






基础篇
关系型数据库:建立在关系模型基础上,由多张相互连接的二维表组成的数据库。
特点:
- 使用表存储数据,格式统一,便于维护。
- 使用SQL语言操作,标准统一,使用方便。
- MySQL启动:net start mysql80
SQL通用语法
- SQL的分类:
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data Definition Language | 数据定义语言,用来定义数据库对象(数据库、表、字段) |
| DML | Data Manipulation Language | 数据操作语言,用来对数据表中的数据进行增删改 |
| DQL | Data Query Language | 数据查询语言,用来查询数据库中表的记录 |
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户、控制数据库的访问权限 |
DDL-数据库操作
- 查询
查询所有数据库
show databases:
查询当前的数据库
select database();
- 创建
create database[ if not exists] 数据库名[deault charset 字符集] [collate 排序规则];
- 删除
drop database[ if exists] 数据库名;
- 使用
use 数据库名;
- 查询当前数据库所有表
show tables;
- 查询表结构
desc 表名
- 查询指定表的建表语句
show create table 表名;
- 创建
create table 表名{
字段1 字段1 类型[comment 字段1注释];
……
}
- 对表组成元素的删改操作
alter table 表名 add/modify/change/drop/rename to……;
- 删除整张表
drop table 表名;
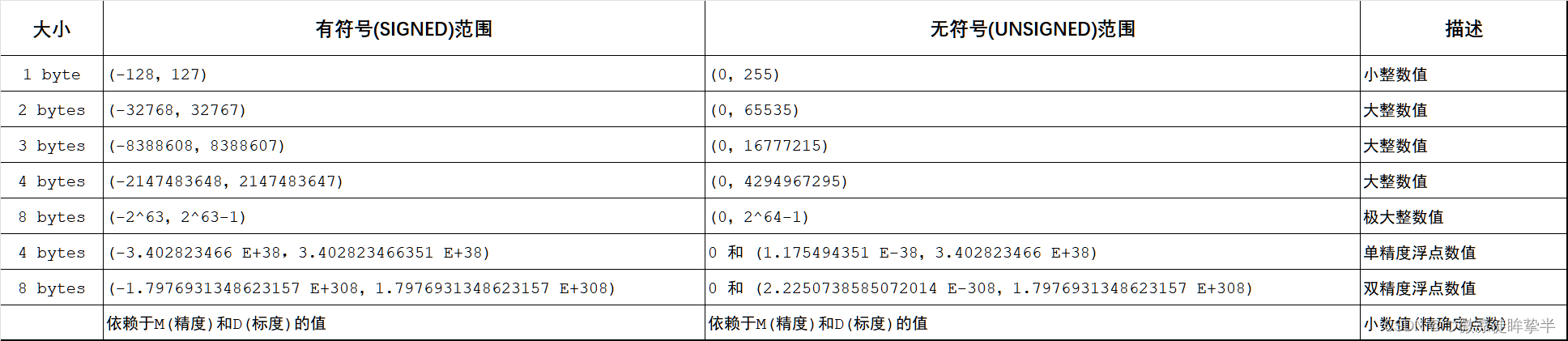
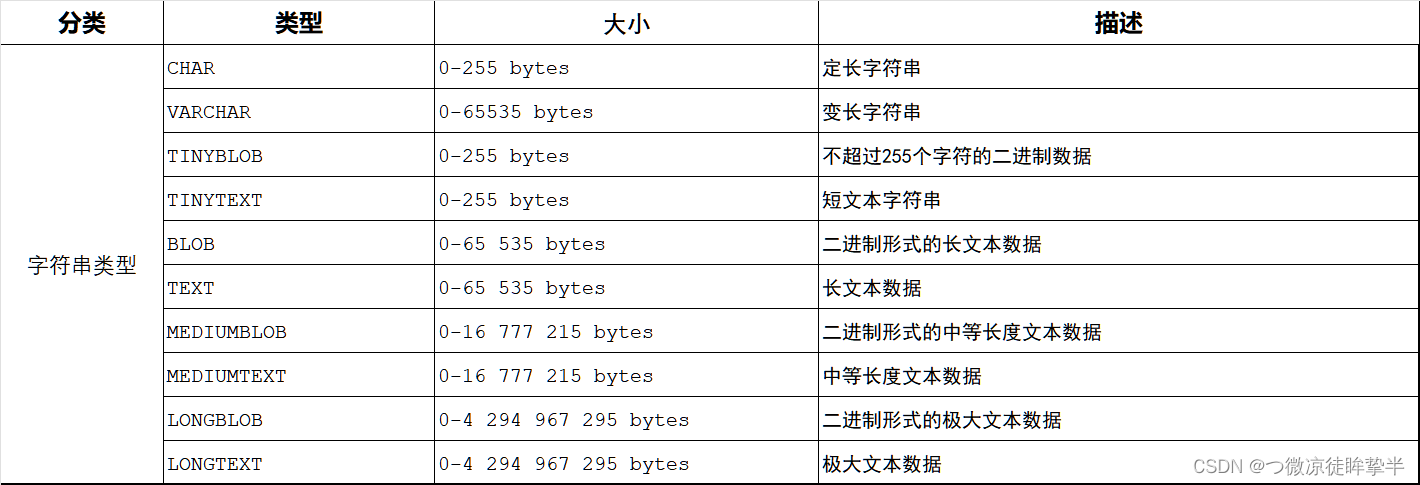
数据类型
数值类型
字符串类型
日期时间类型

