







Transaction Management Overview • Objectives — schedule queries from multiple simultaneous users efficiently — keep the database in a consistent state • Transaction management involves — performing “logical units of work” (definition of transactions) — controlling concurrency – stop user tasks interfering — resolving conflicts – e.g., simultaneous update attempts — recovering from errors – restore DB to consistent state 事务管理目标是有效安排多个用户同时进行的查询 - 保持数据库处于一致状态 包括 - 执行 "逻辑工作单位"(事务定义) - 控制并发性 - 停止用户任务干扰 - 解决冲突 - 如同时尝试更新 - 从错误中恢复 - 将数据库恢复到一致状态
The “ACID” Requirements For a Transaction A transaction should have certain well-defined properties: • Atomicity – each unit of work is indivisible; “all-or-nothing” (transactions that don’t complete must be undone or “rolled-back”) • Consistency – a transaction transforms the database from one consistent state into another (intermediates may be inconsistent) • Isolation – each transaction effectively executes independently – one transaction should not see the inconsistent/incomplete state of another transaction • Durability – once a transaction is complete, its effects cannot be undone or lost (it can only be “undone” with a compensating transaction) ACID要求 原子性:工作单位不可分割 未完成事务必须撤销 一致性:事务将数据库从一种一致状态转换为另一种(中间状态可能不一致) 隔离性:事务有效独立执行 事务不能看到另一个不一致未完成状态 持久性:事务完成,不可撤销或丢失(只能通过补偿事务 "撤销")
How Are Transactions Defined? In SQL, by default, each SQL statement is treated as a transaction (even if it affects multiple rows or tables):每条SQL语句都被视为一个事务
This is one atomic unit of work on the database. Multiple statements may be grouped together into a single transaction. Example: A new member of staff takes over a property for rent:这是数据库的一个原子工作单元 多个语句可以组合成一个事务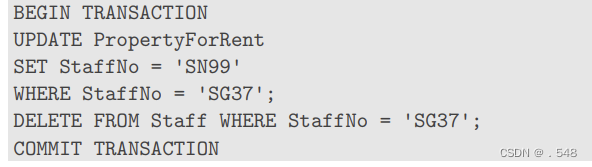
Concurrent Transactions – The Lost Update Problem • Suppose an account holds £100. If T1 deposits £100 and T2 withdraws £10, the new balance should be £190. With concurrent transactions, we could get: • T1: UPDATE Account SET Balance = Balance + 100; • T2: UPDATE Account SET Balance = Balance - 10; 并发事务 更新丢失 
Serialising Transactions • Clearly, one solution would be to serialise all transactions: — make first transaction finish before next one starts • However, this would not be efficient on multi-user systems • A non-serial schedule interleaves operations from a set of concurrent transactions — should produce the same results as some serial schedule • Only need to schedule transactions — that refer to the same data items and perform a mixture of writes and reads — some transactions might benefit from running simultaneously (e.g., if they both read the same tables 序列化事务 解决更新丢失问题 让第一个事务在下一个事务开始前完成 但是在多用户系统上效率低 非序列计划将一组并发事务操作交错进行 和序列化事务结果相同 只需对引用相同数据项并执行混合写入和读取的事务进行计划 同时运行能让事务运行更快(eg 读取相同表)
Controlling Concurrency with Locks • Locks may be used to serialise only those parts of a transaction that need it... • Locks may have different levels of granularity: — Table locks – easy to implement, not so efficient — Row locks – more complicated, better performance — Page locks – used by the Memory Manager (not here) • Transactions can cooperate by using locks to indicate their intention: — Read (shared) – want to read an object — Write (exclusive) - want to read and write an object 使用锁控制并发性 锁只用在序列化事务中的部分 锁可以由不同的粒度 表锁:容易 效率低 行锁:复杂 性能好 页锁:内容管理器使用 事务可以通过锁表明目的进行组合 Read想要读取对象 Write 想要读取和写入对象
• Suppose two transactions want to access a given row...两个事务读取同一行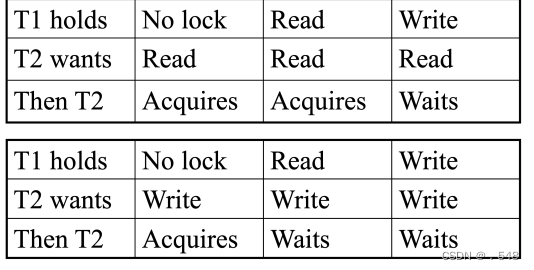
在第一个事务未解锁前,第二个事务Write操作之后等待第一个事务解锁然后继续操作
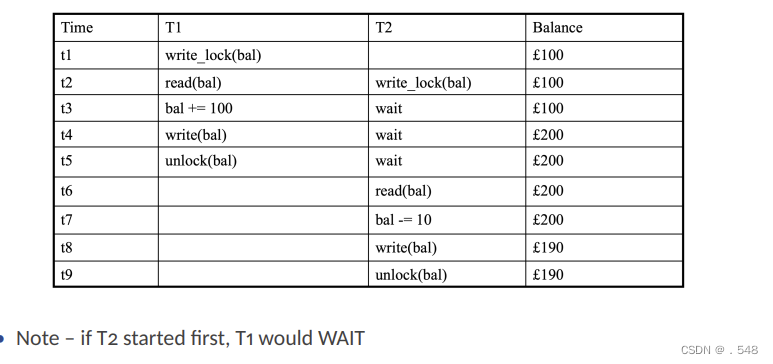 Concurrent Transactions – Inconsistent Analysis Problem • Often, a single transaction may modify multiple rows... • What if two transactions execute at the same time?
