






1、 迭代学习控制
(1)迭代学习控制的基本原理
迭代学习控制(Iterative Learning Control,ILC)的思想最初由日本学者Uchiyama于1978年提出,于1984年由Arimoto等人做出了开创性的研究。这些学者借鉴人们在重复过程中追求满意指标达到期望行为的简单原理,成功地使具有强耦合非线性多变量的工业机器人快速高精度地执行轨迹跟踪任务。其基本做法是:对于一个在有限时间区间内执行轨迹跟踪任务的机器人,利用前一次或前几次操作时测得的误差信息修正控制输入,使得该重复任务在下一次操作过程中做得更好。如此不断重复,直至在整个时间区间内输出轨迹跟踪期望轨迹,如图2所示。
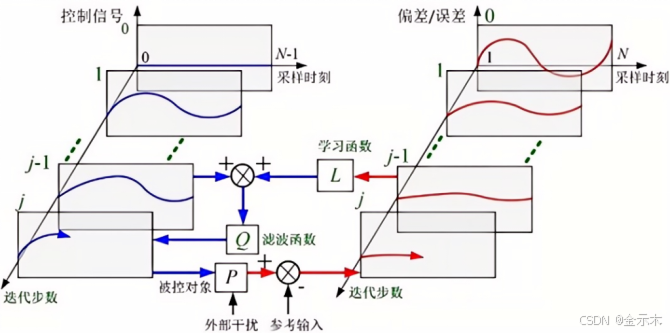
图2 迭代学习控制的基本原理
迭代学习控制适合于具有重复运动性质的被控对象,通过迭代修正达到某种控制目标的改善。迭代学习控制方法不依赖于系统的精确数学模型,能在给定的时间范围内,以非常简单的算法实现不确定性较高的非线性强耦合动态系统的控制,并高精度跟踪给定期望轨迹,因而一经推出,就在运动控制领域得到了广泛的运用。
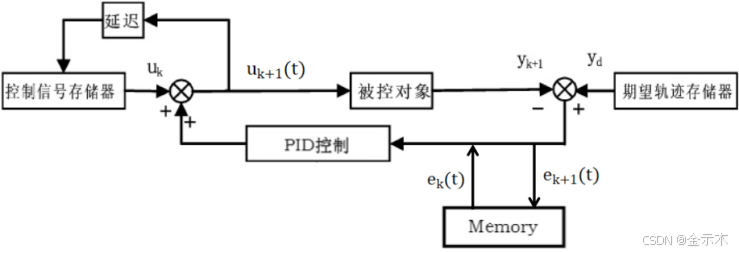
(2)迭代学习控制的基本结构
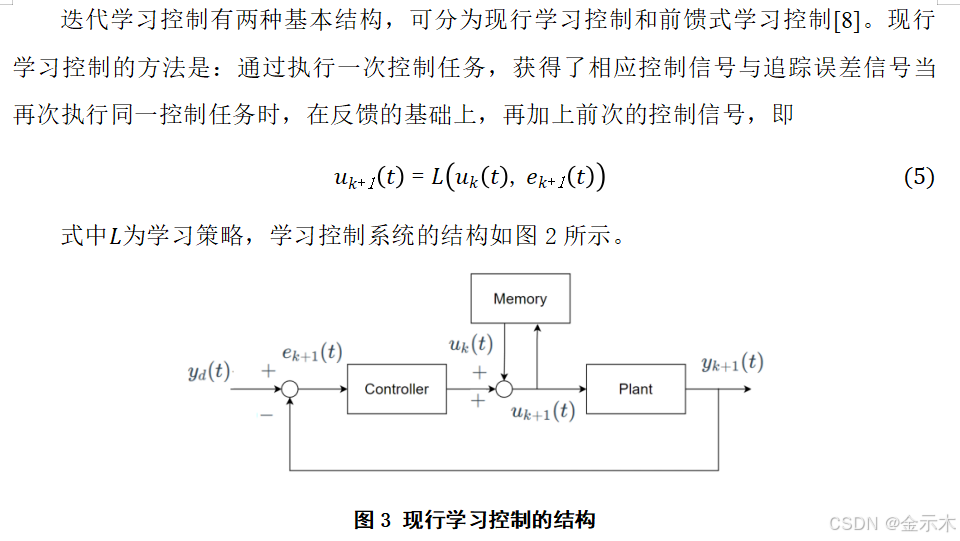
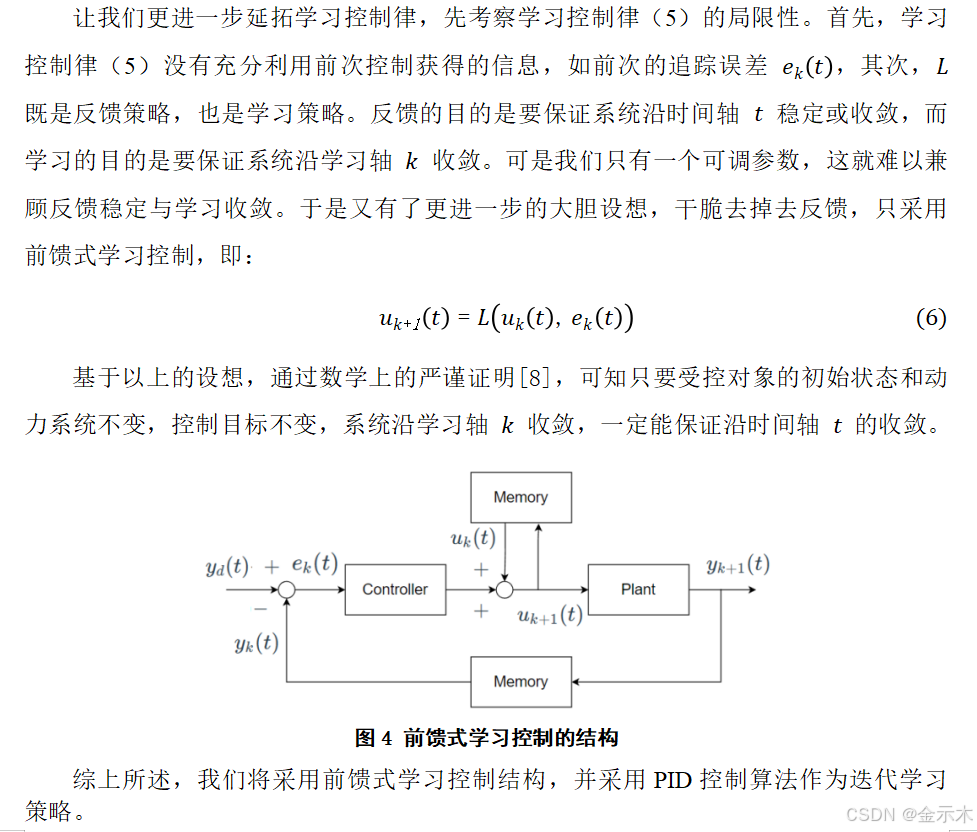 3.3高速列车PID型迭代学习控制器设计
3.3高速列车PID型迭代学习控制器设计
当其迭代到第 k 次时,ATO 系统算法为: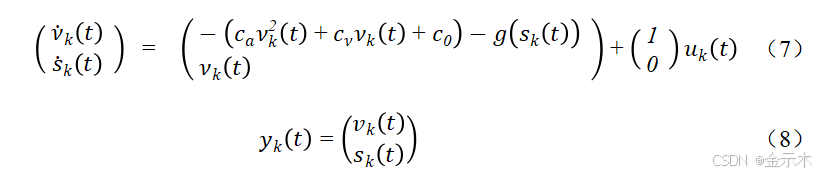
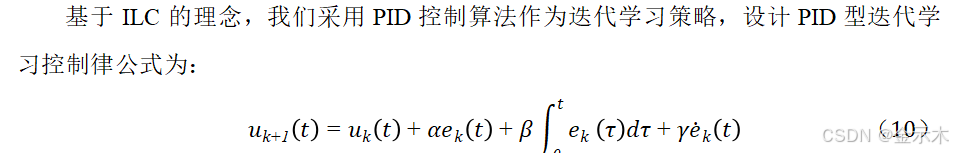
4 基于MATLAB的仿真及分析
clear all;clc;
% 目标轨迹生成 仿真时长101个点,迭代次数N次
N = 30;%迭代次数
dt = 1;%采样间隔
t = 0:dt:15;
t1 = 0:98:1470;
