







目录
前言
不知不觉又是新的一周了,作者不会食言哦,虽然最近在忙着搞统调,但还是抽空出来继续带着大家一起学习一下机器学习。
该篇我们主要学习支持向量机这个模型。今天主要讲的是支持向量机模型解决分类问题,采用的是癌症数据集,因为癌症数据的label只有俩个,一个是良性一个是恶性。比较典型的二分类,然后一个是1一个是0。
一、支持向量机(SVM)模型简介
支持向量机(Support Vector Machine,简称 SVM)是一种基于统计学习理论的二分类模型,可以拓展到多分类和回归问题。SVM通过寻找一个超平面(或多个超平面)来分隔不同类别的数据,其特点是可以高效地处理高维空间的数据,并且能够处理非线性问题。SVM可以通过核函数将数据从原始输入空间映射到一个高维特征空间,使得数据在特征空间中线性可分或近似线性可分。SVM具有较好的泛化能力和鲁棒性(其实就是比较好的处理那些噪声点),可以在样本量较少的情况下得到较好的分类效果,常被应用于图像识别、文本分类、生物信息学等领域。
二、SVM模型的思想
VM的思想是找到一个最优的超平面,将不同类别的数据分隔开来。这个最优的超平面是指可以最大化两边的间隔(Margin),而间隔是指两个不同类别最近的样本点之间的距离。这个超平面可以通过寻找最优的分离超平面来确定。在寻找最优的分离超平面时,SVM不关心数据的分布情况,只关心最靠近分隔超平面的那些数据点,这些点被称为支持向量(Support Vector)。SVM利用支持向量来确定最优的分离超平面,因为只有支持向量对分类结果起作用,其他的数据点对分类结果没有影响。
下面的图是针对二维平面的二分类的SVM演示,下图有两类数据而我们画的直线是用于区分这两类数据的边界的,一般来说我们要看所有让所有点到这条决策边界的距离尽可能的远,这样margin(间隔)才会够大,才能更好的区别这两类数据。
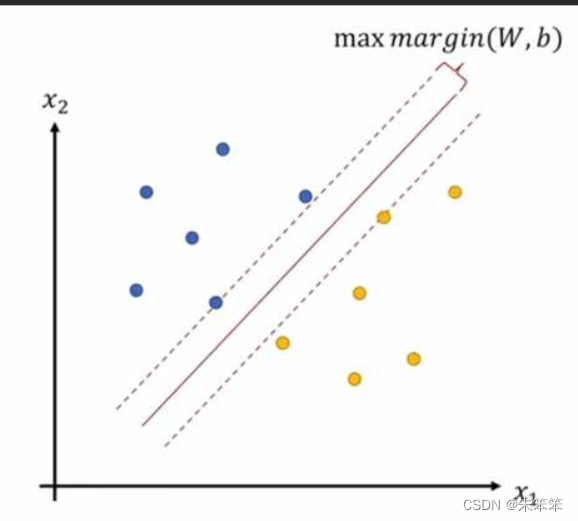
SVM对于线性可分的情况,直接找到一个超平面将两个类别分隔开来;而对于非线性可分的情况,SVM通过引入核函数将原始空间中的数据映射到高位空间,使得数据在高维空间中可以线性可分或近似线性可分。SVM就是基于这样的思想,通过寻找最优的分离超平面,将不同类别的数据分隔开来,从而达到分类的效果。
