






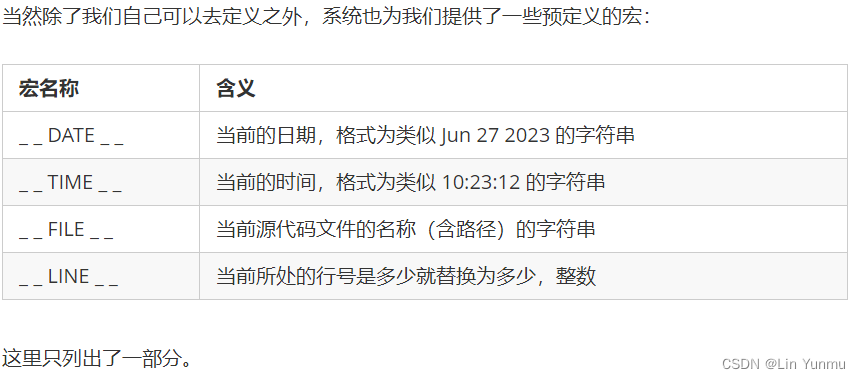
函数
声明与定义
#include <stdio.h>
void test(void); //定义函数原型,因为C语言是从上往下的,所以如果要在下面的主函数中使用这个函数,一定要定义到它的上面。
int main() {
}
void test(void){ //函数具体定义,添加一个花括号并在其中编写程序代码,就和我们之前在main中编写一样
printf("我是测试函数!");
}
//或者按照下面声明定义
#include <stdio.h>
void test(void){ //函数具体定义,添加一个花括号并在其中编写程序代码,就和我们之前在main中编写一样
printf("我是测试函数!");
}
int main() {
}解析printf函数
int printf(const char * __restrict, ...) __printflike(1, 2); //看起来比较高级
这里我们主要关心它的两个参数,一个是char *由于还没有学习指针,这里就把它当做const char[]就行了,表示一个不可修改的字符串,而第二个参数我们看到是...,这三个点是个啥?
我们知道,如果我们想要填写具体需要打印的值时,可以一直往后写:
printf("%d, %d", 1, 2); //参数可以一直写
正常情况下我们函数的参数列表都是固定的,怎么才能像这样写很多个呢?这就要用到可变长参数了,不过可变长参数的使用比较麻烦,这里我们就不做讲解了。
函数参数
如果我们修改形式参数的值,外面的实参值会跟着发生修改吗?
#include <stdio.h>
void swap(int, int);
int main() {
int a = 10, b = 20;
swap(a, b);printf("a = %d, b = %d", a, b); //最后会得到什么结果?
}void swap(int a, int b){
int tmp = a; //这里对a和b的值进行交换
a = b;
b = tmp;
}

通过结果发现,虽然调用了函数对a和b的值进行交换,但貌似并没有什么卵用。这是为什么呢?
还记得我们前面说的吗,函数的形参实际上就是函数内的局部变量,它的作用域仅仅是这个函数,而我们外面传入的实参,仅仅知识将值赋值给了函数内的形参而已,并且外部的变量跟函数内部的变量作用域都不同,所以半毛钱关系都没有,这里交换的仅仅是函数内部的两个形参变量值,跟外部作实参的变量没有任何关系。
那么,怎么样才能实现通过函数交换两个变量的值呢?这个问题我们会在指针部分进行讨论。
不过数组却不受限制,我们在函数中修改数组的值,是直接可以生效的:
#include <stdio.h>
void test(int arr[]);
int main() {
int arr[] = {4, 3, 8, 2, 1, 7, 5, 6, 9, 0};
test(arr);
printf("%d", arr[0]); //打印的是修改后的值了
}
void test(int arr[]) {
arr[0] = 999; //数组就可以做到这边修改,外面生效
}我们再来看一个例子:
#include <stdio.h>
void test(int a){
a += 10;
printf("%d\n", a);
}
int main() {
int a = 10;
test(a);
test(a); //连续两次调用,那么这两次的结果会是什么?
}可以看到结果都是20,(如果猜对了可以直接跳过,如果你猜测的是20和30的话,需要听我解释了)注意每次调用函数都是单独进行的,并不是复用函数中的形参,不要认为第一次调用函数test就将函数的局部变量变成20了,再次调用就是20+10变成30。实际上这两次调用都是单独进行的,形参a都是在一开始的时候被赋值为实参的值的,这两次调用没有任何关系,并且函数执行完毕后就自动销毁了。
那要是我就希望每次调用函数时保留变量的值呢?我们可以使用静态变量:
#include <stdio.h>
void test();
int main() {
test();
test();
}
void test() {
static int a = 20; //静态变量并不会在函数结束时销毁其值,而是保持
a += 20;
printf("%d ", a);
}递归调用
我们的函数除了在其他地方被调用之外,也可以自己调用自己(好家伙,套娃是吧),这种玩法我们称为递归。
#include <stdio.h>
void test(){
printf("Hello World!\n");
test(); //函数自己在调用自己,这样的话下一轮又会进入到这个函数中
}
int main() {
test();
}我们可以尝试运行一下上面的程序,会发现程序直接无限打印Hello World!这个字符串,这是因为函数自己在调用自己,不断地重复进入到这个函数,理论情况下,它将永远都不会结束,而是无限地执行这个函数的内容。

但是到最后我们的程序还是终止了,这是因为函数调用有最大的深度限制,因为计算机不可能放任函数无限地进行下去。
函数调用栈原理
我们来大致了解一下函数的调用过程,实际上在程序运行时会有一个叫做函数调用栈的东西,它用于控制函数的调用:
#include <stdio.h> //我们以下面的调用关系为例
void test2(){
printf("giao");
}
void test(){
test2(); //main -> test -> test2
printf("giao");
}
int main() {
test();
printf("giao");
}其实我们可以很轻易地看出整个调用关系,首先是从main函数进入,然后调用test函数,在test函数中又调用了test2函数,此时我们就需要等待test2函数执行完毕,test才能继续,而main则需要等待test执行完毕才能继续。而实际上这个过程是由函数调用栈在控制的:
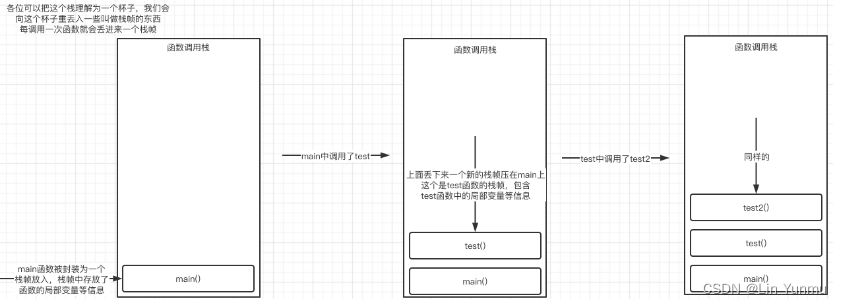
而当test2函数执行完毕后,每个栈帧又依次从栈中出去:
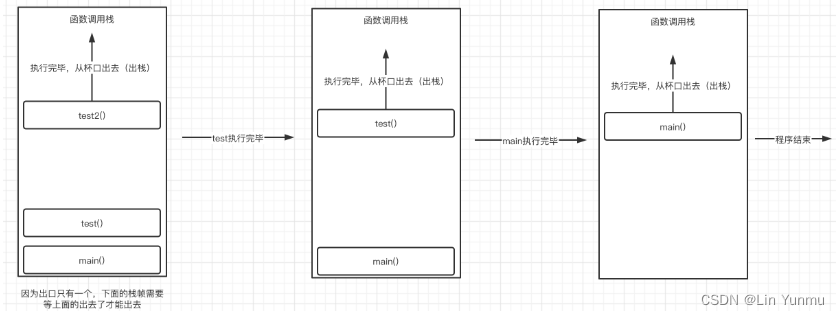
当所有的栈全部出去之后,程序结束。
所以这也就不难解释为什么无限递归会导致程序出现错误,因为栈的空间有限,而函数又一直在进行自我调用,所以会导致不断地有新的栈帧进入,最后塞满整个栈的空间,就爆炸了,这种问题我们称为栈溢出(Stack Overflow)
当然,如果我们好好地按照规范使用递归操作,是非常方便的,比如我们现在需要求某个数的阶乘:
#include <stdio.h>
int test(int n);
int main() {
printf("%d", test(3));
}
int test(int n){
if(n == 1) return 1; //因为不能无限制递归下去,所以我们这里添加一个结束条件,在n = 1时返回
return test(n - 1) * n; //每次都让n乘以其下一级的计算结果,下一级就是n-1了
}通过给递归调用适当地添加结束条件,这样就不会无限循环了,并且我们的程序看起来无比简洁,那么它是如何执行的呢:

它看起来就像是一个先走到底部,然后拿到问题的钥匙后逐步返回的一个过程,并在返回的途中不断进行计算最后得到结果(妙啊)
所以,合理地使用递归反而是一件很有意思的事情。
指针
指针可以说是整个C语言中最难以理解的部分了,不过其实说简单也简单,你会发现也并没有想象中的那么难,你与它的距离可能只差了那么一些基础知识,这一部分都会及时进行补充的。
什么是指针
还记得我们在上一个部分谈到的通过函数交换两个变量的值吗?
#include <stdio.h>
void swap(int, int);
int main() {
int a = 10, b = 20;
swap(a, b);
printf("a = %d, b = %d", a, b); //最后会得到什么结果?
}
void swap(int a, int b){
int tmp = a; //这里对a和b的值进行交换
a = b;
b = tmp;
}实际上这种写法是错误的,因为交换的并非是真正的a和b,而是函数中的局部变量。那么有没有办法能够直接对函数外部的变量进行操作呢?这就需要指针的帮助了。
我们知道,程序中使用的变量实际上都在内存中创建的,每个变量都会被保存在内存的某一个位置上(具体在哪个位置是由系统分配的),就像我们最终会在这个世界上的某个角落安家一样,所有的变量在对应的内存位置上都有一个地址(地址是独一无二的),而我们可以通过这个地址寻找到这个变量本体,比如int占据4字节,因此int类型变量的地址就是这4个字节的起始地址,后面32个bit位全部都是用于存放此变量的值的。

这里的0x是十六进制的表示形式(10-15用字母A - F表示)如果我们能够知道变量的内存地址,那么无论身在何处,都可以通过地址找到这个变量了。而指针的作用,就是专门用来保存这个内存地址的。
我们来看看如何创建一个指针变量用于保存变量的内存地址:
#include <stdio.h>
int main(){
int a = 10;
//指针类型需要与变量的类型相同,且后面需要添加一个*符号(注意这里不是乘法运算)表示是对于类型的指针
int * p = &a; //这里的&并不是进行按位与运算,而是取地址操作,也就是拿到变量a的地址
printf("a在内存中的地址为:%p", p); //地址使用%p表示
}
可以看到,我们通过取地址操作&,将变量a的地址保存到了一个地址变量p中。
拿到指针之后,我们可以很轻松地获取指针所指地址上的值:
#include <stdio.h>
int main(){
int a = 666;
int * p = &a;
printf("内存%p上存储的值为:%d", p, *p); //我们可以在指针变量前添加一个*号(间接运算符,也可以叫做解引用运算符)来获取对应地址存储的值
}注意这里访问指针所指向地址的值时,是根据类型来获取的,比如int类型占据4个字节,那么就读取地址后面4个字节的内容作为一个int值,如果指针是char类型的,那么就只读取地址后面1个字节作为char类型的值。

