







 本文介绍了决策树算法,包括信息增益与ID3,信息增益率与C4.5,以及基尼指数与CART决策树算法。讨论了如何通过熵和基尼指数来衡量节点纯度,并阐述了决策树的剪枝处理,特别是后剪枝算法,通过设置剪枝系数以防止过拟合。
本文介绍了决策树算法,包括信息增益与ID3,信息增益率与C4.5,以及基尼指数与CART决策树算法。讨论了如何通过熵和基尼指数来衡量节点纯度,并阐述了决策树的剪枝处理,特别是后剪枝算法,通过设置剪枝系数以防止过拟合。
一、决策树算法
决策树算法是一种逼近离散函数值的方法。它是一种典型的分类方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。
决策树算法的核心思想就是通过不断地决策来筛选出最终想要的结果,来看下面一个例子:
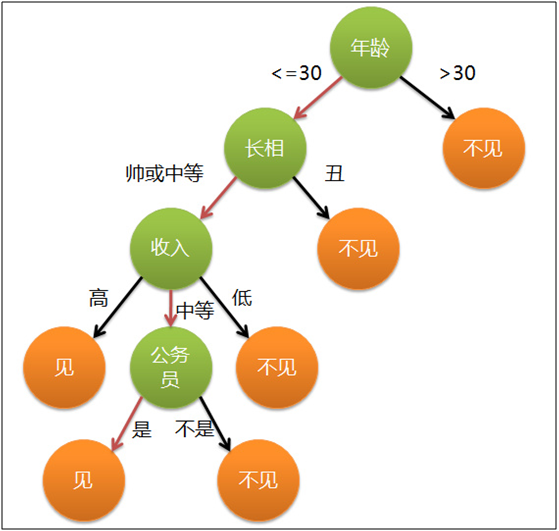
上图是一个女孩相亲中确定见不见男方的过程,她先根据年龄筛选,年龄大于30 的不见,小于30的看长相;长相丑的不见,不丑的见……然后就一直这样筛选直到确定见或者不见。
决策树的基本算法如下:

决策数的生成是一个递归的过程,在决策树基本算法中,有三种情形会导致递归返回:(1)当前节点所包含的样本均属于同一个类别,无需划分(2)当前节点在所有属性上取值相同或者没有属性,无法划分(3)当前节点所包含的样本集为空,不能划分。上述算法是一个递归的过程,情形二和情形三都是到了叶节点不能再划分的情况。情形二和情形三稍有不同,情形二是利用当前节点的后验分布,情形三是利用当前节点父节点的先验分布。
决策树划分选择的依据是信息熵。当数据没有分类时,信息熵是比较大的,分类完成时信息熵比较小,所以是一个熵减小的过程。为了使算法收敛的最快,就要选取使熵减小最快的划分。决策数的典型算法有ID3,C4.5,CART等,下面分别来说一下这三个算法。
信息增益与ID3决策树算法
ID3算法使用信息增益做为划分选择。一般而言,我们希望决策树所包含样本尽可能属于同一类别,即节点"纯度"越来越高。
信息增益表示在得知某一个特征A的情况下,使得某一类X的不确定性减少的程度。比如知道了西瓜的某一特征之后(如敲击响度),就能增大对它属于某一类瓜(好瓜、坏瓜等)的判断,信息增益就是用来度量这个增大程度的。
定义特征A对给定的训练数据集D的信息增益为g(D,A)
g(D,A)=H(D)-H(D|A)
H(D)、H(D|A)分比为经验熵和经验条件熵。经验熵为从实际样本中根据经验估计(如极大似然估计)得到的熵,经验条件熵类似。
上述公式的含义为信息增益等于当前熵减去在知道特征A的情况下的熵,这也就是信息增益的定义。
因为经验熵H(D)的计算公式为:
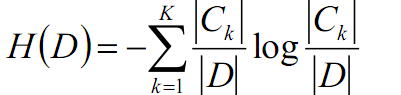
其中k为某一类的个数,Ck为特征类,D为训练数据集,Ck/D即为第k类样本在所有数据集中的比重。(这里k用的有点混淆,k即代表了类别的总个数,也代表了某一类别,希望读者不要混淆)
经验条件熵的推导过程为:
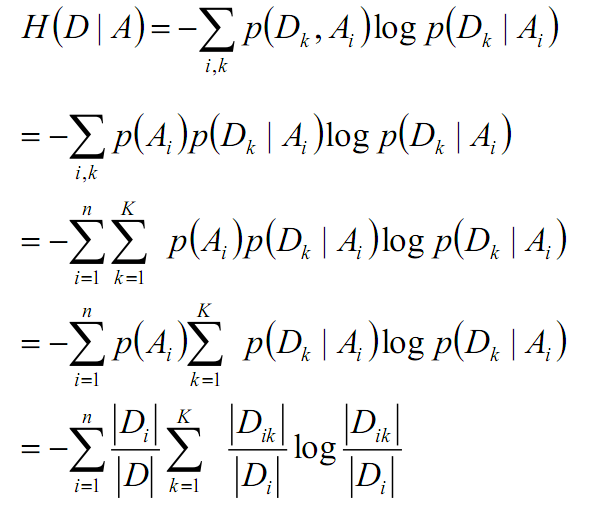
上式的后半部分(后一个累加和后)即为经验熵的公式。
所以分别把H(D)和H(D|A)的计算公式带入到信息增益的计算公式即可得信息增益的计算公式。
信息增益率与C4.5决策树算法
C4.5算法采用信息增益率来进行划分。因为使用信息增益对可取值较多的属性有所偏好(因为在假定信息熵水平大致相等情况下,属性可取的值越多,以为这划分出更多的类别,所以每个类别占总体的比例变比较小,这样计算出来的H(D|A)较小,信息增益较大),为减少这种偏好可能带来的影响,C4.5算法采用增益率选择划分最优属性,增益率的定义如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