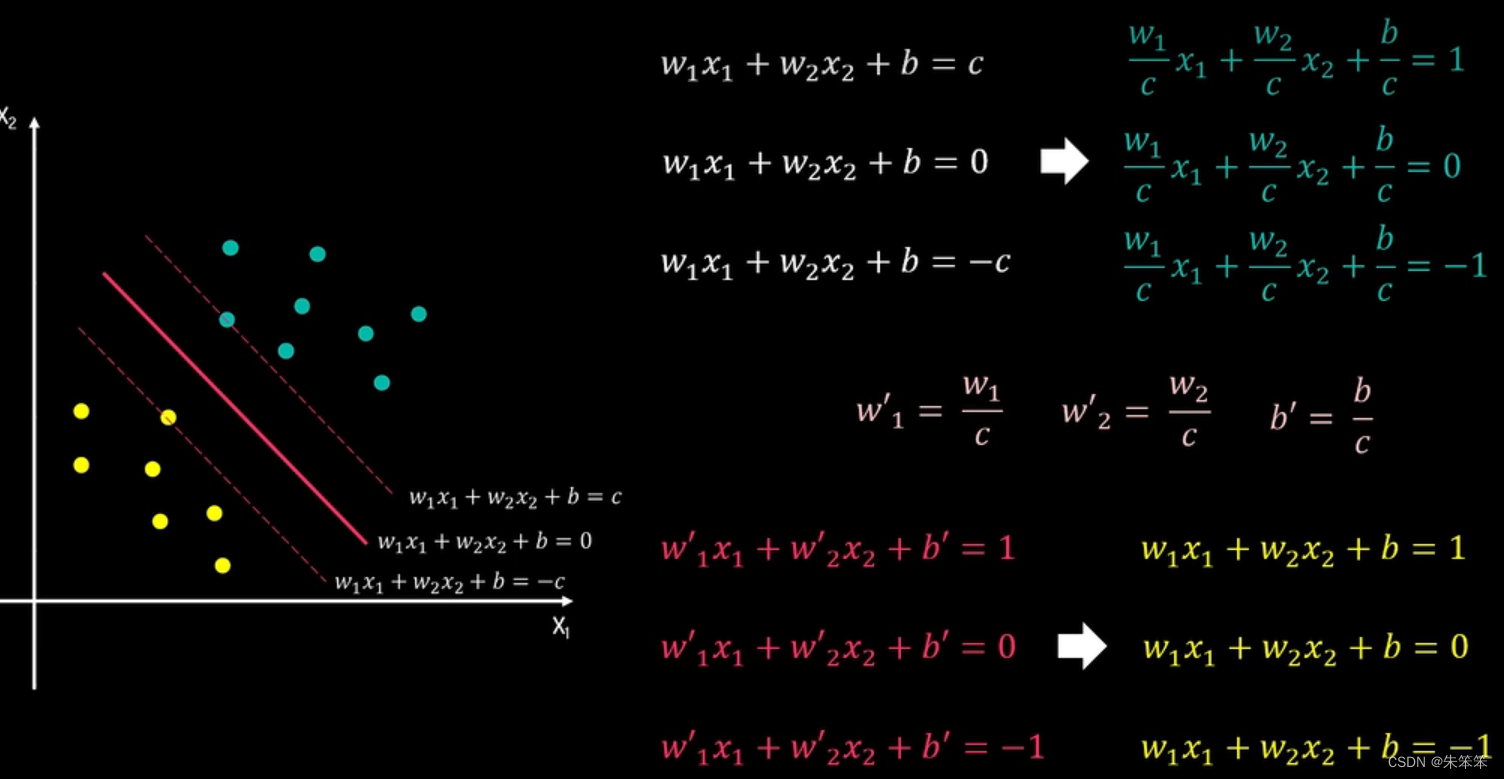
根本上实际就是区求w,b两个参数,确定方程,然后将后面的数据根据我们所得出的方程进行相对位置的比对,就可以得出它的类别了。 这里补充一下,肯定会有人文假设黄点有一个出现在蓝点的群里怎么办?这就要说软间隔和硬间隔了。这里大家可以自己区了解一下,作者这里不多做解释。
三、癌症数据代码实战(sklearn的dataset里有)
3.1导入的库
#需要导入的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus']=False
plt.rcParams['font.sans-serif'] = ['SimHei']
plt. rcParams ["axes.unicode_minus"]= False
import seaborn as sns
sns.set(font= "Kaiti",style="ticks",font_scale=1.4)
from sklearn.metrics import accuracy_score
from sklearn.svm import SVC ,LinearSVC,SVR
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import StandardScaler#标准化数据用的库
from mlxtend.plotting import *
#特征部分的库
from sklearn.feature_selection import SelectKBest,mutual_info_classif3.2数据探索
#将癌症数据集保存为csv文件
cancer = load_breast_cancer()
df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
df['label'] = cancer.target
df.to_csv('cancer.csv', index=False)
data = load_breast_cancer()
X = data.data
y = data.target
