







 Storm的Ack机制确保数据正确处理,通过acker任务跟踪spout发出的每个tuple。当acker接收到完整处理的tuple树响应时,发送ack给spout;否则触发fail。 Ack也可用于限流,基于pending数限制spout发送速度。开启Ack机制涉及设置messageId、缓存tuple、重写fail和ack方法等,关闭则不指定MessageID或设置acker数为0。
Storm的Ack机制确保数据正确处理,通过acker任务跟踪spout发出的每个tuple。当acker接收到完整处理的tuple树响应时,发送ack给spout;否则触发fail。 Ack也可用于限流,基于pending数限制spout发送速度。开启Ack机制涉及设置messageId、缓存tuple、重写fail和ack方法等,关闭则不指定MessageID或设置acker数为0。
一、Ack是什么
为了保证数据能正确的被处理, 对于spout产生的每一个tuple, storm都会进行跟踪。
ack机制即, spout发送的每一条消息:
在规定的时间内,spout收到Acker的ack响应,即认为该tuple 被后续bolt成功处理
在规定的时间内,没有收到Acker的ack响应tuple,就触发fail动作,即认为该tuple处理失败,
或者收到Acker发送的fail响应tuple,也认为失败,触发fail动作
通过Ack机制,spout发送出去的每一条消息,都可以确定是被成功处理或失败处理, 从而可以让开发者采取相应动作。
另外Ack机制还常用于限流作用: 为了避免spout发送数据太快,而bolt处理太慢,常常设置pending数,当spout有等于或超过pending数的tuple没有收到ack或fail响应时,跳过执行nextTuple, 从而限制spout发送数据。
二、Ack原理
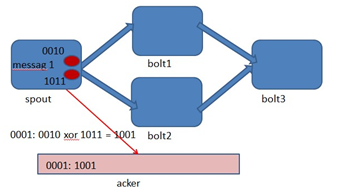
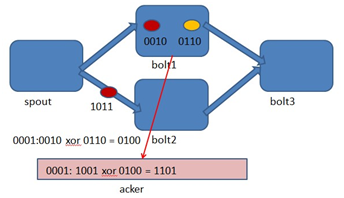
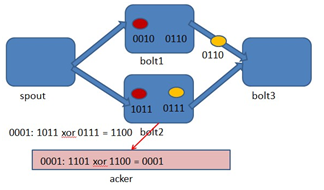
Storm中有个特殊的task名叫acker,他们负责跟踪spout发出的每一个Tuple的Tuple树(因为一个tuple通过spout发出了,经过每一个bolt处理后,会生成一个新的tuple发送出去)。当acker(框架自启动的task)发现一个Tuple树已经处理完成了,它会发送一个消息给产生这个Tuple的那个task。对任意大的一个Tuple树,storm只需要恒定的20字节就可以进行跟踪。acker对于每个spout-tuple保存一个ack-val的校验值,它的初始值是0,然后每发射一个Tuple或Ack一个Tuple时,这个Tuple的id就要跟这个校验值异或一下,
并且把得到的值更新为ack-val的新值。那么假设每个发射出去的Tuple都被ack了,那么最后ack-val的值就一定是0。Acker就根据ack-val是否为0来判断是否完全处理,如果为0则认为已完全处理。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









