







4.1.1 串的定义和基本操作
串,即字符串string,是由0个或多个字符组成的有限序列。一般记为S='asdf......'其中S是串名,单括号括起来的是串的值,字符个数n称为串的长度,n=0时称为空串。
子串:串中任意个连续的字符组成的子序列。
主串:包含子串的串。
字符在主串当中的位置:字符在串中的序号。编号从1开始,和线性表的位序是一样的。
子串在主串中的位置:子串的第一个字符在主串当中的序号。
串其实就是一种线性表,数据元素必须是字符型。
串的基本操作,如增删改查等通常以子串为操作对象。
StrAssign(String&T,chars):赋值操作,把串T赋值为chars.
StrCopy(String&T,S):复制操作,由串S复制得到串T。
StrEmpty(S):判空操作,若S为空,返回true,否则返回false.
StrLength(S):求串长,返回S的元素个数。
ClearString(S):清空操作,清空S为空串。
DestroyString(S):销毁串,将串S销毁(回收存储空间)。
Concat(&T,S1,S2):用T返回由S1和S2连接而成的串。
SubString(&Sub,S,pos,len):求子串。用Sub返回串S的第pos个字符起长度为len的子串。
Index(S,T):定位操作,若主串S中存在与串T相同的子串,则返回它在主串中第一次出现的位置, 否则返回0.
StrCompare(S,T):比较操作。若S>T,返回>0。
4.1.2 串的存储结构
1.串的顺序存储(定长)
#define MaxLen 20