print("特征为",X.shape[1],"个",'\n',"样本为",X.shape[0],"个",'\n',"类别为",np.unique(y))这里保存了一下癌症数据集,看了一下里面的数据,其实还是比较复杂的,有30个特征,然后最后一列是标签,具体就是良性癌症是1,恶性为2

3.3数据特征选择
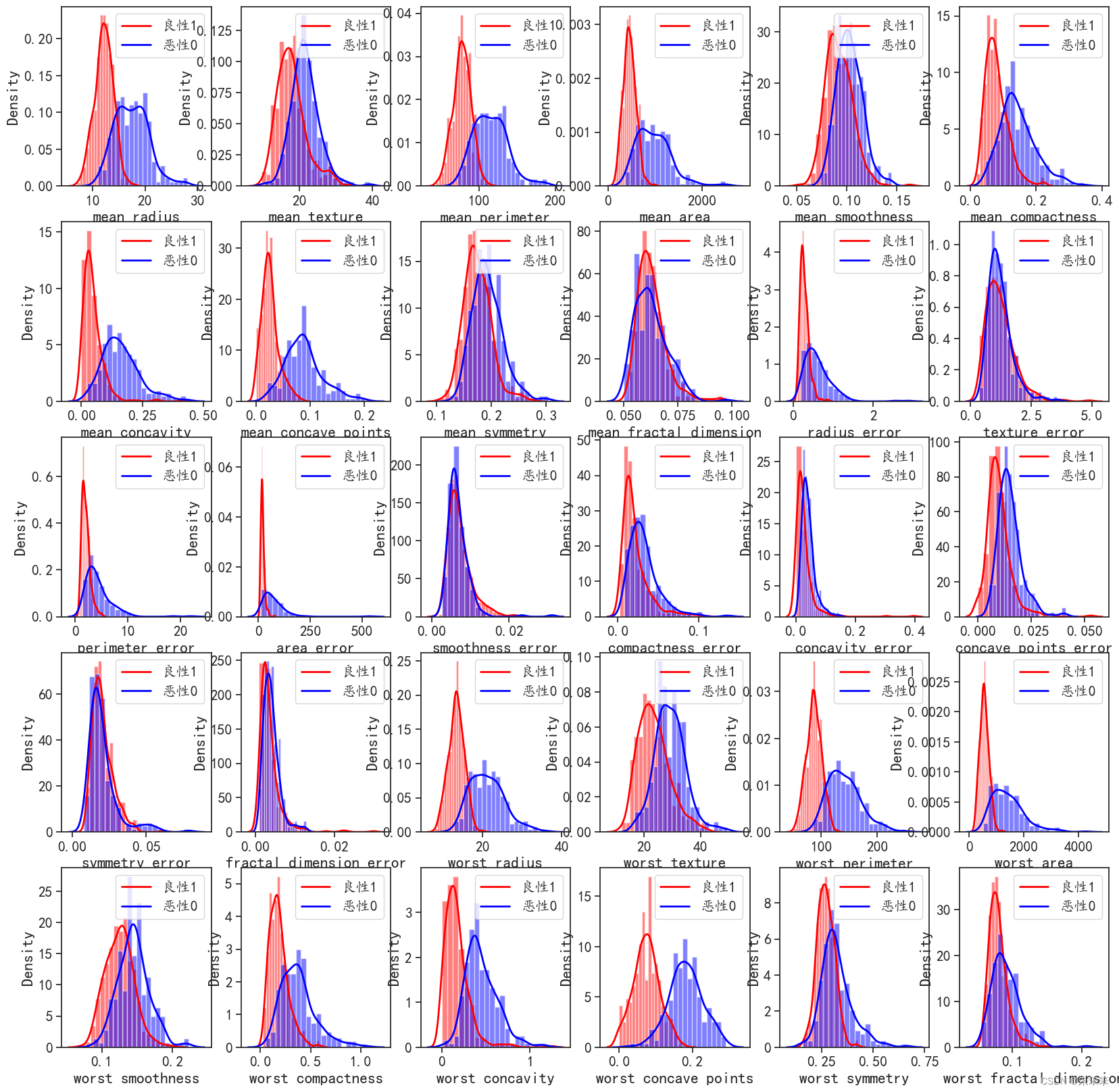
特征选择的话,我们可以先看看不同特征的分布情况,然后看特征重要性,再决定选取特征的数量
#可视化特征重要性的数据分布
scale = StandardScaler(with_mean=True, with_std=True)#标准化数据
scale_X = scale.fit_transform(X)#标准化特征数据 #这里作者强调一下,这里标准化的目的是为了让数据在同一个量级上,这样才能更好的进行分类
feature_names = data.feature_names
print("特征名为:",feature_names)
plt.figure(figsize=(20,20))
for i,j in enumerate(feature_names):
plt.subplot(5,6,i+1)#这里的5和6是指5行6列的意思,i+1是指第几个图
label = X[:,i]#这里的i是指第i个特征
sns.distplot(label[y == 1], bins=20, color='red',hist_kws={'alpha': 0.5}, kde_kws={'linewidth': 2})
sns.distplot(label[y == 0], bins=20, color='blue',hist_kws={'alpha': 0.5}, kde_kws={'linewidth': 2})
plt.legend(['良性1', '恶性0'], loc='upper right')
plt.xlabel(str(j))
plt.ylabel('Density')#密度
plt.show()然后我们看出了这些这里面有些特征针对不同类型的数据其实分布差异很多,作者初步猜测他们可以为分类做出巨大贡献。而那些很相近的数据,其实就不用看了。
接着我们找出特征得分
#选k个变量,这里选取前10个变量
