






obsidian是一款笔记管理软件,更是一种笔记管理平台。如果你使用过R,一定会知道R社区提供了大量的R包来使得R的应用范围越来越广,这就是平台软件的优势。Obsidian也是具备一个开放的第三方插件市场,用户能根据自己的需求开发不同的插件,并分发给其他具备同样需求的用户。
Obsidian还能帮助用户构建网站,想象一下一个课题组把各种项目的进度信息都聚合在一个网站上,可以方便PI管理,也有利于提高交流效率。
管理自己的试验项目
使用笔记管理软件的需求是在着手的项目越来越多的时候产生的。试想,本科的时候处理的数据不过几个图标,放在一个文件夹里面可能就够了。研究生阶段会产生很多需要记录的信息:我的某个小实验进度到哪了? 被某些事情中断的项目想要继续有时候不仅要解决数据与材料的问题,甚至相关知识都记不清楚了。如果你记忆力很强大,那么…让我羡慕嫉妒恨吧。
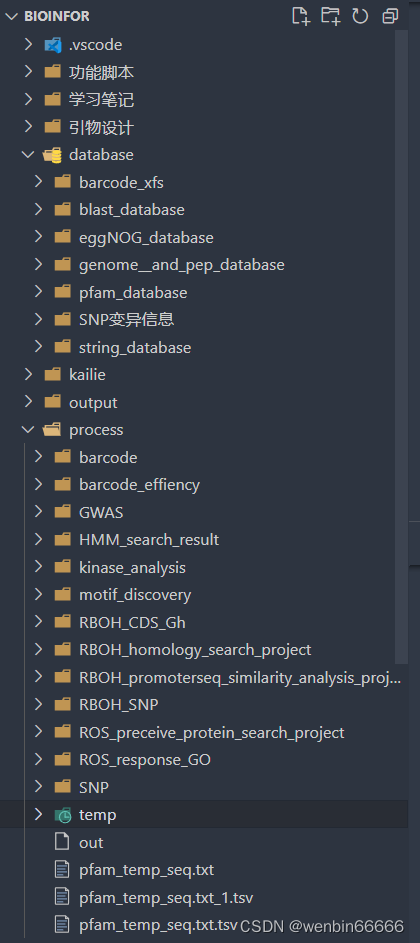
obsidian与windows资源管理器展示文件的差异
以我的bioinfor的文件夹为例,这里面储存了生物信息相关的数据与结果。在obsidian里,我可以查看或选中database和process两个文件夹下面的任意文件,而在windows资源管理器中,你每次只能查看一个吧。所以从文件的检索上,这种树状格式的效率是更高的。当你需要处理多个项目时,这种树状结构的需求就很强了。
一篇文章是一个一个小实验组成的,在你同步进行这些试验时,将一个大项目拆解成一个个小项目,我相信是更有利于你做计划的。做计划,也是一种能力。
项目管理建议
如果你是一个PI,那么你可能从事多个不相关的项目,如果你是一个graduated students,那么你可能只是管理一个项目下的多个实验,那么你们文件夹构建方式一定是不同的。
如果你只是简单管理几个试验的话,你只需要在根目录下根据试验名称来建立几个文件夹就可以了。当然,我相信如果管理的内容很少的话,你是不会愿意花时间与精力学习Obsidian的。可能,学习的动力与兴趣也是环境“胁迫”出来的。
一个简易的项目结构如下,这也是很多人推荐的结构。
/project name #项目名称
/rawdata #原始数据
/process #分析过程产生的文件,分析代码等,初步的结果等,根据项目复杂程度决定是否建立子目录来分类管理
/result #达到发表级别的图表与描述
/temp # 存储临时文件
作为一个入门级选手,大可先建立几个简单的文件夹,随着“财富”的不断积累,平滑地优化自己的项目结构。实际上,我目前也是这么搞的。
看到这里,你基本上可以和windows资源管理器说拜拜了。最后,还是要说明Obsidian与windows资源管理器是完全兼容的,你可以像之前一样用windows资源管理器来访问Obsidian建立的项目目录。尝试把Obsidian的根目录建立在一个云文件夹下,那么是不是可以方便地进行跨设备操作?
