






创建线程
首先,Linux内核中是没有线程的概念的,但是有轻量级进程的概念。系统不会给我们提供线程的系统调用,只会给我们提供轻量级进程的系统调用。所以,我们要创建线程,就要使用pthread线程库。pthread线程库对轻量级进程接口进行了封装,为我们用户提供了直接线程的接口。使用库的方法是:添加头文件时,加上#include <pthread.h>。
线程创建函数pthread_create
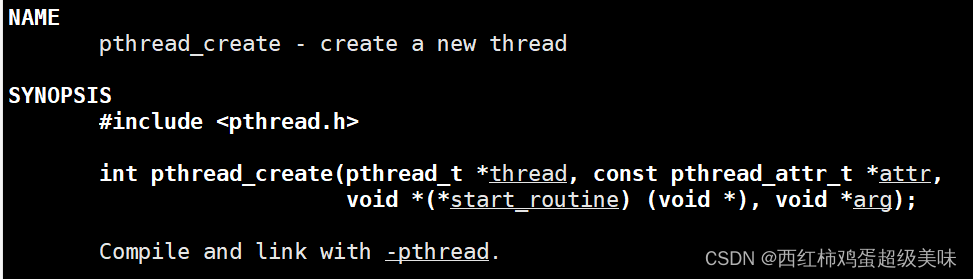 使用此函数,可以创建一个新线程,参数从头到尾依次代表:新线程ID、线程属性(暂时不管,一般都设为nullptr)、线程函数地址(新线程执行的地方)、新线程回调函数的参数。
使用此函数,可以创建一个新线程,参数从头到尾依次代表:新线程ID、线程属性(暂时不管,一般都设为nullptr)、线程函数地址(新线程执行的地方)、新线程回调函数的参数。
下面让我们来试着创建一个线程,执行如下代码:
#include <iostream>
#include <pthread.h>
#include <sys/types.h>
#include <unistd.h>
using namespace std;
//new thread
void *threadRoutine(void *args)
{
while(true)
{
cout << "new phread: " << getpid() << endl;
sleep(2);
}
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadRoutine, nullptr); //不是系统调用