typedef struct {
char ch[MaxLen];
int length;
}SString;串的顺序存储(动态长度)
typedef struct {
char* ch;
int length;
}HString;
HString S;
S.ch = (char*)malloc(sizeof(HString));
S.length = 0;堆分配内存,需要我们手动释放空间。
为了将数组下标和字符位序匹配,我们采取这样的方法:ch[0]废弃不用,在字符串末尾声明一个int型变量表示数组有多长。
串的链式存储:
typedef struct {
char ch;//每个结点存放一个字符
String* next;
}String;这样做有很大的缺点:每一个字符变量只占一个字节,但是我们却多用了4个字节的指针来匹配他,换句话说,存储密度太低了,为此,我们改进这个方案,每一个结点存放4个字符(若不够长,可以用####代替)。
typedef struct {
char ch[4];//每个结点存放一个字符
String* next;
}String;基本操作的实现:
求子串SubString(&Sub,S,pos,len)用Sub返回串S的第pos个字符起长度为len的子串。
bool SubString(String S, String& sub, int pos,int len) {
if (sub + pos - 1 > S.length)//子串范围越界
return false;
for (int i = pos; i < pos + len; i++) {
sub.ch[i-pos+1] = S.ch[i];//我们规定了从数组下标1开始存
}
sub.length = len;
return true;
}字符串的比较StrCompare(S,T)比较操作,若S>T则返回值>0;相等则为0,否则<0。
int StrCompare(String S, String T) {
for (int i = 1; i <= S.length&&i<= T.length; i++) {
if (S.ch[i] != T.ch[i])
return S.ch[i] - T.ch[i];
}
//所有扫描过的都相同,则长度更长的串值大
return S.length - T.length;
}定位操作Index(S,T)若主串中存在与串T值相同的子串,则返回它在主串S中第一次出现的位置,否则函数值为0.
//利用前面实现的两个基本操作,从主串中取出长度为len的子串,依次比较是否相等
int Index(String S, String T) {
int m = S.length; int n = T.length;
int i = 1;
String sub;
while (i <= n - m + 1) {
SubString(S, sub, i, n);
if (StrCompare(sub, T) != 0)
i++;
else return i;
}
return 0;
}4.2.1 朴素模式匹配算法
字符串模式匹配:在主串中找到与模式串相同的子串,并返回其所在的位置。
讲主串中所有长度为m的子串依次与模式串匹配,直到配对或者所有的子串都不匹配为止。
