







前面我们保存多个数据使用的是数组,但是数组有很多不足的地方,分析如下:
1.长度开始时必须指定,并且一旦指定,不能更改。
2.保存的必须为同一类型的元素
3.使用数组进行增加的元素的示意代码
集合的理解与好处
1.可以动态保存任意多个对象,使用比较方便
2.提供一系列方便操作对象的方法: add, remove, set, get等
3.使用集合添加,删除新元素的示意代码,
集合的框架体系
java的集合类很多,主要分为两大类:【背】
1.单列集合

2.双列集合

例如:
Collection 接口有两个重要的子接口 List Set,他们的实现子类都是单列集合
Map 接口的实现子类 是双列集合,存放 K-V
Collection接口和常用方法
Collection接口实现类的特点
public interface Collection < E > extends Iterable < E >
1.有些Collection的实现类,可以存放多个元素,每个元素可以是Object
2.有些Collection的实现类,可以存放重复的元素,有些不可以。
3.有些Collection的实现类,有些是有序的(List),有些不是有序的(Set)
4.Collection接口没有直接的实现子类,是通过它的子接口Set 和List 来实现的
以ArrayList来讲解Collection
list.add//添加一个元素
list.remove//删除一个元素
list.clear//删除所有元素
list.set//改变某个元素
list.get//获取某个元素
list.addAll//添加多个元素
list.contain//判断元素是否存在
list.removeAll//删除多个元素
list.isEmpty//判断是否为空
Collection接口遍历元素方式
使用Iterator迭代器
基本介绍:

1.Iterator对象称为迭代器,主要用于遍历Collection集合中的元素(快捷键 itit)
2.所有实现了Collection接口的集合类都有一个Iterator()方法,用以返回一个实现了Iterator接口的对象用以返回一个迭代器。
3.Iterator的结构

4.Iterator仅用于遍历集合,Iterator 本身并不存放对象

显示所有快捷键 ctrl + J
如果希望再次遍历,需要重置迭代器
2.for循环增强
增强for循环,可以替代iterator迭代器,特点:增强for就是简化版的iterator,本质一样,只能用于遍历集合或数组。(底层是迭代器)
快捷键 : I
基本语法:
for(元素类型 元素名 : 集合名或数组名){
访问元素
}
List接口的基本介绍
List接口是Collection接口的子接口
1.List集合类中元素有序(即添加顺序和去除顺序一致),且可重复
2.List集合中的每个元素都有其对应的顺序索引,即支持索引(索引从0开始)
3.List容器中每个元素都对应一个整数型的序号记载在其容器中的位置,可以根据序号存取容器中的元素
4.JDK API中List接口的实现类有:

常用的有:ArrayList、LinkedList和Vector:此三种都可以使用Iterator,增强for和普通for。
List接口的常用方法:
1.在index位置插入语ele元素:
void add(int index , Object ele);
2.从index位置开始将eles中所有元素添加进来:
boolean addAll(int index, Collection eles);
3.获取指定index位置的元素:
Object get(int index);
4.返回obj在集合中首次出现的位置:
int indexOf(Object obj);
5.返回obj在集合中最后一次出现的位置:
int LastIndexOf(Object obj);
6.移除指定index未知的元素,并返回此元素:
Object remove(int index);
7.设置指定index位置元素为ele,相当于替换:
Object set(int index, Object ele);
8.返回从fromIndex到toIndex位置的子集合(前闭后开):
List subList(int fromIndex, int toIndex);
ArrayList底层结构和源码分析
1.permits all elements, including null, ArrayList 可以加入null,并且多个
2.ArrayList 是由数组来实现数据存储
3.ArrayList 基本等同于Vector, 除了 ArrayList是线程不安全的(执行效率)看源码,在多线程情况下,不建议使用ArrayList
ArrayList底层操作机制源码分析(重点,难点)
1.ArrayList中维护了一个Object类型的数组elementData.transient Object[] elementData
transient表示短暂的,表示该属性不会被序列化
2.当创建ArrayList对象时,如果使用的是无参构造器,则初始elementData容量为0,第一次添加,则扩容elementData为10,如需再猜扩容,则扩容elementData为1.5倍
3.如果使用的是指定大小的构造器,则初始elementData容量为指定大小,如需要扩容,则直接扩容elementData为1.5倍
ArrayList的底层操作机制分析案例
创建一个新数组:

执行添加的方法:

modCount++;记录被修改次数,如果elementData大小不够,就调用grow()去扩容
Vector底层结构和源码分析
1.Vector类的定义说明:

2.Vector底层也是一个对象数组,protected Object[] elementData;
3.Vector是线程同步的,即线程安全,Vector类的操作方法带有synchronized

4.在开发中,需要线程同步安全时,考虑使用Vector
Vector底层结构和ArrayList的比较

LinkedList底层结构
LinkedList的全面说明
1.LinkedList底层实现了双向链表和双端队列特点
2.可以添加任意元素(元素可以重复),包括null
3.线程不安全,没有实现同步
LinkedList的底层操作机制
1.LinkedList底层维护了一个双向链表
2.LinkedList中维护了两个属性first和last分别指向 首节点和尾结点
3.每个节点(Node对象),里面又维护了prev,next,item三个属性,其中通过prev指向前一个,通过next指向后一个节点。最终实现双向链表
4.所以linkedList的元素的 添加 和 删除, 不是通过数组完成的,相对来说效率较高。
5.模拟一个简单的双向链表

LinkedList的增删改查
ArrayList和LinkedList的比较
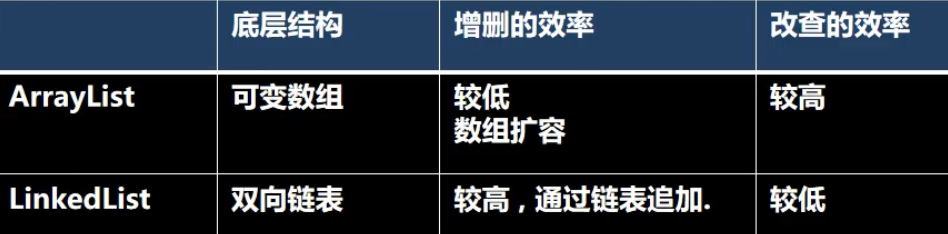
如何选择:
1.如果我们的改查操作较多,选择ArrayList
2.如果我们增删操作较多,选择LinkedList
3.一般来说使用ArrayList较多
4.在一个项目中根据业务灵活选择,也可能一个模块使用ArrayList,另一个模块使用LinkedList,也就是说要根据业务合理选择
Set接口和常用方法
Set接口基本介绍
1.无序(添加和取出的顺序不一致),没有索引
2.不允许重复元素,所以最多只包含一个null
3.JDK API中Set接口的实现类有:

Set接口的常用方法
和List接口一样,Set接口也是Collection的子接口,因此,常用方法和Collection接口一样
Set接口的遍历方式
同Collection的遍历方式一样,因为Set接口是Collection接口的子接口
1.可以使用迭代器
2.增强for
3.不能使用索引的方式来获取(即,无法使用普通for)
HashSet的全面说明
1.HashSet实现了Set接口
2.HashSet实际上是HashMap,看源码:

3.可以存放null值,但是只有一个null
4.HashSet不保证元素是有序的,取决于hash后,再确定索引的结果(即不保证存放元素的顺序和去除元素的顺序是一致的)
5.不能有重复元素/对象。在前面Set接口使用已经讲过了
HashSet底层机制说明
分析HashSet底层是HashMap,HashMap底层是(数组 + 链表 + 红黑树)
分析HashSet 的添加元素底层是如何实现(hash() + equals))
1.HashSet 底层是 HashMap
2.添加一个元素时,先得到hash值 会转成 ->索引值
3.找到存储数据table,看到这个索引位置是否已经存放的有元素
4.如果没有直接加入
5.如果有,调用 equals 进行比较,如果相同,就放弃添加,如果不同添加到最后
6.在Java8中,如果一条链表的元素个数超过 TREEIFY_THRESHOLD(默认是8),并且table的大小 >= MIN_TREEIFY_CAPACITY(默认64位)就会进行树化(红黑树)
源码分析
1.执行HashSet

2.执行add()

//PRESENT = private static final Object PRESENT = new Object();
3.执行put(),该方法会执行hash(Key) 得到key对应的hash值