同样的,我们也可以直接像这样去修改对应地址存放的值:
#include <stdio.h>
int main(){
int a = 666;
int * p = &a;
*p = 999; //通过*来访问对应地址的值,并通过赋值运算对其进行修改
printf("a的值为:%d", a);
}
实际上拿到一个变量的地址之后,我们完全不需要再使用这个变量,而是可以通过它的指针来对其进行各种修改。因此,现在我们想要实现对两个变量的值进行交换的函数就很简单了:
#include <stdio.h>
// 这里是两个指针类型的形参,其值为实参传入的地址,
// 虽然依然是值传递,但是这里传递的可是地址啊,
// 只要知道地址改变量还不是轻轻松松?
void swap(int * a, int * b){
int tmp = *a; //先暂存一下变量a地址上的值
*a = *b; //将变量b地址上的值赋值给变量a对应的位置
*b = tmp; //最后将a的值赋值给b对应位置,OK,这样就成功交换两个变量的值了
}
int main(){
int a = 10, b = 20;
swap(&a, &b); //只需要把a和b的内存地址给过去就行了,这里取一下地址
printf("a = %d, b = %d", a, b);
}
通过地址操作,我们就轻松实现了使用函数交换两个变量的值了。
了解了指针的相关操作之后,我们再来看看scanf函数,实际上就很好理解了:
#include <stdio.h>
int main(){
int a;
scanf("%d", &a); //这里就是取地址,我们需要告诉scanf函数变量的地址,这样它才能通过指针访问变量的内存地址,对我们变量的值进行修改,这也是为什么scanf里面的变量(除数组外)前面都要进行一个取地址操作
printf("%d", a);
}当然,和变量一样,要是咱们不给指针变量赋初始值的话,就不知道指的哪里了,因为指针变量也是变量,存放的其他变量的地址值也在内存中保存,如果不给初始值,那么存放别人地址的这块内存可能在其他地方使用过,这样就不知道初始值是多少了(那么指向的地址可能是一个很危险的地址,随意使用可能导致会出现严重错误),所以一定要记得给个初始值或是将其设定为NULL,表示空指针,不指向任何内容。
#include <stdio.h>
int main(){
int * a = NULL;
}我们接着来看看const类型的指针,这种指针比较特殊:
#include <stdio.h>
int main(){
int a = 9, b = 10;
const int * p = &a;
*p = 20; //这里直接报错,因为被const标记的指针,所指地址上的值不允许发生修改
p = &b; //但是指针指向的地址是可以发生改变的
}我们再来看另一种情况:
#include <stdio.h>
int main(){
int a = 9, b = 10;
int * const p = &a; //const关键字被放在了类型后面
*p = 20; //允许修改所指地址上的值
p = &b; //但是不允许修改指针存储的地址值,其实就是反过来了。
}当然也可以双管齐下:
#include <stdio.h>
int main(){
int a = 9, b = 10;
const int * const p = &a;
*p = 20; //两个都直接报错,都不让改了
p = &b;
}指针与数组
前面我们介绍了指针的基本使用,我们来回顾一个问题,为什么数组可以以原身在函数之间进行传递呢?先说结论,数组表示法实际上是在变相地使用指针,你甚至可以将其理解为数组变量其实就是一个指针变量,它存放的就是数组中第一个元素的起始地址。
为什么这么说?
#include <stdio.h>
int main(){
char str[] = "Hello World!";
char * p = str; //???啥情况,为什么能直接把数组作为地址赋值给指针变量p???
printf("%c", *p); //还能正常使用,打印出第一个字符???
}
你以为这就完了?还能这样玩呢:
int main(){
char str[] = "Hello World!";
char * p = str;
printf("%c", p[1]); //???怎么像在使用数组一样用指针???
}
太迷了吧,怎么数组和指针还能这样混着用呢?我们先来看看数组在内存中是如何存放的:

数组在内存中是一块连续的空间,所以为什么声明数组一定要明确类型和大小,因为这一块连续的内存空间生成后就固定了。
而我们的数组变量实际上存放的就是首元素的地址,而实际上我们之前一直使用的都是数组表示法来操作数组,这样可以很方便地让我们对内存中的各个元素值进行操作:
int main(){
char str[] = "Hello World!";
printf("%c", str[0]); //直接在中括号中输入对应的下标就能访问对应位置上的数组了
}而我们知道实际上str表示的就是数组的首地址,所以我们完全可以将其赋值给一个指针变量,因为指针变量也是存放的地址:
char str[] = "Hello World!";
char * p = str; //直接把str代表的首元素地址给到p而使用指针后,实际上我们可以使用另一种表示法来操作数组,这种表示法叫做指针表示法:
int main(){
char str[] = "Hello World!";
char * p = str;
printf("第一个元素值为:%c,第二个元素值为:%c", *p, *(p+1)); //通过指针也可以表示对应位置上的值
}比如我们现在需要表示数组中的第二个元素:
-
数组表示法:
str[1] -
指针表示法:
*(p+1)
虽然写法不同,但是他们表示的意义是完全相同的,都代表了数组中的第二个元素,其中指针表示法使用了p+1的形式表示第二个元素,这里的+1操作并不是让地址+1,而是让地址+ 一倍的对应类型大小,也就是说地址后移一个char的长度,所以正好指向了第二个元素,然后通过*取到对应的值(注意这种操作仅对数组是有意义的,如果是普通的变量,虽然也可以通过这种方式获得后一个char的长度的数据,但是毫无意义)
*(p+i) <=> str[i] //实际上就是可以相互转换的
这两种表示法都可以对内存中存放的数组内容进行操作,只是写法不同罢了,所以你会看到数组和指针混用也就不奇怪了。了解了这些东西之后,我们来看看下面的各个表达式分别代表什么:
*p //数组的第一个元素
p //数组的第一个元素的地址
p == str //肯定是真,因为都是数组首元素地址
*str //因为str就是首元素的地址,所以这里对地址加*就代表第一个元素,使用的是指针表示法
&str[0] //这里得到的实际上还是首元素的地址
*(p + 1) //代表第二个元素
p + 1 //第二个元素的内存地址
*p + 1 //注意*的优先级比+要高,所以这里代表的是首元素的值+1,得到字符'K'
所以不难理解,为什么printf函数的参数是一个const char *了,实际上就是需要我们传入一个字符串而已,只不过这里采用的是指针表示法而已。
当然指针也可以进行自增和自减操作,比如:
#include <stdio.h>
int main(){
char str[] = "Hello World!";
char * p = str;
p++; //自增后相当于指针指向了第二个元素的地址
printf("%c", *p); //所以这里打印的就是第二个元素的值了
}一维数组看完了,我们来看看二维数组,那么二维数组在内存中是如何表示的呢?
int arr[2][3] = {{1, 2, 3}, {4, 5, 6}};
这是一个2x3的二维数组,其中存放了两个能够容纳三个元素的数组,在内存中,是这样的

所以虽然我们可以使用二维数组的语法来访问这些元素,但其实我们也可以使用指针来进行访问:
#include <stdio.h>
int main(){
int arr[][3] = {{1, 2, 3}, {4, 5, 6}};
int * p = arr[0]; //因为是二维数组,注意这里要指向第一个元素,来降一个维度才能正确给到指针
//同理如果这里是arr[1]的话那么就表示指向二维数组中第二个数组的首元素
printf("%d = %d", *(p + 4), arr[1][1]); //实际上这两种访问形式都是一样的
}多级指针
我们知道,实际上指针本身也是一个变量,它存放的是目标的地址,但是它本身作为一个变量,它也要将地址信息保存到内存中,所以,实际上当我们有指针之后:

实际上,我们我们还可以继续创建一个指向指针变量地址的指针,甚至可以创建更多级(比如指向指针的指针的指针)比如现在我们要创建一个指向指针的指针:

落实到咱们的代码中:
#include <stdio.h>
int main(){
int a = 20;
int * p = &a; //指向普通变量的指针
//因为现在要指向一个int *类型的变量,所以类型为int* 再加一个*
int ** pp = &p; //指向指针的指针(二级指针)
int *** ppp = &pp; //指向指针的指针的指针(三级指针)
}那么我们如何访问对应地址上的值呢?
#include <stdio.h>
int main(){
int a = 20;
int * p = &a;
int ** pp = &p;
printf("p = %p, a = %d", *pp, **pp); //使用一次*表示二级指针指向的指针变量,继续使用一次*会继续解析成指针变量所指的普通变量
}本质其实就是一个套娃而已,只要把各个层次分清楚,实际上还是很好理解的。
特别提醒:一级指针可以操作一维数组,那么二级指针是否可以操作二维数组呢?不能!因为二级指针的含义都不一样了,它是表示指针的指针,而不是表示某个元素的指针了。下面我们会认识数组指针,准确的说它才更贴近于二维数组的形式。
指针数组和数组指针
前面我们了解了指针的一些基本操作,包括它与数组的一些关系。我们接着来看指针数组和数组指针,这两词语看着就容易搞混,不过哪个词在后面就哪个,我们先来看指针数组,虽然名字很像数组指针,但是它本质上是一个数组,不过这个数组是用于存放指针的数组。
#include <stdio.h>
int main(){
int a, b, c;
int * arr[3] = {&a, &b, &c}; //可以看到,实际上本质还是数组,只不过存的都是地址
}因为这个数组中全都是指针,比如现在我们想要访问数组中第一个指针指向的地址:
#include <stdio.h>
int main(){
int a, b, c;
int * arr[3] = {&a, &b, &c};
*arr[0] = 999; //[]运算符的优先级更高,所以这里先通过[0]取出地址,然后再使用*将值赋值到对应的地址上
printf("%d", a);
}当然我们也可以用二级指针变量来得到指针数组的首元素地址:
#include <stdio.h>
int main(){
int * p[3]; //因为数组内全是指针
int ** pp = p; //所以可以直接使用指向指针的指针来指向数组中的第一个指针元素
}实际上指针数组还是很好理解的,那么数组指针呢?可以看到指针在后,说明本质是一个指针,不过这个指针比较特殊,它是一个指向数组的指针(注意它的目标是整个数组,和我们之前认识的指针不同,之前认识的指针是指向某种类型变量的指针)
比如:
int * p; //指向int类型的指针
而数组指针则表示指向整个数组:
int (*p)[3]; //注意这里需要将*p括起来,因为[]的优先级更高
注意它的目标是整个数组,而不是普通的指针那样指向的是数组的首个元素:
int arr[3] = {111, 222, 333};
int (*p)[3] = &arr; //直接对整个数组再取一次地址(因为数组指针代表的是整个数组的地址,虽然和普通指针都是指向首元素地址,但是意义不同)
那么现在已经取到了指向整个数组的指针,该怎么去使用呢?
#include <stdio.h>
int main(){
int arr[3] = {111, 222, 333};
int (*p)[3] = &arr; //直接对整个数组再取一次地址
printf("%d, %d, %d", *(*p+0), *(*p+1), *(*p+2)); //要获取数组中的每个元素,稍微有点麻烦
}注意此时:
-
p代表整个数组的地址 -
*p表示所指向数组中首元素的地址 -
*p+i表示所指向数组中第i个(0开始)元素的地址(实际上这里的*p就是指向首元素的指针) -
*(*p + i)就是取对应地址上的值了
虽然在处理一维数组上感觉有点麻烦,但是它同样也可以处理二维数组:
int arr[][3] = {{111, 222, 333}, {444, 555, 666}};
int (*p)[3] = arr; //二维数组不需要再取地址了,因为现在维度提升,数组指针指向的是二维数组中的其中一个元素(因为元素本身就是一个数组)比如现在我们想要访问第一个数组的第二个元素,根据上面p各种情况下的意义:
printf("%d", *(*p+1)); //因为上面直接指向的就是第一个数组,所以想要获取第一个元素和之前是一模一样的
那么要是我们现在想要获取第二个数组中的最后一个元素呢?
printf("%d", *(*(p+1)+2); //首先*(p+1)为一个整体,表示第二个数组(因为是数组指针,所以这里+1一次性跳一个数组的长度),然后再到外层+2表示数组中的第三个元素,最后再取地址,就是第二个数组的第三个元素了
当然也可以使用数组表示法:
printf("%d", p[1][2]); //好家伙,这不就是二维数组的用法吗,没错,看似很难,你甚至可以认为这两用着是同一个东西
指针函数与函数指针
我们的函数可以返回一个指针类型的结果,这种函数我们就称为指针函数
#include <stdio.h>
int * test(int * a){ //函数的返回值类型是int *指针类型的
return a;
}
int main(){
int a = 10;
int * p = test(&a); //使用指针去接受函数的返回值
printf("%d", *p);
printf("%d", *test(&a)); //当然也可以直接把间接运算符在函数调用前面表示直接对返回的地址取地址上的值
}不过要注意指针函数不要尝试去返回一个局部变量的地址:
#include <stdio.h>
int * test(int a){
int i = a;
return &i; //返回局部变量i的地址
}
int main(){
int * p = test(20); //连续调用两次test函数
test(30);
printf("%d", *p); //最后结果可能并不是我们想的那样
}
为什么会这样呢?还记得我们前面说的吗?函数一旦返回,那么其中的局部变量就会全部销毁了,至于这段内存之后又会被怎么去使用,我们也就不得而知了。
局部变量其实是存放在栈帧中的,如果前面的选学部分听了之后,你就知道为什么这里得到的是第二次的30了,因为第二次调用的栈帧入栈后就覆盖了这段内存,又因为是同一个函数所以栈帧结构是一样的,最后在同样的位置就存放了新的30这个值。
我们接着来看函数指针,实际上指针除了指向一个变量之外,也可以指向一个函数,当然函数指针本身还是一个指针,所以依然是用变量表示,但是它代表的是一个函数的地址(编译时系统会为函数代码分配一段存储空间,这段存储空间的首地址称为这个函数的地址)
我们来看看如何定义:
#include <stdio.h>
int sum(int a, int b) {
return a + b;
}
int main(){
//类型 (*指针变量名称)(函数参数...) //注意一定要把*和指针变量名称括起来,不然优先级不够
int (*p)(int, int) = sum;
printf("%p", p);
}这样我们就拿到了函数的地址,既然拿到函数的地址,那么我们就可以通过函数的指针调用这个函数了:
#include <stdio.h>
int sum(int a, int b) {
return a + b;
}
int main(){
int (*p)(int, int) = sum;
int result = (*p)(1, 2); //就像我们正常使用函数那样,(*p)表示这个函数,后面依然是在小括号里面填上实参
int result = p(1, 2); //当然也可以直接写函数指针变量名称,效果一样(咋感觉就是给函数换了个名呢)
printf("%d", result);
}有了函数指针,我们就可以编写函数回调了(所谓回调就让别人去调用我们提供的函数,而不是我们主动来调别人的函数),比如现在我们定义了一个函数,不过这个函数需要参数通过一个处理的逻辑才能正常运行:
int sum(int (*p)(int, int), int a, int b){ //将函数指针作为参数传入
//函数回调
return p(a, b); //就像你进了公司然后花钱请别人帮你写代码,工资咱们五五开,属于是直接让别人帮你实现
}于是我们就还要给他一个其他函数的地址:
#include <stdio.h>
int sum(int (*p)(int, int), int a, int b){
return p(a, b);
}
int sumImpl(int a, int b){ //这个函数实现了a + b
return a + b;
}
int main(){
int (*p)(int, int) = sumImpl; //拿到实现那个函数的地址
printf("%d", sum(p, 10, 20));
}当然,函数指针也可以保存一组函数的地址,成为函数指针数组,但是这里就不多说了,相信各位已经快顶不住了吧。
结构体、联合体和枚举
我们之前认识过很多种数据类型,包括整数、小数、字符、数组等,通过使用对应的数据类型,我们就可以很轻松地将我们的数据进行保存了,但是有些时候,这种简单类型很难去表示一些复杂结构。
创建和使用结构体
比如现在我们要保存100个学生的信息(学生信息包括学号、姓名、年龄)我们发现似乎找不到一种数据类型能够同时保存这三种数据(数组虽然能保存一些列的元素,但是只能保存同种类型的)。但是如果把它们拆开单独存在,就可以使用对应的类型存放了,不过这样也太不方便了吧,这些数据应该是捆绑在一起的,而不是单独地去存放。所以,为了解决这种问题,C语言提供了结构体类型,它能够将多种类型的数据集结到一起,让他们形成一个整体。
struct Student { //使用 (struct关键字 + 结构体类型名称) 来声明结构体类型,这种类型是我们自己创建的(同样也可以作为函数的参数、返回值之类的)
int id; //结构体中可以包含多个不同类型的数据,这些数据共同组成了整个结构体类型(当然结构体内部也能包含结构体类型的变量)
int age;
char * name; //用户名可以用指针指向一个字符串,也可以用char数组来存,如果是指针的话,那么数据不会存在结构体中,只会存放字符串的地址,但是如果是数组的话,数据会存放在结构体中
};int main() {
struct Student { //也可以以局部形式存在
};
}定义好结构体后,我们只需要使用结构体名称作为类型就可以创建一个结构体变量了:
#include <stdio.h>
struct Student {
int id;
int age;
char * name;
};
int main() {
//类型需要写为struct Student,后面就是变量名称
struct Student s = {1, 18, "小明"}; //结构体包含多种类型的数据(它们是一个整体),只需要把这些数据依次写好放在花括号里面就行了
}这样我们就创建好了一个结构体变量,而这个结构体表示的就是学号为1、年龄18、名称为小明的结构体数据了。
当然,结构体的初始化需要注意:
struct Student s = {1, 18}; //如果只写一半,那么只会初始化其中一部分数据,剩余的内容相当于没有初始值,跟数组是一样的
struct Student s = {1, .name = "小红"}; //也可以指定去初始化哪一个属性 .变量名称 = 初始值那么现在我们拿到结构体变量之后,怎么去访问结构体内部存储的各种数据呢?
printf("id = %d, age = %d, name = %s", s.id, s.age, s.name); //结构体变量.数据名称 (这里.也是一种运算符) 就可以访问结构体中存放的对应的数据了
是不是很简单?当然我们也可以通过同样的方式对结构体中的数据进行修改:
int main() {
struct Student s = {1, 18, "小明"};
s.name = "小红";
s.age = 17;
printf("id = %d, age = %d, name = %s", s.id, s.age, s.name);
}那么结构体在内存中占据的大小是如何计算的呢?比如下面的这个结构体
struct Object {
int a;
short b;
char c;
};
这里我们可以借助sizeof关键字来帮助我们计算:
int main() {
printf("int类型的大小是:%lu", sizeof(int)); //sizeof能够计算数据在内存中所占据的空间大小(字节为单位)
}

当然也可以计算变量的值占据的大小:
int main() {
int arr[10];
printf("int arr[10]占据的大小是:%lu", sizeof (arr)); //在判断非类型时,sizeof 括号可省
}

同样的,它也能计算我们的结构体类型会占用多少的空间:
#include <stdio.h>
struct Object {
char a;
int b;
short c;
};int main() {
printf("%lu", sizeof(struct Object)); //直接填入struct Object作为类型
}

可以看到结果是8
struct Object {
char a; //char占据1个字节
int b; //int占据4个字节,因为前面存了一个char,按理说应该从第2个字节开始存放,但是根据规则一,必须在自己的整数倍位置上存放,所以2不是4的整数倍位置,这时离1最近的下一个整数倍地址就是4了,所以前面空3个字节的位置出来,然后再放置
short c; //前面存完int之后,就是从8开始了,刚好满足short(2字节)的整数倍,但是根据规则二,整个结构体大小必须是最大对齐大小的整数倍(这里最大对齐大小是int,所以是4),存完short之后,只有10个字节,所以屁股后面再补两个空字节,这样就可以了
};,那么,这个8字节是咋算出来的呢?
int(4字节)+ short(2字节)+ char(1字节) = 7字节(这咋看都算不出来12啊?)
实际上结构体的大小是遵循下面的规则来进行计算的:
-
结构体中的各个数据要求字节对齐,规则如下:
-
规则一:结构体中元素按照定义顺序依次置于内存中,但并不是紧密排列的。从结构体首地址开始依次将元素放入内存时,元素会被放置在其自身对齐大小的整数倍地址上(0默认是所有大小的整数倍)
-
规则二:如果结构体大小不是所有元素中最大对齐大小的整数倍,则结构体对齐到最大元素对齐大小的整数倍,填充空间放置到结构体末尾。
-
规则三:基本数据类型的对齐大小为其自身的大小,结构体数据类型的对齐大小为其元素中最大对齐大小元素的对齐大小。
-
这里我们以下面的为例:
struct Object {
char a; //char占据1个字节
int b; //int占据4个字节,因为前面存了一个char,按理说应该从第2个字节开始存放,但是根据规则一,必须在自己的整数倍位置上存放,所以2不是4的整数倍位置,这时离1最近的下一个整数倍地址就是4了,所以前面空3个字节的位置出来,然后再放置
short c; //前面存完int之后,就是从8开始了,刚好满足short(2字节)的整数倍,但是根据规则二,整个结构体大小必须是最大对齐大小的整数倍(这里最大对齐大小是int,所以是4),存完short之后,只有10个字节,所以屁股后面再补两个空字节,这样就可以了
};

这样,就不难得出为什么结构体的大小是12了。
结构体数组和指针
前面我们介绍了结构体,现在我们可以将各种类型的数据全部安排到结构体中一起存放了。
不过仅仅只是使用结构体,还不够,我们可能需要保存很多个学生的信息,所以我们需要使用结构体类型的数组来进行保存:
#include <stdio.h>
struct Student {
int id;
int age;
char * name;
};
int main() {
struct Student arr[3] = {{1, 18, "小明"}, //声明一个结构体类型的数组,其实和基本类型声明数组是一样的
{2, 17, "小红"}, //多个结构体数据用逗号隔开
{3, 18, "小刚"}};
}那么现在如果我们想要访问数组中第二个结构体的名称属性,该怎么做呢?
int main() {
struct Student arr[3] = {{1, 18, "小明"},
{2, 17, "小红"},
{3, 18, "小刚"}};
printf("%s", arr[1].name); //先通过arr[1]拿到第二个结构体,然后再通过同样的方式 .数据名称 就可以拿到对应的值了
}当然,除了数组之外,我们可以创建一个指向结构体的指针。
int main() {
struct Student student = {1, 18, "小明"};
struct Student * p = &student; //同样的,类型后面加上*就是一个结构体类型的指针了
}我们拿到结构体类型的指针后,实际上指向的就是结构体对应的内存地址,和之前一样,我们也可以通过地址去访问结构体中的数据:

不过这样写起来太累了,我们可以使用简便写法:
![]()
我们来看看结构体作为参数在函数之间进行传递时会经历什么:
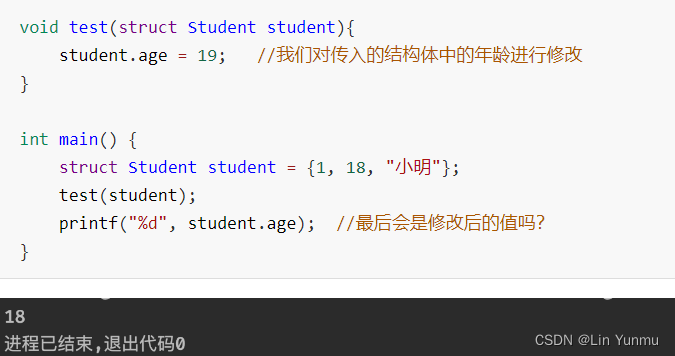
可以看到在其他函数中对结构体内容的修改并没有对外面的结构体生效,因此,实际上结构体也是值传递。我们修改的只是另一个函数中的局部变量而已。
所以如果我们需要再另一个函数中处理外部的结构体,需要传递指针:
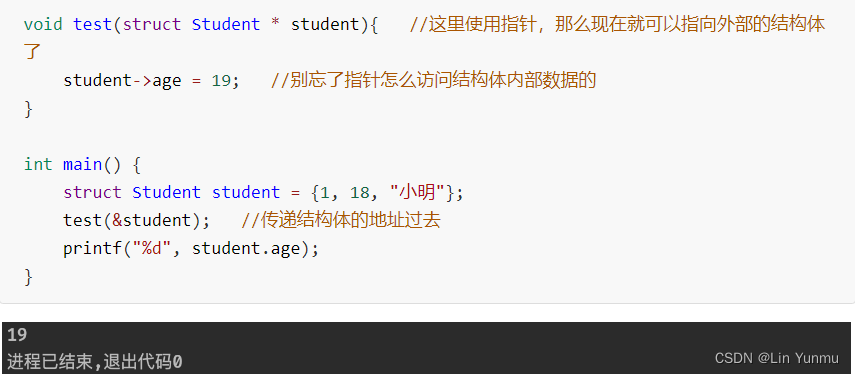
当然一般情况下推荐传递结构体的指针,而不是直接进行值传递,因为如果结构体非常大的话,光是数据拷贝就需要花费很大的精力,并且某些情况下我们可能根本用不到结构体中的所有数据,所以完全没必要浪费空间,使用指针反而是一种更好的方式。
联合体
联合体也可以在内部定义很多种类型的变量,但是它与结构体不同的是,所以的变量共用同一个空间。????啥意思?

