







RAID Structure
- RAID – redundant array of inexpensive disks
- multiple disk drives provides reliability via redundancy
- Increases the mean time to failure
- Mean time to repair – exposure time when another failure could cause data loss
- Mean time to data loss based on above factors
- If mirrored disks fail independently, consider disk with 1300,000 mean time to failure and 10 hour mean time to repair
- Mean time to data loss is 100, 0002 / (2 ∗ 10) = 500 ∗ 106 hours, or 57,000 years!
- Frequently combined with NVRAM to improve write performance
- Several improvements in disk-use techniques involve the use of multiple disks working cooperatively
RAID - 廉价磁盘冗余阵列
多个磁盘驱动器通过冗余提供可靠性
增加平均故障时间
平均修复时间--另一次故障可能导致数据丢失的暴露时间
基于上述因素的平均数据丢失时间
如果镜像磁盘独立发生故障,则考虑平均故障时间为 1300,000 小时、平均修复时间为 10 小时的磁盘
数据丢失的平均时间为 100,0002 / (2 ∗ 10) = 500 ∗ 106 小时,或 57,000 年!
经常与 NVRAM 结合使用以提高写入性能
磁盘使用技术的若干改进涉及使用多个磁盘协同工作
- Disk striping uses a group of disks as one storage unit
- RAID is arranged into six different levels
- RAID schemes improve performance and improve the reliability of the storage system by storing redundant data
- Mirroring or shadowing (RAID 1) keeps duplicate of each disk
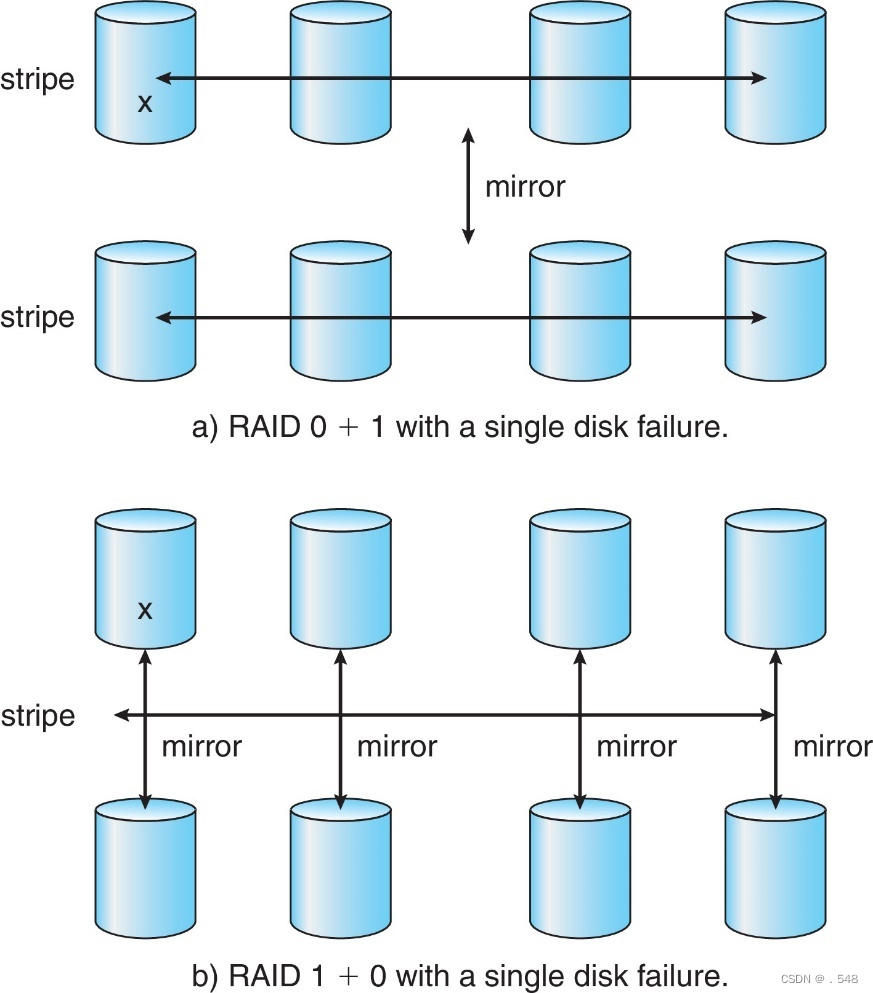
- Striped mirrors (RAID 1+0) or mirrored stripes (RAID 0+1) provides high performance and high reliability
- Block interleaved parity (RAID 4, 5, 6) uses much less redundancy
- RAID within a storage array can still fail if the array fails, so automatic replication of the data between arrays is common
- Frequently, a small number of hot-spare disks are left unallocated, automatically replacing a failed disk and having data rebuilt onto them
磁盘条带化将一组磁盘用作一个存储单元
RAID 分为六个不同的级别
RAID 方案通过存储冗余数据来提高性能和存储系统的可靠性
镜像或阴影(RAID 1)保留每个磁盘的副本
条带镜像(RAID 1+0)或镜像条带(RAID 0+1)提供高性能和高可靠性
块交错奇偶校验(RAID 4、5、6)使用的冗余要少得多
如果阵列发生故障,存储阵列内的 RAID 仍会发生故障,因此阵列间数据的自动复制很常见
通常会留出少量未分配的热备用磁盘,自动替换故障磁盘,并将数据重建到这些磁盘上
RAID Levels 
- Regardless of where RAID implemented, other useful features can be added
- Snapshot is a view of file system before a set of changes take place (i.e. at a point in time)
- Replication is automatic duplication of writes between separate sites
- For redundancy and disaster recovery
- Can be synchronous or asynchronous
- Hot spare disk is unused, automatically used by RAID production if a disk fails to replace the failed disk and rebuild the RAID set if possible
- Decreases mean time to repair
无论 RAID 在哪里实现,都可以添加其他有用的功能
快照是一组变化发生前(即某个时间点)的文件系统视图
复制是在不同站点之间自动复制写入内容
用于冗余和灾难恢复
可同步或非同步
热备用磁盘是未使用的磁盘,当磁盘出现故障时,RAID 生产会自动使用热备用磁盘来替换故障磁盘,并在可能的情况下重建 RAID 集
缩短平均修复时间
- RAID alone does not prevent or detect data corruption or other errors, just disk failures
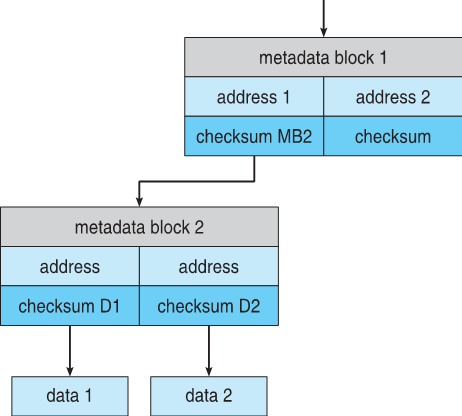
- Solaris ZFS adds checksums of all data and metadata
- Checksums kept with pointer to object, to detect if object is the right one and whether it changed
- Can detect and correct data and metadata corruption
- ZFS also removes volumes, partitions
- Disks allocated in pools
- Filesystems with a pool share that pool, use and release space like malloc() and free() memory allocate / release calls
RAID 本身不能防止或检测数据损坏或其他错误,只能检测磁盘故障
Solaris ZFS 增加了所有数据和元数据的校验和
校验和与对象指针一起保存,以检测对象是否正确以及是否已更改
可检测并纠正数据和元数据损坏
ZFS 还会删除卷和分区
在池中分配的磁盘
具有磁池的文件系统共享该磁池,使用和释放空间,就像 malloc() 和 free() 内存分配/释放调用一样