4.执行 putVal
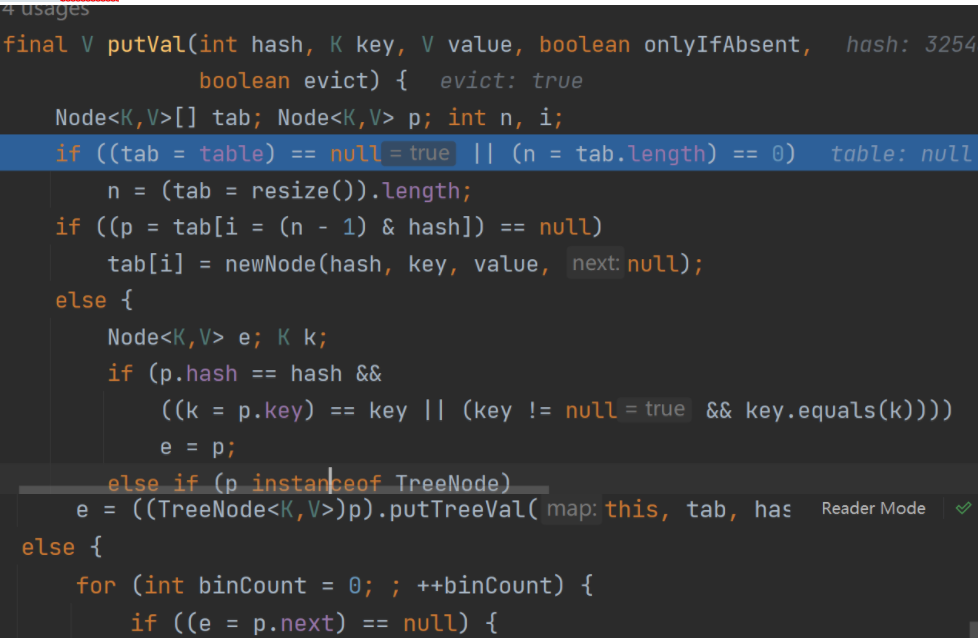
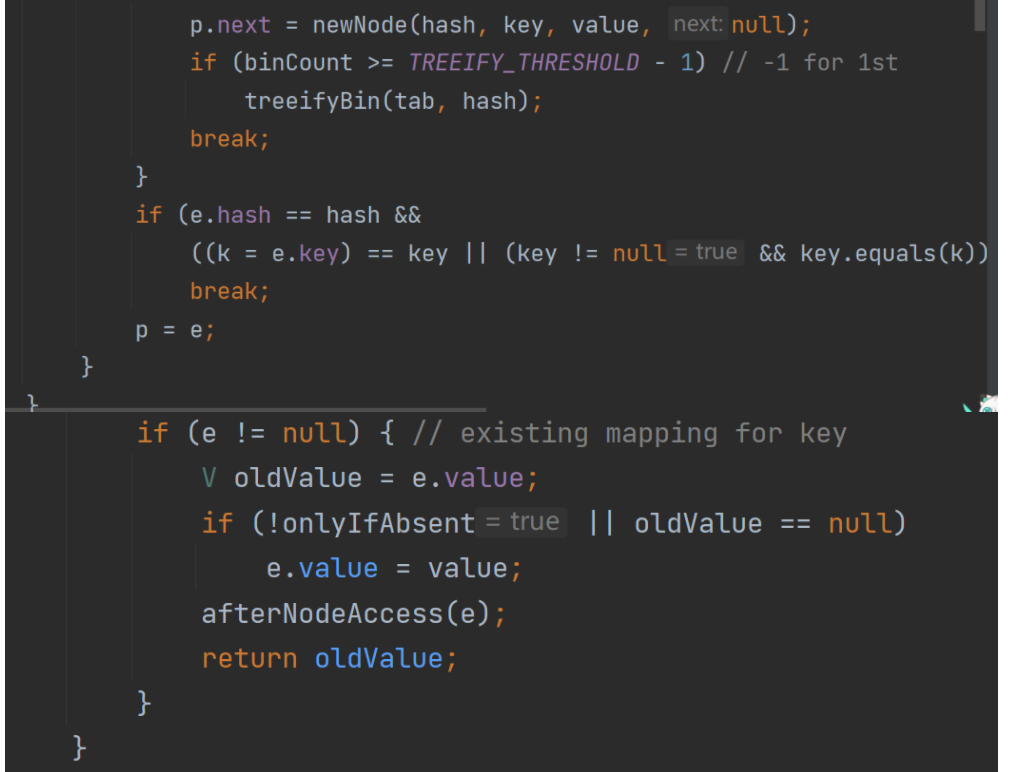
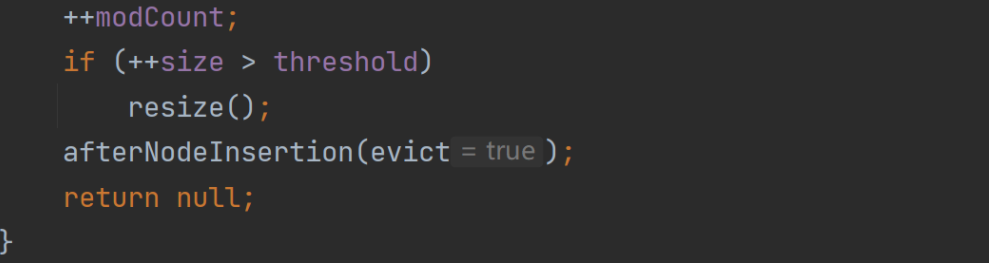

