







8.1 排序的基础知识
稳定性:序列中出现两个相同关键字时,排序前后二者的相对顺序并没有改变。
排序算法的分类:插入排序、交换排序、选择排序、归并排序、基数排序。
插入排序分为直接插入排序,折半插入排序,希尔排序。
选择排序:简单选择排序、堆排序。
交换排序:冒泡排序、快速排序。
归并排序:二路归并排序、外部排序。
基数排序:最特殊的一种,适用于链表。

注意:下面所说的排序序列,均是非递减排序(非递减不一定等于递增,因为可能出现两个相同的)
8.2 插入排序
8.2.1 直接插入排序
算法思想:将一个待排序的关键字,将其放到已经有序的序列,使得原本的序列仍然保持有序。
void InsertSort(int R[], int n) {
int i, j;
for (int i = 1; i < n; i++)//i从1开始,第一个关键字不用比
{
int temp = R[i];
j = i - 1;
while (j >= 0 && R[j] > temp) {
R[j+1] = R[j];
j--;
}
R[j+1] = temp;
}
}在和ChatGPT交流中,我了解到了swap函数要进行三次赋值,其实远远不如我们自己写的交换元素快,排序算法要想更好的理解,脑子里有个动画是最好的。
书上还给出了一种带哨兵的实现方法(其实我们都知道快不了多少),可以确保每次不用判断j>0.
void InsertSort(int A[], int n) {//带哨兵版本
int i, j;
for (int i = 2; i <= n; i++) {
if (A[i] < A[i - 1]) {
A[0] = A[i];
for (j = i - 1; A[0] < A[j];j--) {
A[j + 1] = A[j];
}
A[j] = A[0];
}
}
}
注意,在简单选择排序中,一趟排序不能确保一个关键字到达最终位置,比如考虑1 2 3 4 0这样一个序列,在排序0之后,所有关键字位置都会发生变化。
最佳时间复杂度:O(n);最坏时间复杂度:O(n²);平均时间复杂度:O(n²)
空间复杂度:O(1) 算法稳定性:稳定
8.2.2 折半插入排序
与直接插入排序思想类似,只不过查找是利用折半查找进行的。

void InsertSort(int B[],int n) {//折半插入排序
int i, j, low,high,mid;
for (int i = 2; i <=n; i++) {
B[0] = B[i];
low = 1; high = i - 1;
while (low <= high) {//折半查找
mid = (low + high) / 2;
if (B[0] < B[mid])
high = mid - 1;
else
low = mid + 1;
}
for (j = i - 1; j >= high + 1; i--) {
B[j + 1] = B[j];
}
B[high + 1] = B[0];
}
}折半查找与直接查找相比,只是查找的次数变少了,但是排序所用的关键字移动次数上还是一样的。
最好时间复杂度O(nlogn),最坏O(n²),平均O(n²),空间复杂度O(1)
8.2.3希尔排序
希尔排序核心思想:先追求序列部分有序,再追求整体有序。