主串长度为n,模式串长度为m,那么主串中长度为m的子串一共有n-m+1个。
int Index(String S, String T) {
int i = 1, j = 1;//双起始指针
while (i <= S.length && j <= T.length) {
if (S.ch[i] == T.ch[j]) {
i++; j++;
}
else {
i = i - j + 2;//注意这个地方容易错
j = 1;
}
}
if (j > T.length)//说明匹配成功了
return i - T.length;
else
return 0;
}时间复杂度O(m(n-m+1))=O(mn)
4.2.2 KMP算法 (难度高,不好理解)
KMP算法核心思想:要利用好模式串中隐含的一些信息,处理好模式串失配时主串的信息。
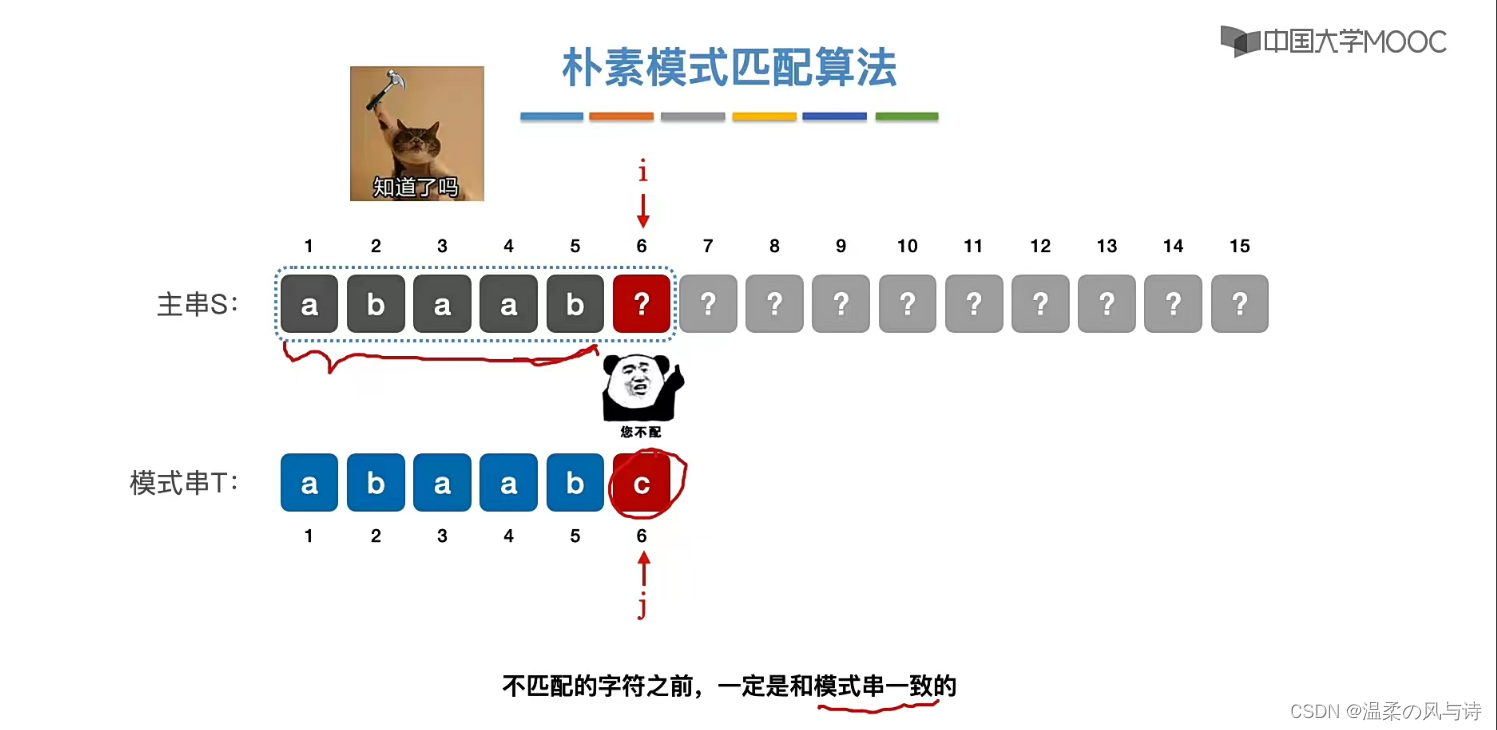
因此,当我们匹配时,前面字符的信息是已知的,朴素模式匹配算法需要从第二个位置再来,如果我们采用KMP算法就可以避免这样。
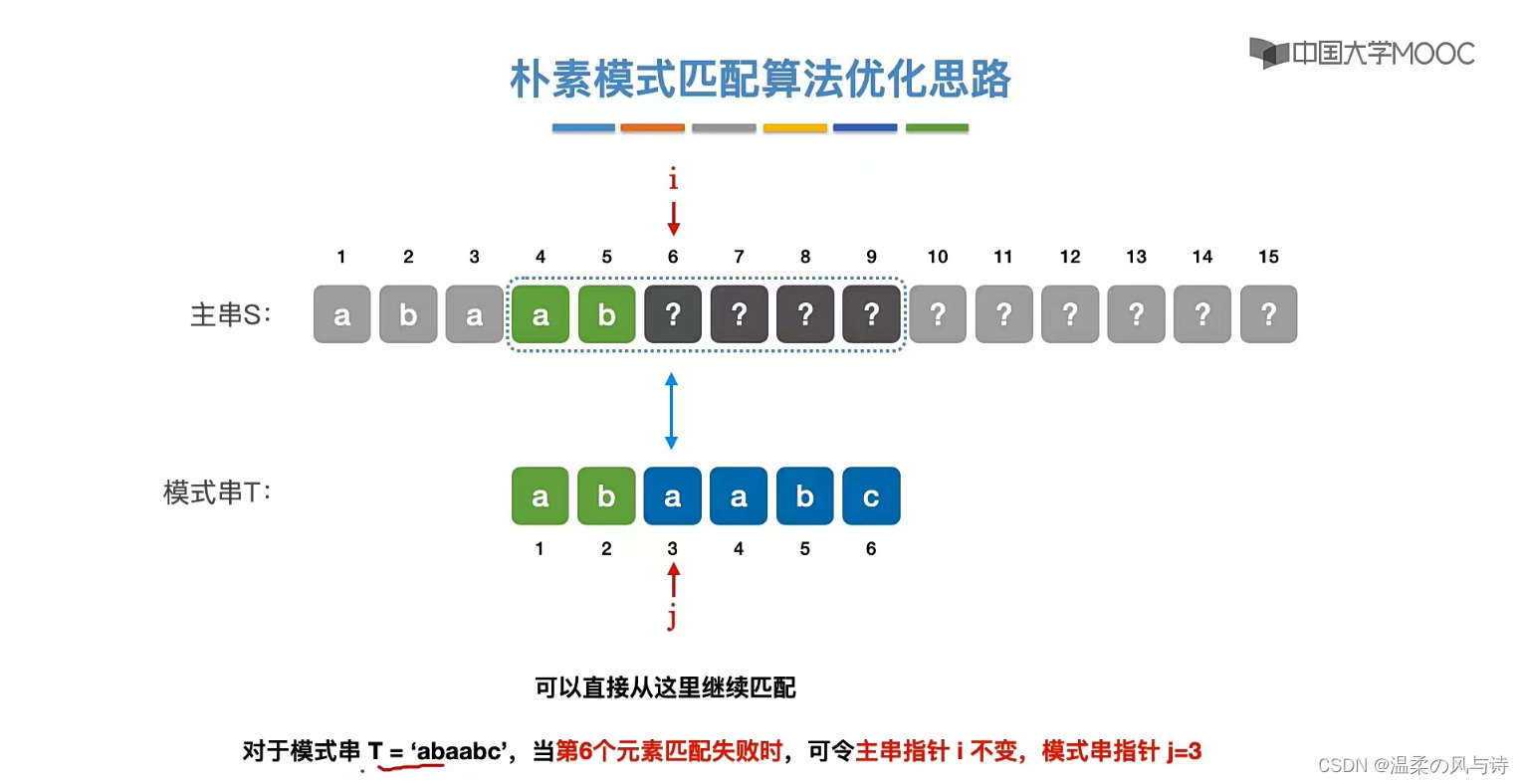
拿这个字符串为例子,我们第六个元素匹配失败时,令j=3,可以直接匹配上。
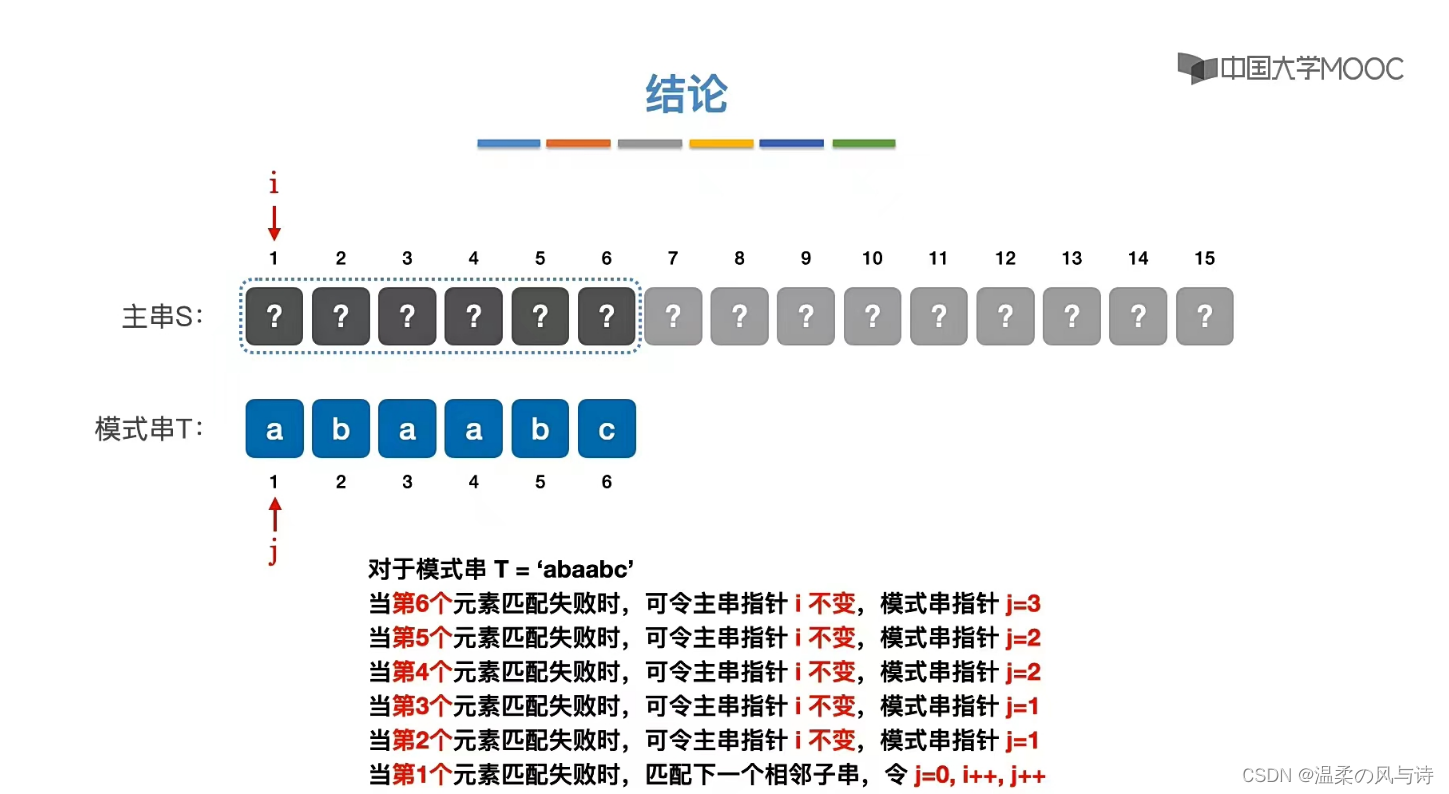
所以如何记录已经匹配的文本内容,是KMP的重点,也是next数组肩负的重任。
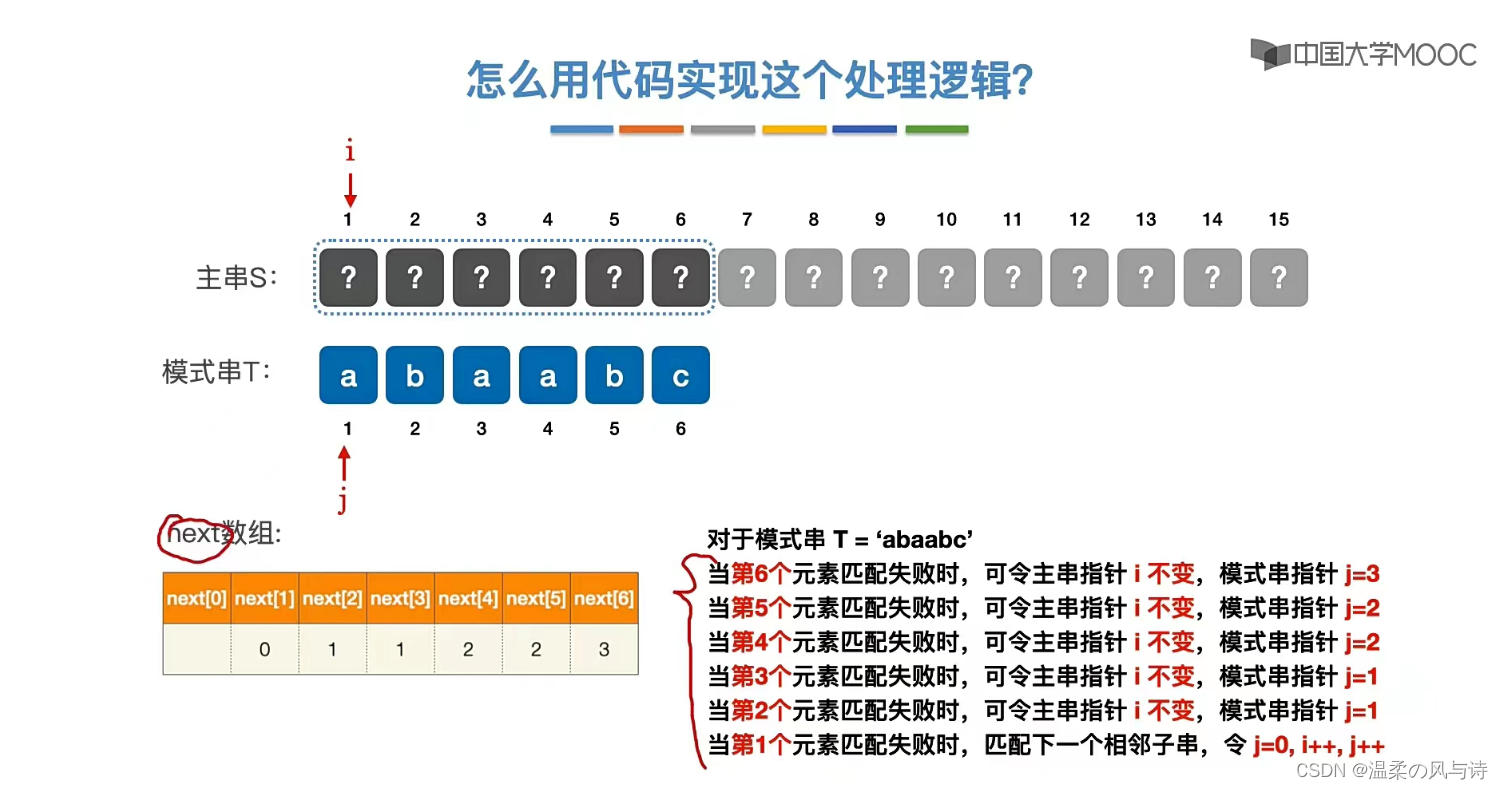
怎么用代码实现这个逻辑?