分析HashSet的扩容和转成红黑树机制
1.HashSet底层是HashMap,第一次添加时,table数组扩容到16,临界值(threshold)是16*加载因子(loadFactor)是0.75 = 12
2.如果table数组使用到了临界值12,就会扩容到16 * 2 = 32,新的临界值就是32 * 0.75 = 24,以此类推
3.在Java8中,如果一条链表元素个数到达TREEIFY_THRESHOLD(默认为8),并且table大小 >= MIN_TREEIFY_CAPACITY(默认64位),就会进行树化
<当我们向HashSet增加一个元素, Node 加入table,就算是增加了一个>
Set接口的实现类LinkedHashSet
LinkedHashSet的全面说明
1.LinkedHashSet是 HashSet的子类
2.LinkedHashSet 底层是一个 LinkedHashMap,底层维护了一个数组 + 双向链表
3.LinkedHashSet根据元素 hashCode 值来决定元素的存储位置,同时使用链表维护元素的次序,这使得元素看起来是以插入顺序保存的
4.LinkedHashSet不允许添加重复元素

1.LinkedHashSet 加入顺序和取出元素/数据的顺序是一致的
2.LinkedHashSet 底层维护的是一个LinkedHashMap
3.LinkedHashSet 底层结构(数组table + 双向链表)
4.添加第一次时,直接将 数组table 扩容到16, 存放的节点类型是 LinkedHashMap$Entry
5.数组是HashMap $ Node[]
存放的元素/数据是LinkedHashMap $ Entry
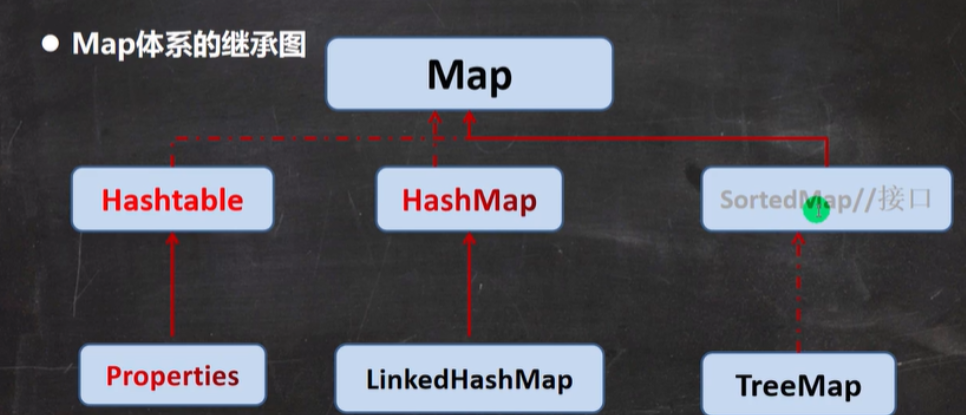
Map接口和常用方法
Map接口实现类的特点
注意:这里讲的是JDK8的Map接口特点
1.Map和Collection并列存在,用于保存具有映射关系的数据:Key - Value(双列元素)
2.Map中的 key 和 value 可以是任何引用类型的数据,会封装到HashMap$Node 对象中
3.Map中的key不允许重复,原因和HashSet一样,当有相同key时,等价于替换
4.Map中的value是可以重复的
5.Map的key可以为null,value也可以为null,注意key为null,只能有一个,value为null可以多个
6.常用的String类作为Map的key
7.key和value之间存在单向一对一关系,即通过指定的key总能找到对应的value
8.Map存放数据的key-value示意图,一对 k-v是放在一个Node中的,有因为Node实现了 Entry接口,有些书上也说 一对k-v就是一个Entry
Map接口的常用方法
1.put:添加
2.remove:根据键删除映射关系
3.get:根据键获取元素值
4.size:获取元素个数
5.isEmpty:判断个数是否为0
6.clear:清除
7.containsKey:查找键是否存在
Map接口遍历方式
1.containsKey:查找key是否存在
2.keySet:获取所有的键