去根据自己的需要规划自己的管理结构吧,多多尝试并向大家分享你发现的好东西。
一体化你的浏览器与写作应用
浏览器一般采用标签页来允许你在同一个窗口下浏览多个网页,试想一下,如果能在浏览器添加一个允许你做记录的标签页是不是会很方便?如果可以快速地通过笔记来定位原始的pdf文件,那对深度阅读用户来说简直太美妙了。
如何实现边浏览网页边写作:在Obsidian中使用插件sufring,即可通过添加新的标签页来访问新的网址,你可以不断地将新获取的知识添加到笔记,把重要还未阅读的网页添加到笔记仓库,方便以后迅速地获取信息,有效避免了工作终端对信息获取的影响。
如下图,左侧是笔记信息栏,右侧是网页,第一行展示的两个标签页中,一个是我正在编辑的文档,另一个是实时阅读的HTML网页。进一步的,Obsidian也提供了插件允许你直接将网页保存在本地,不过在有网络的时候,我们只需要简单制作一个外部链接就可以了。
一个界面上保留太多标签页太丑了,如何快速的创建一个指向网页的链接来方便我未来查看:你在你做笔记的文件中来记录未来要做的阅读,当然可以专门准备一个文本来记录这种信息,实际上,我们往往一篇文献还没有读完,我们已经迫不及待要阅读这篇文章引用的10篇文章了。因此设计一个专门的文档来分类的保存要阅读的文献是有必要的,曾经我是利用powerpoint来记录的,现在似乎可以抛弃这种工作模式了,毕竟现在桌面放不下两块屏幕。
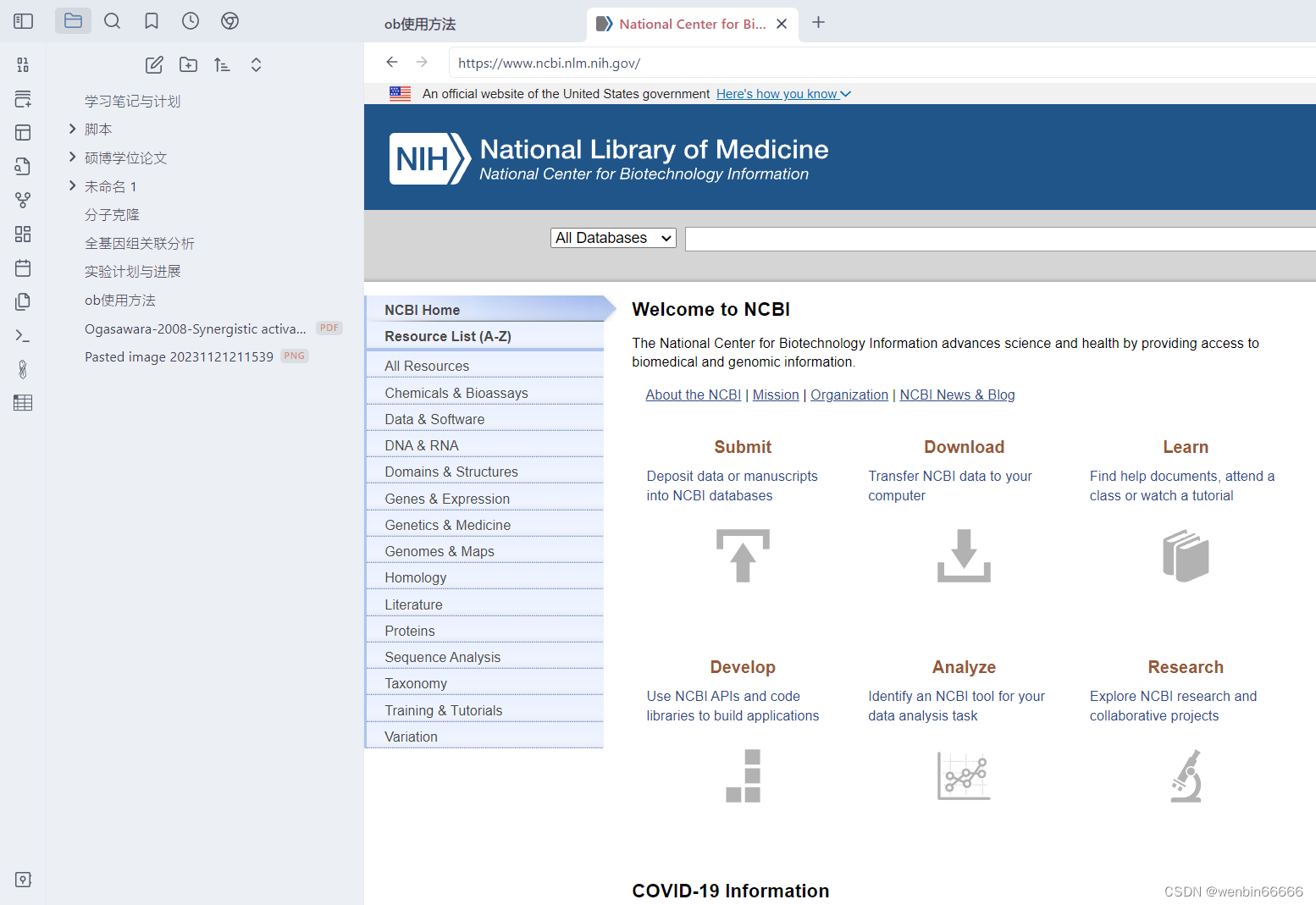
在一个文本文件中,你可以使用[].()语法来记录网站信息,如 [NCBI官方网站].(https://www.ncbi.nlm.nih.gov/);现在看看,是不是可以直接跳转到NCBI。如果你想在windows系统默认浏览器访问此链接,只需要按住Ctrl再用鼠标左键单击网址就可以了。当然,这个在word中也是可以实现的。那么直接在链接处允许你浏览网页呢?Word就不行了吧。