我们来看看一个神奇的现象:

????
我修改的是a啊,怎么b也变成66了?这是因为它们共用了内存空间,实际上我们先将a修改为66,那么就将这段内存空间上的值修改为了66,因为内存空间共用,所以当读取b时,也会从这段内存空间中读取一个char长度的数据出来,所以得到的也是66。

因为:128 = 10000000,所以用char读取后,由于第一位是符号位,于是就变成了-128。
那么联合体的大小又是如何决定的呢?

实际上,联合体的大小至少是其内部最大类型的大小,这里是int所以就是4,当然,当最大成员大小不是最大对齐数的整数倍的时候,就要对齐到最大对齐数的整数倍。
当然联合体的其他使用基本与结构体差不多,这里就不提了。
枚举
最后我们来看一下枚举类型,枚举类型一般用于表示一些预设好的整数常量,比如我们风扇有低、中、高三个档位,我们总是希望别人使用我们预设好的这三个档位,而不希望使用其他的档位,因为我们风扇就只设计了这三个档位。
这时我们就可以告诉别人,我们的风扇有哪几个档位,这种情况使用枚举就非常适合。在我们的程序中,只能使用基本数据类型对这三种档位进行区分,这样显然可读性不够,别人怎么知道哪个代表哪个档位呢?而使用枚举就没有这些问题了:

我们可以创建多个自定义名称的枚举,命名规则和变量差不多。我们可以当每一个枚举对应一个整数值,这样的话,我们就不需要去记忆每个数值代表的是什么档位了,我们可以直接根据枚举的名称来进行分辨,是不是很方便?
使用枚举也非常地方便:


当然也可以直接加入到switch语句中:

不过在枚举变量定义时需要注意:

所以这里的low就是0,middle就是1,high就是2了。
如果中途设定呢?
 这时low由于是第一个,所以还是从0开始,不过middle这里已经指定为6了,所以紧跟着的high初始值就是middle的值+1了,因此low现在是0,middle就是6,high就是7了。
这时low由于是第一个,所以还是从0开始,不过middle这里已经指定为6了,所以紧跟着的high初始值就是middle的值+1了,因此low现在是0,middle就是6,high就是7了。
typedef关键字
这里最后还要提一下typedef关键字,这个关键字用于给指定的类型起别名。怎么个玩法呢?

比如这里我们给int起了一个别名,那么现在我们不仅可以使用int来表示一个int整数,而且也可以使用别名作为类型名称了:
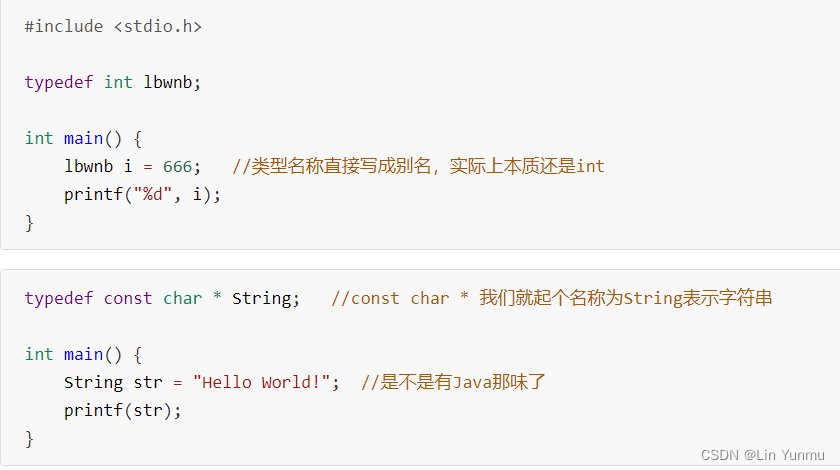
当然除了这种基本类型之外,包括指针、结构体、联合体、枚举等等都可以使用这个关键字来完全起别名操作:

预处理
虽然我们的C语言学习已经快要接近尾声了,但是有一个东西迟迟还没有介绍,就是我们一直在写的:
#include <stdio.h>
这到底是个什么东西,为什么每次都要加上呢?这一部分,我们将详细讨论它缘由。
#include实际上是一种预处理指令,在我们的程序运行之前,会有一个叫做"C预处理器"的东西,根据我们程序中的预处理指令,预处理器能把对应的指令替换为指令想要表示的内容。我们先来看看#include做了什么。
文件包含
当预处理器发现#include指令时,会查看后面的文件名并把文件的内容包含到当前文件中,来替换掉#include指令。比如:

我们说了,这个函数是由系统为我们提供的函数,实际上这个函数实在其他源文件中定义好的,而定义这个函数的源文件,就是stdio.h,我们可以点进去看看:

除了printf之外,我们看到还有很多很多的函数原型定义,他们都写到这个源文件中,而这个文件并不是以.c结尾的,而是以.h结尾的,这种文件我们称为头文件。头文件一般仅包含定义一类的简单信息,只要能让编译器认识就行了。
而#include则是将这些头文件中提供的信息包含到我们的C语言源文件中,这样我们才能使用定义好的printf函数,如果我们不添加这个指令的话,那么会:

直接不认识了,printf是啥,好吃吗?说白了就是,我们如果不告诉编译器我们的这个函数是从哪来的,它怎么知道这个函数的具体定义什么是,程序又该怎么执行呢?
#include的具体使用格式如下:
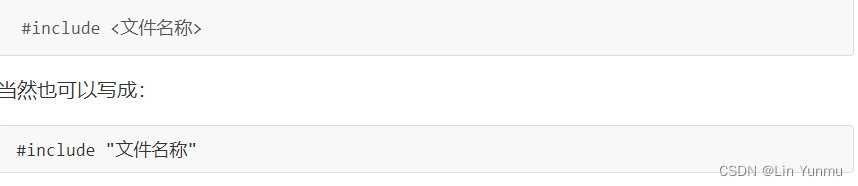
这两种写法虽然都能引入头文件,但是区别还是有的:
-
尖括号:引用的是编译器的库路径里面的头文件。
-
双引号:引用的是程序目录中相对路径中的头文件,如果找不到再去上面的库里面找。
可以看到系统已经为我们提供好了多种多样的头文件了,通过这些系统提供的库,我们就可以做很多的事情了。
当然我们也可以自己编写一个头文件,直接在项目根目录下创建一个新的C/C++头文件:
可以看到系统自动为我们生成好了这些内容,只不过现在还没学到(后面会介绍),现在直接删掉:

我们直接在头文件中随便声明一个函数原型,接着我们就可以引入这个头文件了:

通过导入头文件,我们就可以使用定义好的各种内容了,当然,不仅仅局限于函数。
不过现在还没办法执行,因为我们这里只是引入了头文件中定义的函数原型,具体的函数实现我们一般还是使用.c源代码文件去进行编写,这里我们创建一个同名的C源文件(不强制要求同名,但是这样看着整齐一点)去实现一下:


实际上预处理器正是通过头文件得到编译代码时所需的一些信息,然后才能把我们程序需要的内容(比如这里要用到的test函数)替换到我们的源文件中,最后才能正确编译为可执行程序。
比如现在我们要做一个学生管理库,这个库中提供了学生结构体的定义,以及对学生信息相关操作:

系统库介绍



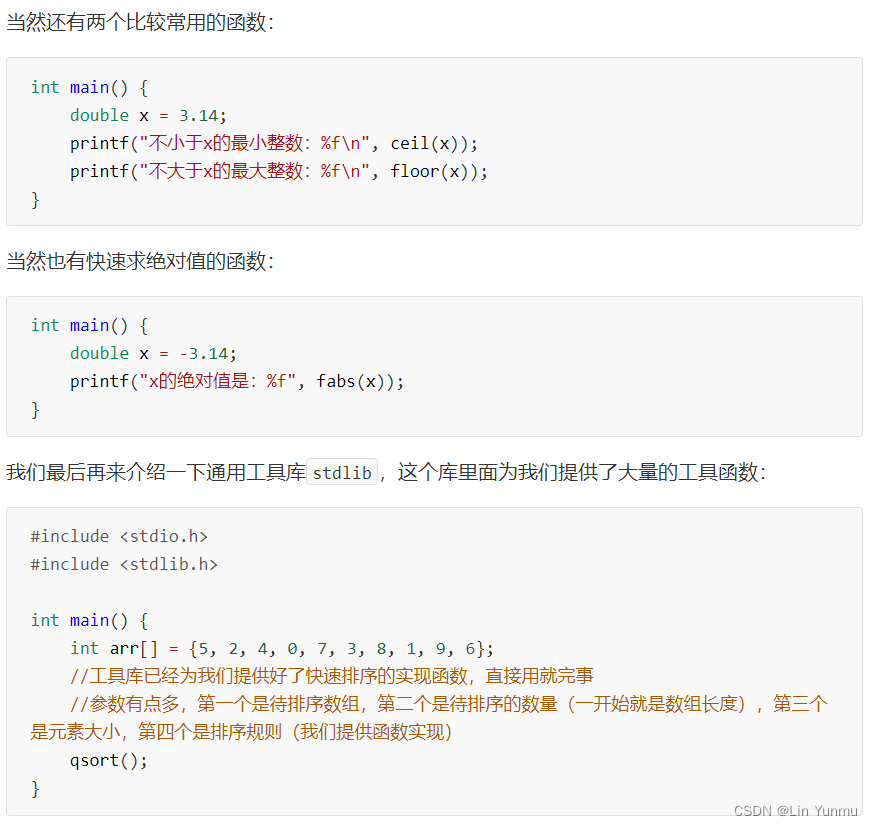

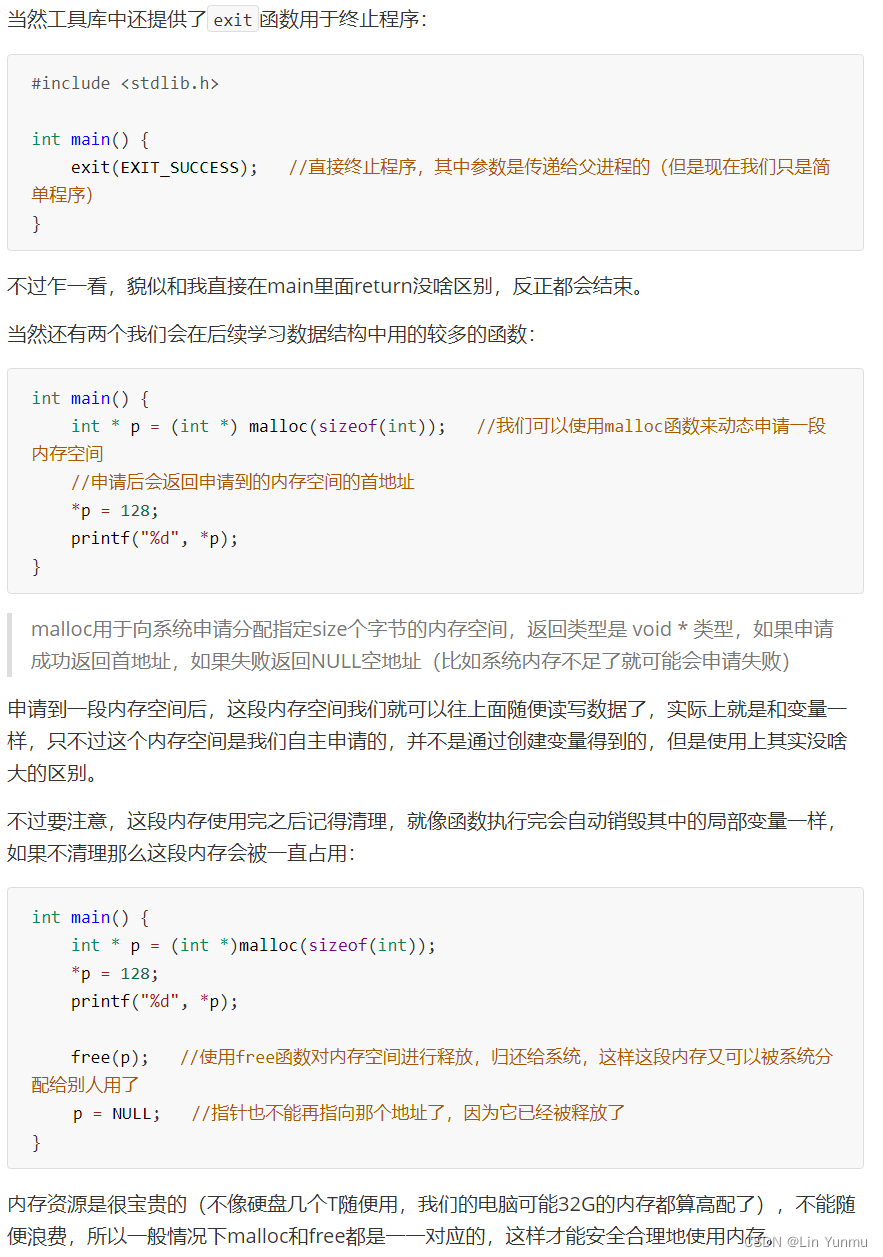
宏定义
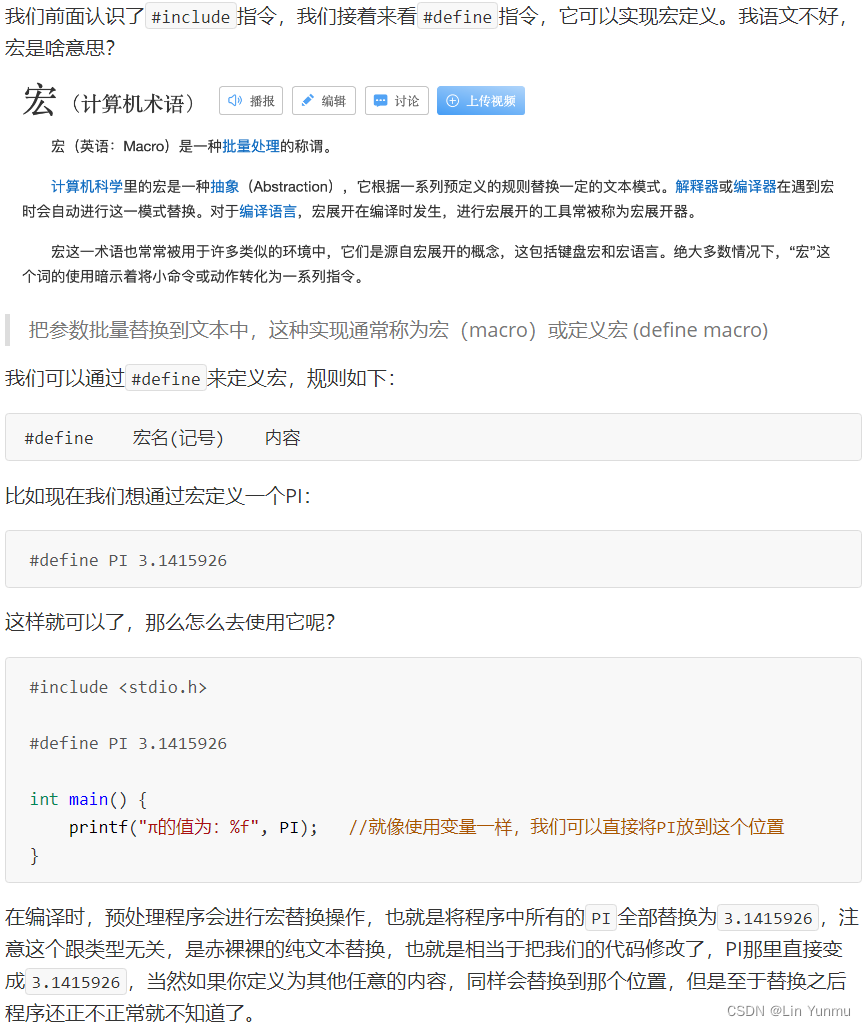

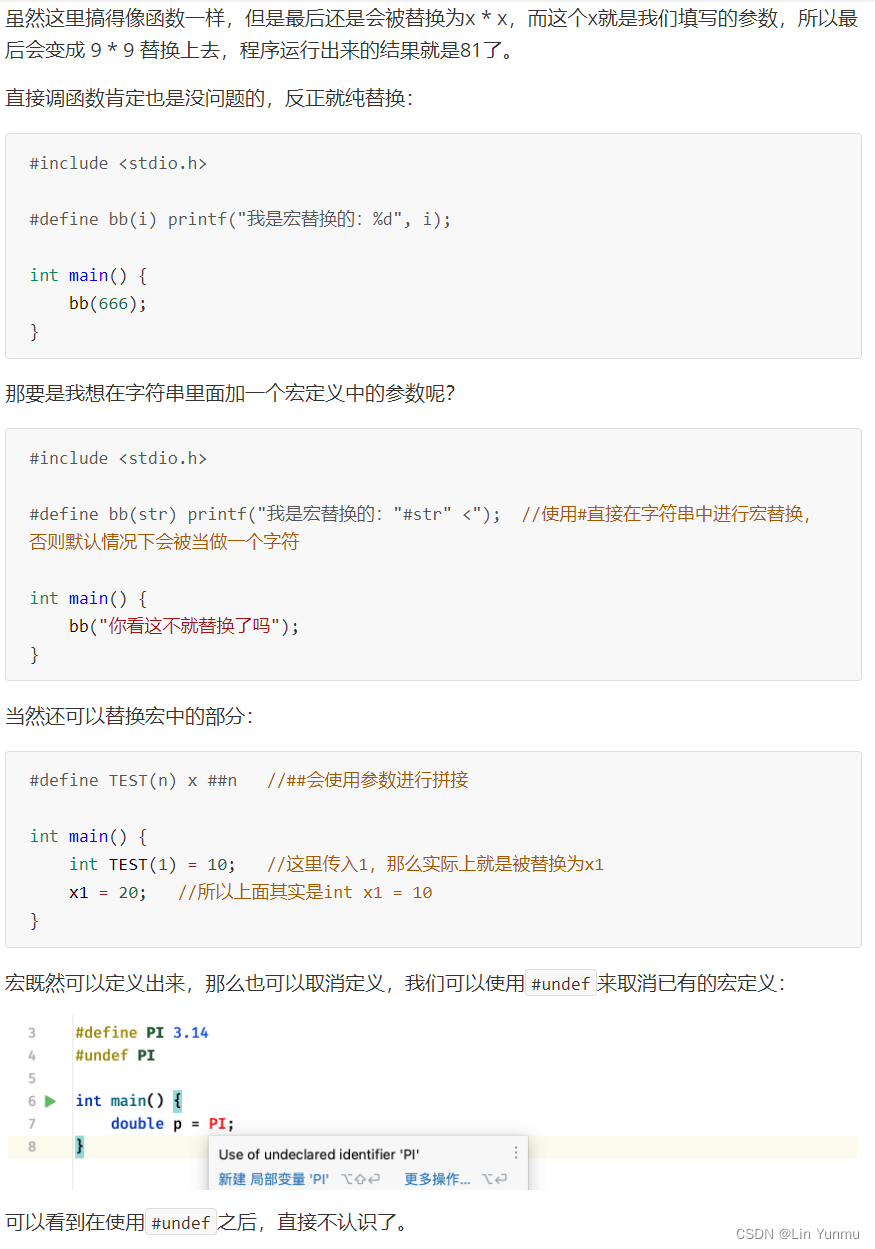
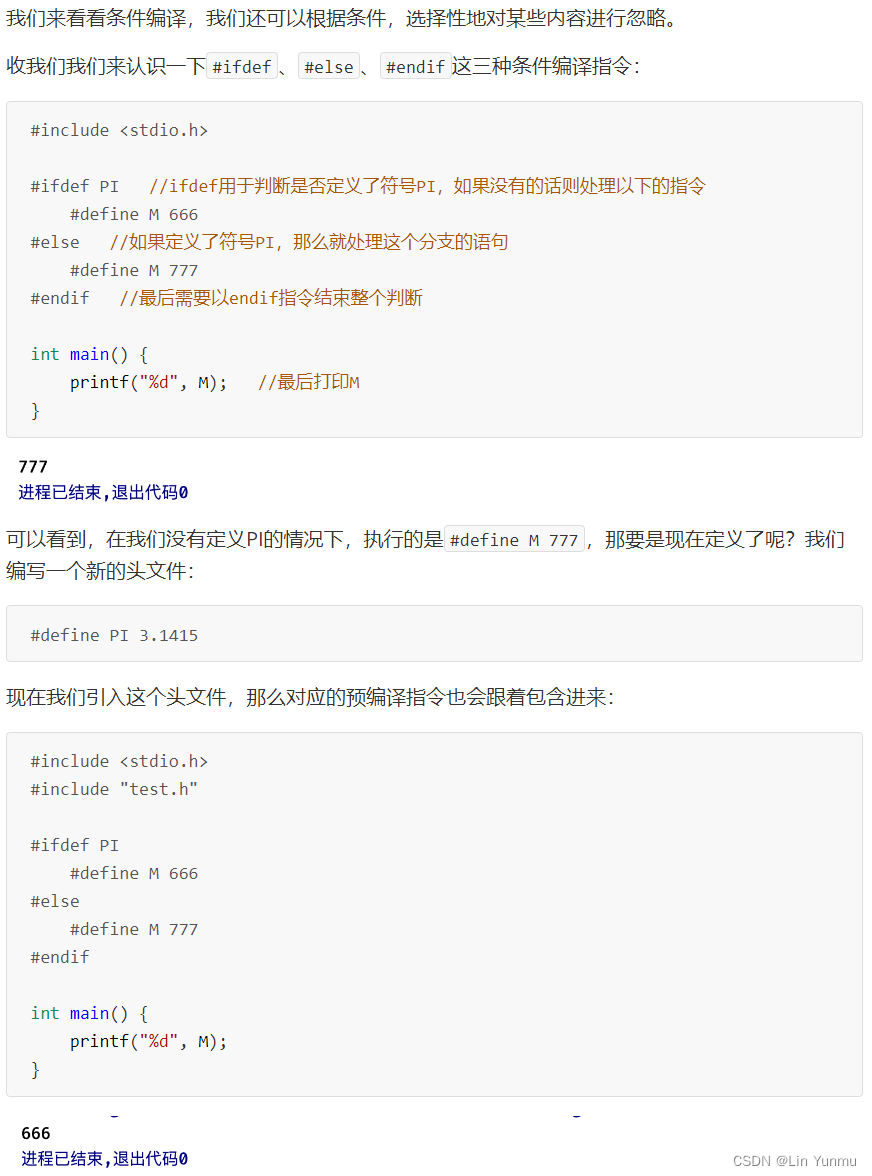
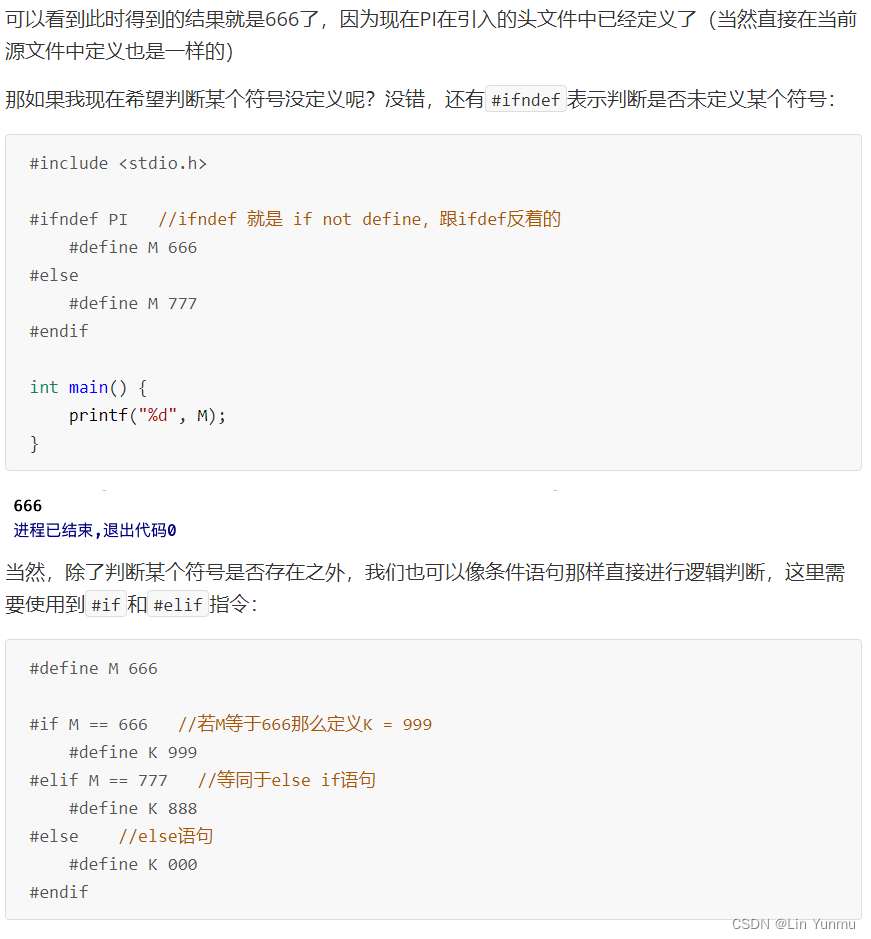
条件编译