案例:
create table emp(
-> id int comment '编号',
-> worknum varchar(10) comment '工号',
-> name varchar(10) comment '姓名',
-> age tinyint unsigned comment '年龄',
-> idcard char(18) comment '身份证号',
-> entrydate date comment '时间'
-> )comment '员工表' ;
DML
- 添加数据
- 给指定的字段添加数据
insert into 表名 (字段名1,字段名2,……) values (值1,值2……);
- 给全部字段添加数据
insert into 表名 values (值1,值2……);
- 批量添加数据
insert into 表名 (字段名1,字段名2,……) values(值1,值2,……),(……)……
insert into values (值1,值2……),(……),……
- 修改数据
updata 表名 set 字段名1=值1,字段名2=值2,……where 条件 ;
- 删除数据
delete from 表名 where 条件 ;
delete不能删除某一个字段的值(用updata可以实现)
DQL
用来查询数据库中的表的记录
- 查询多个字段
select 字段1,字段2,字段3……from 表名 ;
- 设置别名
select 字段 as ‘工作地址’ from 表名 ;
- 去除重复记录
select distinct 字段列表 from 表名 ;
- 条件查询
select 字段列表 from 表名 where 条件列表 ;
聚合函数
将一列数据作为一个整体,进行纵向计算。
常见聚合函数
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
语法
select 聚合函数(字段列表) from 表名 ;
所有的null不参与聚合函数运算
- 分组查询
语法:
select 字段列表 from 表名 [ where 条件 ] group by 分组字段名 [ having 分组后过滤条件 ]
where 和 having 区别
执行时机不同:where 是 分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
判断条件不同:where不能对聚合函数进行判断,而having可以。
注意:
执行顺序:where >聚合函数>having
分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
- 排序查询
语法:select 字段列表 from 表名 order by 字段1 排序方式1,字段2 排序方式2 ……;
asc:升序(默认值)
desc:降序
如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序。
例如:
根据年龄对公司的员工进行升序排序,年龄相同,再按照入职时间进行降序排序
select * from emp order by age asc,entrydate desc;
- 分页查询
语法:
select 字段列表 from 表名 limt 起始索引,每页展示记录数;
注意:
- 起始索引从0开始,起始索引=(查询页码-1)* 每页显示的记录数
- 分页查询时数据库的方言,不同的数据库有不同的实现,mysql时limit
- 如果查询的时第一页数据,起始索引可以省略,直接简写称limit 10.
例如:
查询第二页员工数据,每页展示10条记录----》(页码-1)*页展示记录数
select * from emp limit 10,10;
注意只能用作结尾


DCL
主要用来管理数据库
- 管理用户
- 查询用户
use mysql ;
select * from user ;
- 创建用户
create user ‘用户名’@‘主机名’ identified by ‘密码’ ;
- 修改用户密码
alter user ‘用户名’@‘主机名’ identified with mysql_native_password by ‘新密码’ ;
- 删除用户
drop user ‘用户名’@‘主机名’ ;
注意主机名可以用%通配
这类sql开发人员操作的比较少,主要是DBA使用
- 权限控制
常用权限

- 查询权限
show grants for ‘用户名’@‘主机名’ ;
- 授予权限
grants 权限列表 on 数据库名.表名 to ‘用户名’@‘主机名’;
- 撤销权限
revoke 权限列表 on 数据库名.表名 from ‘用户名’@‘主机名’;
注意:
多个权限之间,使用逗号分隔,
授权时,数据库名和表名可以使用 * 进行通配,代表所有
函数
- 字符串函数:

用select开头:select 函数名 (参数)
例子:
将员工的工号不足五位的向前补足五位用‘0’
update emp set workno = lpad(workno,5,'0') ;
- 数值函数

例子:
通过数据库的函数,生成一个六位数的随机验证码
select lpad(round(rand()*1000000,0),6,'0') ;
- 日期函数

案例:
查询所有员工的入职天数,并根据入职天数倒叙排序。
select name ,datediff(curdate(),entrydate) as 'entrydays' from emp order by entrydays desc ;
- 流程函数

约束
- 概念:约束是作用于表中字段上的规则,用于限制存储在表中的数据。
- 目的:保证数据库中数据的正确、有效性和完整性
- 分类:

注意:
约束是作用于表中字段上的,可以在创建表/修改表的时候添加以约束。
案例:

相关实现:
create table user(
id int primary key auto_increment comment '主键' ,
name varchar(10) not null unique comment '姓名' ,
age int check ( age > 0 && age <= 120 ) comment '年龄' ,
status char(1) default '1' comment '状态' ,
gender char(1) comment '性别'
) comment '用户表' ;
- 外键约束
语法:
- 添加外键:
create table 表名 (
字段名 数据类型 ,
constraint [外键名称] foreign key (外键字段名) references 主表 (主表列名)
);
alter table 表名 add constraint 外键名称 foreign key (外键字段名) references 主表(主列表名);
例子:
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) ;
emp表

dept表

- 删除外键
alter table 表名 drop foreign key 外键名称 ;
- 删除/更新行为

alter table 表名 add constraint 外键名称 foreign key (外键字段) references 主表名(主表字段名) on update 行为 on delete 行为 ;
例如:
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update cascade on delete cascade ;
多表查询
-
一对多
实现:在多的一方建立外键,指向一的一方的主键(要在原来基础上再建立一张表) -
一对一
实现:在任意一方加入外键,关联另一方的主键,并且设置外键为唯一的(unique)
就是将一张大表拆分成两个小表。
- 多表查询分类
连接查询
- 内连接:相当于查询A、B交集部分数据
隐式内连接:
select 字段列表 from 表1 ,表2 where 条件 …… ;
显式内连接
select 字段列表 from 表1 [inner] join 表2 on 连接条件 …… ;
- 外连接:
左外连接:查询左表所有数据,以及两张表交集部分。
select 字段列表 from 表1 left [outer] join 表2 on 条件 ……;
右外连接:查询右表所有数据,以及两张表叫集部分数据
select 字段列表 from 表1 right[outer] join 表2 on 条件 ……;
- 自连接:当前表与自身的连接查询,自连接必须使用表别名
案例:
-- 查询员工 及 其所属领导的名字--
select a.name ,b.name ,a.managerid,b.id from emp a,emp b where a.managerid = b.id;
-- 查询所有员工emp及其领导的名字emp,如果员工没有领导,也需要查询出来 --
-- 使用的是向左查询,使得所有员工显示出来。
select a.name '员工' ,b.name '领导' from emp a left join emp b on a.managerid = b.id;
-- 查询所有的领导,及其员工
select a.name '员工',b.name '领导' from emp a right join emp b on a.managerid = b.id;
6.联合查询-union ,union all
对于union查询,就是把多次查询的结果合并起来,形成一个性的查询结果集。
select 字段列表 from 表A ……
union [all]
select 字段列表 from 表B …… ;
注意:
对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致
union all 会将全部数据直接合并在一起,union 会对合并之后的数据去重
6. 子查询
- 标量子查询
返回结果是单个值(数字,字符串,日期等),最简单的形式,标量子查询。
常用操作符: = <> > >= < <=
例子:
查询”销售部“的所有员工信息。
select * from emp where dept_id = (select id from dept where name = '销售部') ;
- 列子查询
子查询返回结果是一行(多行)
例子:

查询比研发部的任意一个员工的工资高的员工的员工信息
select * from emp where salary > some (select salary from emp where dept_id = (select id from dept where name = '研发部') );
- 行子查询
子查询的返回结果是一行(多列)
常用的操作符: = 、 <> 、 IN 、NOT IN
例子:
查询与张无忌的薪资及其直属领导相同的员工信息。
select * from emp where (salary,managerid) = (select salary ,managerid from emp where name = '张无忌');
- 表子查询
子查询返回的是多行多列
常用的操作符:IN
例子:
-- 查询与路障可和宋远桥的职位和薪资相同的员工信息。
select * from emp where (salary,job) in (select salary , job from emp where name = '鹿杖客' or name = '宋远桥' );
-- 查询入职时间是 ”2006-01-01“ 之后的员工信息
select * from emp where entrydate > '2006-01-01';
-- 查询者部分员工对应的部门信息。
select e.*,d.* from (select * from emp where entrydate > '2006-01-01') e left join dept d on dept_id=d.id;
事务
- 事务操作
- 查看/设置事务提交方式
select @@autocommit;
set @@autocommit=0;
- 提交事务
commit;
- 回滚事务
rollback;
- 开始事务
start transaction 或 beign ;
- 提交事务
commit ;
- 回滚事务
rollback ;
- 四大特性

- 事务的隔离级别

-- 查看事务隔离级别
select @@transaction isolation ;
-- 设置事务隔离级别
set [session | global] transaction iosltaion level [隔离级别] ;
注意:
事务隔离级别越高,数据越安全,但是性能越低。
进阶篇
存储引擎
简介:存储引擎就是存储数据、建立索引、跟新/查询数据等技术的实现方式。存储引擎是基于表的,而不是基于库的,所以存储引擎也被称为表类型。
- 在创建表时,指定存储引擎
注意:在默认情况下存储引擎为 innodb
create table enginer(
id int ,
name varchar(10)
) engine MyISAM(存储引擎) ;
- 查看当前数据支持的存储引擎
show engines ;
InnoDB
介绍:InnoDB是一种兼顾高可靠性和高性能的通用存储引擎,在Mysql5.5后为默认存储引擎。
特点:
DML操作遵循ACID模型,支持事务;
行级锁,提高并发访问性能;
支持外键foreign key约束,保证数据的完整性和正确性;
文件:
xxx.ibd:xxx代表的是表名,innoDB引擎的每张表都会对应这样一个表空间文件,存储该表的表结构(frm,sdi)、数据和索引。
参数:innondb_file_per_table
MyISAM
介绍:
是MySQL早期的默认存储引擎
特点:
不支持事务,不支持外键
支持表锁,不支持行锁
访问速度快
文件
xxx.sdi: 存储表结构信息
xxx.MYD:存储数据
xxx.MYI: 存储索引
Memory
介绍:Memory引擎的表数据是存储在内存中的,由于受到硬件问题、或者断电问题的影响,只能将这些表作为临时表或者缓存使用。
特点
内存存放
hash索引(默认)
文件
xxx.sdi : 存储表结构信息
三种引擎的区别

存储引擎的应用:
INNODB:存储业务系统中对事务、数据完整性要求较高的核心数据(电商)
MyISAM:存储业务系统的非核心事务(评论)
索引
概述:
| 优势 | 劣势 |
|---|---|
| 提高数据检索的效率,降低数据库的IO成本 | 索引列要占空间 |
| 通过索引列对数据进行排序,降低CPU的消耗 | 索引大大提高了查询效率,同时降低了更新表的速度,如对表进行INSERT、UODATE、DELETE时,降低效率 |
索引的结构
索引主要在存储的索引层实现
在默认情况下,采用的时B+tree索引


二叉树
二叉树的缺点:顺序插入时,会形成一个链表,查询性能大大降低。大数据量的情况下,层级较深,检索速度慢。
红黑树:大数据量的情况下,层级较深,检索速度慢。
- B-tree(多路平衡查找树)
示例图:

- B+tree
相对于B-tree的区别:
所有的数据都会出现在叶子节点
叶子节点形成一个单向链表
Mysql索引数据结构对经典的B-tree进行了优化,增加了一个指向相邻叶子节点的链表指针,形成有顺序指针的B-tree,提高区间访问的性能。
例图:

- hash
索引特点:
hash索引只能用于对等比较(=,in),不支持范围查询(between ,<,>……)
无法利用索引完成排序操作
查询效率高,通常只需要一次检索就可以了,效率通常要高于B+tree索引
存储引擎支持
在MySQL中,支持hash索引的时Mermory引擎,而innodb中具有自适应hash功能,hash索引是存储引擎根据B+tree索引在指定条件下自动构建的。
在产生hash碰撞时,会通过链表解决该问题
例图:

思考题
为什么InnoDB存储引擎选择使用B+tree索引结构
- 相对二叉树,层级更少,搜索效率高。
- 对于B-tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中村春的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低。
- 相对Hash索引,B+tree支持范围匹配及排序操作。
索引分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建,只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的时文本中的关键词,而不是比较索引中的值 | 可以有多个 | FULLEXT |
- 根据存储形式分类:

索引语法
- 创建索引
create [unique | fulltext] index ind_name on table_name (index_col,name……);
- 查看索引
show index from table_name;
- 删除索引
drop index index_name on table_name ;
SQL执行频率
可以查看当前数据库的各操作的访问频次。
show global status like 'Com_______' ;(7个下划线)
- 慢查询日志(待重看)76
查询‘show_query_log’的状态
show variables like 'slow_query_log';
设置慢查询状态:
show_query_log=1 || [0];
- profile详情
查看每一台哦sql的耗时基本情况
show proflies ;
查看指定query_id的sql语句哥哥阶段的耗时情况
show profile for query query_id;
查看指定query_id的sql语句cpu的使用情况
show profile cpu for query query_id ;
- explain执行计划
各字段含义:
id:select 查询的序列号,表示查询中执行select子句或者是操作表的顺序(id相同,执行顺序从上到下,id不同,值越大,越线执行)。
select_type:表示select的类型,常见的取值有simple、primary、union、subquery等
type:表示链接类型,性能友好到差的连接类型为null、system、const、eq_ref、ref、range、index、all。
possible_key
显示可能应用在者张表上的索引,一个或者多个。
key:实际使用的索引,如果为null,则没有使用索引。
key_len :表示索引中使用的字段的字节数,改制为索引字段最大可能长度,并非实际使用长度,在不损失精确度的情况下,长度越短越好。
rows:MySQL认为必须要执行查询的行数,在innpdb引擎的表中,是一个估计值,可能并不总是准确的。
filered:表示返回的行数占需要读取的行数的百分比,filtered的值越大越好。
索引使用
-
最左前缀法则
如果索引了多列(联合索引),要遵循最左前缀法则。最左前缀法则指的是查询从索引的最左端开始,并且不跳过索引中的列。如果跳过则后面部分失效。 -
范围查询
联合查询索引中,出现范围查询(< , >),范围查询右侧的列索引失效。
解决方案:尽量采用<=,>=进行范围查询。 -
索引列运算
尽量不要在索引上进行运算,否则索引将失效。 -
字符串要加引号,否则将失效。
-
模糊查询,如果是尾部模糊查询匹配,索引不会失效。如果是头部模糊匹配,索引失效。
select * from 表名 where 字段名 like ‘%字段’ ;(失效)
select * from 表名 where 字段名 like ‘字段%’ ;(有效)
-
or连接的使用,如果在or前的条件中的列有索引,而后面的列中没有索引,那么涉及到的索引都不会被用到。
-
数据分布影响:如果MySQL评估使用索引比全表更慢,则不使用索引。
-
sql提示:用来优化操作
-- 建议选用此类索引方式
explain select * from tb_user use index (idx_user_pro_age_sta) where profession='软件工程';
-- 忽略采用此类索引方式
explain select * from tb_user ignore index (idx_user_pro_age_sta) where profession='软件工程';
//强迫采用此类索引方式
explain select * from tb_user force index(idx_user_pro_age_sta) where profession='软件工程';
- 前缀索引
当字段类型为字符串时,查询时需要查询很长的字符串浪费空间,此时可以将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率
语法:
create index idx_xxx on 表名 (列字段名(创建索引字符串的字符个数)) ;
前缀长度可以根据索引的选择性来决定,而选择是指不重复的索引值(基数)和数据表的记录总数的比值,索引值越高查询效率越好。
用来计算比值的语法:
例子:
select count(distinct email) /count(*) from tb_user;
select count(distinct substring(email,1,5)) /count(*) from tb_user ;
-
在业务场景中,如果存在多个查询条件,考虑针对查询字段,建议建立联合索引。可以有效避免回表查询。
-
索引使用原则

插入数据
order by 优化
- using filesort:通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中王城排序操作,所有不是通过索引直接返回排序结构的排序都叫做Filesort排序。
- using index :通过有序索引顺序扫描直接返回有序数据,这种情况using index,不需要额外排序,操作效率高。
-- 创建索引解决联合索引一升一降排序
create index idx_user_age_phone_ad on tb_user(age asc,phone desc) ;
-- 操作
explain select id,age,phone from tb_user order by age asc ,phone desc ;
总结:
根据排序字段建立合适的索引,多字段排时,也遵循最左前缀法则
尽量使用覆盖索引
多字段排序,一个升序一个降序,此时需要注意来拟合索引在创建时的规则。
如果不可避免的出现filesort,大数据量排序时,可以适当增大排序缓冲区大小sort_buffer_size(默认256k)。
group by 优化
- 在分组操作时,可以通过索引来提高效率
- 分组操作时,索引的使用也满足最左前缀法则。
limit优化
优化思路:一般分页查询时,通过创建覆盖索引能够比较好地提升性能,可以通过覆盖索引加子查询形式进行优化。
例子:
explain select * from tb_user t,(select id from tb_user order by id limit 200000,10) a where t.id=a.id;
count优化