while(true)
{
cout << "man thread: " << getpid() << endl;
sleep(2);
}
return 0;
}由于pthread线程库是个动态库(此动态库是电脑自带的),光是在程序开头引用头文件是不行的,在使用makefile文件编译时,我们还需要加上-pthread选项:
成功执行代码: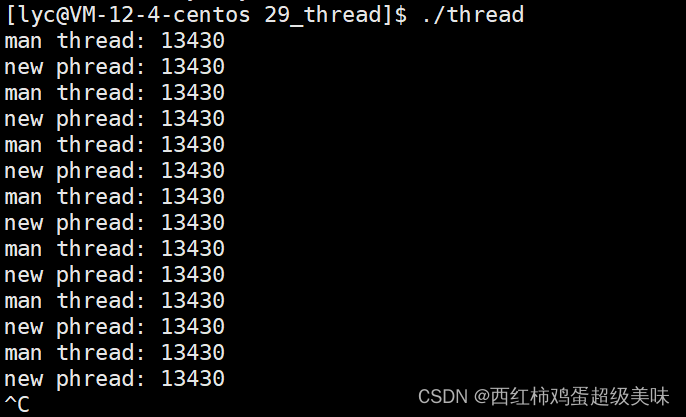 我们可以看到,主线程与新线程都有在运行,说明我们创建新线程成功。
我们可以看到,主线程与新线程都有在运行,说明我们创建新线程成功。
但我们会发现一个问题,在执行结果中,为什么主线程与新线程的pid都是一样的?(都是13430)这是怎么回事?当然是一样的!因为线程本就是进程中的一个执行流,要知道,线程是操作系统调度的基本单位,进程是操作系统分配资源的基本单位,有线程<=执行流<=进程,可以说线程就是进程的一部分。那我们应该怎样去识别某个线程呢?别着急,运行程序后,再使用ps -aL指令看看: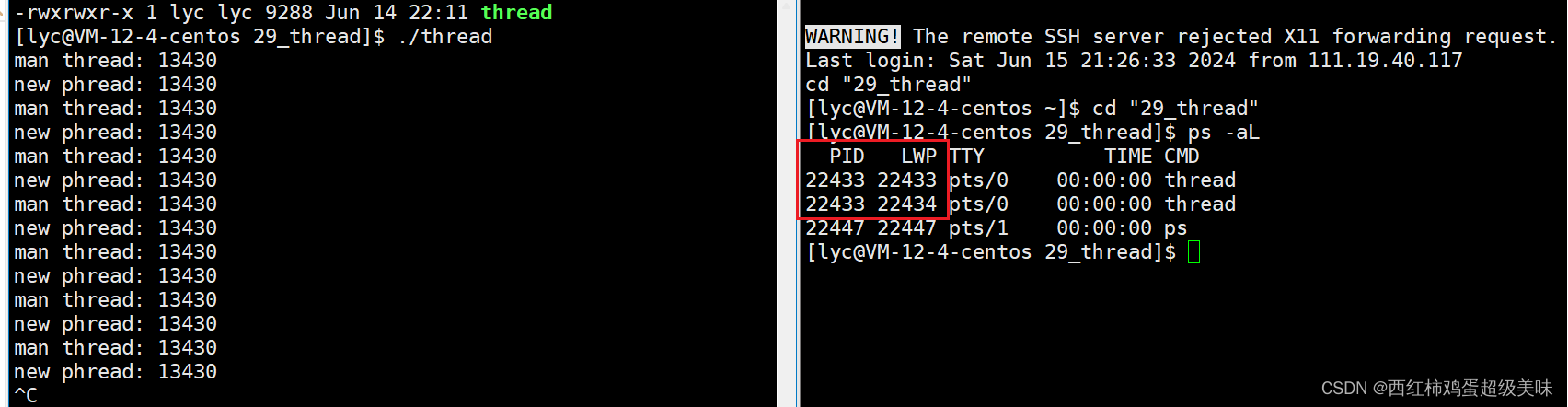
注意看图中红框部分的线程属性,除了PID相同外,我们发现LWP列的数是不一样的,是的,就是你想的那样,LWP全称light weight process也就是轻量级进程的意思 ,LWP就是线程的ID(OS中对线程的标识符),当PID与LWP相等时,它就是主线程,不相等时就是用户所创建的新线程。
