







官方文档:http://scrapy-chs.readthedocs.io/zh_CN/0.24/
XPATH:http://www.w3school.com.cn/xpath/xpath_functions.asp
牛人博客:http://blog.csdn.net/column/details/younghz-scrapy.html
Scrpay的运行过程:
(1)Engine从Spider中获取一个需要爬取的URL(从spider中start_url获取),并以Request的形式在Scheduler中列队。
(2)Scheduler根据列队情况,把Request发送给Downloader,Downloader根据Request请求网页,并获取网页内容。
(3)网页内容以Response的形式经过Engine发送给Spider,并根据用户解析生成Item,发送给Pipeline。
(4)Pipeline根据获得的item和settings中的设置,处理item(process_item)把数据输出到文件或是数据库中。
python 爬虫教程:http://python.jobbole.com/81361/
163.邮箱:http://www.cnblogs.com/xiaowuyi/archive/2012/05/21/2511428.html
使用Scrapy爬取知乎网站:http://blog.javachen.com/2014/06/08/using-scrapy-to-cralw-zhihu.html
知乎论坛相关的爬虫内容:https://www.zhihu.com/question/20899988
Python开发爬虫常用库:https://www.douban.com/group/topic/39919487/?type=like
read doc: https://readthedocs.org/projects/selenium-python-docs-zh/
入门实战
以人民网军事深阅读栏目为例子,爬取相关文章的标题和时间
- 建立爬虫的项目工程.
在开始爬取之前,您必须创建一个新的Scrapy项目。 进入您打算存储代码的目录中,运行下列命令:
scrapy startproject people该命令将会创建包含下列内容的 people 目录:
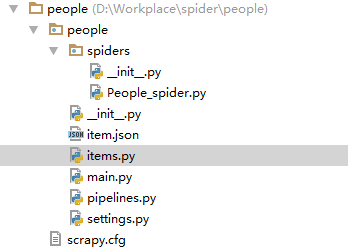
scrapy.cfg:项目的配置文件
people/:该项目的python模块
people/items.py:项目的item文件,定义你要爬取的内容,dict_like,看源码就知道,可以直接按照字典的形式操作。
people/piplines.py:负责负责解析Item、将item存进数据库或者其他文件
people/spiders:放置爬虫代码的目录。People_spider.py自己建立的
定义Item:
item 是保存爬取到的数据的容器;其使用方法和python字典类似, 并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
import scrapy
from scrapy import Field,Item
class PeopleItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=Field()
pub_date=Field()
编写第一个爬虫(Spider)
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。
其包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成 item 的方法。
为了创建一个Spider,您必须继承 scrapy.Spider 类, 且定义以下三个属性:
- name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
- start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
- parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
import scrapy
from scrapy import Request
from bs4 import BeautifulSoup
from people.items import PeopleItem,paper_Item
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor as sle
class People_Spider(CrawlSpider):
name='people'
domain=['people.com.cn']
junshi_url='http://military.people.com.cn/GB/367530/'
start_urls=[
"http://military.people.com.cn/GB/367530/index%s.html" %i for i in xrange(1,5)
]
## rules是匹配的是start_urls页面里面的网页。只要匹配就按照parse_item的方式进行解析,还有其他的deny,tags等参数。
rules = [
Rule(sle(allow=("/n\d/\d{4}/\d{4}/.{15}html",)),callback='parse_item'),
#Rule(sle(allow=("/tag/$", )), follow=True),
]
# def parse(self, response):
# # print response.url
# items=PeopleItem()
# sel=BeautifulSoup(response.body)
# titles=sel.find('div',class_='p2_left d2_left fl').find_all('li')[1:]
# for title in titles:
# items['title']=title.a.text
# items['title_link']=title.a['href']
# items['date']=title.i.text
#
# yield items
def parse_item(self,response):
print response.url
paper=BeautifulSoup(response.body)
Item_p=paper_Item()
Item_p['title']=paper.find('h1',id='p_title').text
Item_p['pub_date']=paper.find('span',id='p_publishtime').text
yield Item_ppipelines.py
import json
import csv
import codecs
class PeoplePipeline(object):
def __init__(self):
self.file=codecs.open('item.json','wb',encoding='utf-8')
def process_item(self, item, spider):
line=json.dumps(dict(item),ensure_ascii=False)+'\n'
self.file.write(line)
# csvfile=csv.writer(self.file)
# csvfile.writerow(tuple(line))
return item
def spider_closed(self, spider):
self.file.close()
setting.py
ITEM_PIPELINES = { #数字表示优先级
'people.pipelines.PeoplePipeline': 300,
#'doubanmovie.pipelines.RedisPipeline': 301,
}
LOG_LEVEL = 'INFO'
DOWNLOAD_DELAY = 1
自己建立以个main.py ,方便在pycharm下调试。
#codeing:utf-8
from scrapy import cmdline
cmdline.execute('scrapy crawl people'.split(' '))爬取的结果:
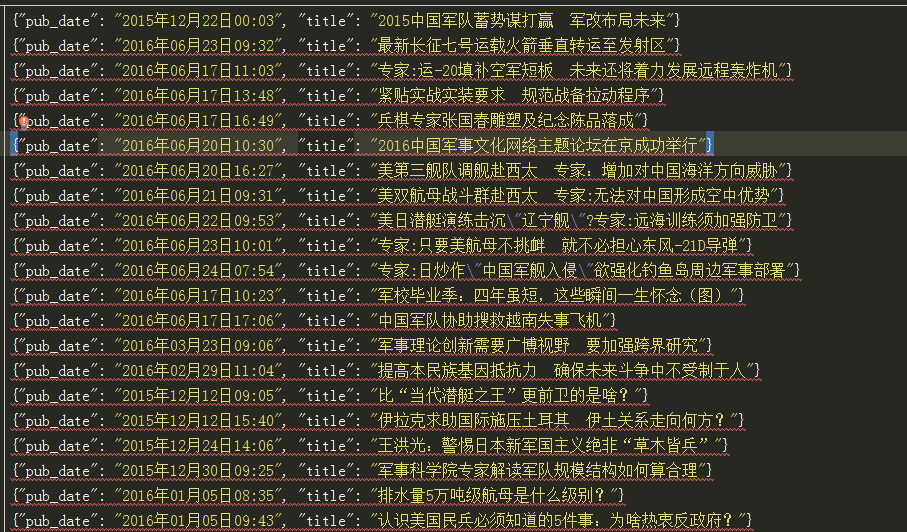















 1035
1035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









