






第二章
数据抓取
首先 , 我们会介绍一个叫 做Firebug Lite 的浏览器扩展, 用 于检查网页 内容 , 如 果你有一些网络开发背景的话, 可能 己经对该扩展十分熟悉 了 。 然后 ,我们会介绍三 种抽取网 页数据的 方法 , 分别是正则表达式、 Beauti削Soup up 和lxml 。 最后 , 我们将 对 比这三 种数据抓取方法 。
2.1 分析网页
想要了解一个网页的结构如何,可以使用查看源代码的 方法 。在大多数浏览器中 ,都可以在页面上右键单击选择 ViView page source 选工页 工页 ,获取网页的源代码,如 图 2. 1 所示。我们可 以在 H刊伍 的下述代码 中 找到我们感兴趣 的 数据 。
<table>
<tr id= ”place s_national_flag_row ” ><td class=”w2p_f l ” ><label
for= ”place s_national_flag ”

2.2.2 Beautiful Soup
Beautifuful Soup
是一个非常流行的Pythython模块 。该模块可 以解析网页,并提供定位 内 容的便捷接 口 。 如果你还没有安装该模块 ,可 以使用 下面的命令安装其最新版本:pip install beautifuls。up4使用 Beauautiful Soup 的第一步是将 己下载的 HTML 内 容解析为 soup 文档 。由 于大多数网 页都不具备 良好的 HTML 格式, 因 此 Beautiful Soup需要对其实 际格式进行确定 。例 如 ,在下面这个简单网页的列表 中 ,存在属性值两侧引号缺失和标签未 闭含 的 问题。
<ul class=country>
<li>Area
<li>Population
< /ul>
2.2.3 Lxml
Lxml 是基于 l ibxml 2 这一 XML 解析库的 Python封装 。该模块使用 C语言编写 ,解析速度 比 Beauautiful Soup 更快 ,不过安装过程也更为复杂 。最新的 安装说明可以参考 http : / / Lxml . de / instal l at i on . html o和 Beauautiful Soup 一样 ,使用 lxml 模块的第一步也是将有可能不合法的HTML 解析为统一格式 。下面是使用 该模块解析同一个不完整 HTML 的例子 。
》> import lxml . html
》> bro ken html = ’ <ul clas s=country><li>Area<li>Population</ul> ’ 》> tree = lxml . html . fromstring (broken_ html ) # parse the HTML
》> fixed html = lxml . html . tos tring ( tree , pretty_pr int=True )
》> print fixed_html
<ul clas s=” country">
<li>Area< /li>
<li>Popul ation< /li>
< /ul>

的例子相同
2.2.5 结论表
2. 1 总结了每种抓取方法的优缺点 。
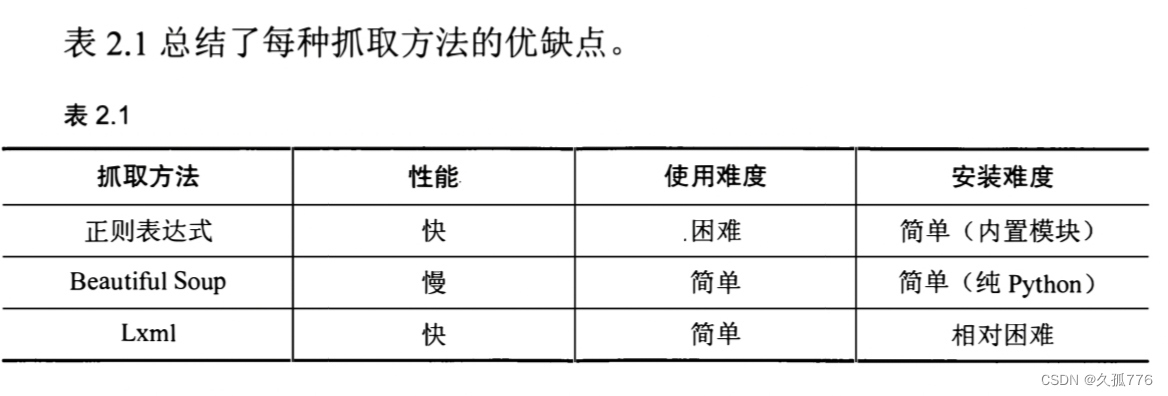
如果你的爬虫瓶颈是下载网页,而不是抽取数据的话 ,那么使用较慢的方法 ( 如 Beauautiful Soup ) 也不成 问题。如果只需抓取少量数据 ,并且想要避免额外依赖的话, 那 么 正则表达式可能更加适合 。不过, 通常情况下 ,l xml 是抓取数据 的 最好 选择 , 这是因为该方法既快速又健壮而正则表达式和Beautiful Soup up 只在某些特定场景下有用 。
2.2.6 为链接爬虫添加抓取回调
前面我们 已 经了解了如何抓取国家数据 , 接 下来我们 需 要将其集成到上一章的 链接爬虫 当 中 。要想复用这段爬虫代码抓取其他网站,我们需要添加 一个 cal lback参数处理抓取行 为 。 cal lba c k 是一个函数在发生某个特定 事件之后会调用该函数( 在本例中,会在 网 页下载完成后 调用 ) 。该抓取 cal lback 函 数包含url和html 两个参数 ,并且可 以返回一个待爬取的URL 列 表 。 下面是其实现代码 , 可以看出在 Python 中 实现该功能非常简单 。
de f link_crawler ( ... , , s c rape_cal lbac k=None ):
links = []
if scrapape_callback :
links . extend ( scrape__callback (url , ht皿1) or [ ] )
2.3 本章小结
在本章 中 ,我们介绍了几种抓取网页数据的方法。正则表达式在一次性数据抓取中非常有用 ,此外还可以避免解析整个网页带来的开销 :BeautifulSoup提供了更高层次的接口 ,同 时还能避免过多麻烦的依赖。不过通常情况下 ,lxml 是我们的最佳选择,因为它速度更快 , 功能更加丰富 ,因此在接下来的例子中我们将会使用 l xml 模块进行数据抓取。
下一章, 我们会介绍缓存技术 ,这样就能把网 页保存下来 , 只 在爬虫第一次运行时才会下载 网页。
















 6482
6482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