下面,我们再讨论一个问题,之前说过,进程独立的,进程间互不影响,我们删除一个进程,不会影响到另一个进程,那线程也是这样吗?我们不妨试一下,执行刚刚的代码,再创建一个窗口分别对主线程与新线程发送9号信号(杀死线程),我们看看会发生什么:
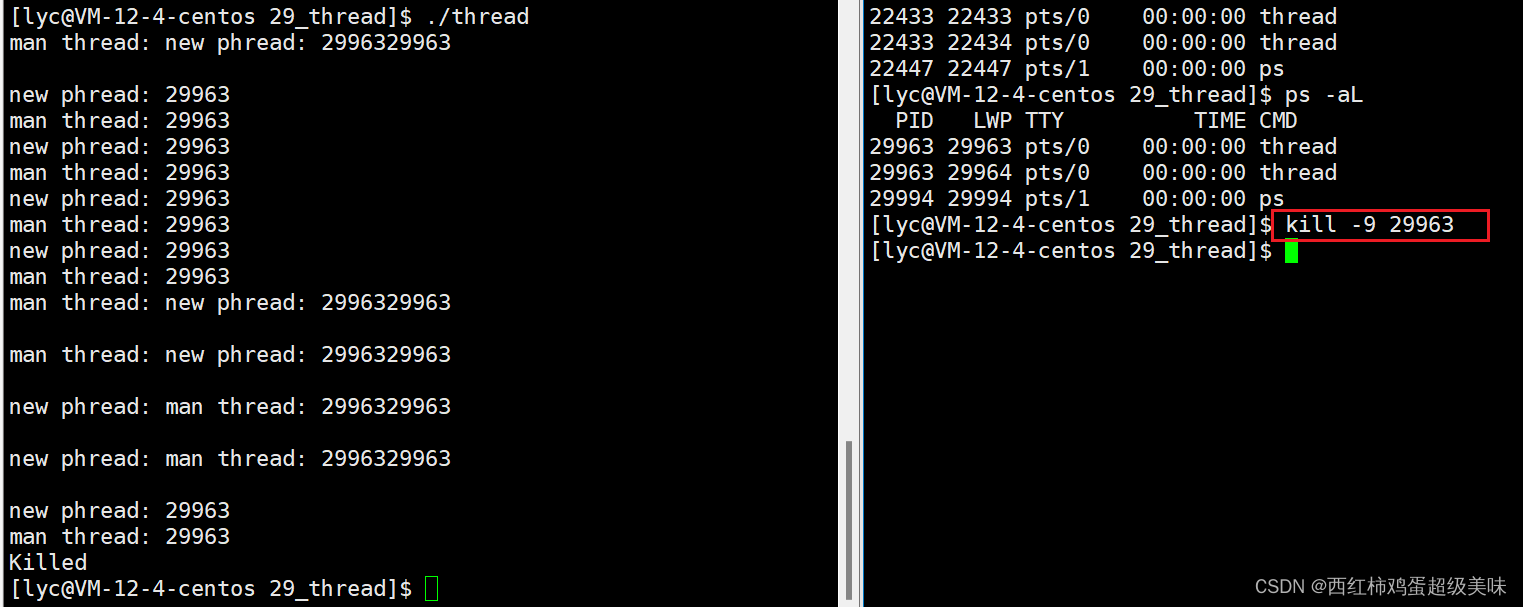
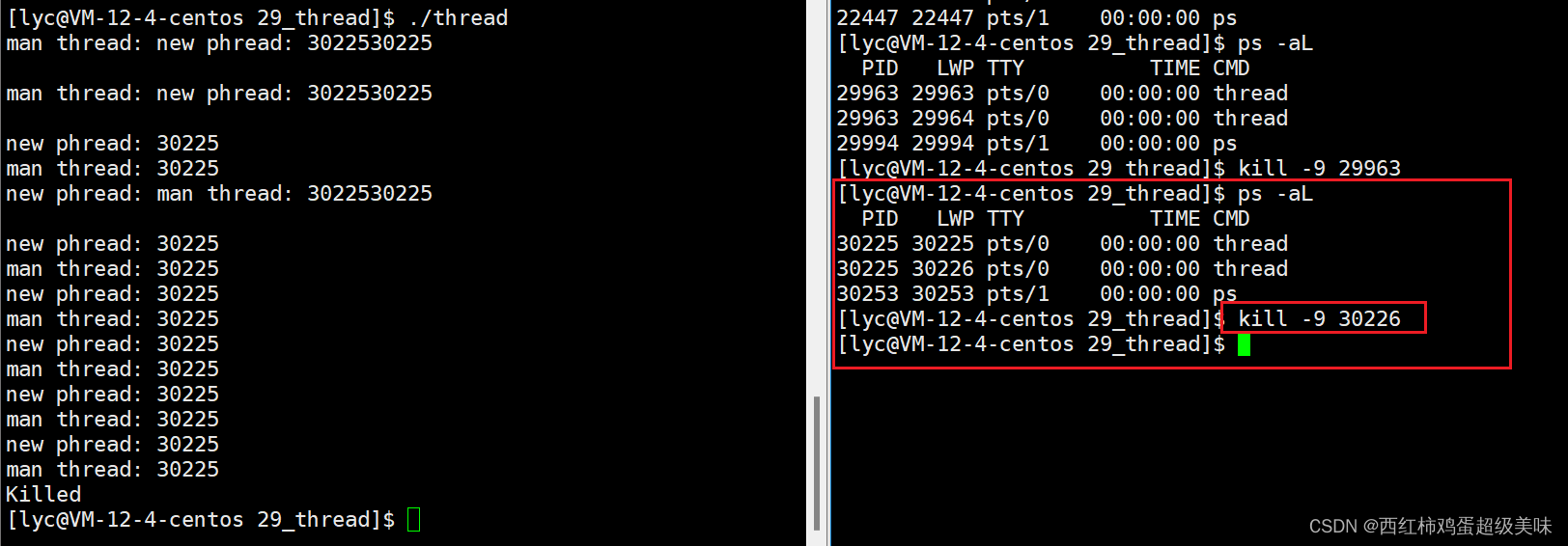
我们发现,无论我们是杀死主线程,还是新线程,我们的进程都会被杀死,即进程中的任何一个线程被干掉,进程都会被干掉,这也说明了线程的健壮性很差。
线程等待
创建子进程时,父进程会等待子进程,进而进行诸多操作,线程也不例外,主线程也需要等待其他线程。
线程等待函数pthread_join
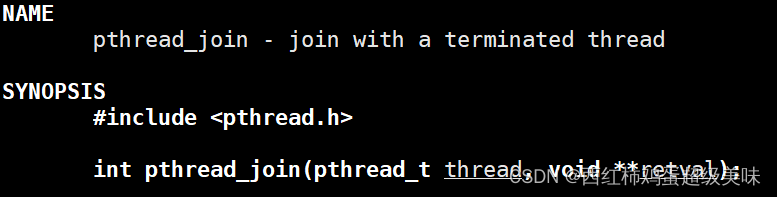 两个参数分别是等待进程的ID、等待进程的返回值。
两个参数分别是等待进程的ID、等待进程的返回值。
线程退出函数
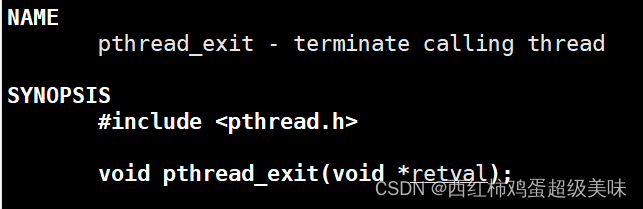
参数为线程的退出码(也就是线程回调函数的返回值)
使用上述两个函数,可以实现主线程等待其他线程的功能。
小贴士:除了pthread_exit退出函数以外,还有以下函数也可以实现线程的退出:
- 从线程函数return。这种方法对主线程不适用,从main函数return相当于调用exit。
- 线程可以调用pthread_ exit终止自己。
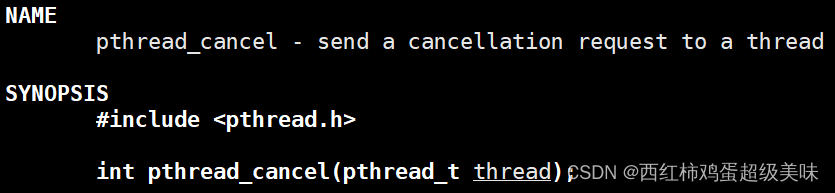
- 一个线程可以调用pthread_ cancel终止同一进程中的另一个线程(如下图,参数为需要终止的线程ID)。