Concurrent Transactions – Inconsistent Analysis Problem • Often, a single transaction may modify multiple rows... • What if two transactions execute at the same time?  • Depending on the timing, User2 might see: — Sum of all old salaries — Sum of all new salaries — Sum of some old + some new salaries (problem!!) • This is called the inconsistent analysis problem • Clearly, multiple locks are required...不一致性分析问题 一个事务可能修改多行 如果两个事务同时执行需要多个锁避免不一致
• Depending on the timing, User2 might see: — Sum of all old salaries — Sum of all new salaries — Sum of some old + some new salaries (problem!!) • This is called the inconsistent analysis problem • Clearly, multiple locks are required...不一致性分析问题 一个事务可能修改多行 如果两个事务同时执行需要多个锁避免不一致
Two-Phase Locking • What if a transaction requires more than one lock? • The transaction should: — acquire the locks as it needs them ... — but only release the locks at the end of the transaction • This is two-phase locking – So called because there is: — a growing phase – more & more locks are acquired — a shrinking phase – the locks are finally released • Two-phase locking solves inconsistent analysis problem • Can you work out why? • Hint: consider read & write lock waiting rules...两阶段锁:事务在需要多个锁时 在需要锁定,结束时解锁 增长阶段 获得多个锁 缩小阶段 最后解锁 解决不一致分析问题
Deadlocks • Two-phase locking ensures serializability, but it cannot prevent deadlocks • Example: Suppose a pair of transactions are in the growing phase, and both need write-locks on objects A and B: As deadlocks are relatively rare, most DBMSs allow them to occur rather than attempt to prevent them...死锁 两阶段锁定可确保序列化,但不能防止死锁 允许死锁发生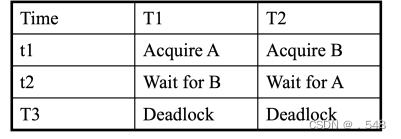
Detecting Deadlocks • Deadlocks can be detected if the Lock Manager maintains a transaction dependency graph, which is sometimes called a wait-for graph (WFG)... • The dependency graph contains: — a node for each transaction T — an arc Ta → Tb for each dependency • T1 → T2 means T1 is waiting for a resource held by T2 • A cycle in the graph indicates deadlock...检测死锁 锁管理器维护事务依赖图(WFG等待图)就可以检测 该图包括事务T的节点 依赖关系的弧线 T1 → T2表示T1等待T2持有资源 图中为死锁
图中为死锁
Deadlock Resolution • If the DBMS detects deadlock, it picks a victim transaction: — the victim is killed – rolled-back and re-scheduled — the other transaction proceeds... • Strategies for picking the victim include: — pick youngest, oldest, or random transaction — consider amount done (or to do) by each transaction — pick deadlocked node in WFG with the most dependencies 解除死锁 DBMS检测到死锁会选择一个受害四五 杀死该事务 回滚重新安排事务 其他事务继续 选择受害事务的规则是 选择最早或最晚 随机的事务 考虑到事务已完成或待完成量 在WFG中选择依赖关系最多的死锁节点
Specifying Locking Modes in SQL • ANSI SQL (and some storage engines in MySQL Server) supports several locking modes. These are specified according to the degree of concurrency/isolation required. Syntax:在SQL中指定锁模式 ANSI SQL根据所需并发隔离程度指定锁模式
• Where level is one of: 
完全表锁定 类似表锁定(可以INSERT另一个T)可能出现幽灵行 类似行锁定可能出现不可重复读取 无锁定可能出现脏读 具体名词解释事务中的脏读,不可重复读,幻影读:Isolation of databases - 知乎 (zhihu.com)
The Journal File and Rolling Back Transactions • Usually, a log of each step of transaction is written to a special journal file. Each “record” of the journal file contains (in order of time): — a transaction ID & timestamp — a before-image (if the operation is an update or delete) — an after-image (if the operation is an update or insert) • Periodically, the DBMS flushes all memory to disc & writes a checkpoint record. The Journal file can then be used for: — rolling back transactions — system error recovery (roll back to last checkpoint)日志文件和回滚事务 每一步事务都会写入日志文件 每条记录按时间顺序排序包括 事务 ID 和时间戳 - 前映像(如果操作是更新或删除) - 后映像(如果操作是更新或插入)DBMS 会定期将所有内存刷新到磁盘,并写入检查点记录。日志文件可用于 - 回滚事务 - 系统错误恢复(回滚到上一个检查点)
Summary • Transaction Management is largely concerned with implementing the “ACID” requirements: — Defining logical units of work – atomic transactions — Using rollback and transaction scheduling to maintain consistency — Using locks to stop transactions interfering – isolation — Using journaling to recover from system errors – durability • In SQL, its up to the programmer to consider & specify: — how much concurrency/isolation is required...事务管理主要涉及 "ACID "要求的实施: - 定义工作的逻辑单元--原子事务--使用回滚和事务调度来保持一致性--使用锁来阻止事务干扰--隔离--使用日志来从系统错误中恢复--持久性--在 SQL 中,由程序员来考虑和指定: - 需要多少并发性/隔离性















 495
495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