updata 优化
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁,并且该索引不能失效,否则会从行锁升级成表锁。
视图
是一种虚拟存在的表。视图中的数据并不在数据库中实际存在,行和列数据来自自定义视图的查询中使用的表,并且是在使用视图时动态生成的。
只保存了查询的sql逻辑,不保存查询结果。所以我们在创建视图的时候,主要的工作就落在创建这条sql查询语句上。
- 创建
create [or replace] view 视图名称 as select语句 [with [cascaded | local] check option];
- 查询
-- 查询创建视图语句:
show create view 视图名称 ;
-- 查看视图数据:
select * from 视图名陈…… ;
- 修改
方法一:
create [or replace] view 视图名称 as select 语句 [with[cascaded | local] check option] ;
方法二:
alert view 视图名称 as select 语句 [with[cascaded | local] check option];
- 删除
drop view [if exits] 视图名称 ,……;
例子:
-- 创建视图
create or replace view stu_v_1 as select id,name,no from student where id<10;
-- 查看视图
show create view stu_v_1;
-- 修改视图
create or replace view stu_v_1 as select id,name,no from student where id<10;
-- 删除视图
drop view stu_v_1;
视图的检查选项
当使用with check option 子句创建视图时,mysql会通过视图检查正在更改的每个行,例如插入、更新、删除,以使其符合视图的定义。
为了确定检查的范围,mysql提供了两个选项:cascaded和local,默认值为cascaded
视图更新
要使视图可以更新,视图中的行于基础表中的行之间必须存在一对一的关系。如果视图包含以下任何一项,则该视图不可以更新:
- 聚合函数或者窗口函数(sum(),min(),max(),count()等)
- ditinct
- group by
- having
- union 或者 union all
作用:
简单:
视图不仅可以简化用户对数据的理解,也可以简化他们的财政。哪些被经常使用的查询可以被定义为视图,从而使得用户不必为以后的操作每次指定全部的条件。
安全:
数据库可以授权,但是不能授权到数据库特定行的特定的列上。通过视图用户只能查询和修改他们所能看见的数据。
数据独立
视图可以帮助用户屏蔽真实表结构变化带来的影响。
储存过程
-- 创建
create procedure p1()-- 名称
begin
select * from student;
end;
-- 调用
call p1();
-- 查看
select * from information_schema.ROUTINES where ROUTINE_SCHEMA='itcase';
show create procedure p1;-- 查询某个存储过程的定义
-- 删除
drop procedure p1;
变量
系统变量是mysql服务器提供,不是用户定义的,属于服务器层面。分为全局变量(global)、会话变量(session)
- 查看系统变量
show [session | global] variables;-- 查看所有系统变量
show [session | global] variables like '……';-- 可以通过like模糊匹配方法查找变量
select @@[session | global] variable 系统变量名;-- 查看指定变量的值
- 设置系统变量
set [session | global] 系统变量名 =值;
set @@[session | global] 系统变量名 = 值;
注意:
如果没有指定session/global,默认是session,会话变量。
mysql服务启动后,所设置的全局参数会失效,要想不失效,可以在/etc/my.cnf/中配置。
-- 创建变量并赋值
set @myname = 'itcase';
set @age:=10;
select @age,@myname;
-- 将查询结果赋值给变量
select count(*) into @mycount from itcase.tb_user;
- 局部变量
局部变量是根据需要定义的在局部生效的变量,访问之前,需要declare声明,可用作存储过程内的局部变量和输入参数,局部变量的范围是在其内声明的begin……end块。
声明:变量类型就是数据库字段类型:int、bigint、char、varchar、date、time等。
declare 变量名 变量类型 ;
赋值
set 变量名 = 值;
set 变量名:=值;
select 字段名 into 变量名 from 表名 ……;
例子:
create procedure p3()
begin
declare stu_count int default 0;-- 声明
select count(*) into stu_count from student;-- 赋值
select stu_count;-- 展示
end;
-- 调用
call p3();
if
语法:
create procedure p2()
begin
declare score int default 58;
declare result varchar(10);
if score >=85 then
set result :='GOOD';
elseif score >=60 then
set result :='及格';
else
set result:='不及格';
end if;
select result;
end
- 修改版
create procedure p5(in score int ,out result varchar(10))
begin
if score >=85 then
set result :='GOOD';
elseif score >=60 then
set result :='及格';
else
set result:='不及格';
end if;
end;
call p5(61,@result);
select @result;
case
- 语法一:
case 表达式
when value1 then statement_list1(执行语句);
when value2 then statement_list2;……
else statement_list
end case;
- 语法二
case
when search_condition1 then statement_list1;
when search_condition then statement_list2……;
else statement_list;
end case;
while
create procedure p7(in n int )
begin
declare total int default 0;
while n>0 do
set total:=total+n;
set n:=n-1;
end while;
select total;
end;
call p7(10);
repeat
create procedure p8(in n int)
begin
declare total int default 0;
repeat
set total:=total+n;
set n:=n-1;
until n<=0
end repeat;
select total;
end;
call p8(10);
loop
loop实现简单的循环,如果不在sql逻辑中增加退出循环条件,可以用其他实现简单的死循环。loop可以配合一下两个语句的使用:
leave:配合循环使用,退出循环。
iterate:必须用在循环中,作用是跳过当前循环剩下的语句,直接进入下一次循环。
-- 求出在以内奇数的和。
create procedure p10(in n int )
begin
declare total int default 0;
sum:loop
if n<=0 then
leave sum;
end if;
if n%2=1 then
set n:=n-1;
iterate sum;
end if;
set total :=total+n;
set n:=n-1;
end loop;
select total;
end;
call p10(100);
游标
游标是用来存储查询结果集的数据类型,在存储构成和函数中可以使用游标对结果集进行循环的处理。
步骤:
- declare 游标名称 cursor for 查询语句;
- open 游标名称;
- fetch 游标名称 into 变量 ;
- close 游标名称 ;

演示
create procedure p11(in uage int)
begin
//声明变量
declare uname varchar(100);
declare upro varchar(100);
//声明游标
declare u_cursor cursor for select name ,profession from itcase.tb_user where age<=uage;
//进行报错处理
declare exit handler for SQLSTATE '02000' close u_cursor;
//创建一个表用来储存数据
drop table if exists tb_user_pro;
create table if not exists tb_user_pro(
id int primary key auto_increment,
name varchar(100),
profession varchar(100)
);
open u_cursor;
//将表中的数据进行获取分别赋值给变量
while true do
fetch u_cursor into uname,upro;
insert into tb_user_pro values(null,uname,upro);
end while;
close u_cursor;
end;
//调用
call p11(40);
存储函数

示例:
create function fun1(n int)
returns int deterministic
begin
declare total int default 0;
while n>0 do
set total :=total + n;
set n:=n-1;
end while;
return total;
end;
select fun1(100);
触发器
通过触发器记录表的数据变更日志,将变更日志插入到日志表中,包含增删改。
例子:

create table user_logs(
id int(11) not null auto_increment,
operation varchar(20) not null comment '操作类型, insert/update/delete',
operate_time datetime not null comment '操作时间',
operate_id int(11) not null comment '操作的ID',
operate_params varchar(500) comment '操作参数',
primary key(`id`)
)engine=innodb default charset=utf8;
create trigger tb_user_insert_trigger
after insert on itcase.tb_user for each row
begin
insert into user_logs(id,operation,operate_time,operate_id,operate_params) values(null,'insert',now(),new.id,
concat('插入的数据内容为:id',new.id,',name=',new.name,',phone=',new.phone,',email=',new.email,',profession=',new.profession));
end;
show triggers ;
drop trigger tb_user_insert_trigger;
insert into itcase.tb_user(id, name, phone, email, profession, age, gender, status, createtime)
VALUES (27,'二皇子','18809091212','erhuangzi@163.com','软件工程',26,'1','1',now());
锁
- 全局锁

