表(部分)
2.6 最终成果制图
在Pro内容列表中,仅保留修正后老年人口分布图层可见,符号系统中选择分类,方法选择自然间断点分级法,自定义配色方案。
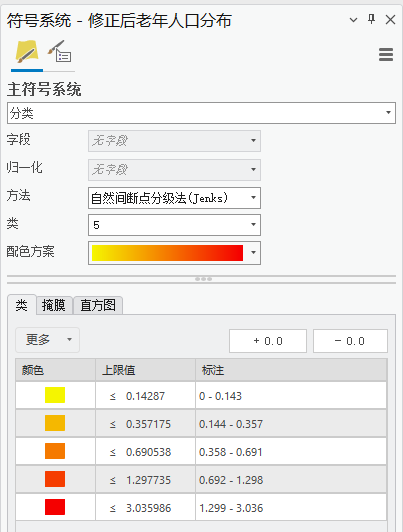
图115 符号设置
新建布局,选择自定义布局大小。
将目录中的地图直接拖拽至布局中。设置左下方的比例尺为1: 60,000(可自定义)。
添加名称、指北针、比例尺以及图例。
在共享菜单栏中,选择导出布局。导出PNG、PDF等格式图片。分辨率最高设为300DPI。效果如下图:
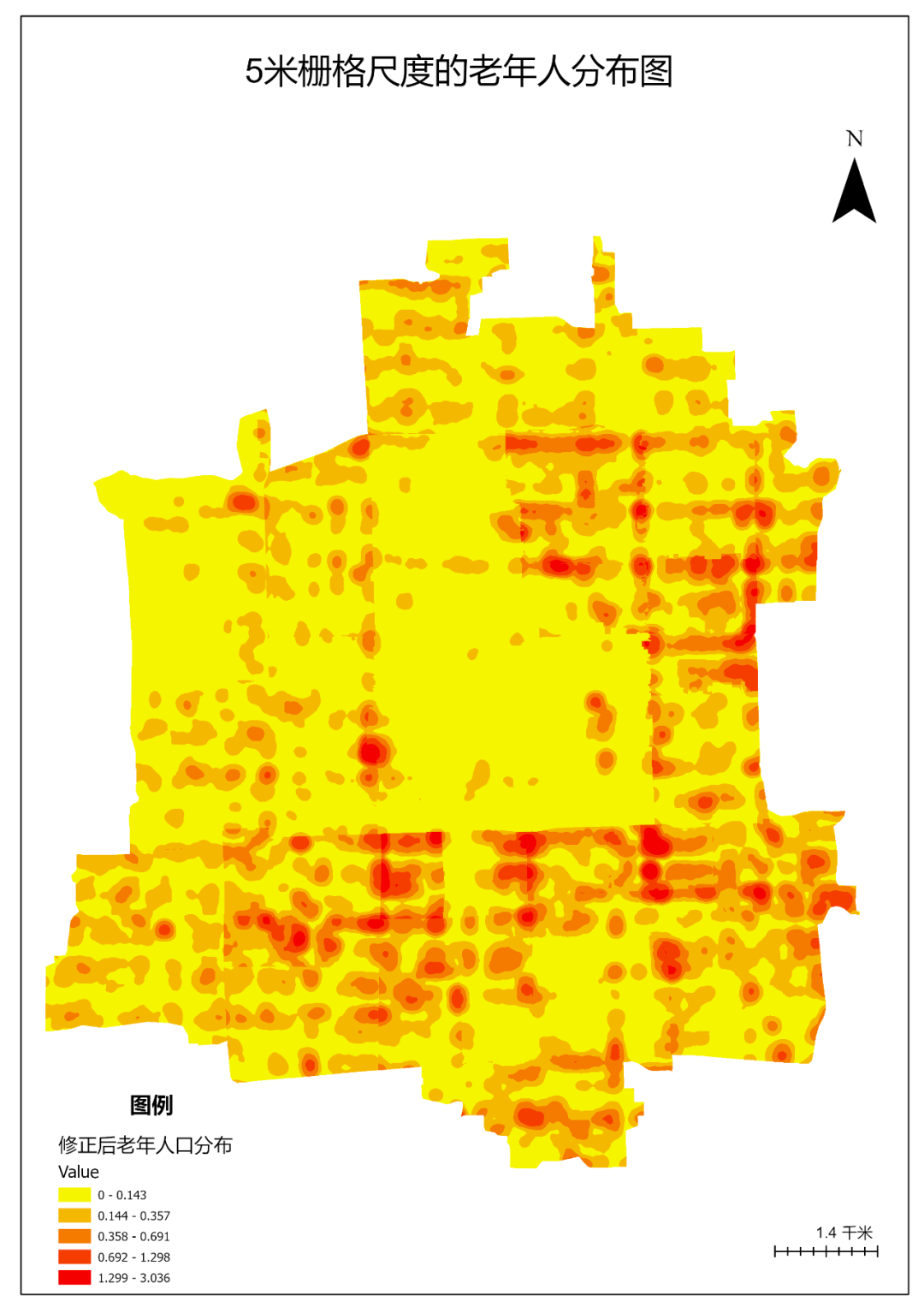
图116 老年人口分布专题图
同样的方式导出其它专题图。
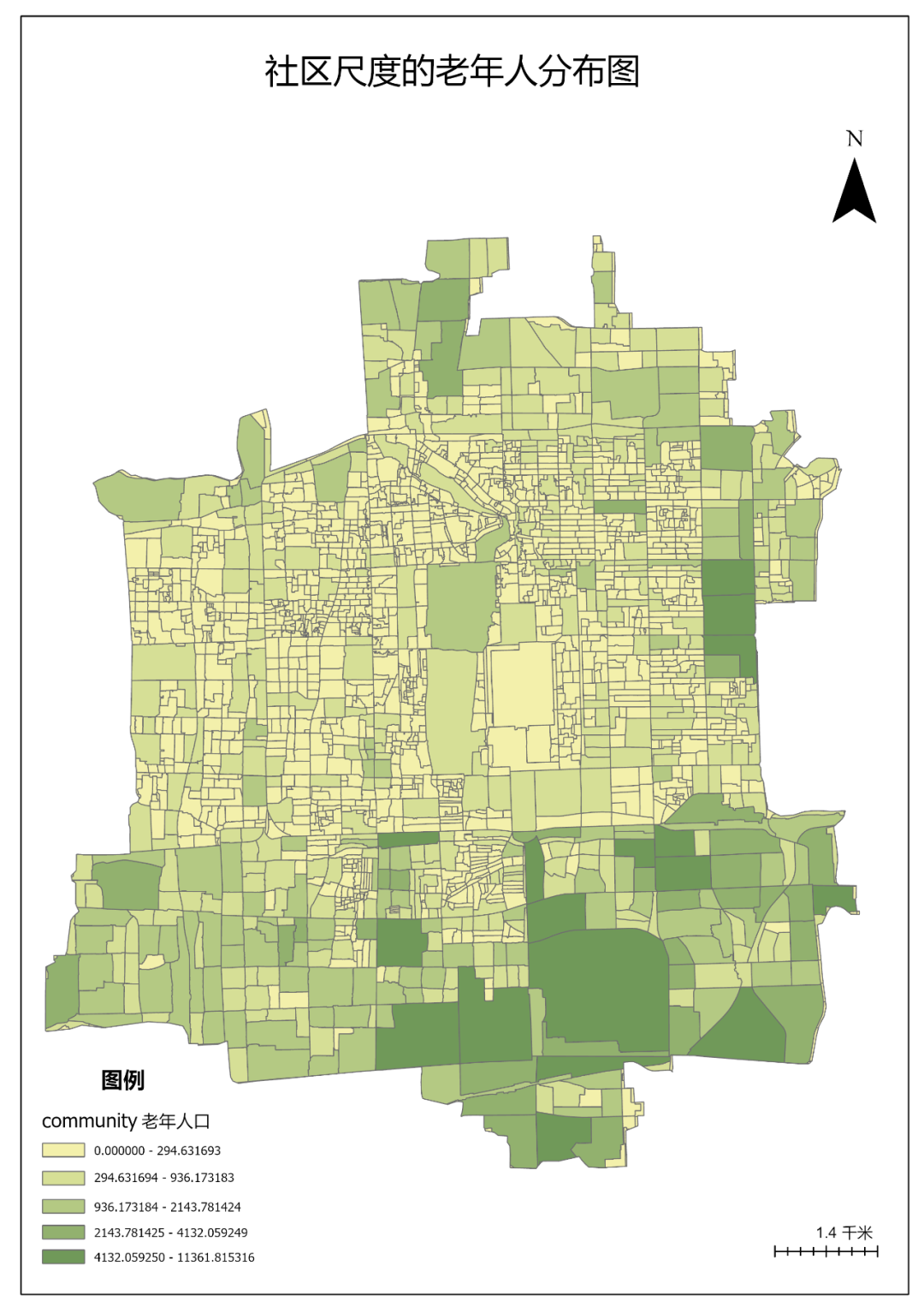
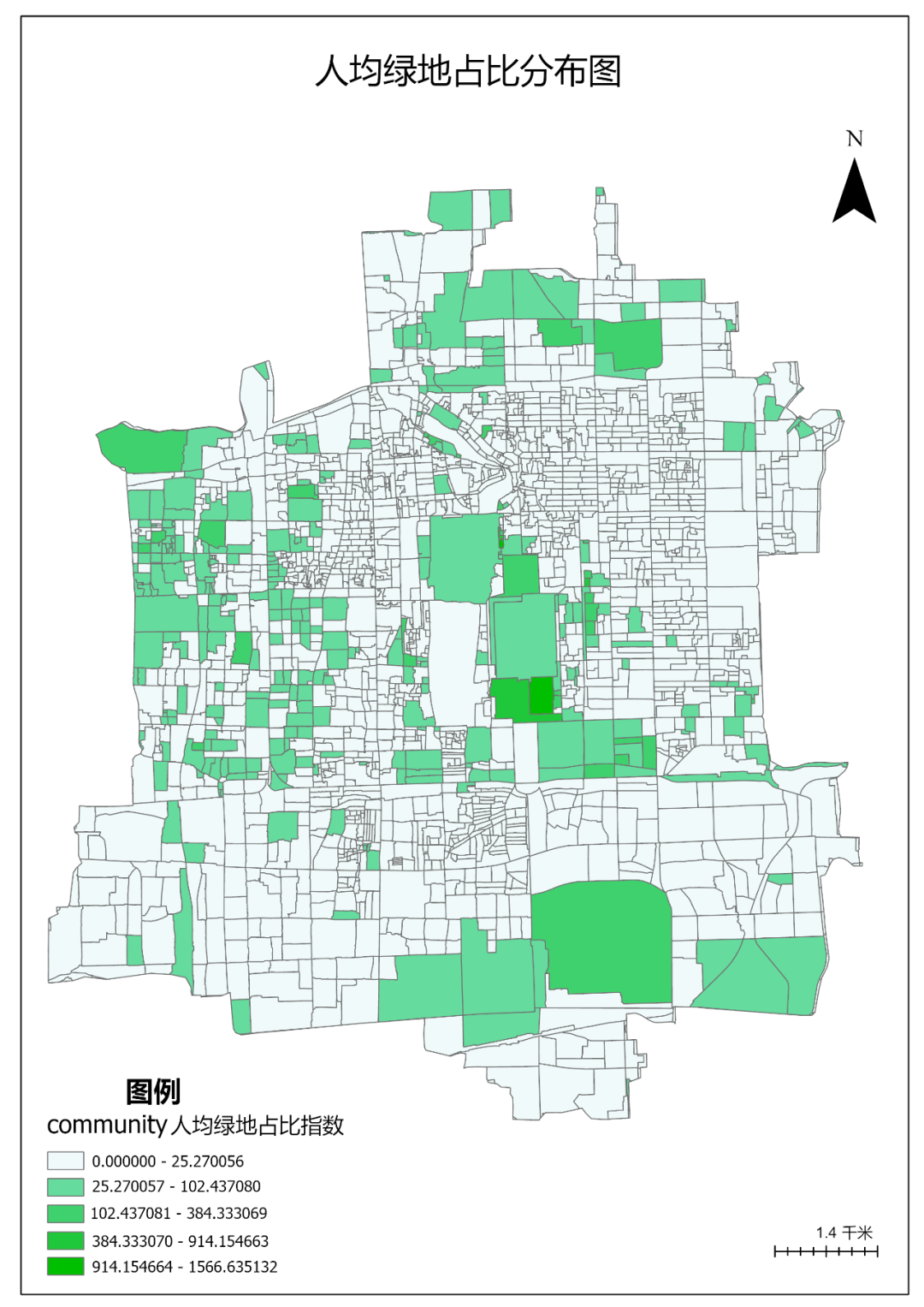