[~, N_t] = size(t);
% 参数初始化 - N行,代表N次迭代;N_t列,代表每次仿真时长为N_t个时间点
u = zeros(N, N_t); %控制量
y = zeros(N, N_t); %系统输出
y_d = zeros(1, N_t); %期望输出
e = zeros(N, N_t); %与期望的偏差
s = zeros(N, N_t);
max_e = zeros(N, 1); %量化评估-最大误差
% 期望轨迹与系统初始状态
for j = 1:N_t
if t(j) <= 4
y_d(j) = 2 * j - 2;
elseif t(j) > 4 && t(j) <= 6
y_d(j) = 8;
elseif t(j) >= 7 && t(j) <= 8
y_d(j) = 6;
elseif t(j) >= 9 && t(j) <= 10
y_d(j) = 8;
elseif t(j) > 10
y_d(j) = 30 - 2 * j + 2;
end
end
figure(4)
plot(t, y_d, 'Color', 'k'); % y_d 的颜色指定为黑色
% 迭代过程
for k = 1:N
% 第k次控制过程
integral = 0;
for i = 1:N_t - 1
% 计算位移量*
s(k, i+1) = y(k, i)*dt + s(k, i);
if s(k, i) >= 38.5 && s(k, i) < 51.35
theta = 0.096;
elseif s(k, i) >= 90.75 && s(k, i) < 94.85
theta = 0.0724;
else
theta = 0;
end
% 系统模型
y(k, i+1) = -0.0166*y(k, i)^2 - 0.228*y(k, i)-7.75 + u(k, i) + y(k, i) - 9.8 * theta;
%y(k, i+1) = y(k, i) / (1 + y(k, i)^2) + u(k, i)^3;%从第二个时间点开始