if(S[i]!=T[j])
j=next[i];
if(j==0){
i++;j++;
}相比于朴素模式匹配算法,KMP算法主串指针不需要回溯。
下面给出KMP算法的流程图:
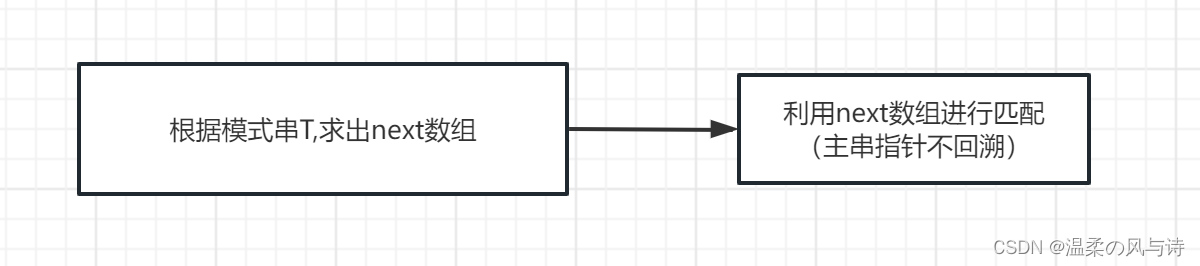
next数组只和短短的模式串有关,和主串无关。
在408考研中,只要求我们能手动求出next数组即可,不要求用代码实现。同时我们要知道KMP算法的流程以及时间复杂度。
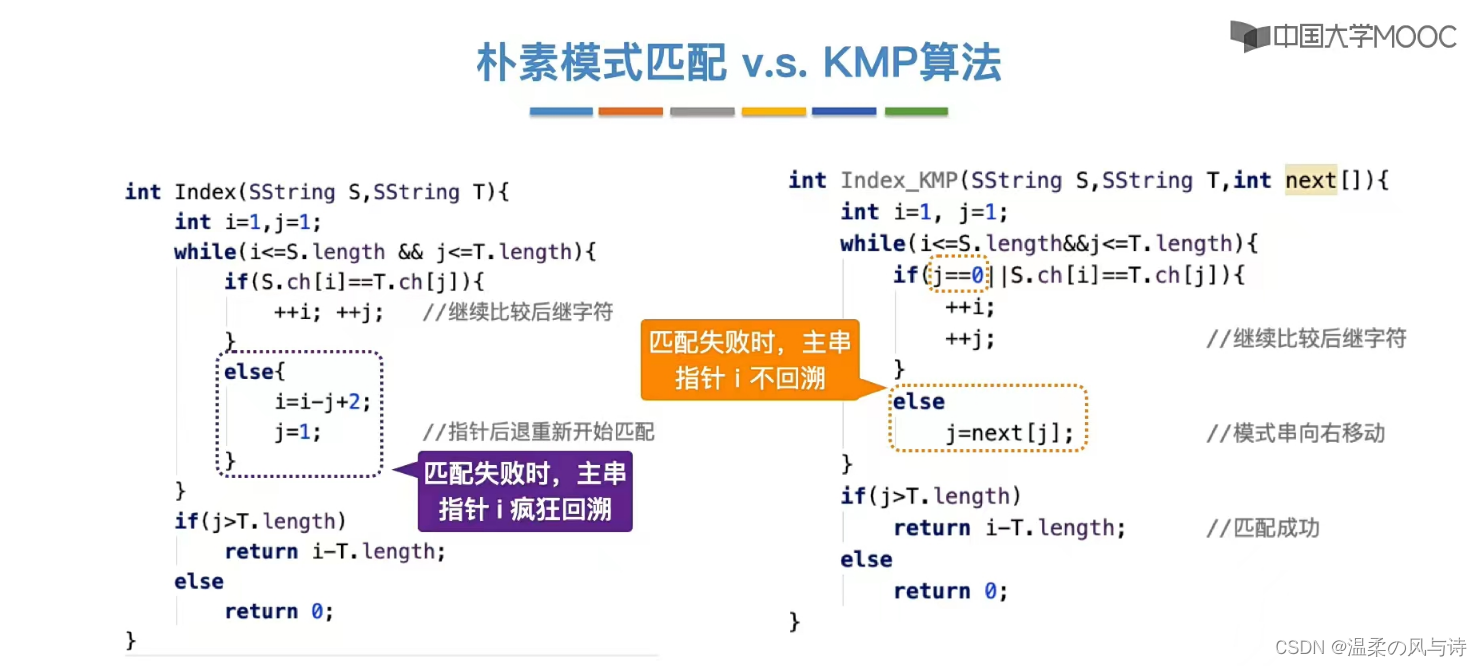
朴素模式匹配算法:最坏时间复杂度O(mn);