希尔排序的重点在于选择题考点,要分析出不同的增量,每一次排序的结果应该是什么。
希尔排序的时间复杂度分析与增量d的选择有关。
希尔本人建议:每次将增量d除以2向下取整,这样时间复杂度为O(n²)。
另一种方法:1,3,5,9.....2^k+1,此时时间复杂度达到O(n^1.5)
只需要注意两点:增量最后一定为1,并且尽量都是素数。
void ShellSort(int A[],int n) {
int d, i, j;
for (d = n / 2; d >= 1; d /= 2) {//缩小增量
for (i = d + 1; i <= n; i++) {//找到每一次的数组
if (A[i] < A[i - d]) {
A[0] = A[i];//A[0]暂时存一下
for (j = i - d; j > 0 && A[0] < A[j]; j -= d) {//移动位置
A[j + d] = A[j];
}
A[j + d] = A[0];
}
}
}
}希尔排序空间复杂度为O(1)
8.3 交换排序
8.3.1 冒泡排序
最熟悉不过的算法了......从大一用到现在。不过当时傻呆呆的只会两层循环,现在知道了冒泡排序算法结束的标志:在一趟排序过程中没有发生关键字交换。
void BubbleSort(int A[], int n) {
for (int i = 0; i < n - 1; i++) {
bool flag = false;
for (int j = n - 1; j > i; j--) {//一趟排序过程
if (A[i] < A[i - 1]) {
swap(A[j - 1], A[i]);
flag = true;
}
}
if (flag = false)
return;//本次遍历没有发生交换则结束
}
}最好时间复杂度O(n) 最坏O(n²) 平均O(n²),空间复杂度O(1)。
8.3.2 快速排序
这是排序算法的重中之重!不但原理要理解,代码一定要闭着眼睛也能写出来!并且很多开发环境也是用快速排序完成的!
算法思想:

对于快速排序而言,对每一个子序列的一次划分算作一趟排序,每一趟排序之后必然有一个关键字找到了它的位置。
//用第一个元素将待排序序列划分为左右两个部分
int Partition(int A[], int low, int high) {
int pivot = A[0];//第一个元素作为枢轴
while (low < high) {
while (low < high && A[high] >= pivot)high--;
A[low] = A[high];
while (low < high && A[low] <= pivot)low++;
A[high] = A[low];
}
A[low] = pivot;//pivot找到了自己的位置
return low;//返回存放枢轴的最终位置
}
void QuickSort(int A[], int low,int high) {
if (low < high) {//递归终止条件
int pivotpos = Partition(A, low, high);
QuickSort(A, low, pivotpos - 1);
QuickSort(A, pivotpos + 1, high);
}
}待排序列越接近无序,快速排序越快,最好时间复杂度O(nlog2n),如果原本序列有序,并且很多元素都一样(故意恶心你)那么快速排序将非常慢,时间复杂度O(n²).

n个结点的二叉树最小高度=【log2n】+1,最大高度 = n
快速排序算法优化思路:尽量选择可以把数据中分的枢轴元素。
eg:选头、中、尾三个位置的元素,取中间值作为枢轴元素;随机选一个元素作为枢轴元素
后面还会学到许多时间复杂度O(nlog2n)的算法,但是快速排序的系数最小,因此还是它性能最好。
最好空间复杂度O(log2n),最坏空间复杂度O(n)因为调用了递归栈。
快速排序是一种不稳定的算法!
8.4 选择排序
8.4.1 简单选择排序
算法思想:从头到尾遍历,选出最小的一个关键字,然后和第一个关键字交换,如此循环往复。
void SelectSort(int A[], int n) {
for (int i = 0; i < n - 1; i++) {
int min = i;//记录最小元素位置
for (int j = i + 1; j < n; j++) {
if (A[j] < A[min])
min = j;//更新最小元素位置
}
if (min != i)
swap(A[i], A[min]);
}
}空间复杂度O(1) 时间复杂度O(n²),不稳定排序。
8.4.2 堆排序
堆排序和快排一样,是我们考试的重点,重中之重,必须严格掌握!
堆是一种数据结构,可以理解为一棵完全二叉树,这棵完全二叉树满足:根结点的值小于或大于两个孩子结点的值。如果是大于,那么就称之为大根堆,小于就是小根堆。
注意堆和二叉排序树不同,二叉排序树是左<根<右。
回顾一下二叉树的顺序存储,一个结点i,i的左孩子为2i,右孩子为2i+1,父结点为[i/2],i所在的层次为[log2n]+1;

