查看Hadoop目录内容
[atguigu@hadoop102 hadoop-3.3.4]$ ll
总用量 92
drwxr-xr-x. 2 atguigu atguigu 203 7月 29 2022 bin
drwxr-xr-x. 3 atguigu atguigu 20 7月 29 2022 etc
drwxr-xr-x. 2 atguigu atguigu 106 7月 29 2022 include
drwxr-xr-x. 3 atguigu atguigu 20 7月 29 2022 lib
drwxr-xr-x. 4 atguigu atguigu 288 7月 29 2022 libexec
-rw-rw-r--. 1 atguigu atguigu 24707 7月 29 2022 LICENSE-binary
drwxr-xr-x. 2 atguigu atguigu 4096 7月 29 2022 licenses-binary
-rw-rw-r--. 1 atguigu atguigu 15217 7月 17 2022 LICENSE.txt
-rw-rw-r--. 1 atguigu atguigu 29473 7月 17 2022 NOTICE-binary
-rw-rw-r--. 1 atguigu atguigu 1541 4月 22 2022 NOTICE.txt
-rw-rw-r--. 1 atguigu atguigu 175 4月 22 2022 README.txt
drwxr-xr-x. 3 atguigu atguigu 4096 7月 29 2022 sbin
drwxr-xr-x. 4 atguigu atguigu 31 7月 29 2022 share
在Hadoop目录下创建wcinput文件夹
[atguigu@hadoop102 hadoop-3.3.4]$ mkdir wcinput
[atguigu@hadoop102 hadoop-3.3.4]$ cd wcinput/
创建word.txt用于存放原始数据
[atguigu@hadoop102 wcinput]$ vim word.txt
[atguigu@hadoop102 wcinput]$ cd ../
[atguigu@hadoop102 hadoop-3.3.4]$ pwd
/opt/module/hadoop-3.3.4
调用自带的mapreduce程序进行统计
[atguigu@hadoop102 hadoop-3.3.4]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount wcinput/ wcoutput
2024-03-25 23:52:58,766 INFO impl.MetricsConfig: Loaded properties from hadoop-metrics2.properties
2024-03-25 23:52:58,826 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
2024-03-25 23:52:58,826 INFO impl.MetricsSystemImpl: JobTracker metrics system started
2024-03-25 23:52:59,129 INFO input.FileInputFormat: Total input files to process : 1
2024-03-25 23:52:59,146 INFO mapreduce.JobSubmitter: number of splits:1
2024-03-25 23:52:59,247 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local17770842_0001
2024-03-25 23:52:59,247 INFO mapreduce.JobSubmitter: Executing with tokens: []
2024-03-25 23:52:59,442 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
2024-03-25 23:52:59,443 INFO mapreduce.Job: Running job: job_local17770842_0001
2024-03-25 23:52:59,459 INFO mapred.LocalJobRunner: OutputCommitter set in config null
2024-03-25 23:52:59,480 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2
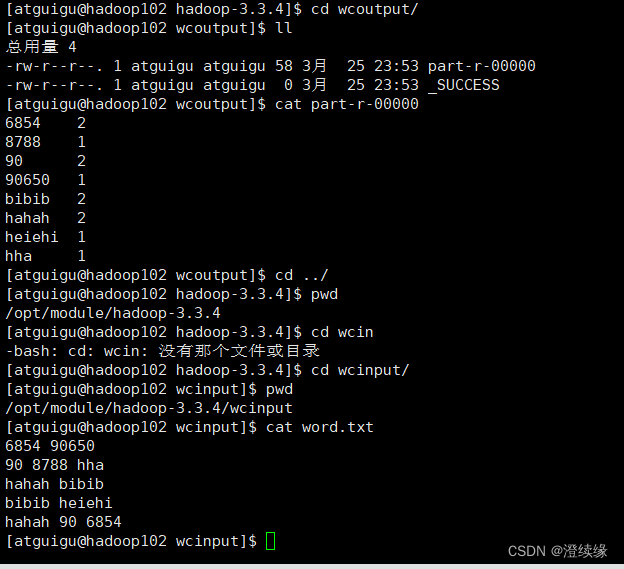
执行结束后查看统计结果
[atguigu@hadoop102 hadoop-3.3.4]$ cd wcoutput/
[atguigu@hadoop102 wcoutput]$ ll
总用量 4
-rw-r--r--. 1 atguigu atguigu 58 3月 25 23:53 part-r-00000
-rw-r--r--. 1 atguigu atguigu 0 3月 25 23:53 _SUCCESS
part-r-00000 为统计结果
[atguigu@hadoop102 wcoutput]$ cat part-r-00000
6854 2
8788 1
90 2
90650 1
bibib 2
hahah 2
heiehi 1
hha 1
[atguigu@hadoop102 wcoutput]$ cd ../
[atguigu@hadoop102 hadoop-3.3.4]$ pwd
/opt/module/hadoop-3.3.4
[atguigu@hadoop102 hadoop-3.3.4]$ cd wcinput/
[atguigu@hadoop102 wcinput]$ pwd
/opt/module/hadoop-3.3.4/wcinput
原始内容如下
[atguigu@hadoop102 wcinput]$ cat word.txt
6854 90650
90 8788 hha
hahah bibib
bibib heiehi
hahah 90 6854
[atguigu@hadoop102 wcinput]$
























 4058
4058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