Kbest = SelectKBest(mutual_info_classif)#mutual_info_classif是互信息法,这里的Kbest是指选取最好的K个特征
Kbest.fit(scale_X,y)#这里的scale_X是指标准化后的特征数据,y是指标签
# 可视化每个特征的得分
KbestMIdf = pd.DataFrame(data={'score':Kbest.scores_,'feature':feature_names})#这里的feature_names是指特征名,Kbest.scores_是指特征的得分
KbestMIdf = KbestMIdf.sort_values(by='score',ascending=False)#按照得分进行排序
KbestMIdf.plot(kind='barh',x='feature',y='score',figsize=(20,20))
plt.xlabel = 'feature'
plt.ylabel = 'score'
plt.show() 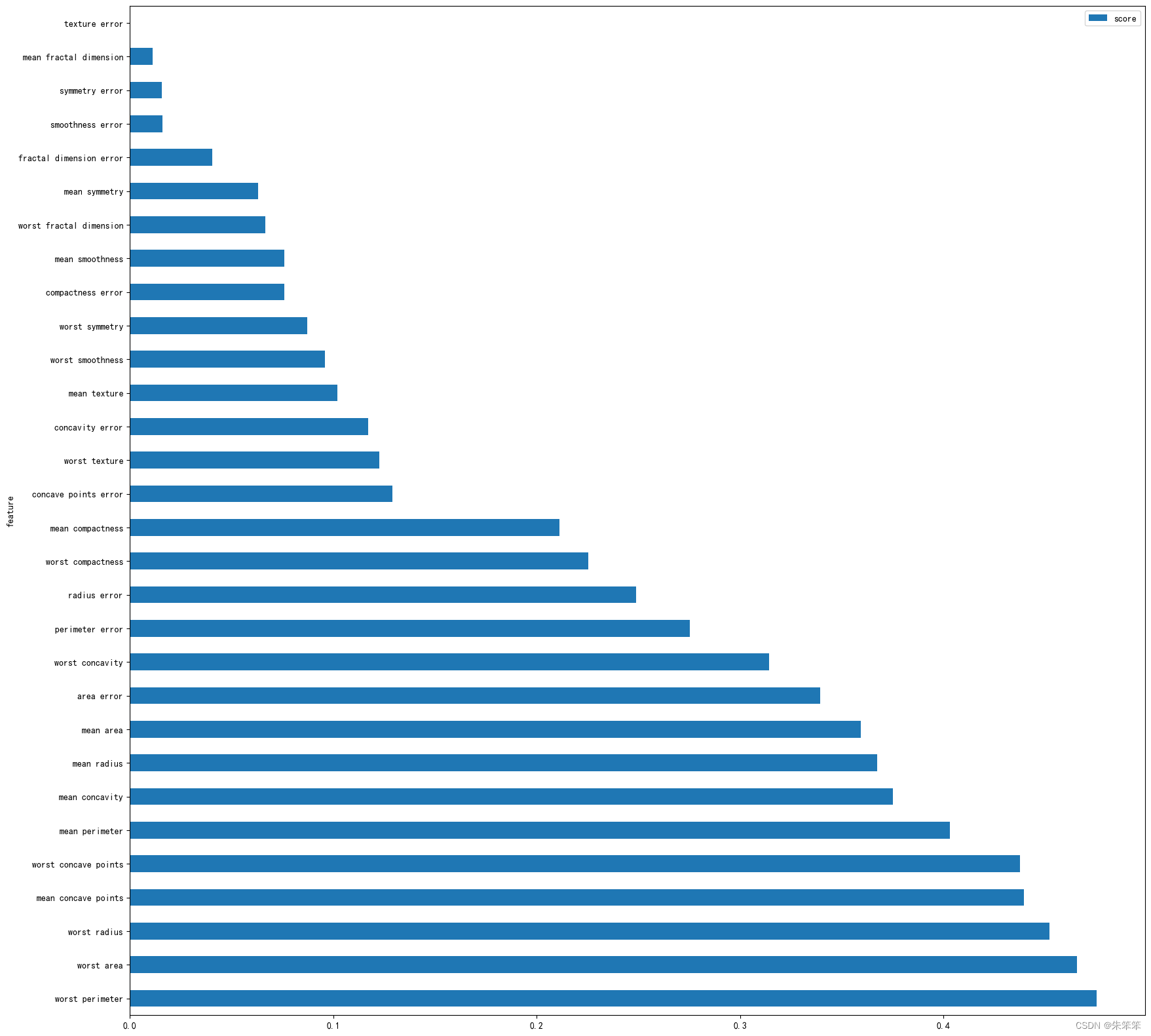
仔细一看发现后面10个特征的得分及其的高,所以我们后面的线性和非线性支持向量机决定采用这10个变量
3.4线性支持向量机
#选取前10个特征
Kbest.set_params(k=10)#这里的k是指选取的特征个数
scale_X10 = Kbest.fit_transform(scale_X,y)
print("选择特征后的数据维度为",scale_X10.shape)
Feature10 = KbestMIdf.feature.values[::-1][0:10]#这里的[::-1]是指倒序,[0:10]是指选取前10个特征
print("选取的特征为:",KbestMIdf['feature'].values[:10])
#切分数据集
X_train,X_test,y_train,y_test = train_test_split(scale_X10,y,test_size=0.3,random_state=0)
print(X_train.shape)
print(X_test.shape)
from sklearn.model_selection import learning_curve