KMP算法:最坏时间复杂度O(m+n),其中计算next数组时间复杂度O(m),匹配过程时间复杂度O(n)。
4.2.3 求next数组
1.手算练习
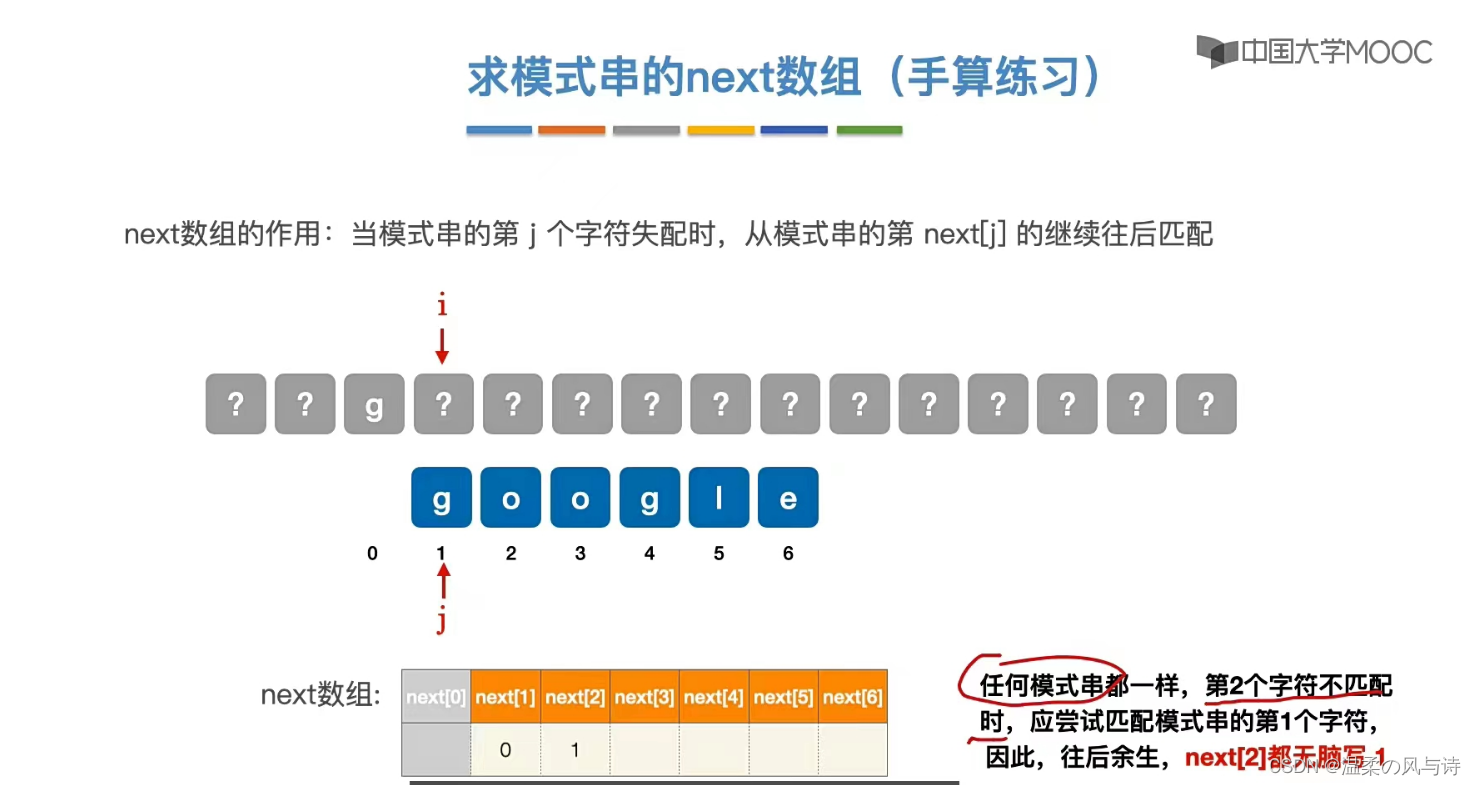
答应我,往后余生,next[0]=0,next[1]=1直接这样写好吗?
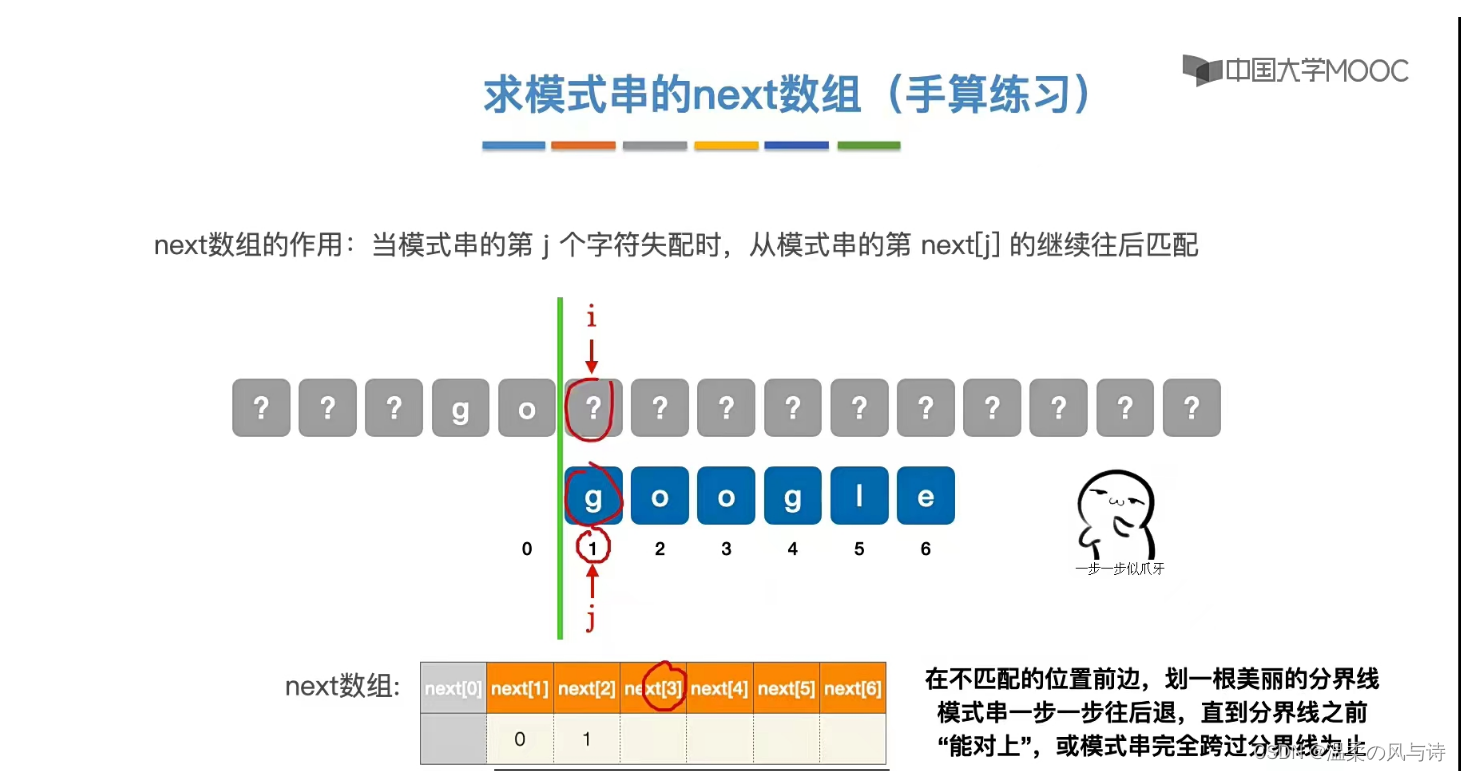
图片中给出了next数组的计算方法:在不匹配位置的前边画一条线,模式串一步步往后退,直到分界线以前都能对上或者模式串完全跨过分界线为止。
