






上一篇建立了知识蒸馏基本框架,在老师的介绍下了解到了ModelScope的极限蒸馏挑战赛,在看完选手们的路演后受到了以下启发:
1.可以引入桥接模型来缓解教师模型与学生模型差异太大的问题
2.了解到了高质量的开源数学数据集s1k-1.1和limo(问答对+推理过程)
3.监督微调小模型时可以分阶段微调和调整数据集中专业知识和通用知识的比例
4.可以用Swanlab来追踪训练过程,evalScope用于评估
通过查询资料得知1是《Improved Knowledge Distiling via Teacher Assistant》的变种。
以下是《Improved Knowledge Distiling via Teacher Assistant》的粗读:
作者观察到,当教师模型和学生模型的差异太大时,知识蒸馏的学习方法会导致学生模型性能下降的现象。在实际应用时,往往教师模型和学生模型都是给定的,为了解决这一问题,作者提出了可以在教师模型和学生模型中插入若干个规模逐级减小的TA模型的蒸馏框架,并在实验中的得到了理想的结果。
作者主要是分析教师与学生模型间的规模差异对蒸馏效果的影响。规模差异变大,会带来以下三个影响:
1.教师模型性能越强,学生模型学习能学习到更强的泛化性能。
2.教师模型太强以至于学生模型没有足够的能力来学习老师的复杂的知识。
3.教师模型性能越强,它的输出会更加的自信,表现为熵值减小,导致输出的信息量减少
第一点是积极的,后两点是消极的,而模型的规模差异会决定哪一种力量成为主导因素:

所以随着差异的变大,表现出类似二次函数的曲线。
本文提到了知识蒸馏发展至2019年时的主流损失函数:
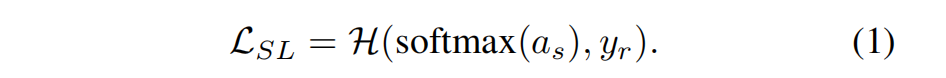

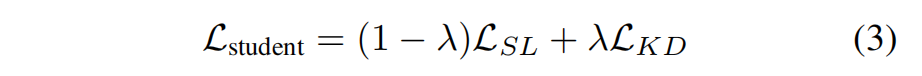
hard loss 与 KL散度的加权(KL散度中包含了soft loss的计算)
对于选取多大的TA模型,文章没有定论,但提到只要是引入中间规模的TA,就能提高学生模型的蒸馏效果。可以简单理解为更加平滑的蒸馏可以提高知识迁移效果。
文章中提到了一种启发式的选择合适的教师助理的方式,及选择“性能“在教师模型与学生模型之间的教师助理,很符合直觉,期待后续研究。
在实际尝试时发现,deepseek模型的token词表和Qwen模型的token词表并不一致,所以传统的蒸馏框架并不适用,但幸运的是读到了deepseekR1发布时的论文,其中提到了“硬蒸馏”的方法,用问答对和推理过程监督微调学生模型可以显著提升学生模型在专业领域的推理能力,而我们专业知识问答和数学能力刚好属于推理能力,所以我们的框架如下:
deepseekR1硬蒸馏Qwen2.5-7B-Instruct,再将监督微调后的 Qwen2.5-7B-Instruct作为教师模型用经典的知识蒸馏方式微调Qwen2.5-1.5B-Instruct。

















 1180
1180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