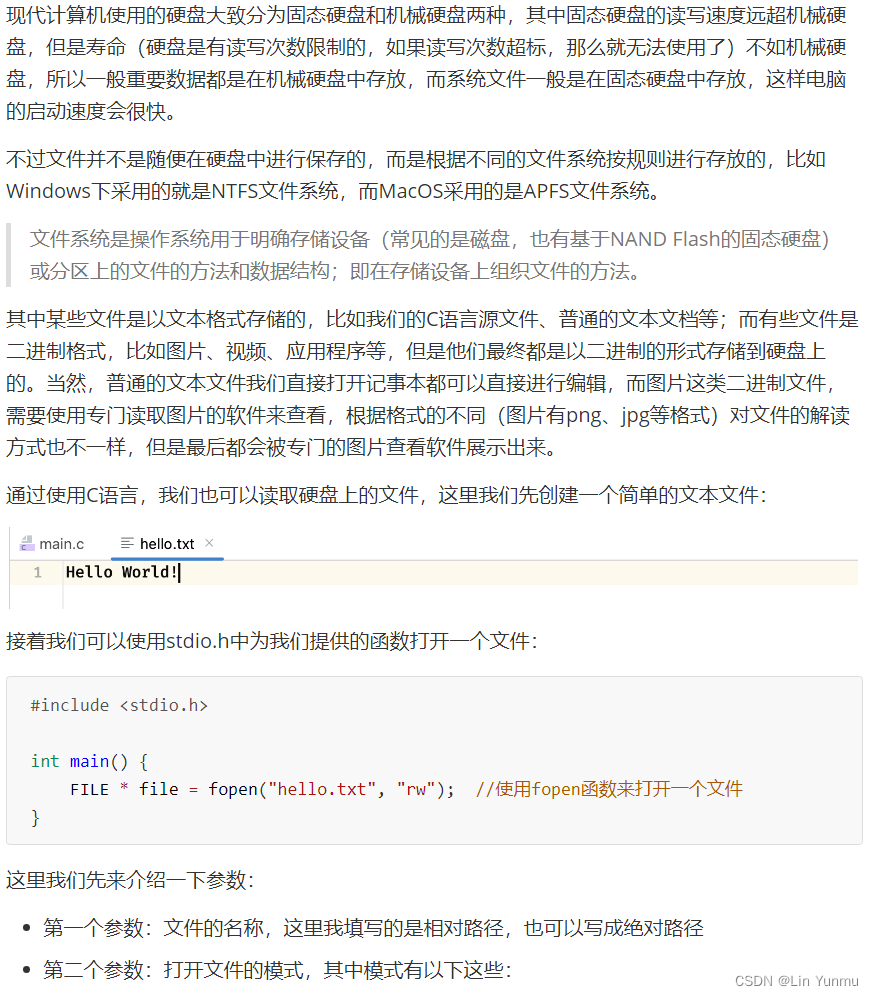
文件输入/输出

文本读写操作
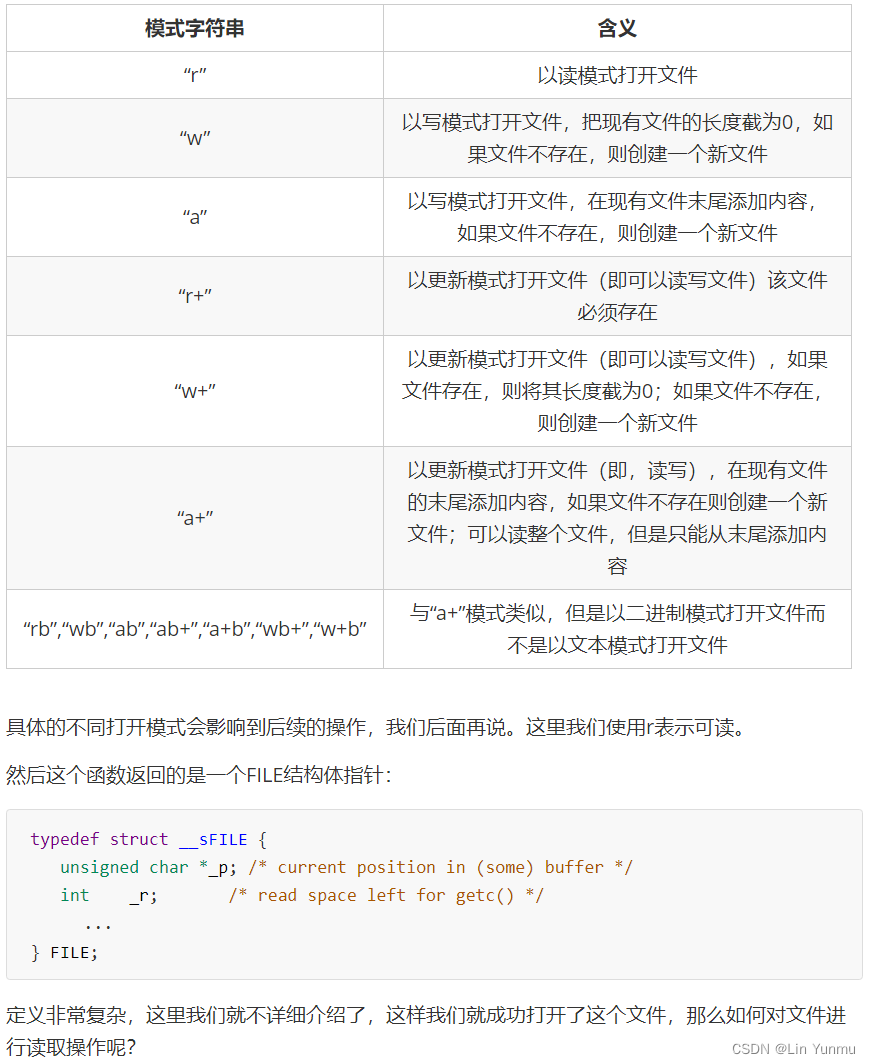

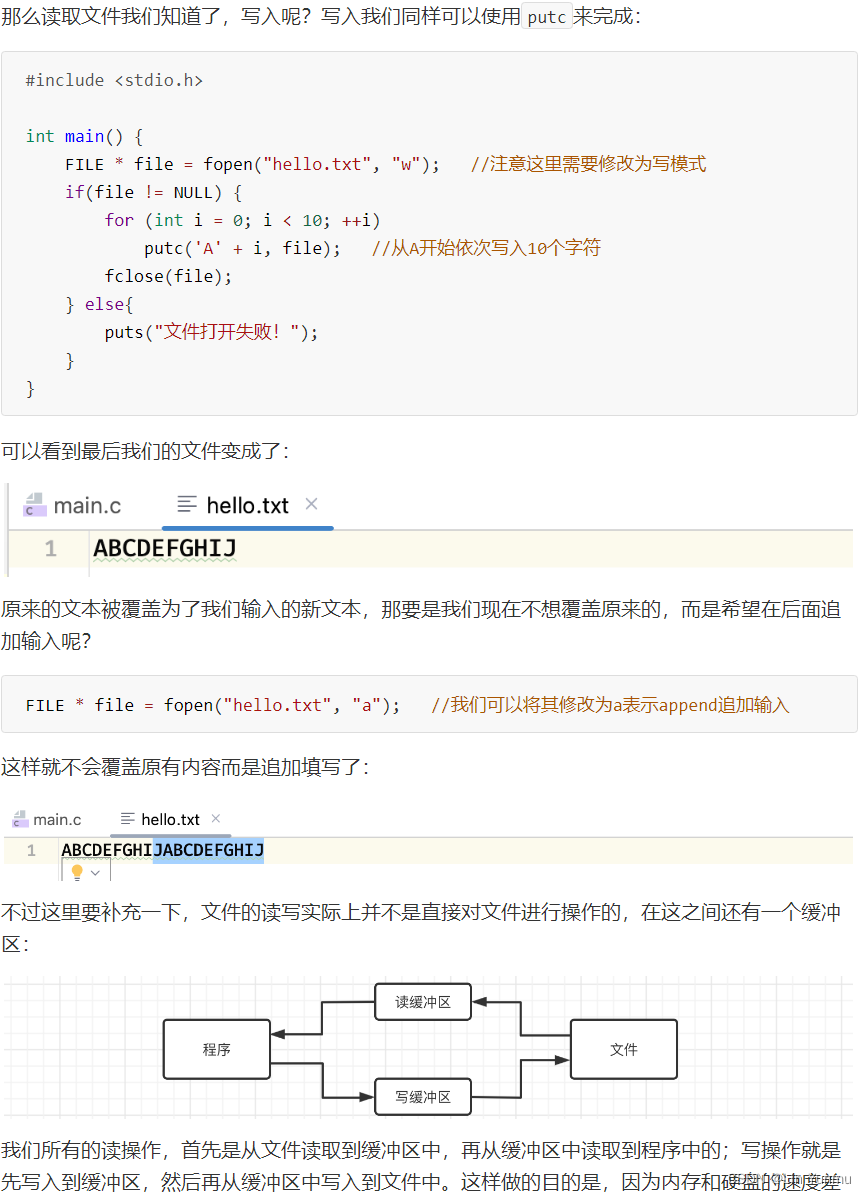


随机访问



程序编译与调试

C语言程序的编译