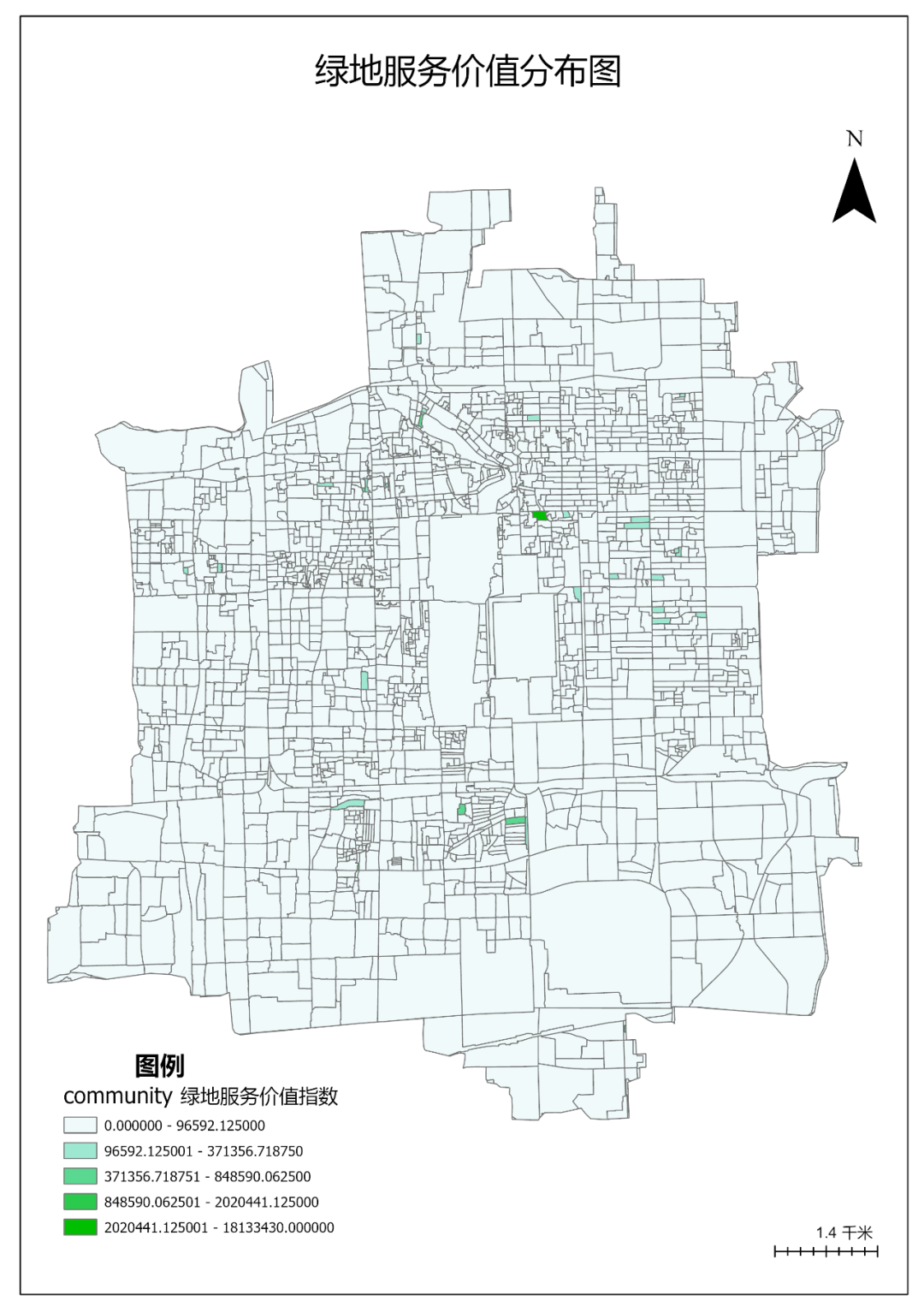
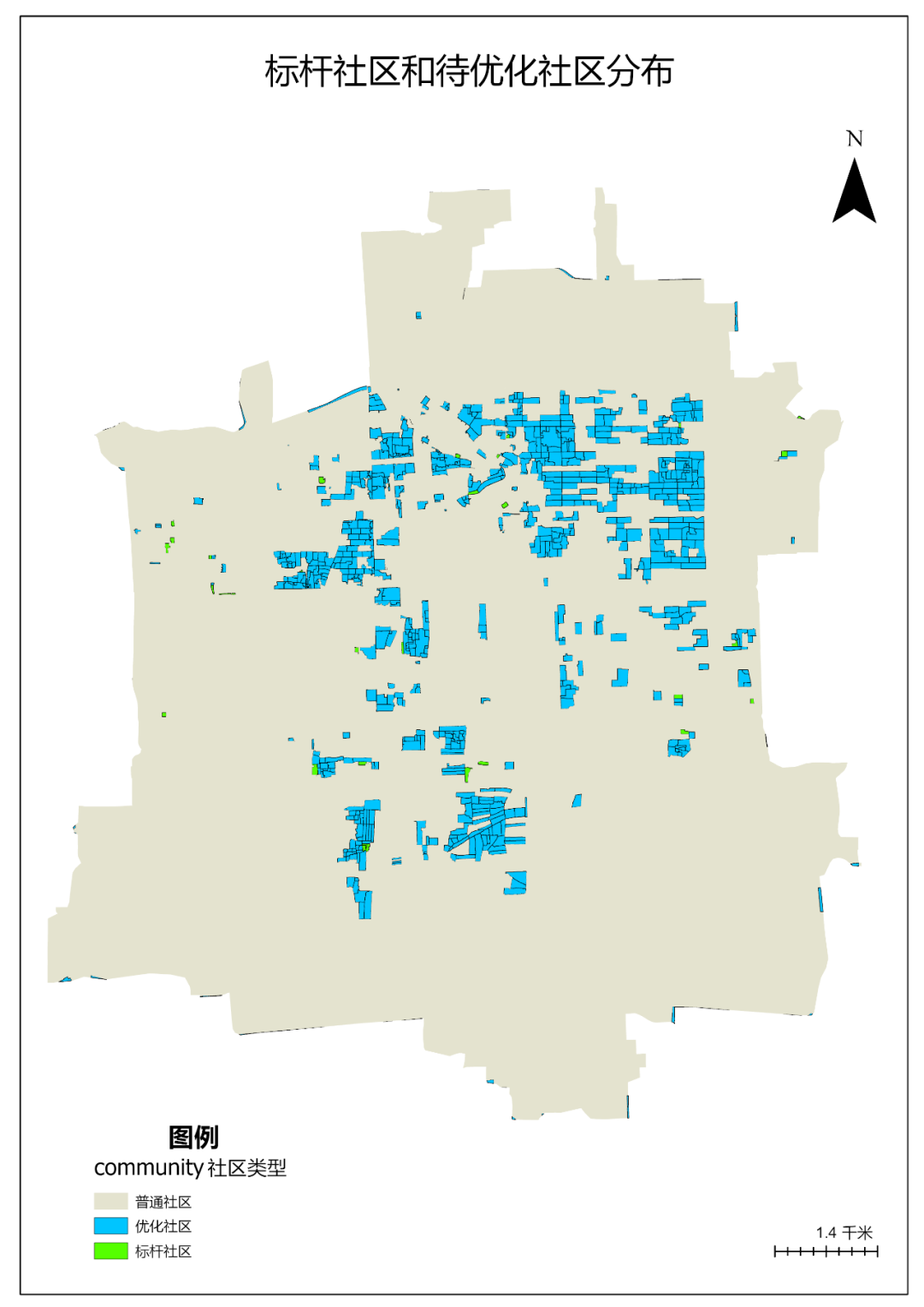
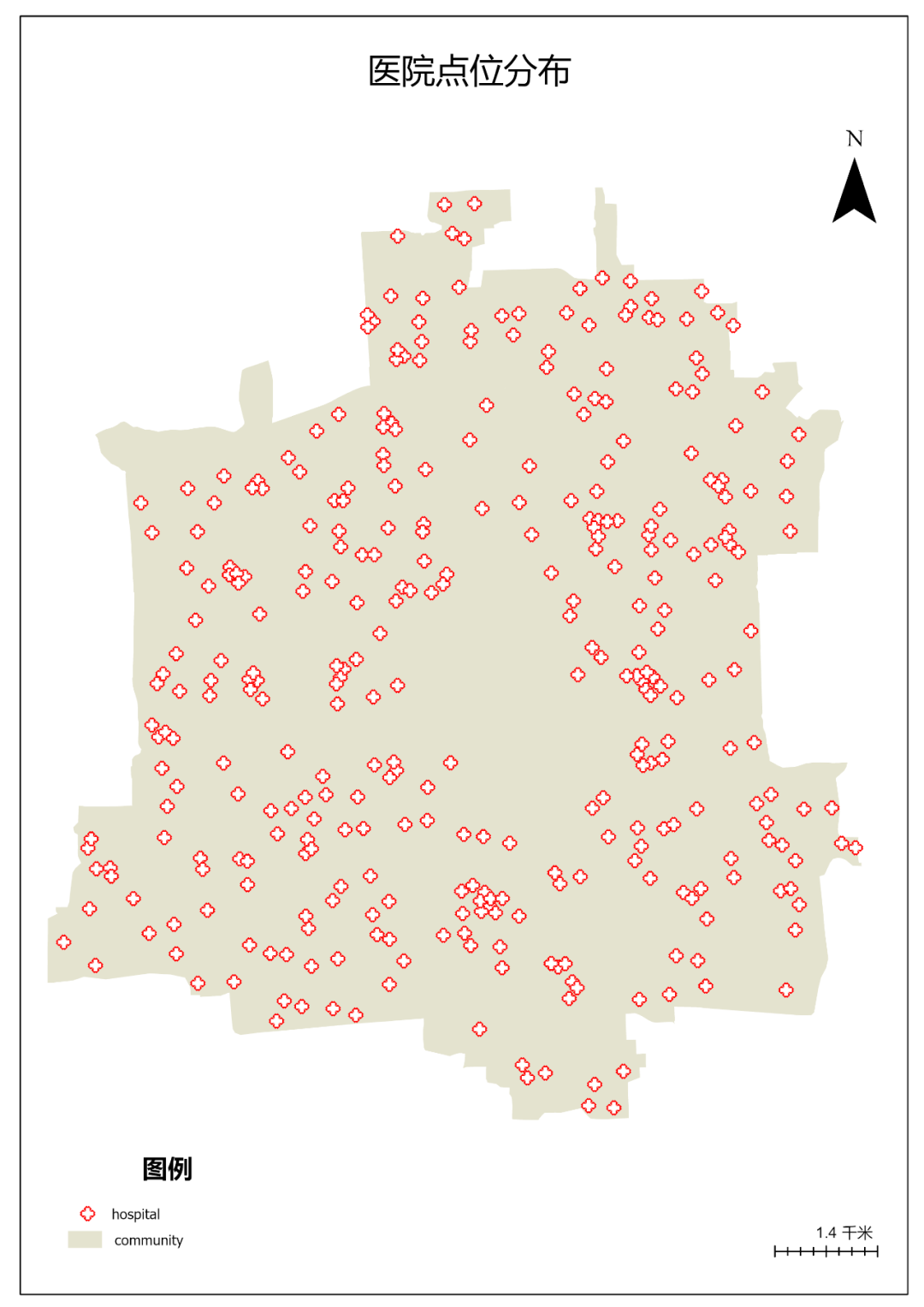
