







什么是支持向量机
支持向量机(简称SVM)是一种强大的监督学习算法,主要用于分类和回归任务。
SVM的核心思想是在特征空间中寻找一个最优的超平面,这个超平面能够使得不同类别的数据点尽可能地分开,即最大化两个类别之间的间隔。这个间隔被称为“间隔边界”,而最靠近这个边界的数据点被称为“支持向量”。
以一个二维平面为例,判定边界是一个超平面(在本图中其实是一条线,但是可以将它想象为一个平面乃至更高维形式在二维平面的映射),它是由支持向量所确定的(支持向量是离判定边界最近的样本点,它们决定了判定边界的位置)。
间隔的正中就是判定边界,间隔距离体现了两类数据的差异大小
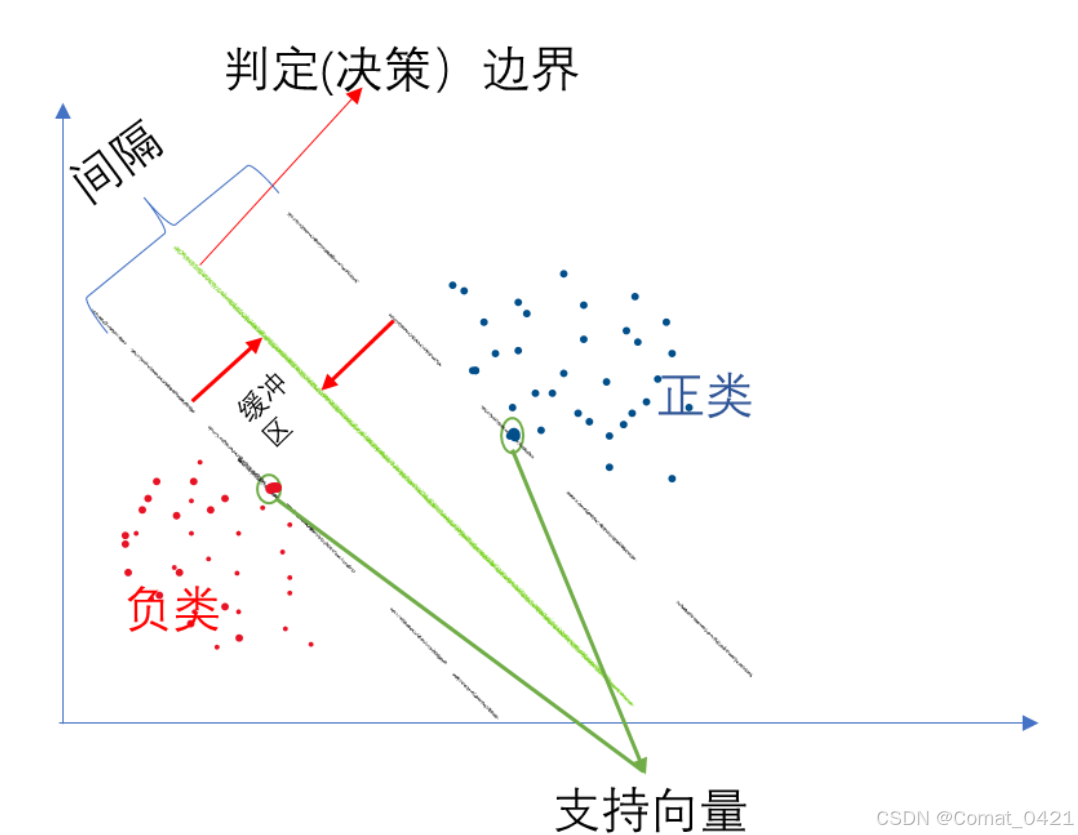
若严格地规定所有的样本点都不在“缓冲区”,都正确的在两边,称为硬间隔分类; 但是在一般情况下,不易实现,这里有两个问题:
第一,它只对线性可分的数据起作用。第二,有异常值的干扰。
在实际应用中,数据可能不是完全线性可分的,这时可以引入软间隔的概念。软间隔SVM通过引入松弛变量ξi(ξi≥0)来允许一些数据点违反间隔规则,即它们可以位于间隔边界的内部。这样做的目的是为了在最大化间隔的同时,最小化分类错误的数量。通过引入正则化参数C来控制间隔的宽度和误分类之间的权衡。在SVM中,正则化项通常是权重向量w的L2范数(即w的平方和的一半),这有助于防止过拟合,因为过拟合的模型往往对训练数据拟合得很好,但在未见过的测试数据上表现不佳。正则化参数C是一个超参数,它控制着间隔最大化(间隔最大化指的是在特征空间中找到一个超平面,使得不同类别的数据点被这个超平面尽可能远地分开)和误分类惩罚(误分类惩罚是指在SVM中对于那些位于间隔边界错误一侧或者边界上的数据点的惩罚。在硬间隔SVM中,所有数据点都必须被正确分类,即它们必须完全位于间隔边界的两侧。在软间隔SVM中,允许一些数据点违反这个规则,即它们可以位于间隔边界的内部或者甚至在边界的另一侧。)之间的权衡。C的值越大,模型对误分类的惩罚就越大,越倾向于硬间隔;C的值越小,模型对误分类的容忍度就越高,越倾向于软间隔。

在SVM中,有时候很难找出一条线或一个超平面来分割数据集,这时候我们就需要升维(把无法线性分割的样本映射到高纬度空间,在高维空间实现分割),核函数是特征转换函数,它可以将数据映射到高维特征空间中,从而更好地处理非线性关系。
核函数的作用是通过计算两个样本之间的相似度(内积)来替代显式地进行特征映射,从而避免了高维空间的计算开销。
在SVM中,核函数的选择非常
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









