







在机器学习和深度学习中,有许多经典的数据集被广泛用于模型训练、验证和测试。以下是一些常见的数据集以及它们的特征:
1. MNIST(手写数字数据集)
描述:MNIST(Modified National Institute of Standards and Technology)数据集包含70,000张手写数字图像(28x28像素的灰度图像),分为60,000张训练样本和10,000张测试样本。
特点:
任务:手写数字识别
数据类型:图像(灰度图像)
类别:10个(数字0到9)
简单且易于使用,常用于入门级别的深度学习模型训练。
2. CIFAR-10 和 CIFAR-100
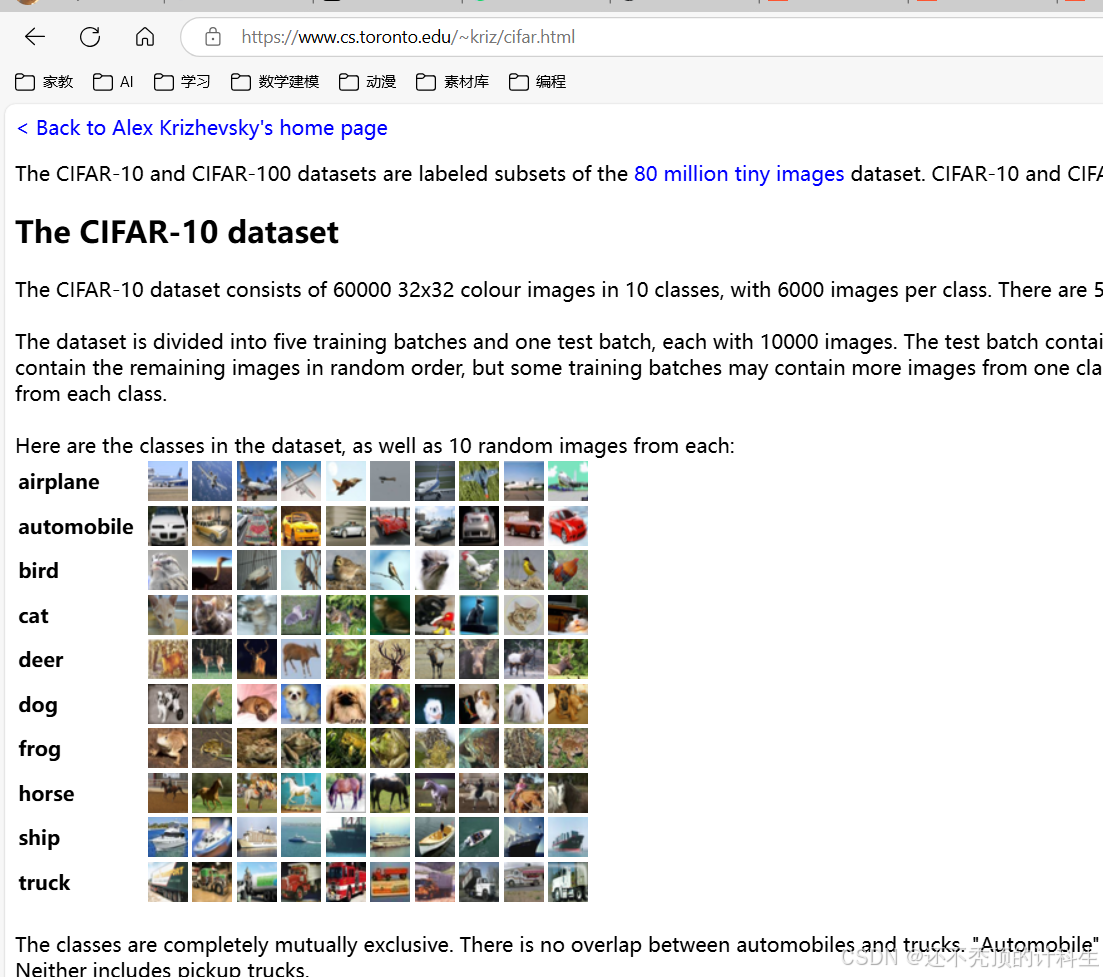
描述:CIFAR(Canadian Institute for Advanced Research)是由10类和100类物体组成的小图像数据集。CIFAR-10包含60,000张32x32像素的彩色图像,其中10类,每类6,000张图片;CIFAR-100是CIFAR-10的扩展版本,包含100个类别,每个类别有600张图片。
特点:
任务:物体分类
数据类型:图像(彩色图像)
类别:CIFAR-10有10类,CIFAR-100有100类
图像尺寸较小,适合深度学习中的卷积神经网络(CNN)实验。
网站为:
3. ImageNet
描述:ImageNet是一个包含超过1,000万张标注图像的大型数据集,分为1,000个类别。ImageNet用于图像分类、物体识别等任务,常用于深度学习模型的训练。
特点:
任务:物体分类、物体检测、图像标注等
数据类型:图像(彩色图像)
类别:1,000类
包含大量的图像,适合训练大规模深度神经网络(如ResNet、VGG等)。
4. COCO (Common Objects in Context)
描述:COCO是一个用于物体检测、分割和图像描述的数据集,包含了330,000张图像,其中有80类物体标注。它提供了丰富的标注信息,包括物体检测、关键点标注、语义分割等。
特点:
任务:物体检测、语义分割、图像描述等
数据类型:图像(彩色图像)
类别:80类物体
标注详细,包括边界框、分割掩码、关键点等。
5. PASCAL VOC
描述:PASCAL VOC(Visual Object Classes)是一个广泛用于物体检测和图像分割的标准数据集。它包含20个类别,适用于图像分类、物体检测、图像分割等任务。
特点:
任务:物体检测、图像分割、分类等
数据类型:图像(彩色图像)
类别:20类
每个图像有标注信息,包括边界框、分割区域等。
6. UCI Machine Learning Repository
描述:UCI(University of California, Irvine)机器学习库是一个包含各种类型数据集的集合,涵盖分类、回归、聚类等任务。它包括大量经典的结构化数据集。
特点:
任务:分类、回归、聚类等
数据类型:结构化数据(表格型数据)
类别:根据不同数据集的具体任务而不同
包含许多不同领域的经典数据集,如Iris数据集、Wine数据集等。
7. Kaggle Datasets
描述:Kaggle是一个数据科学竞赛平台,提供了大量的数据集,涉及领域包括金融、医学、图像、文本等。
特点:
任务:分类、回归、生成模型、推荐系统等
数据类型:多种类型,包括结构化数据、文本数据、图像数据等
类别:根据具体任务而不同
数据集质量较高,且有大量竞赛和社区资源支持。
8. Sentiment140
描述:Sentiment140是一个文本数据集,包含160万条推文,并标注了情感分类(积极、消极、或者中性)。
特点:
任务:情感分析
数据类型:文本(推文)
类别:情感分类(正面、负面)
大型数据集,适合文本分类模型训练。
9. Amazon Reviews
描述:Amazon Reviews数据集包含了来自亚马逊产品评论的文本数据,涉及各种产品和用户评分。适用于情感分析、推荐系统等任务。