Error Detection and Correction
- Fundamental aspect of many parts of computing (memory, networking, storage)
- Error detection determines if there a problem has occurred (for example a bit flipping)
- If detected, can halt the operation
- Detection frequently done via parity bit
- Parity one form of checksum – uses modular arithmetic to compute, store, compare values of fixed-length words
- Another error-detection method common in networking is cyclic redundancy check (CRC) which uses hash function to detect multiple-bit errors
- Error-correction code (ECC) not only detects, but can correct some errors
- Soft errors correctable, hard errors detected but not corrected
计算机许多部分(内存、网络、存储)的基本要素
错误检测确定是否发生了问题(例如位翻转)
如果检测到,可停止运行
通常通过奇偶校验位进行检测
奇偶校验是校验和的一种形式--使用模块算术计算、存储、比较固定长度字的值
网络中常见的另一种错误检测方法是循环冗余校验 (CRC),它使用哈希函数检测多位错误
纠错码 (ECC) 不仅能检测错误,还能纠正某些错误
软错误可纠正,硬错误可检测到但无法纠正
- Data storage and transmission are complex and frequently result in errors. Error detection attempts to spot such problems to alert the system for corrective action and to avoid error propagation. Error correction can detect and repair problems, depending on the amount of correction data available and the amount of data that was corrupted.
数据存储和传输非常复杂,经常会出现错误。错误检测试图发现这些问题,提醒系统采取纠正措施,避免错误传播。纠错可以检测和修复问题,这取决于可用的纠错数据量和损坏的数据量。















 347
347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