在上锁后不能对表进行增删改。
- 表级锁
- 表锁
表共享读锁
表独占写锁
语法:
- 加锁:lock tables 表名……read/write.
- 释放锁:unlock tables/客户端断开连接。
读锁不会堵塞其他客户端的读,但是会堵塞写。写锁既会堵塞其他客户端的读,还会堵塞其他客户端的写
- 元数据锁
为了避免DML与DDL冲突,保证读写的正确性

查看元数据锁:
select object_type,object_schema,object_name,lock_type,lock_duration from performance_schema.metadata_locks;
- 意向锁
- 意向共享锁(IS):与表锁共享锁(read)兼容,与排他锁(write) 互斥。
- 意向排他锁(IX):与表共享锁(read)及排他锁(write)都互斥。意向锁之间不会互斥
查看意向锁和行锁的加锁情况:
select object_schema,object_name,lock_type,lock_mode,locK_data from performance_schema.data_locks;
- 行级锁


默认情况下,innoDB在REPEATABLE READ事务隔离级别运行,innoDB使用next-key锁进行搜索和索引扫描,以防止幻读,
- 针对唯一索引时,对已存在的记录进行等值匹配时,会自动优化为行锁。
2.innoDB的行锁是针对于索引加的锁,不通过索引条件检索数据,那么innoDB将对表中的所有记录加锁,此时就会升级为表锁。
- 间隙锁/临键锁