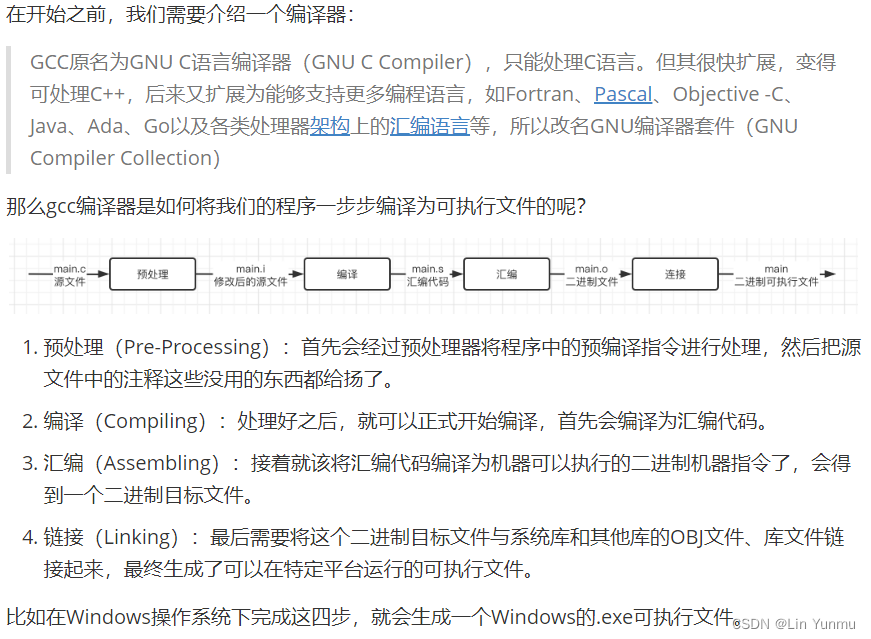
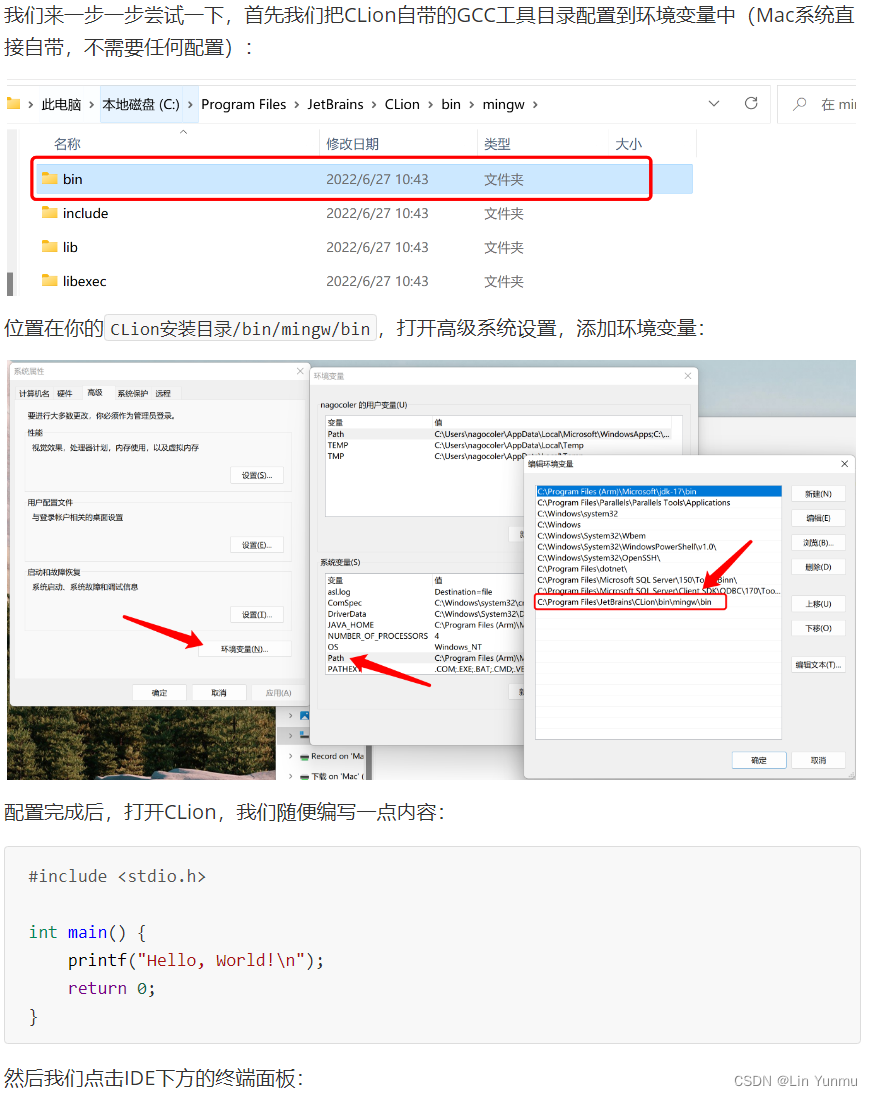
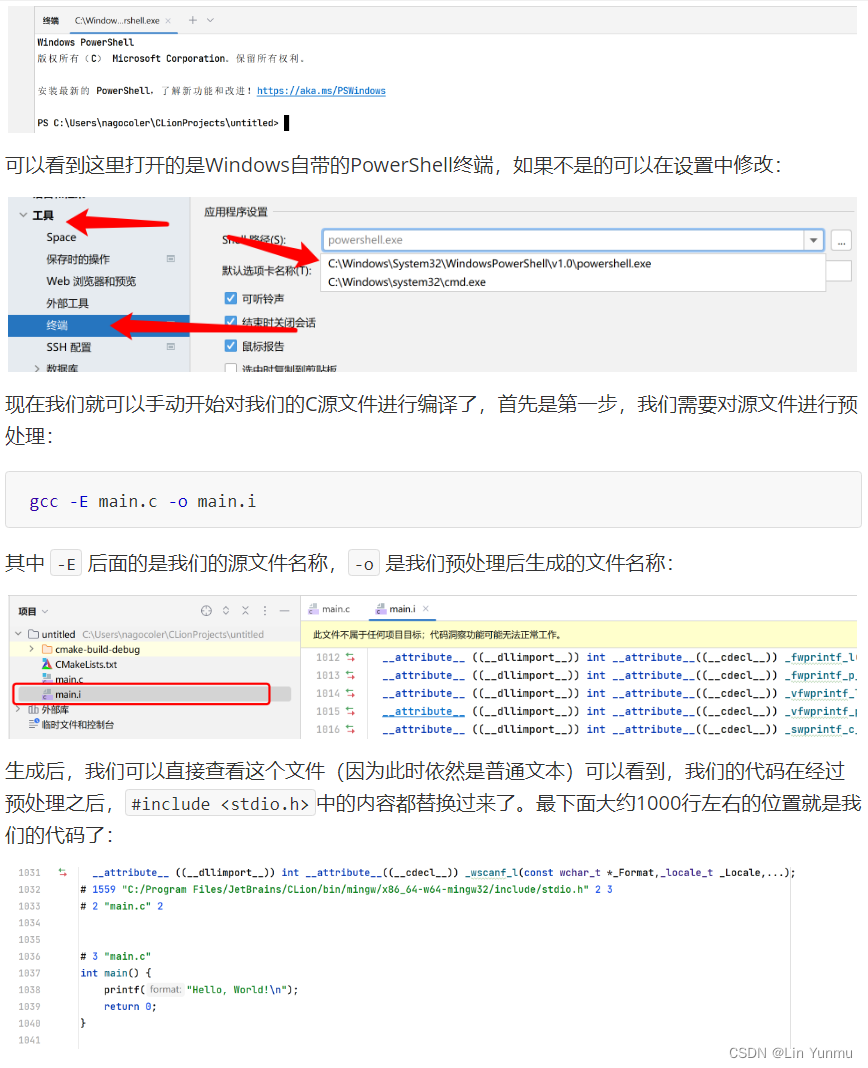
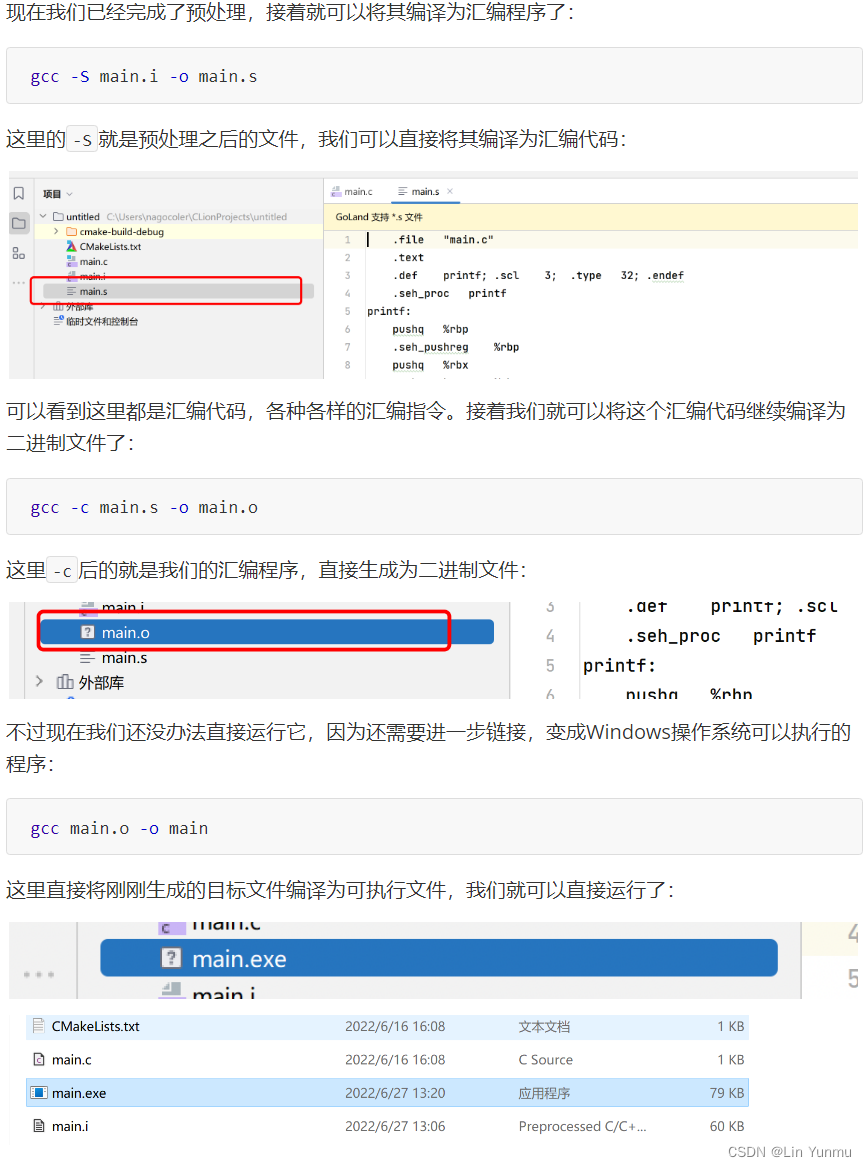
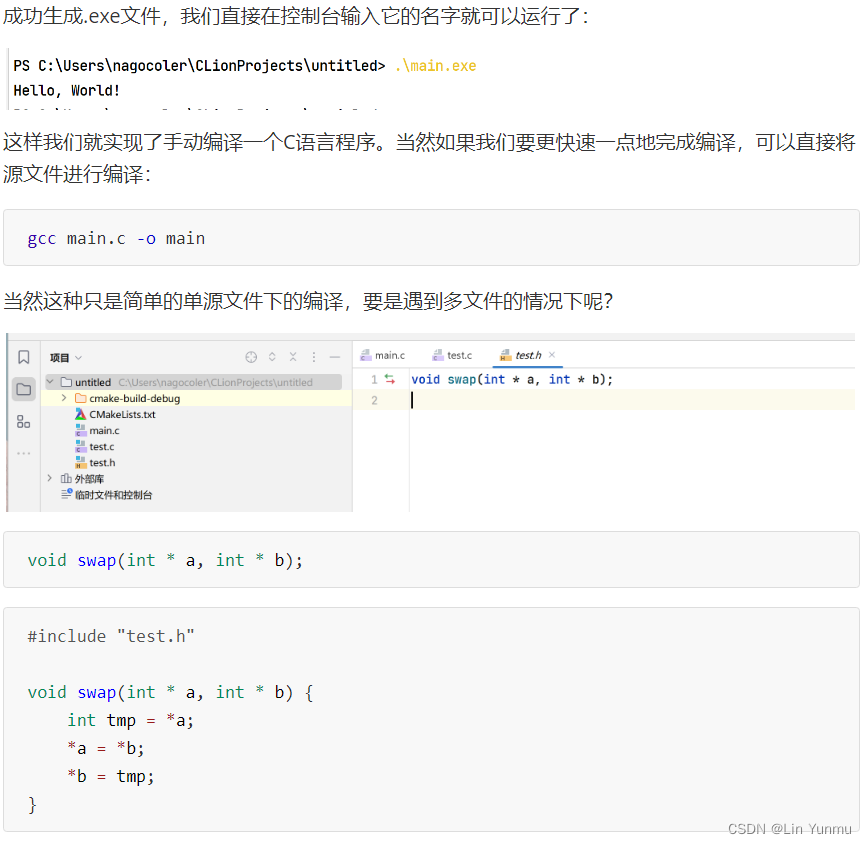