if y(k, i+1)>100
y(k, i+1)=100;
end
e(k, i+1) = y_d(i+1) - y(k, i+1);%计算所有时间点对应的误差
%控制量更新
%控制量更新 PID 控制
if e(k, i+1)>100
e(k, i+1)=100;
end
integral = integral + e(k, i+1) * dt;
derivative = (e(k, i+1) - e(k, i)) / dt;
u(k+1, i) = u(k, i) + 0.5 * e(k, i+1) + 0.01 * integral + 0.05 * derivative;
end
max_e(k) = max(e(k, :));
X = ['第', num2str(k), '次迭代——最大误差为', num2str(max_e(k))];
disp(X)
if k>=4 && k <= 30
figure(17)
subplot(1, 1, 1);
plot(t1, y(k, :)*10);
hold on;
xlabel('t/s');
ylabel('y/(m/s)');
pause(0.4);
end
if k == 30
figure(18)
subplot(1, 1, 1);
plot(t1, u(k, :)*10);
hold on;
xlabel('t/s');
ylabel('u/(m/s)');
pause(0.4);
end
end
figure(2)
plot(1:N, max_e(:, 1))
xlabel('迭代次数 k');
ylabel('e/(m/s)');
figure(4)
plot(t1, y_d*10, 'Color', 'k'); % y_d 的颜色指定为黑色
xlabel('t/s');
ylabel('y_d/(m/s)');
















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









