







最近在给某大型游戏公司调试Wi-Fi,具体的硬件平台信息如下所示:
| Processor | 6 nm AMD APU CPU: Zen 2 4c/8t, 2.4-3.5GHz (up to 448 GFlops FP32) GPU: 8 RDNA 2 CUs, 1.6GHz (1.6 TFlops FP32) |
| Wi-Fi | Qualcomm QCA2066 Tri-band Wi-Fi 6E radio, 2.4GHz, 5GHz, and 6GHz 2 x 2 MIMO IEEE802.11a/b/g/n/ac/ax |
| Kernel Version | 6.1.x |
| Wi-Fi Driver | ATH11K |
到这里,大家应该能猜到是那个项目,hahaha...。没错,就是如你所想的那样,Valve的最新一代Steam Deck OLED:Steam Deck™
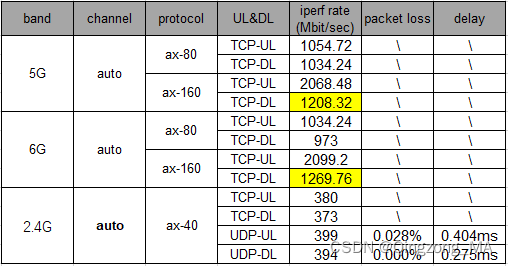
言归正传,回归到我们的问题点:客户在进行5G/6G 160Mhz带宽下的TPUT测试,按照理论计算2.4G(具体为啥是2.4G,可以查看:WLAN物理层速率计算方式_wlan速率计算公式-CSDN博客) x (0.7 ~ 0.8) = (1.68G ~ 1.92G),但是我们实际测试结果DL的速率只能达到1.2+G左右(具体如下图所示),这明显无法满足标准。
基于此,我们着手开始排查问题的原因。在看到问题那一刻,我们按照正常的排查思路(所谓的三板斧),首先怀疑的第一点是:系统的调度资源是否满足?
所使用的工具是mpstate(关于mpstate工具的使用方法,各个平台都有很多介绍,可以自行搜索学习,这里不做过多的描述),果然不出所料,进行Rx TPUT测试时,系统的软中断100%,系统idle为0%,具体如下图所示:
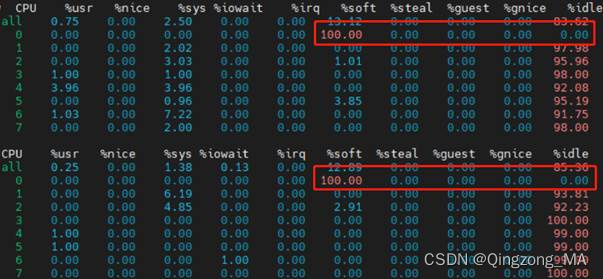
此时我们暂时不去追究更多的细节问题,首先从上图可以看出:表象原因是系统资源不够了。到此,我们是不是无处着手,先不着急,需要用到我们的另一大法:对比排除法。
因为我们在kickoff此项目之前,已经在Intel X86 ubuntu18.04平台上进行过我们Wi-Fi平台的性能摸底,所以肯定Wi-Fi芯片的能力是足够的,所以我们首先想到的是:是不是内核配置有差异?
最后确定差异点是:AMD平台上的IOMMU被关闭了(这其中如何发现IOMMU的这里不做详细描述,真的是一语难尽啊,做了大量的数据测试,真是一把辛酸泪)。
排查到这里,可终于让人轻松了一把,我们以为使能IOMMU就能解决此问题,开开心心,写了一长篇的邮件(从如何发现问题,如何排查,如何解决此问题)给Valve客户(以此来邀功),可是打脸的总是那么及时,很快心就凉了一截。Valve客户给我们的反馈是不能打开IOMMU,因为他们要使用GPU,IOMMU是降低GPU的性能。所以解决此问题还得另辟蹊径。
紧急召开了AMD/Qualcomm/Valve/我司的一个四方会议(巴拉巴拉的一堆英语,有时候听个半懂),最后定位到是DMA的mapping因为关闭了IOMMU,所以在进行数据转发时耗费了大量的软中断。
这里关于DMA mapping的相关知识,请参考此链接:Dynamic DMA mapping Guide — The Linux Kernel documentation。
我们在进行Rx TPUT的时候,使用的DMA是Streaming DMA mappings方式,此方式的DMA mapping是通过IOMMU进行的,因为我们把IOMMU关闭掉了,所以才会使用软中端进行mapping。所以,这里引出一个思考点:为什么会进行地址的mapping呢?我们有没有办法让它不要进行软中断的mapping呢?
要不说Qualcomm的东西虽然贵但是好用呢,这不就找到方法了么:
由于此前我们将Wi-Fi PCIe的DMA MASK设置到了32位,所以能寻址的范围为0~4G,但是因为Rx TPUT时,socket buffer的随机性,很大概率会分配大于4G以上的内存地址,此时就需要进行地址的转换,那如果IOMMU是使能的话,这个活就不需要CPU的参与了,但是好巧不巧,IOMMU是被关闭的,所以这个事情就只能交给CPU处理,这不就让CPU很吃力嘛,但是没办法,必须干啊,不干就没办法进行Rx了。
这时候我们想到,如果不让进行地址的转换,那就不就解决此问题了么:Qualcomm的强大这时候就体现出来了,人家的Wi-Fi芯片支持36bit的DMA MASK,地址访问范围从0~4G一下子提升到了0~64G,也就不需要进行地址转换了,只要使能Wi-Fi芯片PCIe接口的36bit DMA MASK完美解决问题。
复测的Rx TPU结果如下所示:
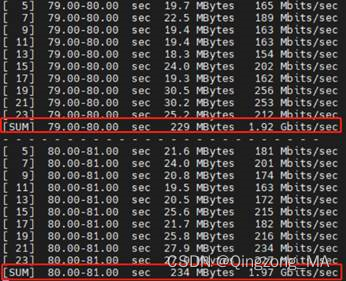
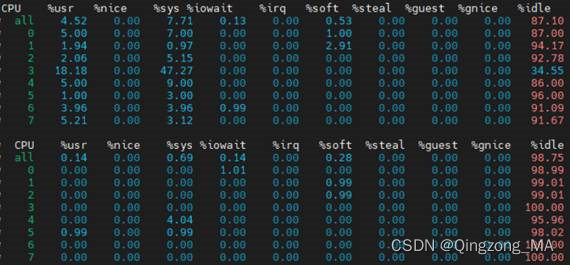
复测的CPU资源占用结果如下所示:

















 580
580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









