







简单的爬虫,用到的知识点:
1、代理服务器
2、多线程
需要提高的:
1、分布式机制
#encoding=utf8
import os
from bs4 import BeautifulSoup
import urllib2
from multiprocessing import Pool
import random
def proxys():
proxy_cont=open("proxy_ronng_avi.txt")
proxy_list=proxy_cont.read().split('\n')
proxy_cont.close()
return proxy_list
def opener(url,proxy):
User_Agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0'
header = {}
header['User-Agent'] = User_Agent
proxy_support = urllib2.ProxyHandler(proxy) # 注册代理
# opener = urllib2.build_opener(proxy_support,urllib2.HTTPHandler(debuglevel=1))
opener = urllib2.build_opener(proxy_support)
urllib2.install_opener(opener)
req = urllib2.Request(url,headers=header)
response=urllib2.urlopen(req,None)
return response
def crawl_ip(page):
print page
User_Agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0'
header = {}
header['User-Agent'] = User_Agent
for proxy in proxys():
proxy={"http":proxy}
url = 'http://www.xicidaili.com/nn/' + str(page)
try:
response = opener(url,proxy)
soup = BeautifulSoup(response)
ips = soup.find_all('tr')
except Exception as e:
continue
with open("proxy.txt",'a+') as f:
for x in range(1,len(ips)):
ip = ips[x]
tds = ip.find_all("td")
ip_temp = tds[1].contents[0]+"\t"+tds[2].contents[0]+"\n"
# print ip_temp
# print tds[2].contents[0]+"\t"+tds[3].contents[0]
f.write(ip_temp)
print "final"
break
#seq是类列表的格式
def randomSelect(seq):
length=len(seq)
randIndex=random.randrange(length)
randItem=seq[randIndex]
return randItem
def proxyOfAvi(proxy):
ip = proxy.split('\t')[0]
print "Now %s is running" %proxy
flag = os.system('ping -n 3 -w 3 %s' % ip)
if flag == 0:
with open("proxy_avi.txt", "a+") as pro:
pro.write(proxy + '\n')
def Topic(word):
proxyAvi=[]
ask_hrefs=[]
page=1
proxys_list = proxys()
while page:
if len(proxyAvi)==0:
proxy_host=randomSelect(proxys_list)
proxy={"http":proxy_host.split('\t')[0]}
else:
proxy=randomSelect(proxys_list)
url = "http://www.rong360.com/ask/tag/" + word + "?q=&pn=" + str(page)
try:
response = opener(url,proxy)
url_con = BeautifulSoup(response)
except Exception as e:
if proxy in proxyAvi:
del proxyAvi[proxyAvi.index(proxy)]
# print e
continue
try:
pageflag = url_con.find("div", class_="page")
ask_list=url_con.find("ul", class_="search_list")
pageflag = int(pageflag.find_all('a')[-2].string)
ask_page_herfs = [line["href"] for line in ask_list.find_all("a")]
except Exception as e:
continue
else:
print "Now %s is crawl %d pages" % (word, page)
proxyAvi.append(proxy)
print "Proxy_list length is %d" %(len(proxyAvi))
if pageflag > page:
page += 1
else:
page = 0
yield ask_page_herfs
# ask_hrefs.extend(ask_page_herf)
# return ask_hrefs
def ansOfCont(ask_href):
try:
b=BeautifulSoup(urllib2.urlopen(ask_href))
ask_title = b.find("h2",class_="title reply_question_title clearfix").text.encode('utf-8')
ask_text=b.find_all("div", class_="reply_content")
ask_text = [ask_title+"\t"+line.text.encode('utf-8')+"++" for line in ask_text]
except Exception as e:
ask_title=""
return ask_title
def to_txt(word,ask_texts):
'''
ask_texts is a structure which like list,array
:word: filename
'''
with open("%s.txt" % word.decode('utf-8'), "a+") as f:
print ask_texts
print type(ask_texts)
if isinstance(ask_texts,list):
f.writelines(ask_texts)
else:
f.write(ask_texts)
def crwalProxy_main():
pagelist = range(298, 1011)
pool = Pool(8)
pool.map(crawl_ip, pagelist)
pool.close()
pool.join()
def AviProxy_main():
proxys_list = open("proxy.txt").read().split('\n')
pool = Pool(8)
pool.map(proxy_Avi, proxys_list)
pool.close()
pool.join()
def rong_Crawl(word):
# wordlist=["利息咨询"]
ask_hrefs = Topic(word)
ask_cont_list=map(ansOfCont,ask_hrefs)
to_txt(word,ask_cont_list)
def rong_mian():
wordlist = ['常用知识', "利息咨询", "无抵押贷", "抵押贷款", "按揭贷款", "担保咨询", '信用卡', '消费贷款', '经营贷款', '买车贷款', '买房贷款']
pool=Pool(8)
pool.map(rong_Crawl,wordlist)
pool.close()
pool.join()
if __name__=="__main__":
rong_mian()
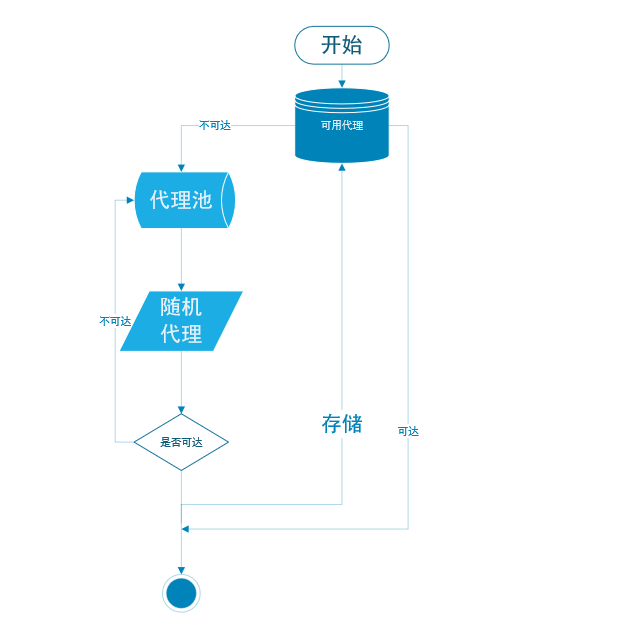
流程示意:















 2927
2927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