来看看Convert a URL into iframe插件的功能,这个插件允许你不打开一个新的标签页来浏览网页,甚至播放网页上的视频,想象一下,在word的上一行还是自己编辑的文本,从下一行开始就可以浏览网页了,是不是很强大?在此插件打开的网页中,也可以使用Alt+鼠标左键来跳转到MicrosoftEdge。实际上,边写作边浏览pdf也是可行的。实际上,这个插件的缺点速度不够,浏览本地的pdf我想还是足够了。
总结 阅读与写作必须要同时进行,否则往往看了等于没没看。使用obsidian的基础功能就能允许你在同一个界面上实现浏览器+word+powerpoint,能够帮助你快速的在阅读、写作、记录中切换。 快去学习如何构建适合自己的工作区吧。
处理pdf文件
对于文献阅读,回想一下我曾经的工作模式。先在网站上查到文献,把pdf下载到本地,导入到endnote,用WPS阅读与标记。WPS有一个很好用的功能,那就是划词翻译。有道词典也集成了划词翻译,但是往往影响键盘的输入。这样考虑,对于一个喜欢在本地工作的人来说,把浏览器与写作集成还不够让人满足,如果能把pdf阅读也集成到一个平台就好了。obsidian能够打开pdf文件,但是我们能够脱离endnote等文献管理软件吗?
再描述一下需求:我希望能够在obsidian中顺利的检索文献条目并打开pdf文件,将阅读与写作集成在一个窗口下,obsidian能够将我在pdf上做的高亮与标记自动整理在笔记系统里面。
我们只好想一个点子了:
模仿Endnote在/文献目录下,为每一个topic建立一个子目录,在这个子目录中储存一个文件,存放文献的信息。然后把pdf在本地的地址链接到文献的信息上。我们可以把endnote的pdf数据库就设置在Obsidian的附件目录内,这样集成度会更高一些。
如果是刚开始着手建立文献库,这个方法可能还行。但是对于在endnote中已经存放了几千篇文献的人,总不能让他们一条条来重构自己的文献库吧。
另一个文献管理Zotero提供了与obsidian数据互通的接口,允许共享pdf的标注信息,那么可能要从endnote转向Zotero了?