 再次说明,408不会出KMP算法大题,也不会代码要求实现next数组,我们需要掌握手算即可。
再次说明,408不会出KMP算法大题,也不会代码要求实现next数组,我们需要掌握手算即可。
4.2.4 KMP算法的进一步优化
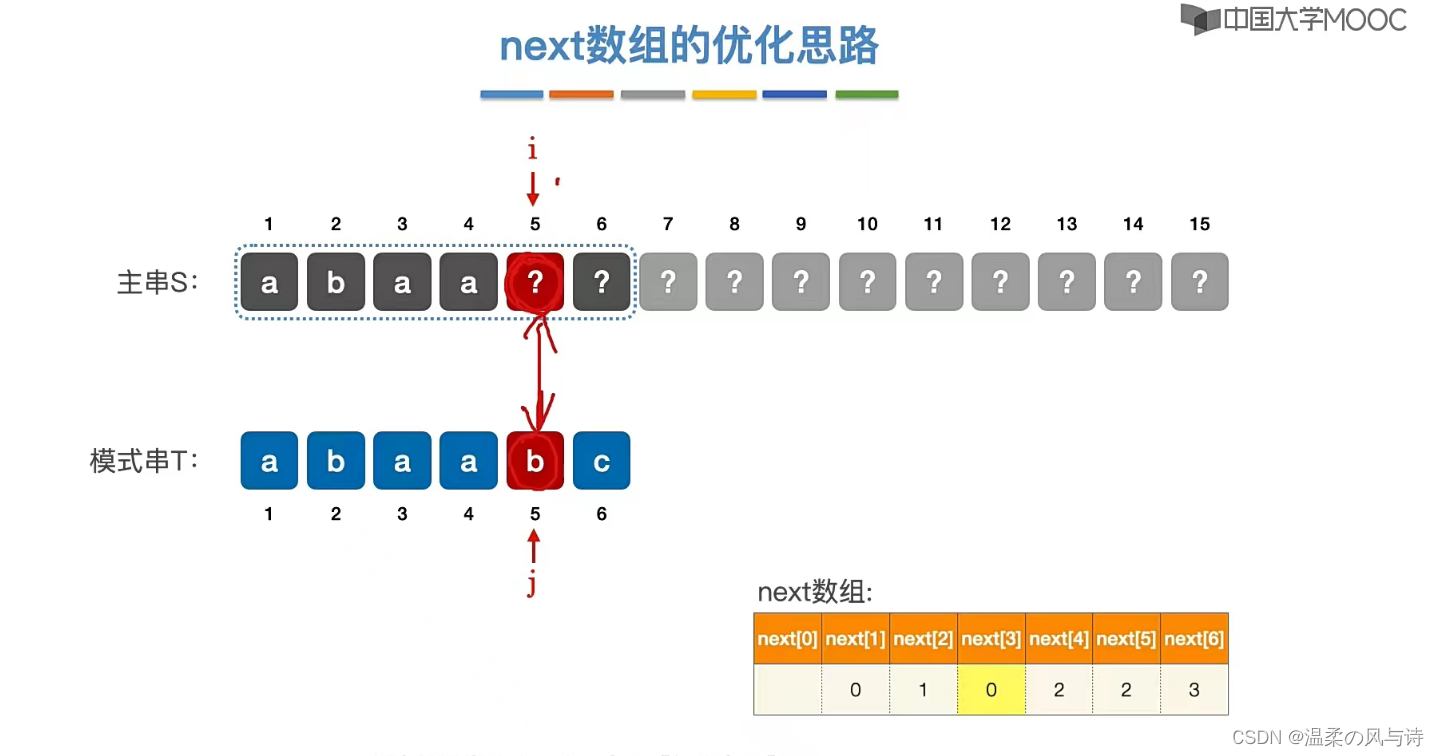
如图所示,我们先求出了next数组,当发现第五个匹配失败时,我们会返回到next[2],但是,第五个匹配失败,我们能得知主串元素一定不是b,现在回到了位置为2的next数组,这不是多此一举吗?因此next数组可以进一步优化, 因此我们更新了nextval数组,用它来作为KMP算法最终的参考。