linesvm = LinearSVC(penalty="l2",C=1.0,random_state=1)
linesvm.fit(X_train,y_train)
linesvm_label = linesvm.predict(X_train)
linesvm_predict = linesvm.predict(X_test)
print("训练集精度",accuracy_score(y_train,linesvm_label))
print("测试集精度",accuracy_score(y_test,linesvm_predict))
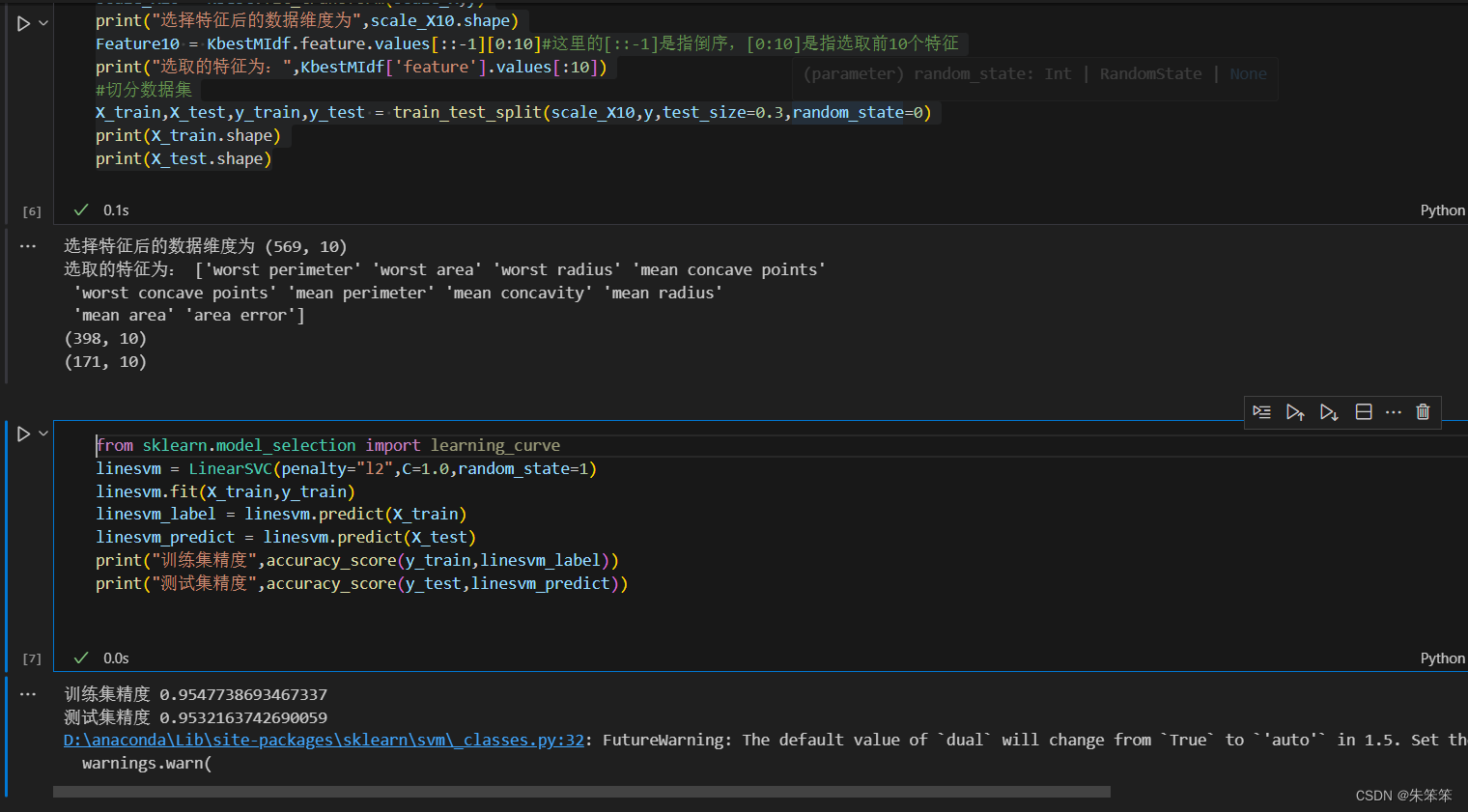
不得不说运行的精度很高,所以可以初步得出支持向量机很适合这个数据集进行二分类。
3.4.1 学习曲线
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import learning_curve
# 用sklearn的learning_curve得到training_score和cv_score,使用matplotlib画出learning curve
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1,
train_sizes=np.linspace(.05, 1., 20), verbose=0):
"""
画出data在某模型上的learning curve.
参数解释
----------
estimator : 你用的分类器。
title : 表格的标题。
X : 输入的feature,numpy类型
y : 输入的target vector
ylim : tuple格式的(ymin, ymax), 设定图像中纵坐标的最低点和最高点
cv : 做cross-validation的时候,数据分成的份数,其中一份作为cv集,其余n-1份作为training(默认为3份)
n_jobs : 并行的的任务数(默认1)
"""
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