事务原理
- redo log

- undo log
保证事务的原子性

MVCC
基本概念

实现原理
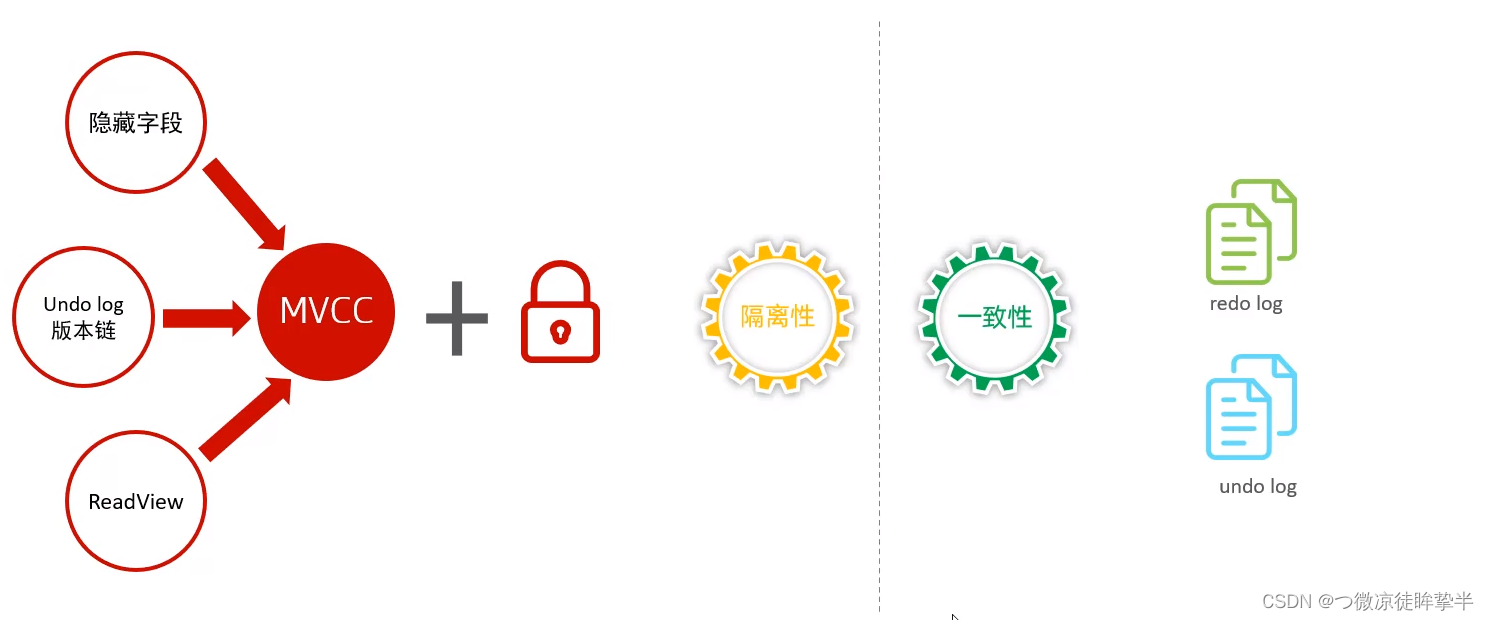
- 记录中的隐藏字段

不同的事务或相同事务对同一条记录进行修改,会导致该记录的undolog生成一条记录版本链表,链表的头部是最新的旧纪录,链表的尾部是最早的旧纪录。


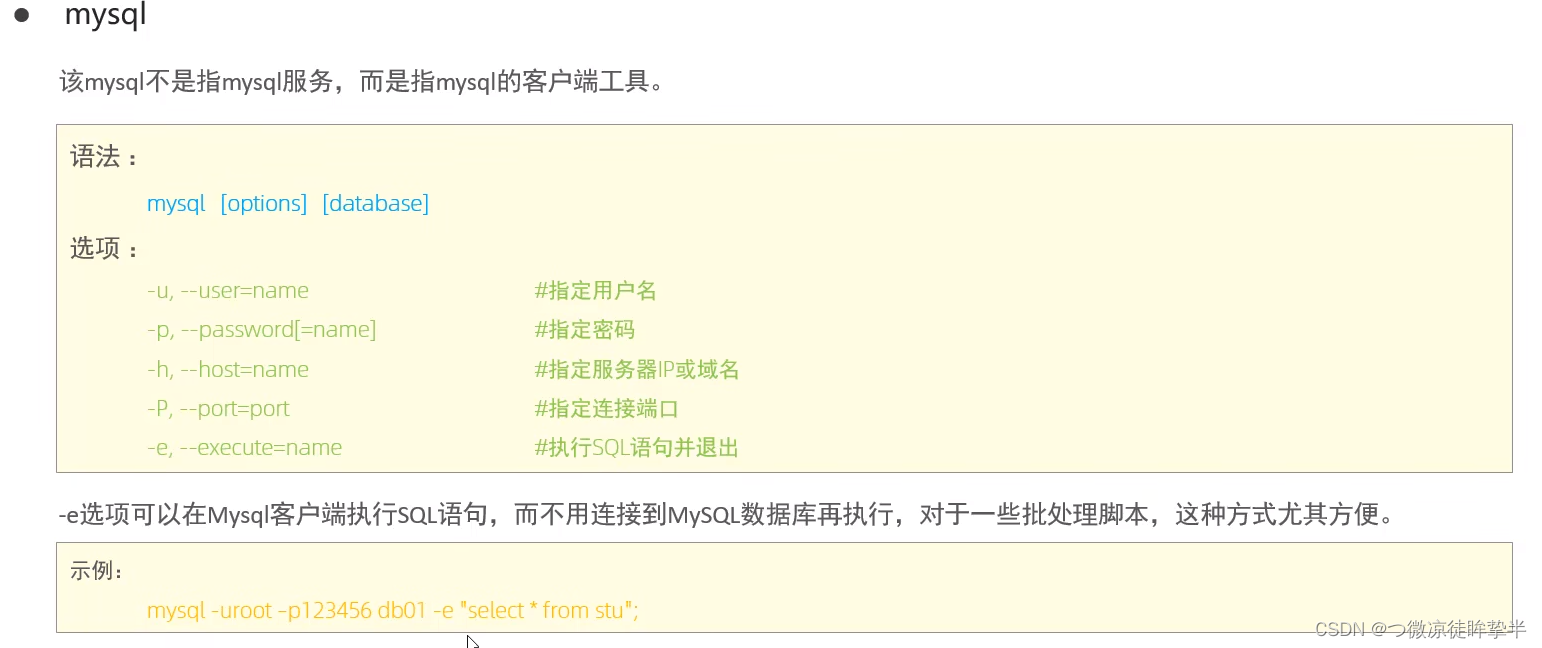