3.entrySet:获取所有关系

4.values:获取所有的值

Map接口实现类HashMap
HashMap小结
1.Map接口的常用实现类:HashMap, Hashtable和 Properties
2.HashMap是以Map接口使用频率最高的实现类
3.HashMap 是以 key- value对的方式来存储数据(HashMap$Node类型)
4.key不重复,但是值是可以重复,允许使用null键和 null值
5.如果添加相同的key,则会覆盖原来的key-value,等同于修改(替换value)
6.与HashSet一样,不保证映射的顺序,因为底层是以hash表的方式来存储的
7.HashMap没有实现同步,因此线程是不安全的
扩容机制[和hashSet完全一样]
1.HashMap底层维护了Node类型的数组table,默认位null
2.当创建对象时,将加载因子(loadfactor)初始化位0.75
3.当添加key - value时通过key的哈希值得到在table的索引。然后判断该索引处是否有元素,如果没有直接添加。如果有,则判断该元素的key是否和准备加入的key相等,如果相等替换value,如果不相等,判断树结构还是链表结构,做出相应处理。如果添加时发现容量不够,则需要扩容。
4.第一次添加将table扩容为16,临界值为12
5.以后扩容,则需要扩容table容量为原来的两倍,临界值为原来的两倍即24,以此类推
6.在Java8中,如果一条链表的元素个数超过了TREEIFY_THRESHOLD(默认是8),并且table大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)
HashTable的基本介绍
1.存放的元素是键值对:即K-V
2.hashtable的键和值都不能为null
3.hashTable使用方法基本上和HashMap一样
4.hashTable是线程安全的(synchronized),HashMap是线程不安全的
HashTable底层
1.底层有数组 Hashtable#Entry[] 初始化大小为11
2.threshould 8 = 11* 0.75
3.扩容:按照自己的扩容机制来进行
4.执行 方法 addEntry(hash key, value, index);添加 K-V 封装到Entry
5.当 if(count >= threshould)满足时,就进行扩容
HashMap和HashTable对比

Properties
1.Properties类继承自Hashtable类,并且实现了Map接口,也是使用一种键值对的形式来保存数据
2.他的使用特点和Hashtable类似
3.Propertices 还可以用于 从 xxx.properties 文件中,加载数据到Properties类对象,并进行读取和修改
4.说明:工作后 xxx.properties 文件通常作为配置文件,这个知识点在IO流举例,

Collections 工具类
Collections工具类介绍
1.Collections 是一个操作 Set,List 和 Map 等集合的工具类
2.Collections 中提供了一系列静态方法对集合元素进行排序,查询,修改等操作
排序操作方法
1.reverse(List):反转 List 中元素的顺序
2.shuffle(List):对List集合元素进行随机排序
3.sort(List):根据元素的自然顺序对指定的List 集合元素按升序排序
4.sort(List, Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
5.swap(List, int, int):将指定 List 集合中 i 处元素和 j 处元素进行交换
6.Object max(Collection):根据元素中自然排序,返回集合中的最大元素
7.Object max(Collection, Comparator):根据Comparator 指定顺序,返回给定集合中的最大元素
8.Object min(Collection)
9.Object min(Collection, Comparator)
10.int frequency(Collection, Object):返回指定集合中指定元素的出现次数
11.void copy(List dest, List src):将src中指定数据复制到dest中
12.boolean replaceALL(List list, Object oldVal, Object newVal):使用新值替换 List对象的所有旧值

//学习资源来自b站韩顺平30天学Java
















 1703
1703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