plot_learning_curve(linesvm, u"SVM学习曲线",X, y)作者这里傻了,没看到mxltend 这个库里有函数可以用,上网搜了个原函数调用了。大意了哎。
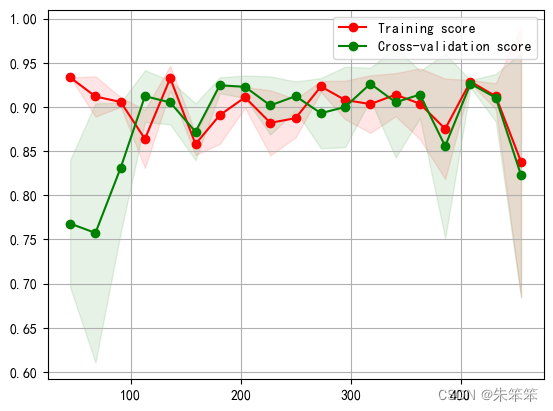
不过这个后面的拟合效果还是让人满意的。
3.4.2分界面可视化
#可视化线性SVM分界面
#基于特征10个太多我们只选取组合就行
zuhe = [(0,1),(0,5),(0,9),(3,6),(2,7),(4,9)]
plt.figure(figsize=(14,8))
for i,j in enumerate(zuhe):
print(i,j)
plt.subplot(2,3,i+1) ## 子窗口
#改变x,y轴的标签
plt.xlabel = Feature10[j[0]]
plt.ylabel = Feature10[j[1]]
print(Feature10[j[0]],"和",Feature10[j[1]])
## 训练模型
x_tr = X_train[:,j]
x_te = X_test[:,j]
linesvm = linesvm.fit(x_tr,y_train)
## 计算在测试集上的预测精度
Lsvm_pre = linesvm.predict(x_te)
acc = accuracy_score(y_test,Lsvm_pre)
## 可视化分界面
plot_decision_regions(x_te, y_test,clf=linesvm, legend=2)
plt.title("分类精度:"+str(round(acc,3)))
plt.tight_layout()
plt.show()
#这里不知道出了什么问题我都x,y都没了,但是我已经写过xlabel和ylebel了做这个东西肯定是需要分界面可视化的,但是一般来说我们只能看到平面和三维的,而更高维的图像我们不能展示,所以作者选了6组变量做了分界面,但是比较尴尬的是不知道为啥我都x,y明明有赋值但是图像里不显示,如果有知道原因的小伙伴可以私信我哦。
#可视化线性SVM分界面
#基于特征10个太多我们只选取组合就行
zuhe = [(0,1),(0,5),(0,9),(3,6),(2,7),(4,9)]
plt.figure(figsize=(14,8))