不过在最后写论文时,依然不能抛弃文献管理软件,毕竟他们处理不同期刊的文献格式是他们的强项。Obsidian并不能很好地完成这个任务,有大牛人开发相应的插件吗?如果你想在obsidian写作时引用,需要学习Endnote等文献管理工具自动引用文献信息的原理,那么你就可以用一种特殊的格式标记在笔记中来记录文献来源,当然或许有插件直接实现。
为什么非要用obsidian来做记录?
网络化自己的笔记系统
在阅读文献时,往往是先往大脑内灌入大量碎片化知识,这些知识再积累到一定程度后,才会有明显的逻辑与层次,我们才可以去写一段文字来进行总结。那么还没有被总结的知识存放在哪里?另外,存放的未被总结的知识点过多后,就会出现我曾经看过的那句话它在哪里?出自哪一篇文献?
其实记录信息还不是痛点,痛点是当我需要某个相关的知识时,有没有什么办法能让这些知识“主动地”涌现到我面前。试想那些视频博主在开发某个项目时,需要总结多少相关的资料?他们如何快速追逐与热点相关的信息的?Obsidian同时能够同时解决以上问题。
附件 你可以准备一个文件夹专门用来存放各种附件,比如你下载的pdf文献,实验过程中产生的图片等。当你的某条笔记链接到了某个附件文件时,obsidian可以直接打开附件,而你无需直接找到它。如果你观察过Endnote的文献存放位置的话,你会发现Endnote在导入文献的时候,会把pdf放到一个文件夹内,并给文件夹以唯一标识符命名,你在endnote中打开这个pdf时,endnote会通过这个唯一标识找到pdf。 obsidian是通过链接来实现的,你可以尽情的往你的附件文件夹内添加附件,而不必关注文件本身。
链接 链接是网络化笔记系统的核心。大致介绍一下它的作用,试想你阅读了100篇文章并产生了100篇笔记,如果用word记录还不及时整了的话,那可就头大了。假设你在阅读ROS相关的研究,大概率每篇笔记都会出现ROS这个词,Obsidian自带的出链插件能够自动匹配这样的相似或相同的词汇,当你想查看与ROS相关的笔记或想法时,这些散落在不同笔记的内容就很容易聚合到一起,这样就提高了效率。Obsidian允许多种链接方式,如链接到某一篇笔记的某个标题,某一个外部网站?访问这些链接时,既可以方便地跳转到目标文件,也可以利用插件预览目标文件的内容。在使用的时候,多多添加链接,添加的越多越有利于后期信息的聚合。
进行文献阅读的工作时,也可以这么做。先建立一个文件,一条一条的标注不同文献的信息,在这些条目上添加链接,通过点击链接,把阅读获得的详细知识存放到点击链接产生的文件内部。
AI赋能
如果你已经尝试过百度的文心一言,OPENAI的chatgpt,那么你对AI的能力应该相当清楚了。
我们所总结的知识库,实际上是互联网上的资料的一小部分,这些资料的相关知识,其实大语言模型可能都学习过了。有时候,大语言模型甚至比人更要专业。那么,如果让AI学习我们的知识库,它是否能更好的了解“我”是做什么的,从而为我们提供更精准的服务。我的想象是,把我们搜集到的资料送给AI,我们需要什么知识,只需要与AI对话就好了,such as: 请告诉我资料库中所有包含过氧化氢测定方法的文献位置,并生成一个报告。我相信,再也不需要我去Endnote一篇一篇的去过滤了,即便AI计算需要一些服务费,每月花25$请一个高级私人助理应该比吃一次肯德基性价比高多了吧。它完全可以做一个人类大脑的外置硬盘,甚至辅助我们产生灵感。但是,如何操作呢?我也不知道,去外网探索吧。及时在中文社区分享你的进展。

















 3442
3442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