分离线程
- 默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资 源,从而造成系统泄漏。
- 如果不关心线程的返回值,join是一种负担,这个时候,我们可以告诉系统,当线程退出时,自动释放线程资源。
线程分离函数
可以是线程组内其他线程对目标线程进行分离,也可以是线程自己分离,joinable和分离是冲突的,一个线程不能既是joinable又是分离的。
线程ID及进程地址空间布局
前面我们说过,OS是没有线程的概念的,那么,线程到底是由谁来维护的呢?答案是线程库(pthread.h)!前面所讲的pthread_create函数第一个参数是存放线程ID的指针,其实,这里存放线程ID和前面所讲的线程ID(LWP)不是一回事。LWP表示的线程ID是属于进程调度的范畴,因为线程是轻量级进程,是OS调度器的最小单位,所以需要一个数值来唯一表示该线程。
pthread_create函数第一个参数指向一个虚拟内存单元,该内存单元的首地址即为新创建线程的线程ID,属于线程库的范畴。也就是说,线程是由线程库维护的(只维护线程的概念,不维护执行流!)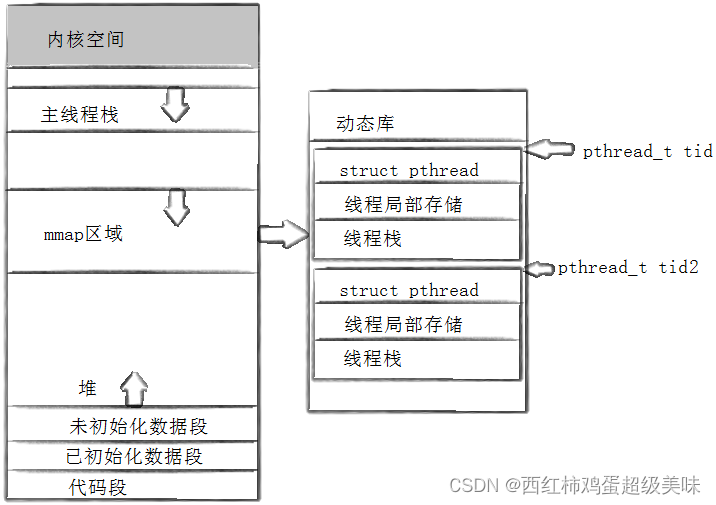
如上图,我们知道线程库是动态库,那么它在内存中的位置是堆与栈之间的共享区域。pthread库将线程的所有属性进行描述并组织,打包为一个模块,也就是线程的tcb,再用链表的方式将每个线程tcb连接起来,最后对线程的管理,不还是对链表的增、删、查、改等操作,这也再次验证了管理数据的6字真言:先描述,再组织!