for i,j in enumerate(zuhe):
print(i,j)
plt.subplot(2,3,i+1) ## 子窗口
#改变x,y轴的标签
plt.xlabel = Feature10[j[0]]
plt.ylabel = Feature10[j[1]]
print(Feature10[j[0]],"和",Feature10[j[1]])
## 训练模型
x_tr = X_train[:,j]
x_te = X_test[:,j]
linesvm = linesvm.fit(x_tr,y_train)
## 计算在测试集上的预测精度
Lsvm_pre = linesvm.predict(x_te)
acc = accuracy_score(y_test,Lsvm_pre)
## 可视化分界面
plot_decision_regions(x_te, y_test,clf=linesvm, legend=2)
plt.title("分类精度:"+str(round(acc,3)))
plt.tight_layout()
plt.show()
#这里不知道出了什么问题我都x,y都没了,但是我已经写过xlabel和ylebel了然后直接就可以看出这个决策边界了。
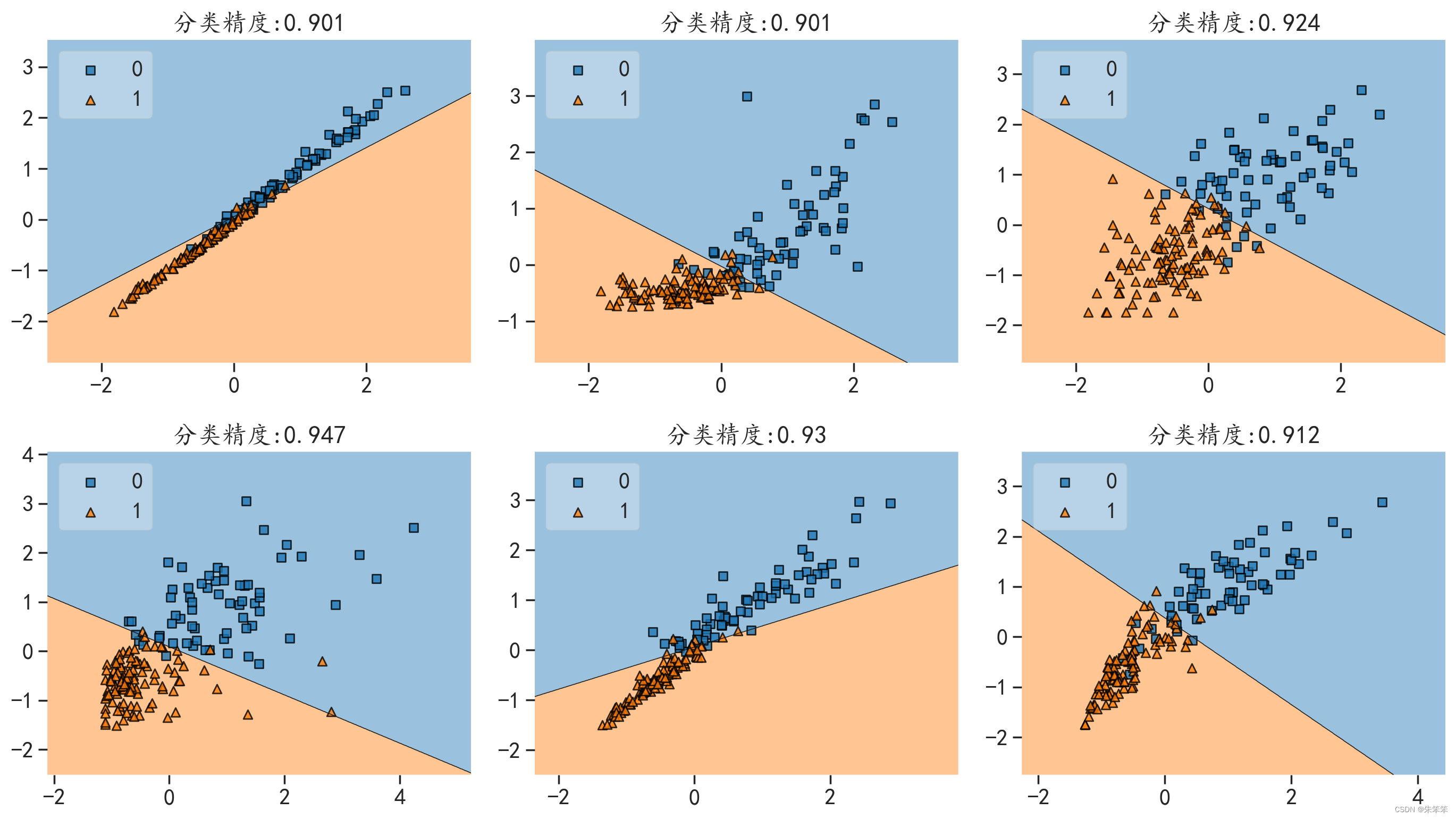
下面放张图必须证明值没问题,但不知道为啥。
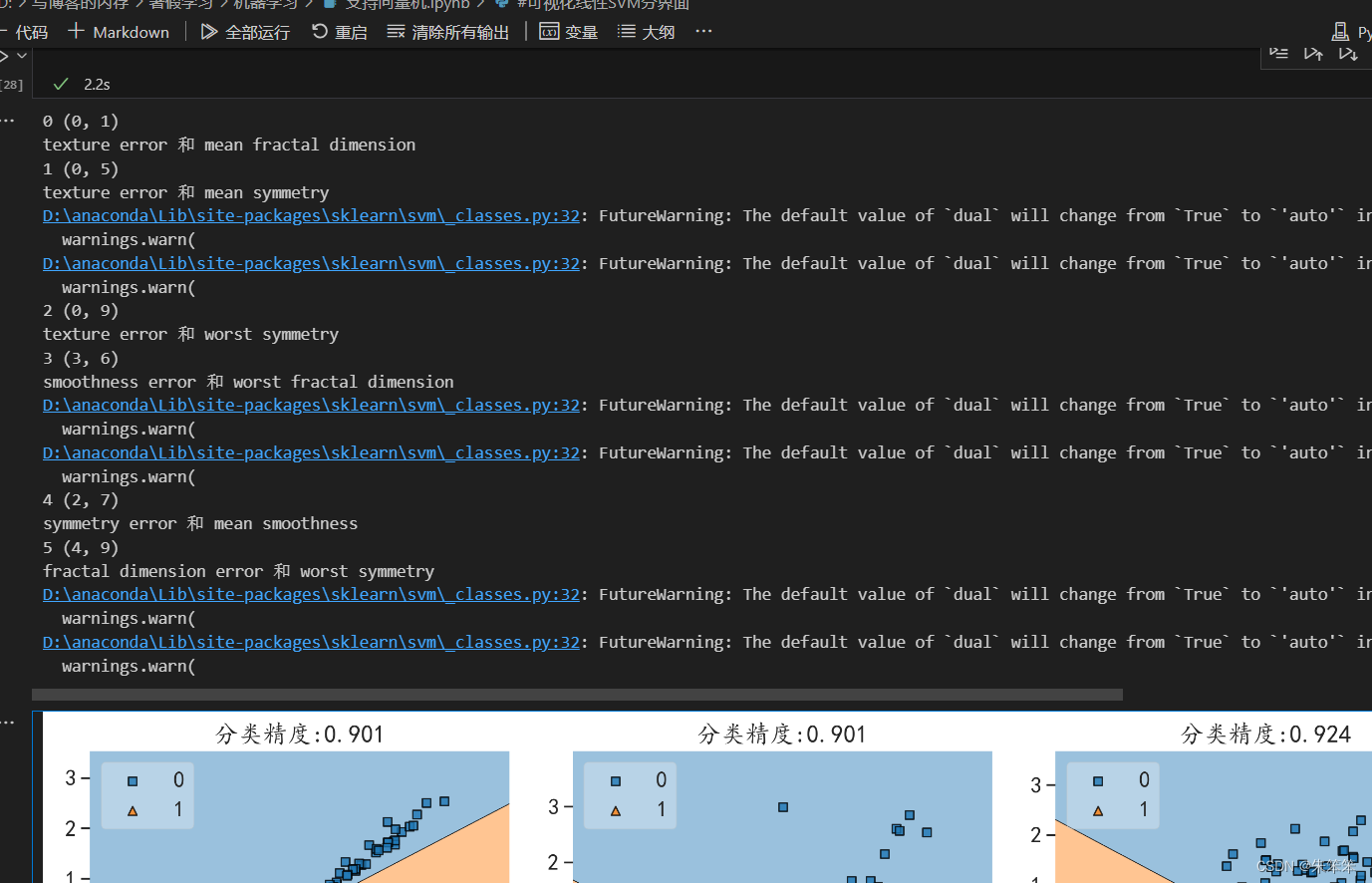
3.5非线性支持向量机
实际操作同理,只是把模型和参数微调
rbfsvm = SVC(kernel="rbf",gamma=0.1,C=1.0,random_state=1)
rbfsvm.fit(X_train,y_train)
rbfsvm_label = rbfsvm.predict(X_train)
rbfsvm_predict = rbfsvm.predict(X_test)
print("训练集精度",accuracy_score(y_train,rbfsvm_label))
print("测试集精度",accuracy_score(y_test,rbfsvm_predict))
plot_learning_curve(rbfsvm, u"SVM学习曲线",X, y)