我们现在手上有一个序列a[n],现在要将其转换为一个大根堆。按照定义,我们只需要考虑那些非终端节点是否是三者中最大值即可。
而在完全二叉树中,非终端节点满足i<=[n/2];检查是否满足根>左右,若不满足,将根结点替换为最大值即可。
只不过,在小元素下坠的过程中,有可能导致下一层元素又不满足大根堆的定义了,因此我们需要不断使小元素下坠,使之满足堆的定义。
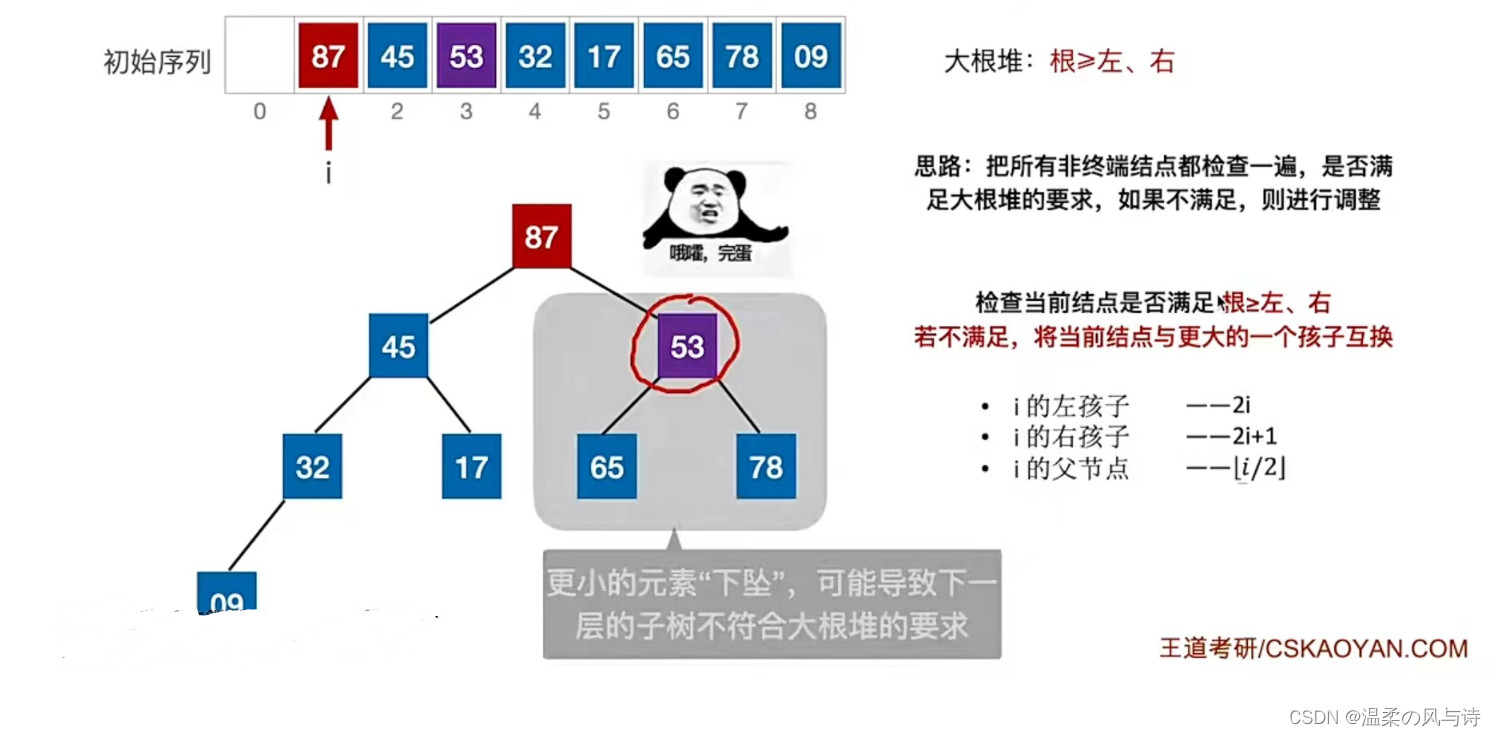
注意我们在序列中,第一个位置A[0]是空着不存的。
//建立大根堆
void BuildMaxHeap(int A[], int len) {
for (int i = len / 2; i > 0; i--)
HeapAdjust(A, i, len);
}
//将以k为根的子树调整为大根堆
void HeapAdjust(int A[], int k, int len) {
A[0] = A[k];//A[0]暂存一下
for (int i = 2 * k; i <=len; i++) {
if (i < len && A[i] < A[i + 1])
i++;//通过这样找到两个孩子值较大的一个
if (A[0] >= A[i])break;//若根结点大则停止
else {
A[k] = A[i];
k = i;//为什么不直接在这里交换?因为有可能还要继续向下筛选
}
}
A[k] = A[0];//被筛选结点的值放入最终位置
}基于大根堆进行排序:
选择排序是每一趟选出一个最大的元素加入有序子序列。
而堆排序指的是每一次都将堆顶元素加入有序子序列(与待排序列最后一个元素进行交换),并将待排序列再次调整为大根堆(小元素不断下坠)。
void HeapSort(int A[], int len) {
BuildMaxHeap(A, len);
for (int i = len - 1; i > 0; i--) {
swap(A[i], A[1]);//堆顶元素和堆底元素互换
HeapAdjust(A, 1, i - 1);//把剩余待排元素整理为堆
}
}算法效率分析:一个结点,如果要下坠,那么关键字对比次数不超过两次。一个编号为i的结点,它所在的层数我们知道是[log2n]+1,那么它下坠层数不会超过h-[log2n]-1层。