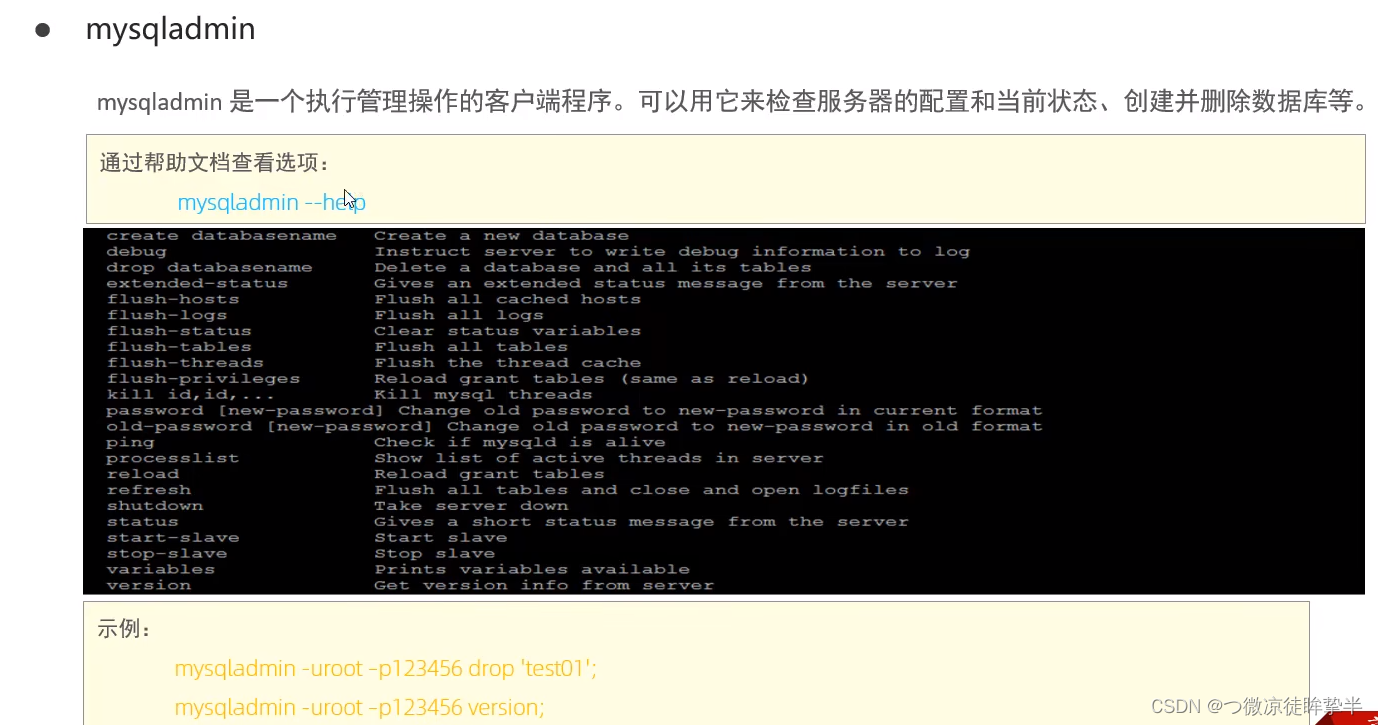
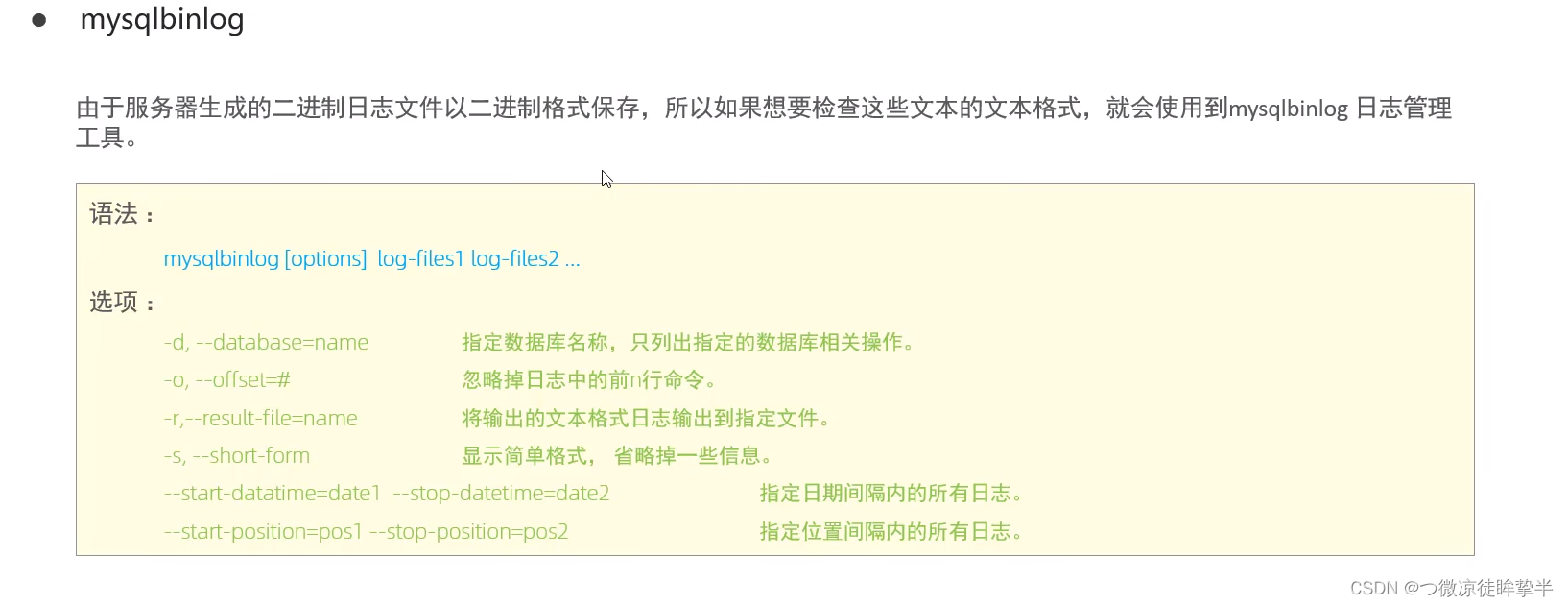
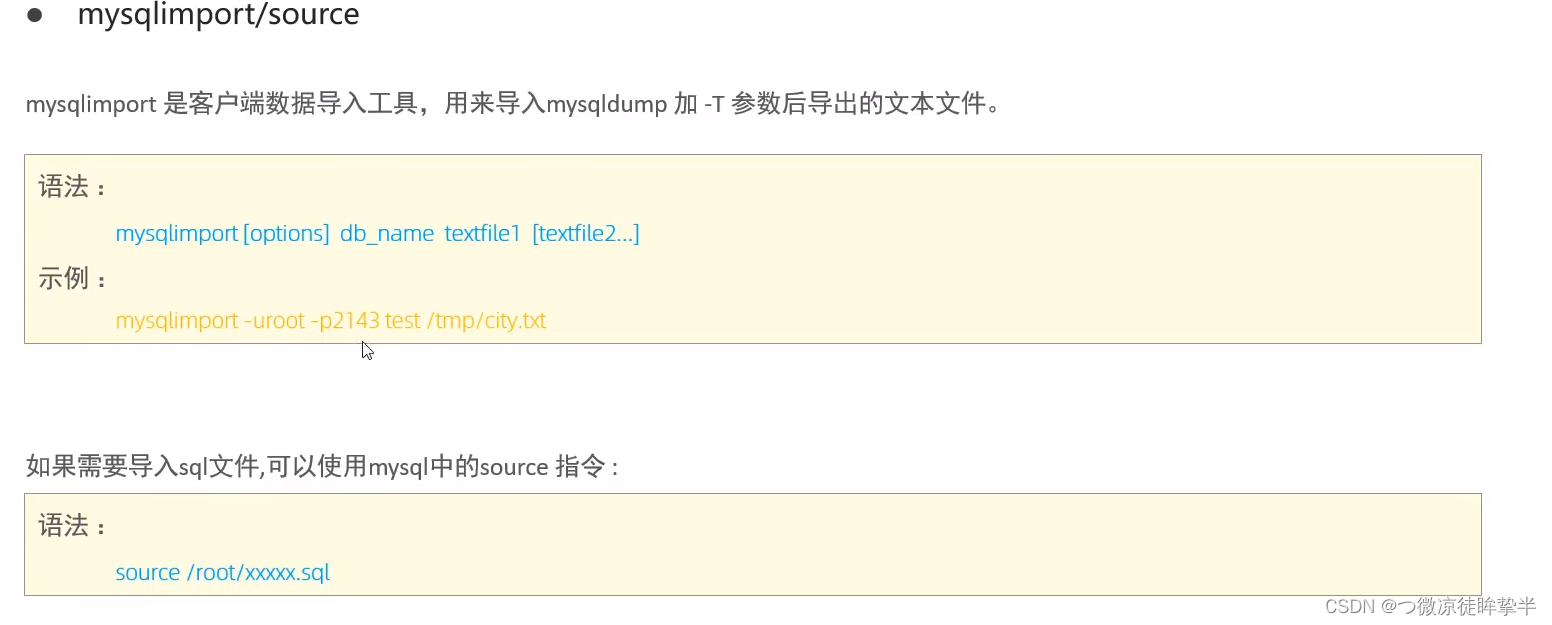
常用工具



















 693
693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