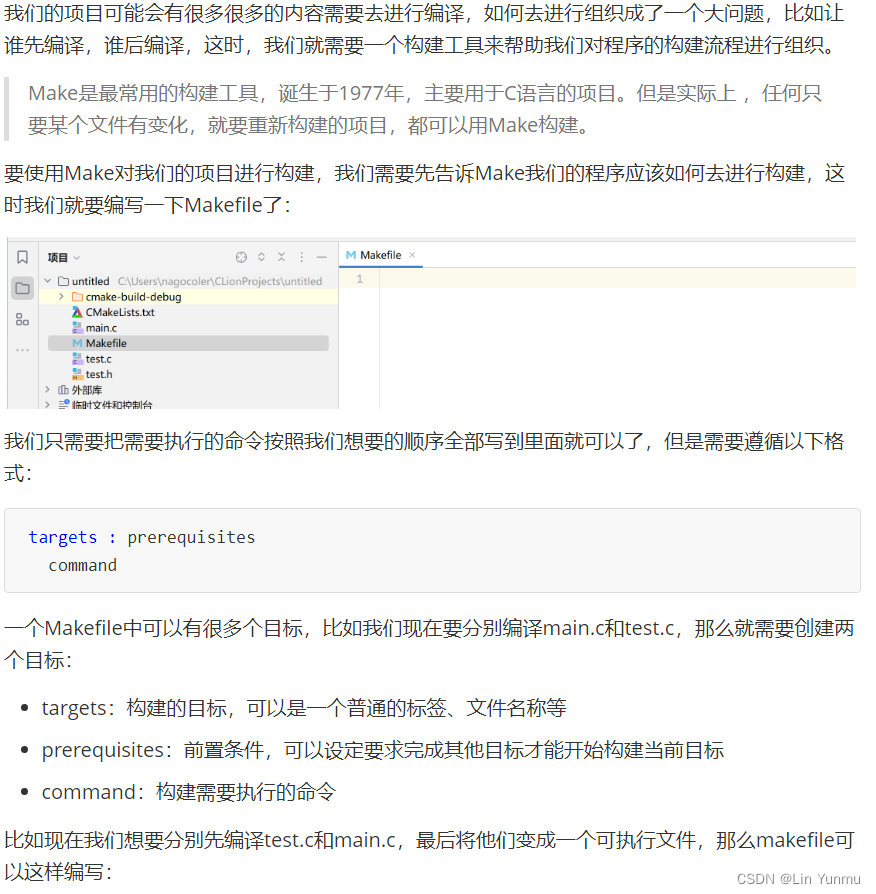
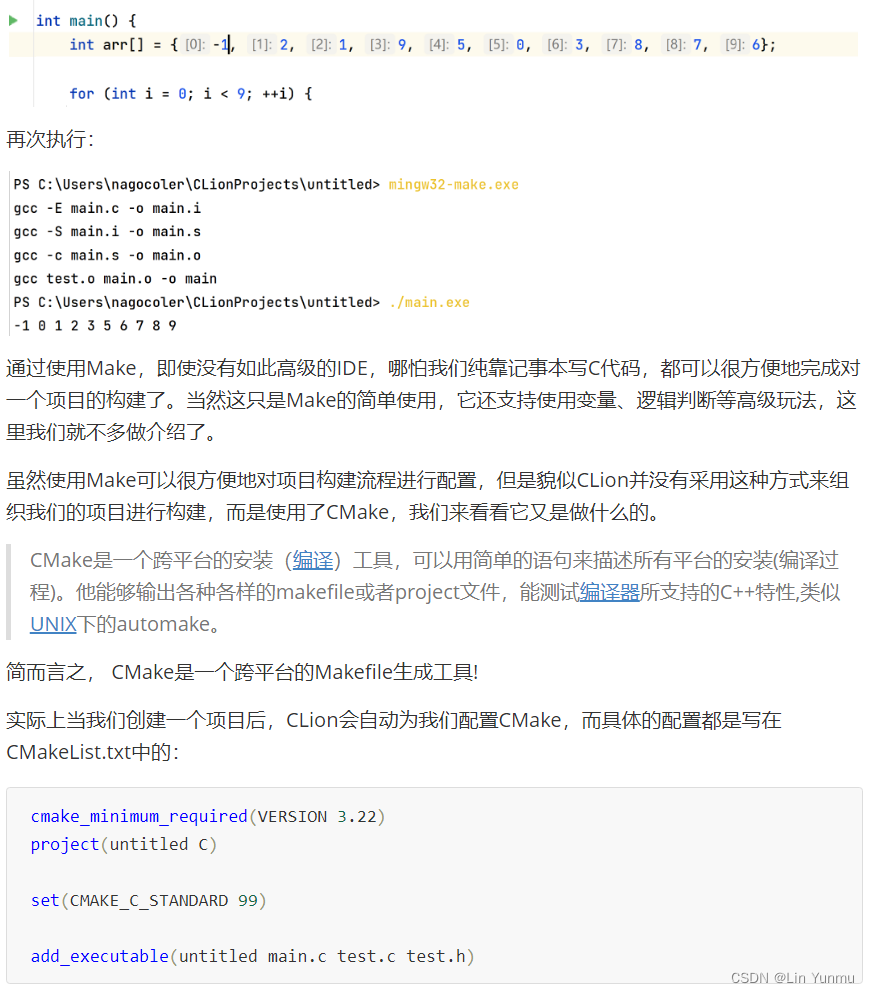
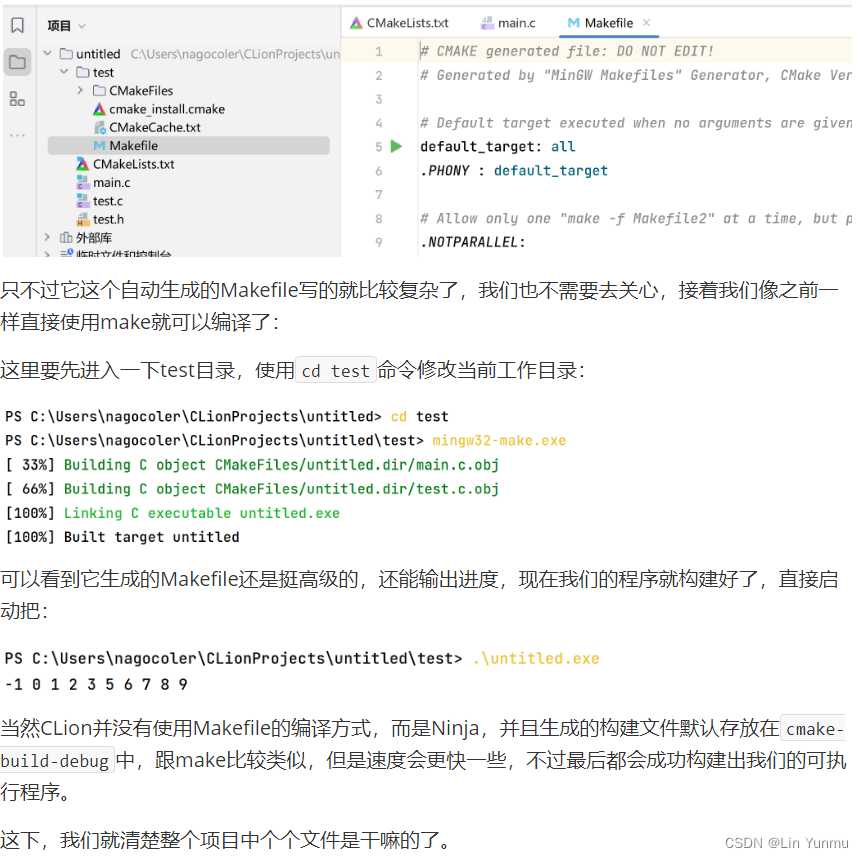
使用Make和CMake进行构建


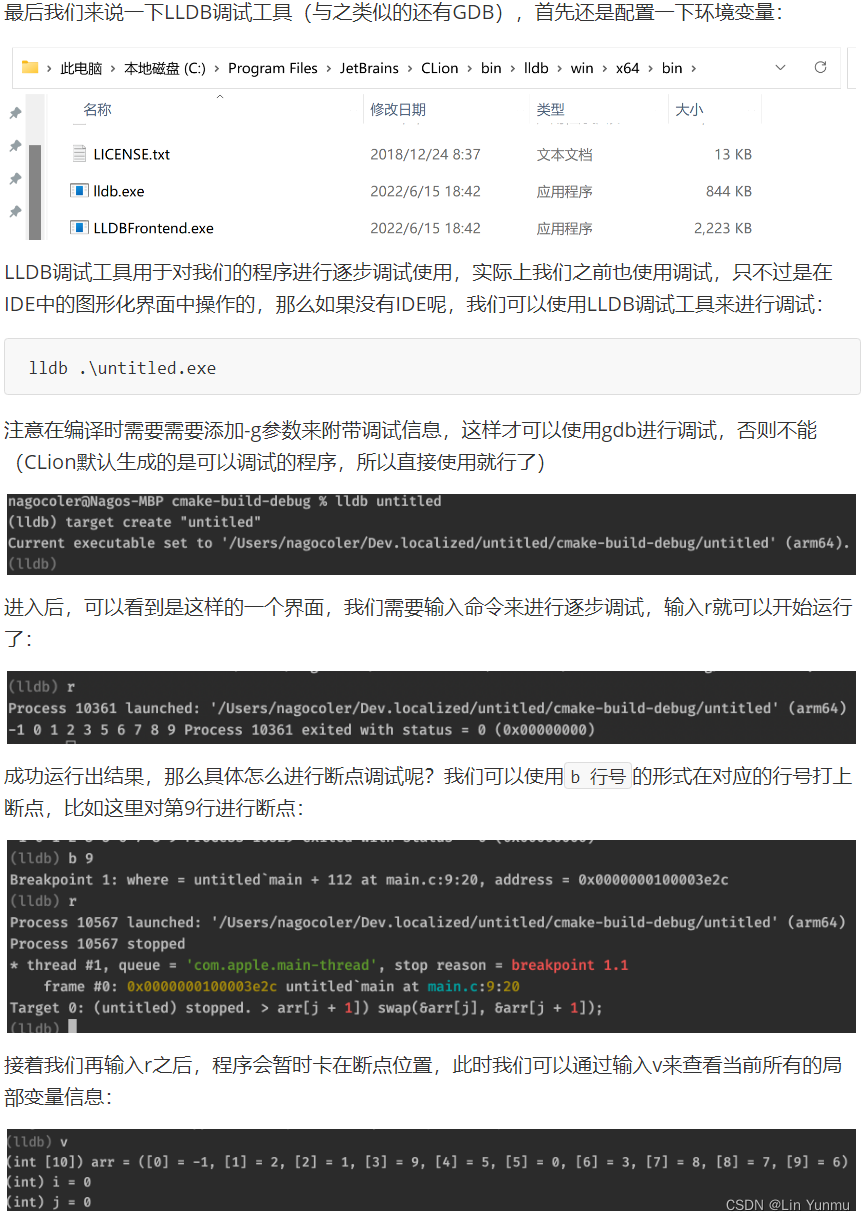
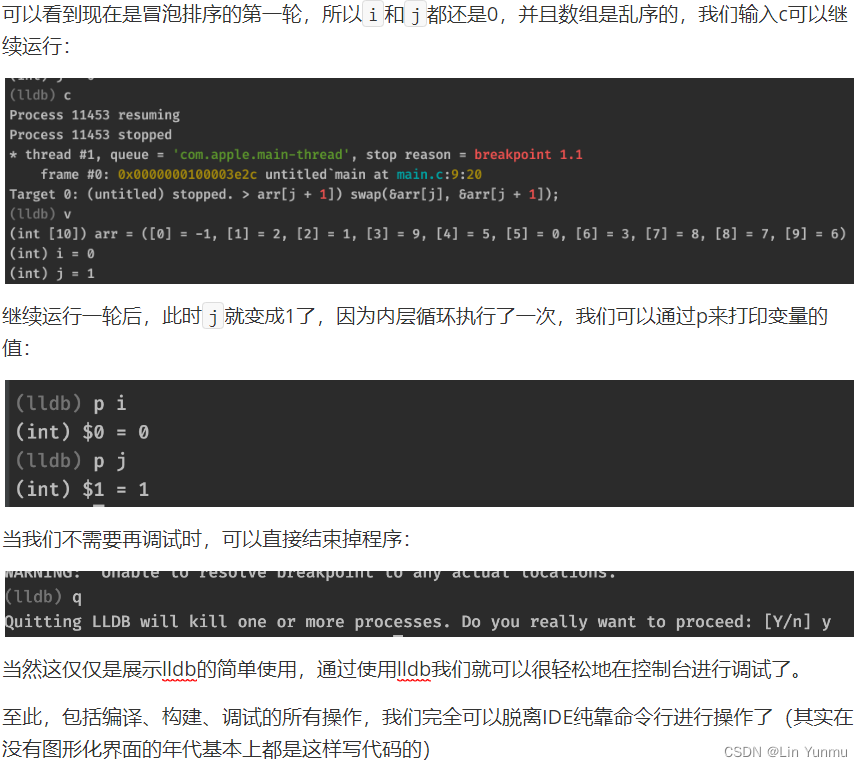
使用LLDB调试工具















 853
853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