特点:
任务:情感分析、推荐系统
数据类型:文本(用户评论)
类别:评级(1到5星)
含有大量产品评论和评分数据,适合用于推荐系统和情感分析模型。
10. LSTM/Transformer 语料库(如OpenSubtitles)
描述:这些数据集包含了大量的文本数据,适合用于语言模型训练、机器翻译等任务。例如,OpenSubtitles包含了数百万的电影字幕,适用于语言模型和文本生成任务。
特点:
任务:自然语言处理、机器翻译、对话系统等
数据类型:文本(对话或字幕)
类别:无固定类别,但有丰富的语言信息
适用于训练语言模型(如LSTM、Transformer等)。
11. SQUAD (Stanford Question Answering Dataset)
描述:SQUAD是一个用于问答系统的数据集,包含了大量的文章和基于文章的问答对。数据集用于评估机器阅读理解能力。
特点:
任务:问答系统、机器阅读理解
数据类型:文本(文章和问题)
类别:无类别(根据文章内容回答问题)
包含长文本和基于文本的问答对,适合用于训练和评估问答系统。
12.EMNIST
EMNIST(Extended MNIST)数据集是一个扩展版的MNIST数据集,旨在提供更广泛的手写字符识别任务。它由多个子数据集组成,包含了手写数字和字母的图像,扩展了传统MNIST的应用范围,尤其是在字符识别领域。
EMNIST数据集的特点:
扩展性:EMNIST不仅包括数字(0-9),还扩展了包含手写字母(大写字母和小写字母)的数据集。
字符类别:它涵盖了多个字符集,涵盖了大写字母(A-Z)和小写字母(a-z)的手写样本。
图像尺寸:与MNIST数据集相似,EMNIST中的图像大小通常为28x28像素的灰度图像,适合用于深度学习模型的训练。
EMNIST的主要子集:
EMNIST有几个不同的子数据集,具体包括:
EMNIST ByClass:
包含所有的字母(大写和小写字母)和数字(0-9)。
每个类别都有较大的样本数量,适用于字符分类任务。
包含814,255个样本,62个类别(包括数字和字母)。
EMNIST ByMerge:
与ByClass类似,但是将部分相似类别合并,减少类别数目。
包含814,255个样本,47个类别(合并了大小写字母的相似类别)。
EMNIST Balanced:
提供一个平衡的数据集,意味着每个类别的样本数量大致相等。
包含814,255个样本,47个类别(包括数字和字母)。
EMNIST Letters:
仅包括大写字母(A-Z)。
包含145,000个样本,26个类别(字母A到Z)。
EMNIST Digits:
仅包括手写数字(0-9),与原始MNIST相似。
包含280,000个样本,10个类别(数字0到9)。
EMNIST MNIST:
包含手写数字和字母(大写字母)。
与MNIST数据集类似,但还增加了字母的样本。
EMNIST数据集的特点:
任务:手写字符识别,包括数字和字母。
数据类型:图像数据(28x28像素的灰度图像)。
应用:EMNIST适用于训练和评估各种字符识别模型,特别是在更广泛的手写字符识别任务中(不仅限于数字)。
扩展性:与MNIST相比,EMNIST适用于需要处理更多类别(如字母和数字)的任务,适合用于更复杂的深度学习模型训练。
总结
不同的数据集有不同的应用场景和任务类型。图像数据集(如MNIST、CIFAR、ImageNet)适用于计算机视觉任务;文本数据集(如Sentiment140、SQUAD)适用于自然语言处理任务;结构化数据集(如UCI、Kaggle数据集)适用于传统的机器学习任务(分类、回归等)。选择适当的数据集是进行模型训练和测试的重要一步,数据集的质量和规模直接影响模型的表现。



















 2275
2275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