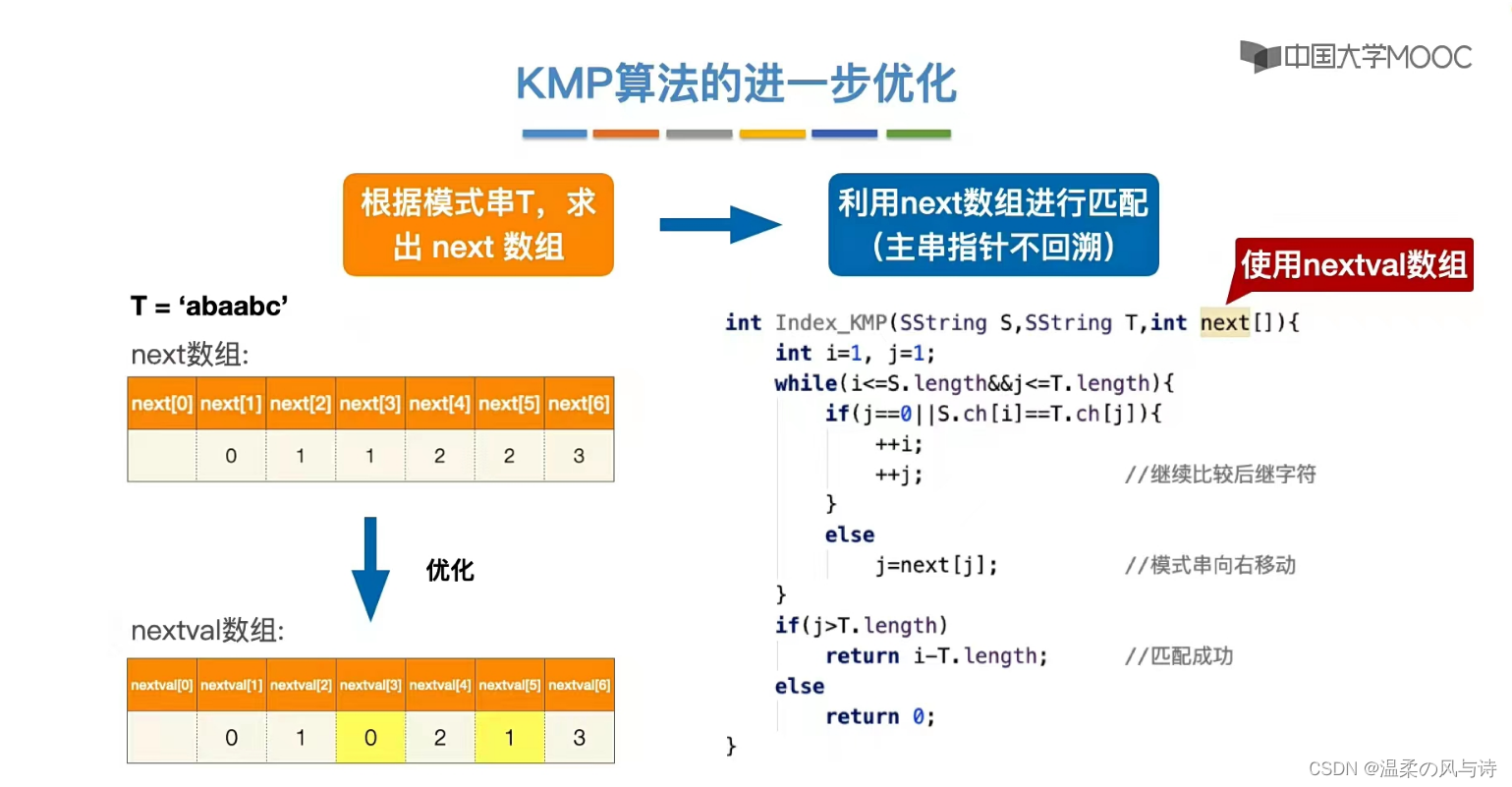

图上给出了nextval数组的求法流程。,我们按照这样的逻辑求出的模式串nextval数组如下:
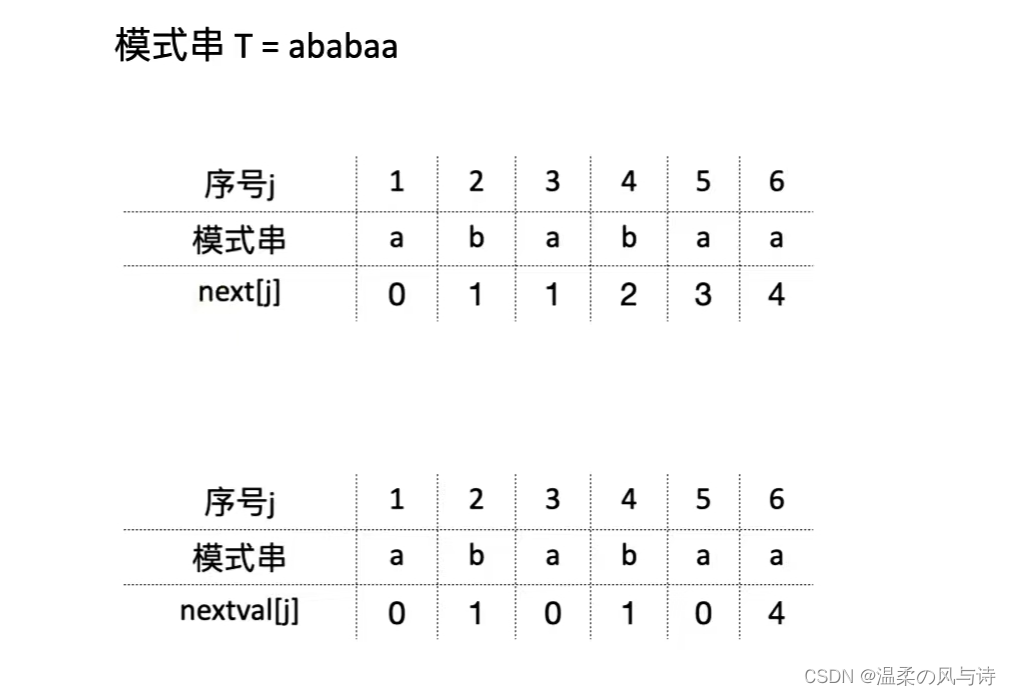
注意本章在考研复习时不必纠结KMP算法的具体实现,如果对KMP算法有更高兴趣,欢迎阅读我的另一篇文章:















 1579
1579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