在线程tcb中,有LWP属性,由于线程库是应用层面的,线程库使用LWP属性去联系内核,作为线程在OS中的唯一标识符,让OS去识别本线程属于进程执行流中的哪一段,从而实现调度。

通过线程实现一个简单的和计算
首先,我们定义两个类,分别是和Request与Repose,Request里包含了和运算的参数、线程名与和运算函数: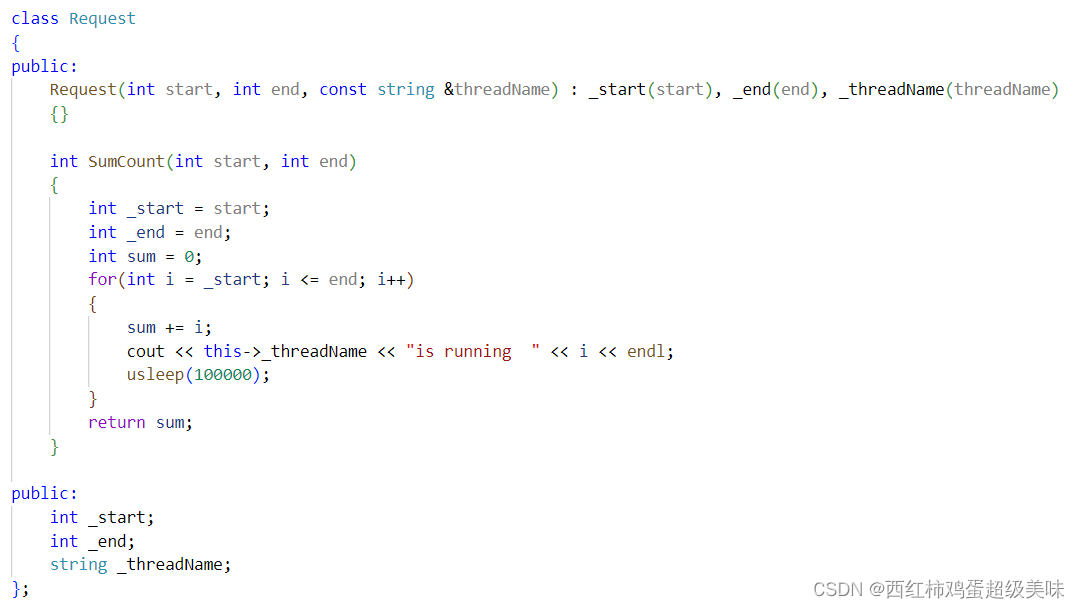 Repose则是包含了计算结果:
Repose则是包含了计算结果:

接着,我们编写主函数与线程回调函数:
void *Sum(void *args)
{
Reponse *rp = new Reponse(0);
Request *rqt = static_cast<Request*>(args);
rp->_res = rqt->SumCount(rqt->_start, rqt->_end);
delete rqt;
return rp;
}
int main()
{
pthread_t tid;
Request *rqt = new Request(1, 100, "thread_1");
pthread_create(&tid, nullptr, Sum, rqt);
void *rtn;
pthread_join(tid, &rtn);
Reponse *rep = static_cast<Reponse *>(rtn);
cout <<"Sum Value is: " << rep->_res << endl;
delete rep;
return 0;
}代码编写完成后,编译并执行程序,执行结果: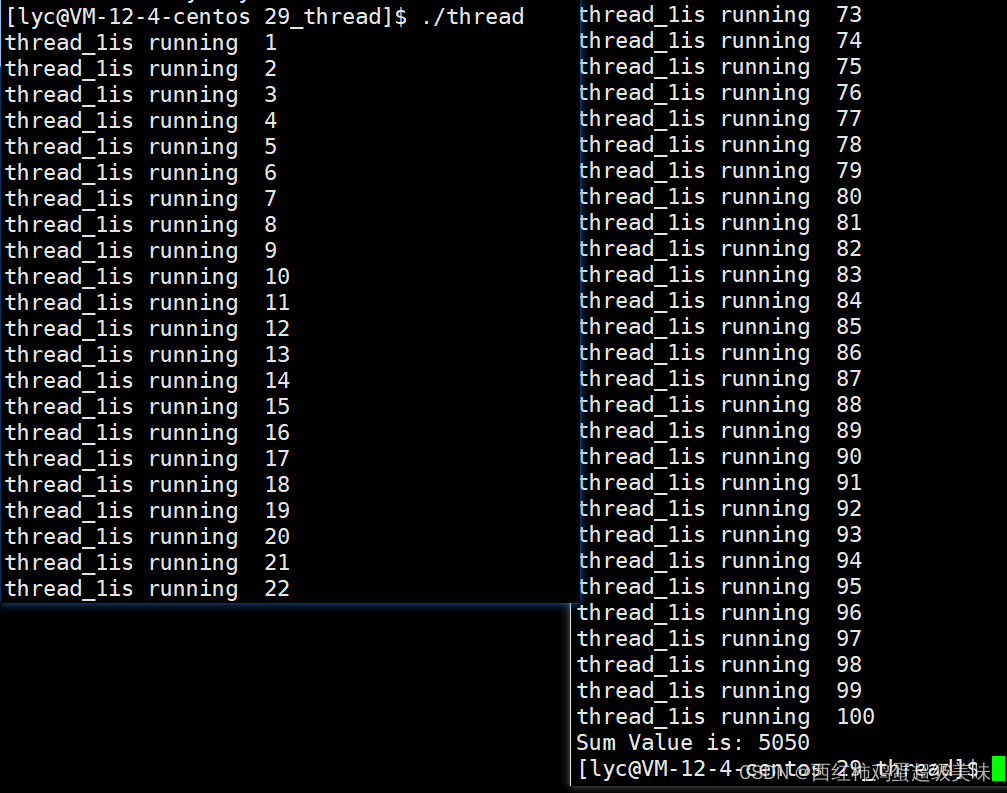
我们可以看到窗口依次把需要求和的数打印了出来,当完成对最后一个数求和后,退出线程回调函数,并返回计算结果给主线程,主线程再将其接收并输出。
每个线程都有自己独立的栈结构
我们可以用一段代码来验证这个话题,在主线程中创建多个线程,让创建的每个线程执行同一个回调函数,再在回调函数里定义局部变量,并打印其值与地址:
struct threadData