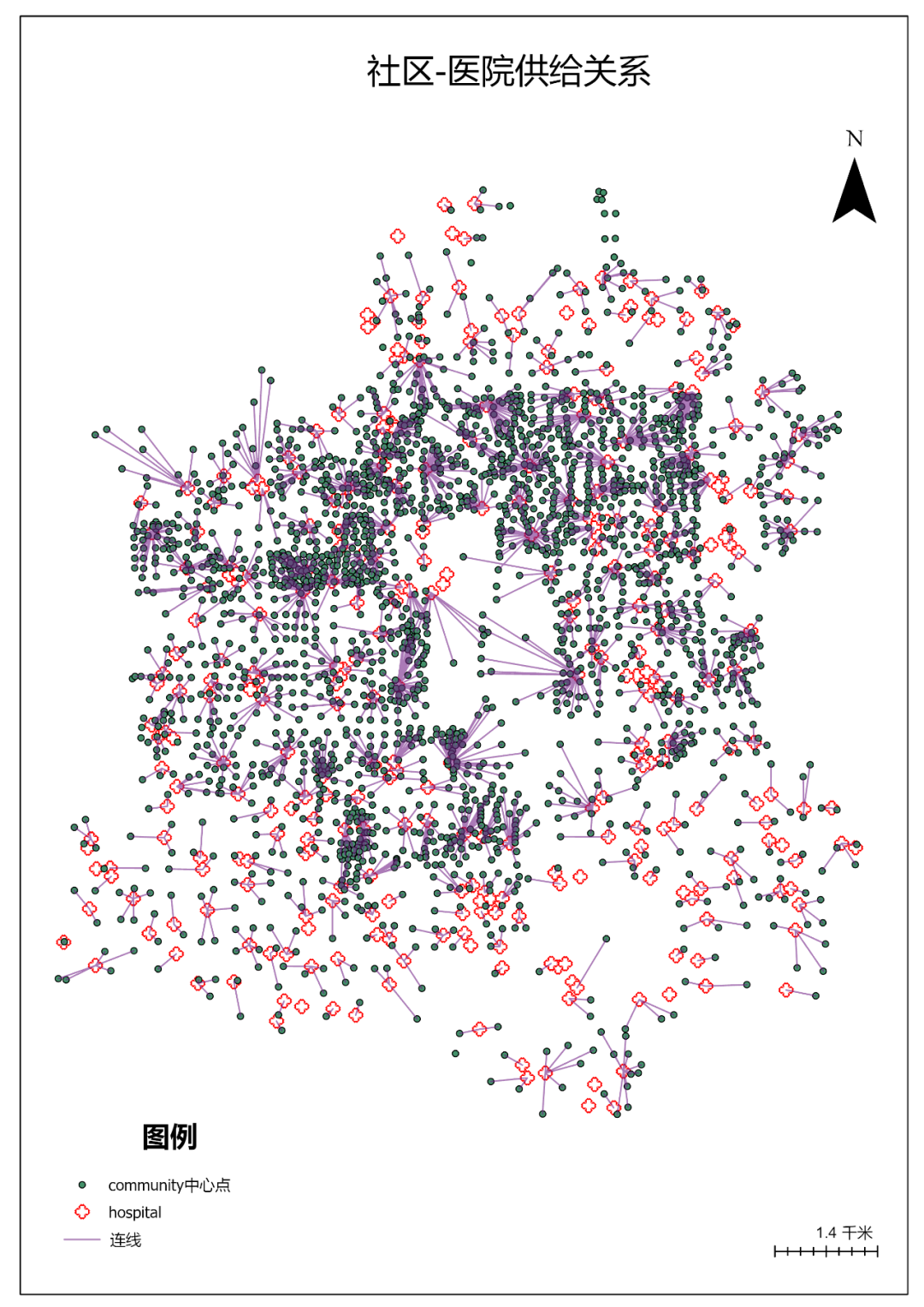
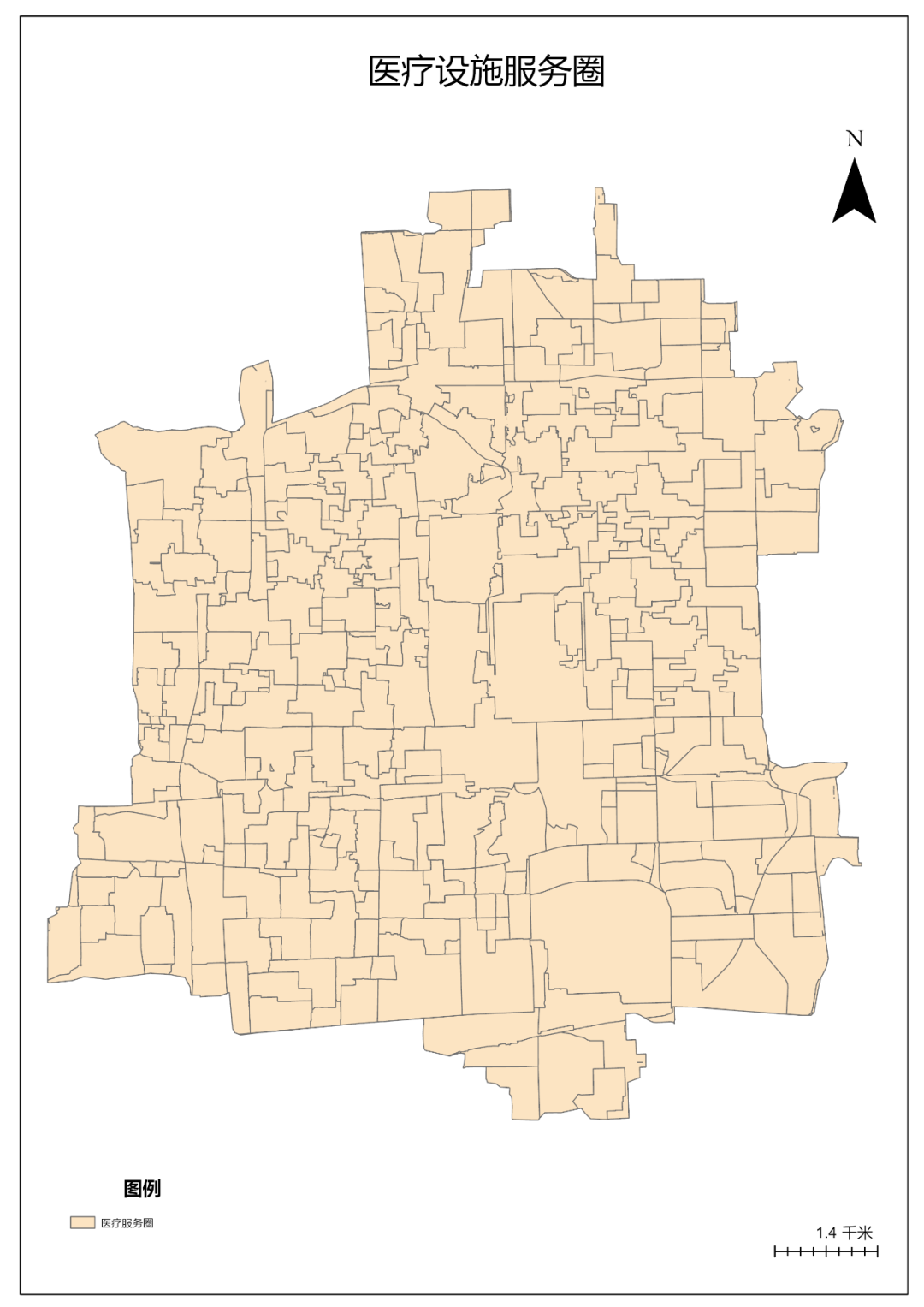
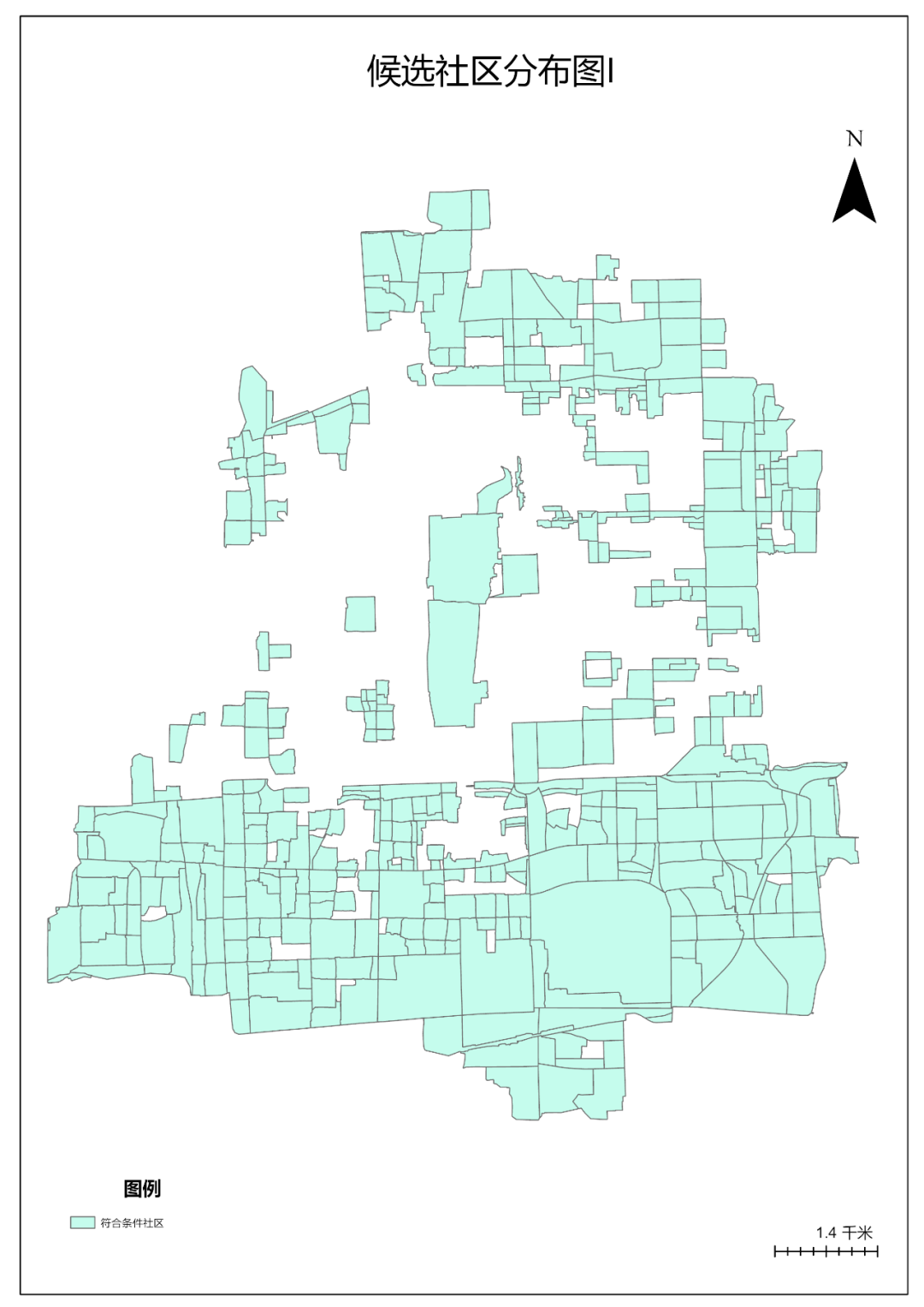
