




Spark-Pipeline
注
学习笔记。若涉及侵权,请告知删除。
Intro
构建在DataFrame之上。Mllib提供标准的机器学习算法API,能够方便的将不同的算法组合成一个独立的管道 Pipeline or workflow.
- DataFrame: from Spark SQL as an ML dataset, which can hold a variety of data types, e.g. different columns storing text, feature vectors, true labels and predictions.
- Estimator: is an algorithm which can be fit on a DataFrame to produce a Transformer. A learning algorithm is an Estimator which trains on a DataFrame and produces a model.
- Transformer: is an algorithm which can transform one DataFrame into another DataFrame, e.g. an ML model is a Transformer which transforms a DataFrame with features into a DataFrame with prediction.
- Pipeline: a pipeline chains multiple Transformers and Estimators together to specify an ML workflow.
- Parameter: All Transformer and Estimators share a common API for specifying parameters.
Pipeline
A Pipeline is specified as a sequences of stages, and each stage is either a Transformer or an Estimator.
The input DataFrame is transformed as it passes through each stage.
For Transformer stages, the transform() method is called on the DataFrame.
For Estimator stages, the fit() method is called to produce a Transformer (which becomes a part of the PipelineModel, or fitted Pipeline)
Fit
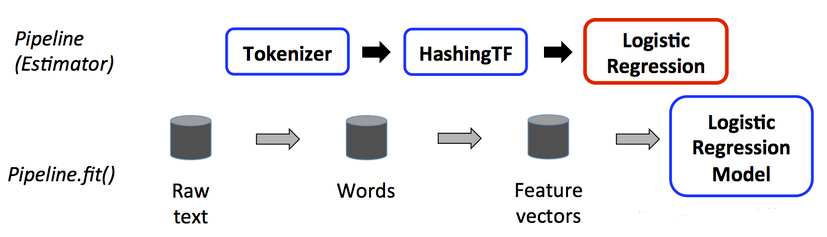
the figure is for the training time usage of a Pipeline.
The top row, three stages, the first two are Transformers and the third one is an Estimator.
The bottom row represents data flowing through the pipeline, where cylinders indicate DataFrames.
If the Pipeline has more stages after LogRegModel, it would call the model’s transform() method on the DataFrame before passing the DF to the next stage.
Transform
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