{
string threadname;
};
string toHex(pthread_t tid)
{
char buffer[128];
snprintf(buffer, sizeof(buffer), "0x%x", tid);
return buffer;
}
string thread_Name(string threadname, int i)
{
string name = "threadname" + to_string(i);
return name;
}
void *threadRoutine(void *arge)
{
int test_i = 0;
threadData *td = static_cast<threadData*>(arge);
int i = 0;
while(i < 3)
{
cout << "pid: " << getpid() << ", tid: "
<< toHex(pthread_self()) << ", threadname: " << td->threadname
<< ", test_i " << test_i << ", &test_i: " << toHex((pthread_t)&test_i) << endl;
i++;
test_i++;
}
delete td;
return nullptr;
}
int main()
{
vector<pthread_t> tids;
for(int i = 0; i < NUM; i++)
{
threadData *td = new threadData;
td->threadname = thread_Name("thread ", i);
pthread_t tid;
pthread_create(&tid, nullptr, threadRoutine, td);
tids.push_back(tid);
sleep(1);
}
for(int i = 0; i < NUM; i++)
{
void *rtn;
pthread_join(tids[i], &rtn);
}
return 0;
}运行结果;
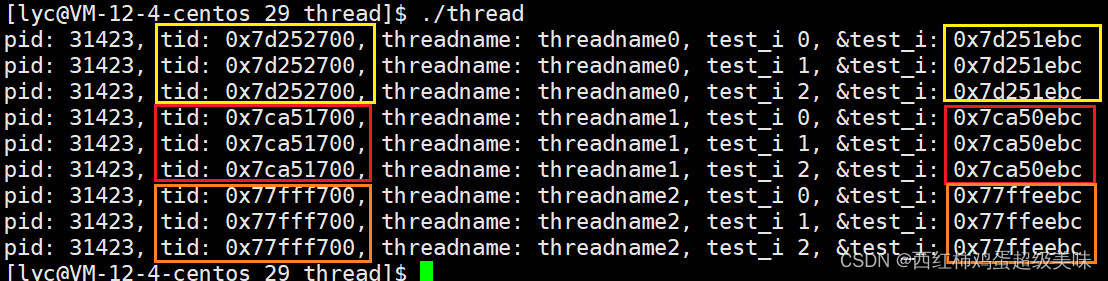
注意看用三种不同颜色框住的地方,很容易看出,这是三个不同地址 ,所以,也成功验证了每个线程都有其独立的栈结构。但其实,我们线程与线程之间是没有秘密的,如果你想去访问到某个进程的局部变量,也是可以实现的,具体方法这里就不说了。
那我们试着定义一个全局变量,再去看看其值与地址会有什么不同?在程序里定义一个全局变量g_val,再在线程回调函数中去打印其值与地质:
void *threadRoutine(void *arge)
{
int test_i = 0;
threadData *td = static_cast<threadData*>(arge);
int i = 0;
while(i < 3)
{
cout << "pid: " << getpid() << ", tid: "
<< toHex(pthread_self()) << ", threadname: " << td->threadname
<< ", g_val " << g_val << ", &g_val: " << toHex((pthread_t)&g_val) << endl;
i++;
test_i++;
}
delete td;
return nullptr;
}结果如下:
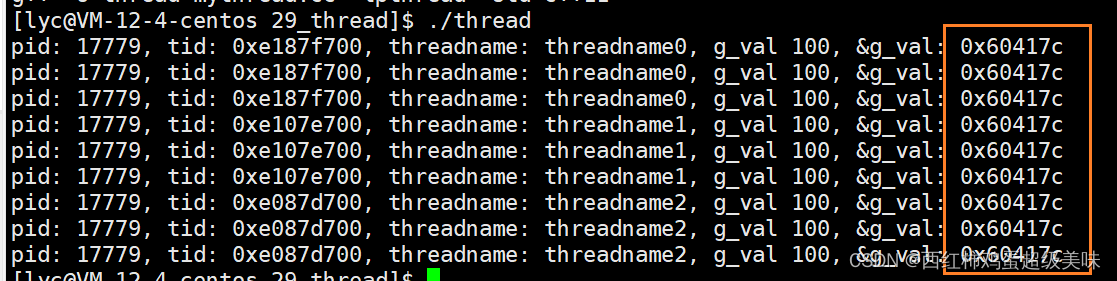
可以看出,全局变量在内存的区域是所有线程所共享的,其实,除了这个区域外,堆区等范围也是所有进程所共享的。
其实,线程库还为线程设计了私有全局变量,定义方式如下,在变量前加上__thread(只能对内置类型有用) :
![]()
这样做以后,我们不改变代码其他部分,再次运行代码:
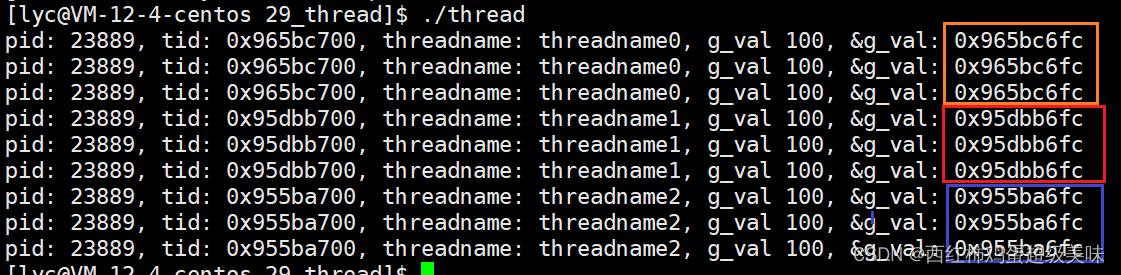
这样,又为每个线程创建了私有全局变量,至于私有全局变量的作用与用途,就留给各位小伙伴们去思考了。
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