#可视化线性SVM分界面
#基于特征10个太多我们只选取组合就行
zuhe = [[0,1],[0,5],[0,9],[3,6],[2,7],[4,9]]
plt.figure(figsize=(14,8))
for i,j in enumerate(zuhe):
print(i,j)
plt.subplot(2,3,i+1) ## 子窗口
#改变x,y轴的标签
plt.xlabel = Feature10[j[0]]
plt.ylabel = Feature10[j[1]]
print(Feature10[j[0]],"和",Feature10[j[1]])
## 训练模型
x_tr = X_train[:,j]
x_te = X_test[:,j]
rbfsvm = rbfsvm.fit(x_tr,y_train)
## 计算在测试集上的预测精度
rbfsvm_pre = rbfsvm.predict(x_te)
acc = accuracy_score(y_test,rbfsvm_pre)
## 可视化分界面
plot_decision_regions(x_te, y_test,clf=rbfsvm, legend=2)
plt.title("分类精度:"+str(round(acc,3)))
plt.tight_layout()
plt.show()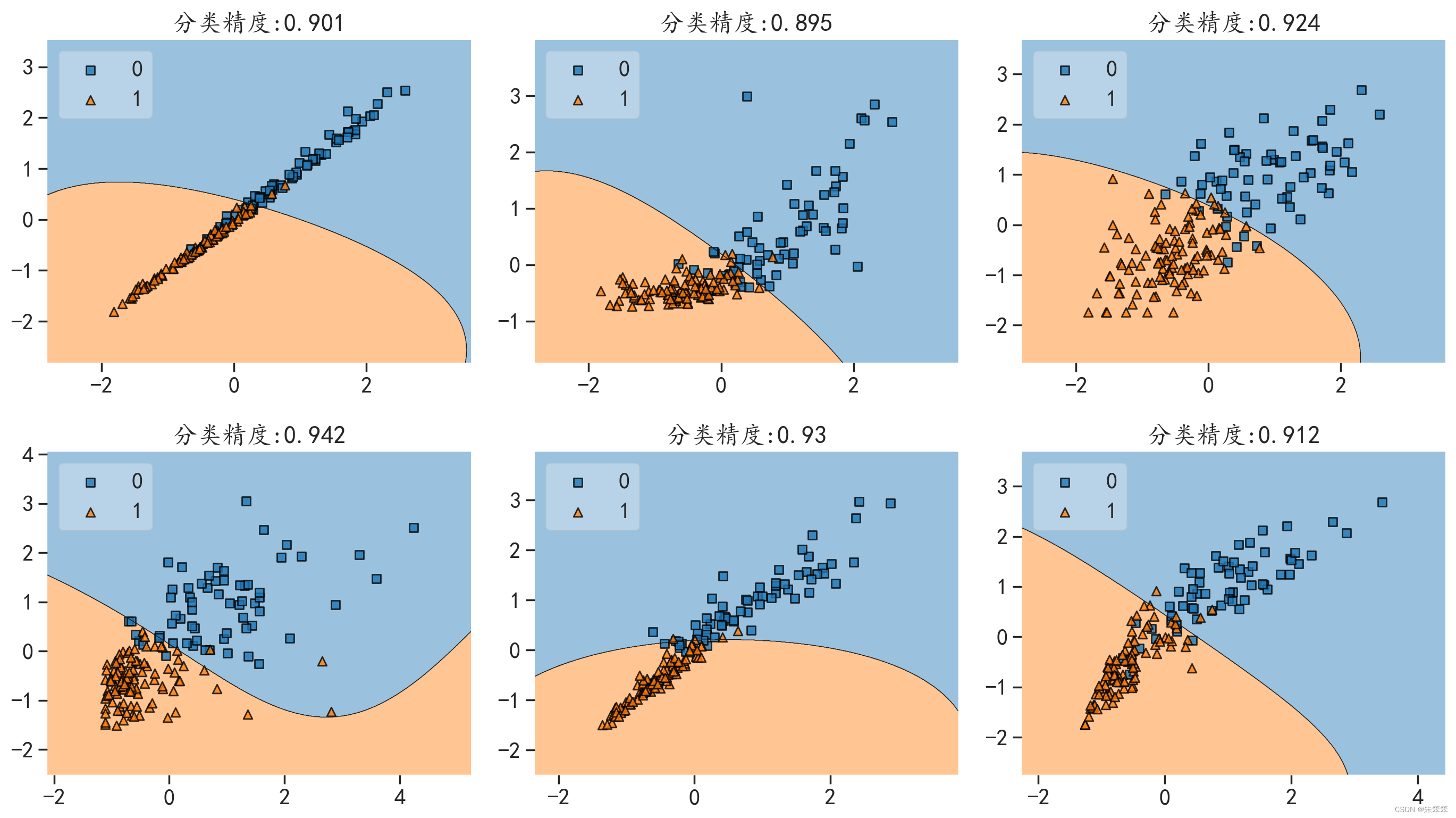
但均衡来看非线性的支持向量机再精度上好像与线性相似,看具体问题,毕竟具体问题具体分析,无非就是决策边界是条曲线or曲面罢了。
总结
总的来说这篇文章可以带领大家浅学支持向量机了,其实就是一个二分类问题。当然了,这个模型好像还可以做回归,作者还没有做过。
因为作者最近在忙统计调查,所以抽空出来写实在不容易,本篇一半的时间在图书馆完成,一半在工作室。其中还出现了bug请各位读者见谅。然后谢谢各位读者的支持,我也会坚持周更的,这个肯定不能食言。大家有时间也可以多去图书馆,里面的资源还挺好的。

















 2046
2046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











