






目录
一.什么是Object Detection?
在之前我们已经对单纯的图像分类任务进行了简单的介绍。对于一张图片,图像分类实际上是对图片中最主要的物体进行分类。但是在实际应用中一张图片可能会包括多个物体以及信息,这就需要我们对一张照片的不同物体进行分类+定位在图片中的位置。简单而言,目标检测问题就是要去对一张图片中的物体进行 classification+localization。
那么问题来了我们对目标检测任务该如何去定位+识别呢?
这里先给出一个处理的基本思路:
Step1:对图像的特征提取依旧和之前一样,比如借助VGG/RESTNET等等。然后进入两个分支。
Step2:第一个分支A用来分类,这里需要引入一个背景类,判断不是背景才会进入用于定位的分支B。进入分支B会给出所判断目标物体的位置信息(比如center point,width,length,etc)。
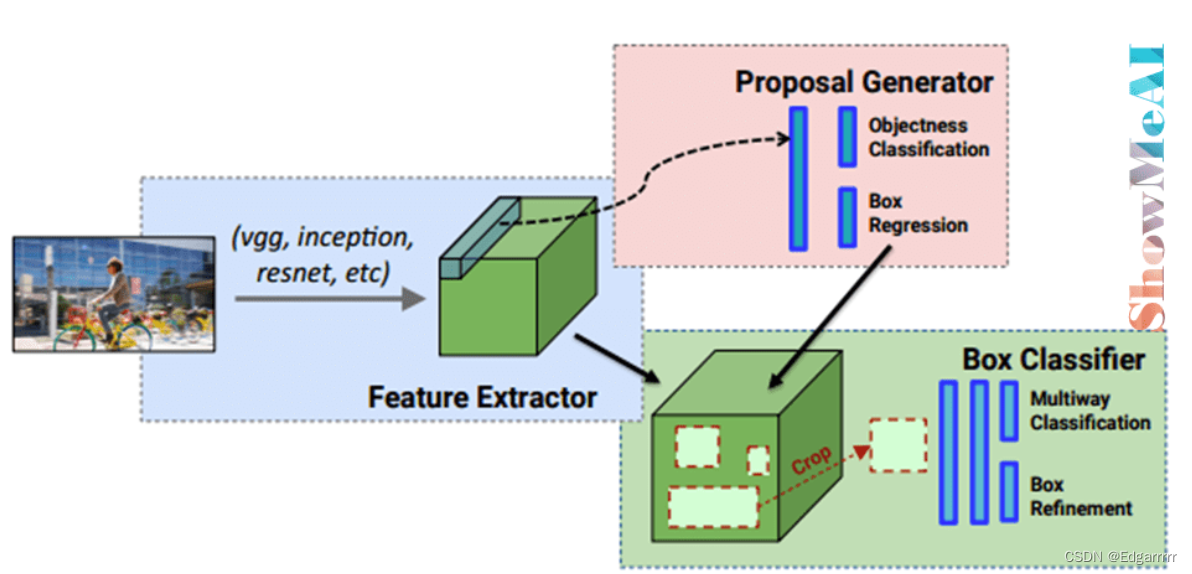
二.两阶段(Two stages)目标检测算法介绍
2.1什么是两阶段呢?
阶段一:首先由算法生成一系列作为样本的候选框
阶段二:再通过卷积神经网络进行分类
当然你可能会问,为什么是两阶段呢?为什么没有一阶段?其实当然有的,一阶段将在下一篇blog中作出介绍。不过这里大概说明一下二者区别:两阶段算法检测准确率和定位精度上占优,基于端到端(一阶段)的算法速度占优。相对于R-CNN系列的「两步走」(候选框提取和分类),YOLO等方法只「看一遍」。
2.2两阶段典型算法—R-CNN
R-CNN核心思想: 对每张图片选取多个区域(Region Proposal),然后每个区域作为一个样本进入一个卷积神经网络来抽取特征。
那如何确定待选区域呢?
确定待选区域:利用选择性搜索 Selective Search 算法在图像中从下到上提取 2000个左右的可能包含物体的候选区域 Region Proposal。因为获取到的候选区域大小各不相同,所以需要将每个 Region Proposal 缩放(warp)成统一的大小并输入到CNN中去提取特征。
我如何去优化待选区域呢?
优化待选区域:接上,我们将每个 Region Proposal 提取到的CNN特征输入到SVM进行分类。用这些区域特征来训练线性回归器对区域位置进行调整。
R-CNN的优劣之处:

2.3基于R-CNN的改进模型Fast R-CNN
这里首先给出改进的概览内容:

Fast R-CNN的核心环节如下:
1.Region Proposal:与 R-CNN 一致。跟RCNN一样,Fast-RCNN 采用的也是 Selective Search 的方法来产生 Region Proposal,每张图片生成 2k 张图片。但是不同的是,之后不会对 2k 个候选区域去原图截取,后输入 CNN,而是直接对原图进行一次 CNN,在 CNN 后的 feature map,通过 ROI project 在 feature map 上找到 Region Proposal的位置。
2. Convolution & ROI (region of interest候选区)映射:就是对原图输入到 CNN 中去计算,Fast-RCNN 的工具包提供提供了 3 种 CNN 的结构,默认是使用 VGG-16 作为 CNN 的主干结构。根据 VGG-16 的结构,Fast-RCNN 只用了 4 个 MaxPooling 层,最后一个换成了 ROI Pooling,因此,只需要对 Region Proposal 的在原图上的 4 元坐标 (x,y,w,h)除以16,并找到最近的整数。便是 ROI Project 在 feature map 上映射的坐标结果。最终得到2k个ROI。
3.ROI Pooling:对每一个 ROI 在 feature map 上截取后,进行 ROI Pooling,就是将每个 ROI 截取出的块,通过 MaxPooling 池化到相同维度。
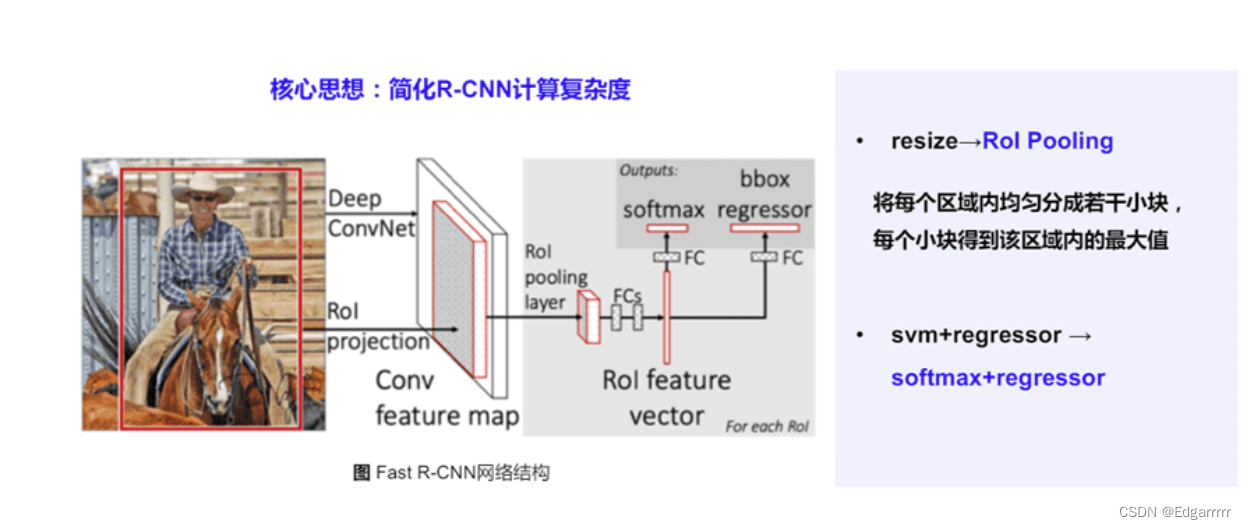
三.R-CNN与Fast R-CNN算法总结
至此,关于目标检测的两阶段算法我们已经大致介绍完毕了R-CNN与Fast R-CNN。
前者对每一个ROI都会进行resize然后送入CNN中进行特征提取以及分类和回归,效率比较低,耗时长。而后者是对整张图片进行一次特征的提取工作。在得到的feature map中,我们根据不同的ROI映射到feature map的不同位置处,得到相应的特征。
可是值得注意的是,FC Layer对输入数据的尺寸要求是一致的,而我们不同的ROI势必会产生不同的尺寸。那么我们这时需引入ROI pooling层来进行对每个ROI相应尺寸的一致化操作。
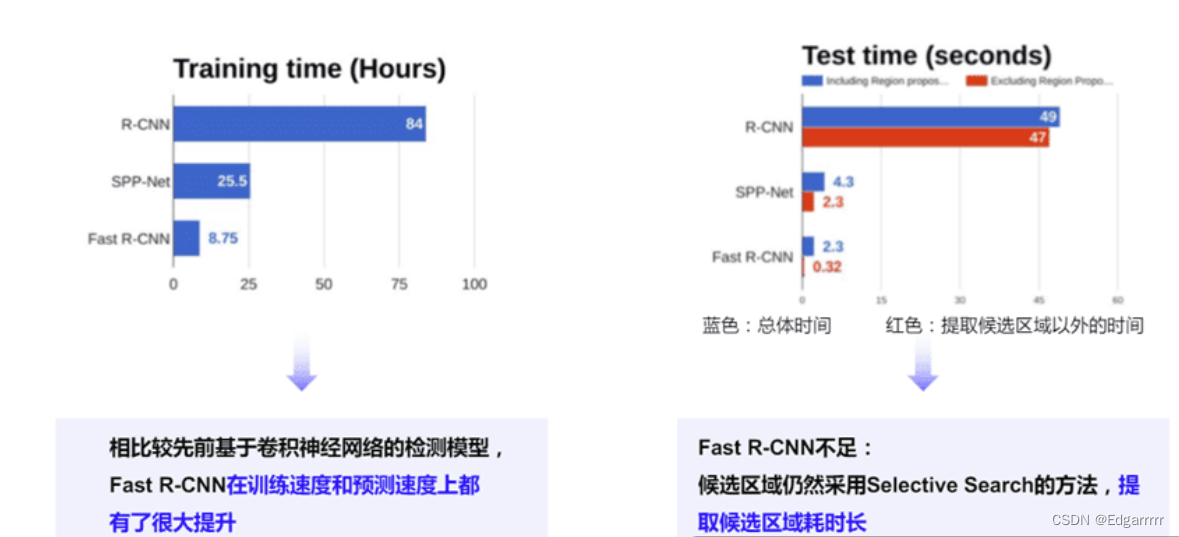
可以由下图看出,Fast R-CNN 相较于R-CNN 无论是在训练还是预测速度上都有了很大的提升!















 971
971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