故堆排序算法最好最坏时间复杂度均为O(nlog2n),空间复杂度O(1)。堆排序适合用于关键字很多的情况,关键字较少还是不要用堆排序算法。
稳定性:堆排序是不稳定的
8.4.3 在堆中插入删除新元素
以小根堆为例,如果要插入元素,就将该元素直接加入到表尾,如果不满足堆的定义了,那么久开始和父结点互换,新插入的结点就这样不断上升即可。对于删除来说,将删除位置用表尾元素代替,让该元素不断下坠,直到满足堆的定义为止。



下坠过程,如果只有一个孩子,那么只需要下降一层,对比关键字一次。
8.5 归并排序
什么是归并Merge排序?归并,是把多个有序序列合并成一个有序序列的过程。

我们回顾一下双指针法,用i、j两个指针分别指向表头,对比两个指针所指的元素,将较小者加入新的序列,这样不断循环往复。如果一个指针已经指向了NULL,那么就把另一个序列所有元素直接加进来。
考虑2路归并,选出一个最小值需要比较1次。4路归并需要比较关键字3次,因此我们得出结论,M路归并,需要对比关键字次数为m-1.

在内部排序中,一般选择的都是二路归并。

int* b = (int*)malloc(sizeof(int));
void Merge(int a[],int low,int mid,int high) {
int i, j, k;
for ( i = low; i <= high; i++) {
b[i] = a[i];
}
for ( i = low, j = mid + 1, k = i; i <= mid && j <= high;) {
if (b[i] <= b[j]) {
a[k++] = b[i++];
}
else {
a[k++] = b[j++];
}
}
while (i<=mid)a[k++]=b[i++];
while (j<=high)a[k++]=b[j++];
}
void MergeSort(int a[],int low,int high) {
if (low < high) {
int mid = (low + high) / 2;
MergeSort(a, low, mid);
MergeSort(a, mid + 1, high);
Merge(a, low, mid, high);
}
} 
归并排序是一种比较快速的算法,它也是稳定的排序算法。
8.6 基数排序

我们给定十个1000以内的三位数,对他们进行排序。

第一趟先对个位进行排序,初始化10个队列。 不看十位百位。
接着我们按队列顺序收集这十个元素,越先进队的越先出队。

接着我们对十位进行排序,十位相同,个位越大的越先入队。

接着我们继续收集,收集完成对百位进行分配。


我们来看一下基数排序中的术语,:


接下来我们分析复杂度:首先空间复杂度一定是O(r)因为我们初始化了r个队列;
时间复杂度:一次分配肯定需要O(n)时间复杂度,因为要把n个元素全部分配好。
对于一次收集,由于队列指针是连着的,所以只需要O(1)时间复杂度,一共需要r趟收集,故一趟收集时间复杂度O(r)

一共d趟分配收集(d指的是关键字拆为d个部分),故时间复杂度O(d(n+r))
基数排序是稳定算法。
基数排序使用场景:
1.数据元素的关键字可以便地拆分为 d组,且d较小(反例 给身份证排序)
2.每组关键字的取值范围不大,即r 较小(反例 给中文人名排序)
3.数据元素个数 n 较大

8.7 外部排序
外部排序与内部排序不同,内部排序主要是交换元素等时间开销,但外部排序我们一方面要减少元素移动次数,还要格外关注与磁盘的读写次数。磁盘的读写是很慢的。
操作系统以块为单位修改磁盘,磁盘的数据不能直接更改,必须先读入内存,在内存中作出修改之后,再把数据送回磁盘。
对于外部排序而言,我们最常用的算法是归并排序,我们通过对归并排序一步步优化最终实现外部排序的优化。
8.7.1 初始归并排序

初始归并段要求有序,我们每次从磁盘中读出两个块的内容放到缓冲区里,接着进行归并排序,凑够三个数字放回到磁盘里。
因此,构造初始归并段的过程中,我们读写磁盘一共32次,其中读和写各占一半。



第三趟之后我们已经完成排序,接下来我们分析时间开销。

根据时间分析我们得知,最主要的时间开销集中在读写外存上。因此如果读写外存次数减少,归并排序所需的时间开销将大大降低。
读写外存次数与文件总块数和归并趟数有关。
如果我们采取多路归并,就可以降低归并趟数。比如采用四路归并,那么上述过程简化为初始化归并段+二次排序。

但是多路归并也带来新的问题:一是所需的缓冲区增加,内存开销增大。二是关键字比较次数会增加,四路归并需要比较三次关键字。
增加初始归并段长度,就可以减少初始归并段数量。

8.7.2 败者树

败者树:可视为一棵完全二叉树 (多了一个头头)。k个叶结点分别是当前参加比较的元素,非叶子结点用来记忆左右子树中的“失败者”,而让胜者往上继续进行比较,一直到根结点。

此时对于上面这棵树,如果突然来了一个派大星选手,那么冠军需要重新比赛,我们是重新打七场吗?不用!我们只需要让派大星和阿乐打一场,胜利后再和程龙打,如果还胜利和孙悟空打,最终赢了的话派大星就是冠军了。(天津饭已经离开这棵树了)

败者树的考查不是很多,(2024就考了)我们大多数时候会用手动模拟即可,不用代码实现。如果想要代码实现,一般我们是声明数组。

败者树解决的问题:使用多路平衡归并可减少归并趟数,但是用老土方法从 k 个归并段选出一个最小/最大元素需要对比关键字 k-1次,构造败者树可以使关键字对比次数减少到[log2 k]
败者树可视为一棵完全二叉树(多了一个头头)。k个叶结点分别对应 k 个归并段中当前参加比较的元素,非叶子结点用来记忆左右子树中的“失败者”,而让胜者往上继续进行比较,一直到根结点。
8.7.3 置换选择排序



8.7.4 最佳归并树

(归并过程的磁盘I/O次数 )= 归并树的WPL* 2
要使得I/O次数减少,我们可以用——哈夫曼树!

注意:对于k路归并,若初始归并段的数量无法构成严格的 k 叉归并树,则需要补充几个长度为 0 的“虚段”,再进行 k 叉哈夫曼树的构造 。
















 873
873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