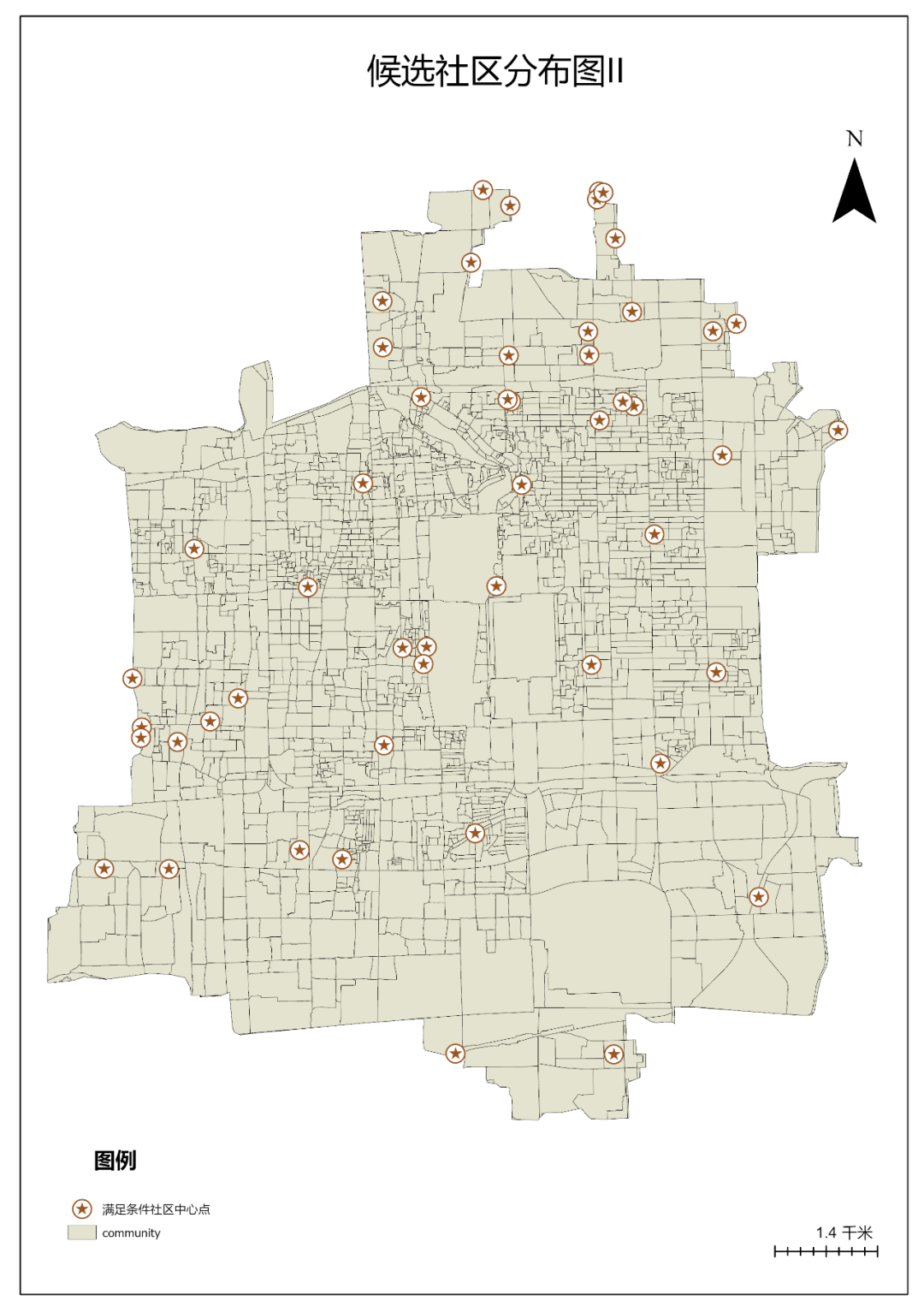
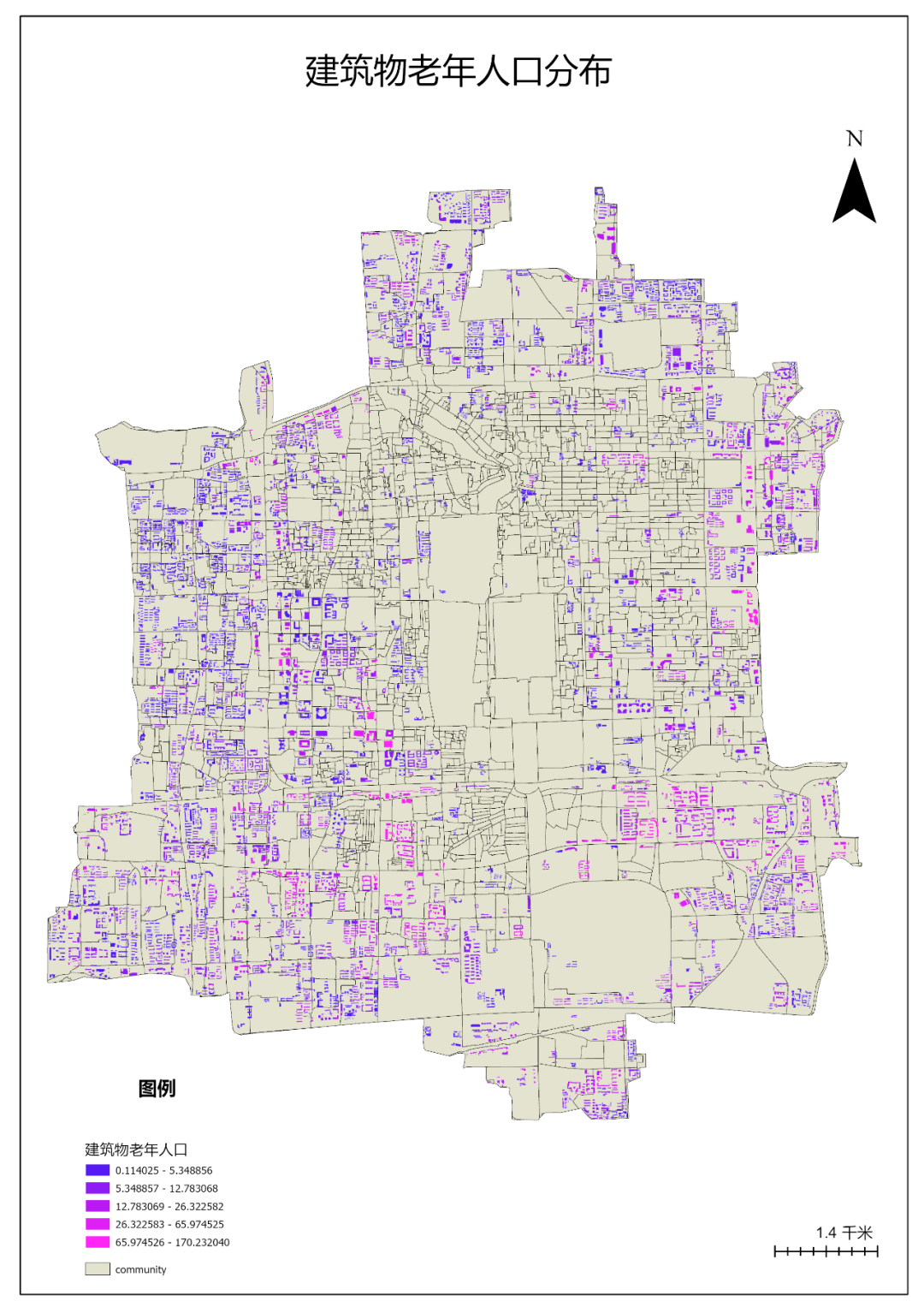
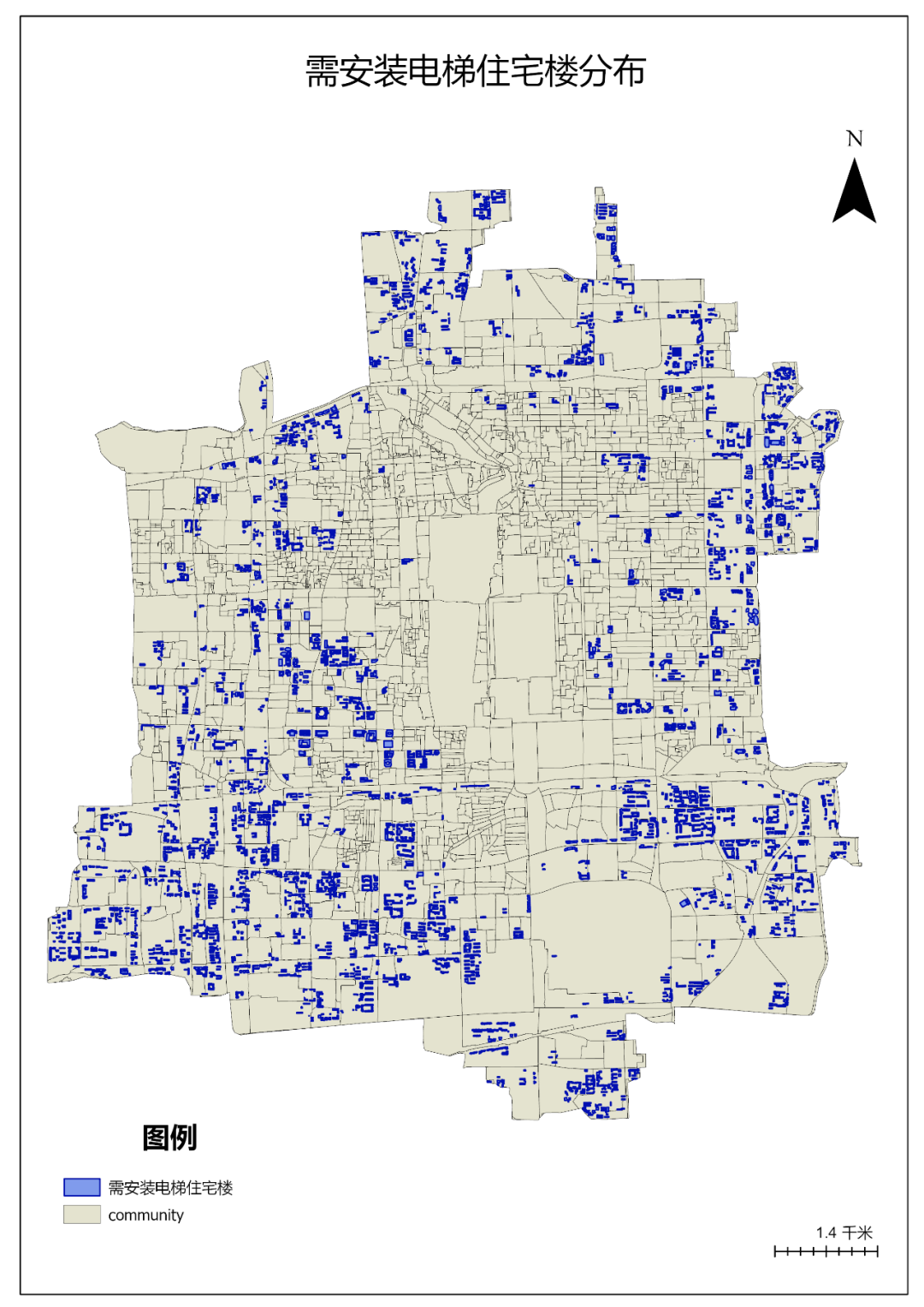
图117 各类专题图
3 总结
空间分析历来是考试的重点和难点,今年的题量也比较大,对同学们来说都是不小的挑战。GeoScene Pro中的分析工具多多,又分布在不同的工具箱中,甚至有些工具更改参数后与其他工具功能相同(例如汇总统计数据与频数工具),这就要看平时大家对工具的熟悉程度。再强调一次,方法不一样,结果可能会有出入,但是不影响任务目标,合理即可。

















 6089
6089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









