








原文地址:https://machinelearningmastery.com/machine-learning-ensembles-with-r/
集成学习能够提升准确率,而本文将会介绍如何用R建立三种高效的集成学习模型。
本次案例研究将手把手地教你实现bagging、boosting、stacking,以及展示如何继续提高模型的准确率。
让我们开始吧!
提高模型的准确率
给特定的数据集找到性能优秀的机器学习算法颇为费时,因为应用机器学习算法本身所具有的实验和错误属性。
如果你已经有了准确性较高的一些算法,可以调整每一个算法,从中得到最佳性能的算法。
或者综合利用多个算法预测结果,用以提高准确率。
这就是所谓的集成学习。
Combine Model Predictions Into Ensemble Predictions (怎么翻译?)
三种最流行的方法如下:
- Bagging 从训练集中有放回抽取不同子集,建立多个模型(通常是同一个模型)
- Boosting 训练多个模型(通常是同一个模型),每个模型学习修正上一个模型错判的样本
- Stacking 训练多个模型(通常是不同模型),学习如何把各个模型组合达到最优性能
本文假设你已经相当熟悉相关算法,并不打算解释每一个算法的含义。重点关注如何用R实现集成学习算法。
用R实现集成学习
你能够用R实现三个主要集成学习技术:Bagging、Boosting、Stacking。在这部分,我们将轮流讲解。
开始之前,先确认我们的测试计划。
测试数据集
测试数据集为ionosphere 。可以从UCI Machine Learning Repository获得。这个数据集描述了大气中高能粒子的高频率天线返回的结果是否显示了结构。这个问题是一个二分类问题,共有351个样本,3个数值特征。
先载入数据集和和相关包
# Load libraries
library(mlbench)
library(caret)
library(caretEnsemble)
# Load the dataset
data(Ionosphere)
dataset <- Ionosphere
dataset <- dataset[,-2]
dataset$V1 <- as.numeric(as.character(dataset$V1))注意第一个特征是因子型,需要转换为数值型,以便和其他数值型特征保持一致。还要注意第二个特征是一个常量,需要删去。
下面是数据集前几行的情况:
> head(dataset)
V1 V3 V4 V5 V6 V7 V8 V9 V10 V11 V12 V13 V14 V15
1 1 0.99539 -0.05889 0.85243 0.02306 0.83398 -0.37708 1.00000 0.03760 0.85243 -0.17755 0.59755 -0.44945 0.60536
2 1 1.00000 -0.18829 0.93035 -0.36156 -0.10868 -0.93597 1.00000 -0.04549 0.50874 -0.67743 0.34432 -0.69707 -0.51685
3 1 1.00000 -0.03365 1.00000 0.00485 1.00000 -0.12062 0.88965 0.01198 0.73082 0.05346 0.85443 0.00827 0.54591
4 1 1.00000 -0.45161 1.00000 1.00000 0.71216 -1.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 -1.00000
5 1 1.00000 -0.02401 0.94140 0.06531 0.92106 -0.23255 0.77152 -0.16399 0.52798 -0.20275 0.56409 -0.00712 0.34395
6 1 0.02337 -0.00592 -0.09924 -0.11949 -0.00763 -0.11824 0.14706 0.06637 0.03786 -0.06302 0.00000 0.00000 -0.04572
V16 V17 V18 V19 V20 V21 V22 V23 V24 V25 V26 V27 V28
1 -0.38223 0.84356 -0.38542 0.58212 -0.32192 0.56971 -0.29674 0.36946 -0.47357 0.56811 -0.51171 0.41078 -0.46168
2 -0.97515 0.05499 -0.62237 0.33109 -1.00000 -0.13151 -0.45300 -0.18056 -0.35734 -0.20332 -0.26569 -0.20468 -0.18401
3 0.00299 0.83775 -0.13644 0.75535 -0.08540 0.70887 -0.27502 0.43385 -0.12062 0.57528 -0.40220 0.58984 -0.22145
4 0.14516 0.54094 -0.39330 -1.00000 -0.54467 -0.69975 1.00000 0.00000 0.00000 1.00000 0.90695 0.51613 1.00000
5 -0.27457 0.52940 -0.21780 0.45107 -0.17813 0.05982 -0.35575 0.02309 -0.52879 0.03286 -0.65158 0.13290 -0.53206
6 -0.15540 -0.00343 -0.10196 -0.11575 -0.05414 0.01838 0.03669 0.01519 0.00888 0.03513 -0.01535 -0.03240 0.09223
V29 V30 V31 V32 V33 V34 Class
1 0.21266 -0.34090 0.42267 -0.54487 0.18641 -0.45300 good
2 -0.19040 -0.11593 -0.16626 -0.06288 -0.13738 -0.02447 bad
3 0.43100 -0.17365 0.60436 -0.24180 0.56045 -0.38238 good
4 1.00000 -0.20099 0.25682 1.00000 -0.32382 1.00000 bad
5 0.02431 -0.62197 -0.05707 -0.59573 -0.04608 -0.65697 good
6 -0.07859 0.00732 0.00000 0.00000 -0.00039 0.12011 bad关于数据集更多信息参看官网描述description of the Ionosphere dataset
1、Boosting Algprithms
有以下两个最受欢迎的Boosting算法:
- C5.0
- Stochastic Gradient Boosting
下面是两种算法的实现,都采用默认参数,没有进行调参。
# Example of Boosting Algorithms
control <- trainControl(method="repeatedcv", number=10, repeats=3)
seed <- 7
metric <- "Accuracy"
# C5.0
set.seed(seed)
fit.c50 <- train(Class~., data=dataset, method="C5.0", metric=metric, trControl=control)
# Stochastic Gradient Boosting
set.seed(seed)
fit.gbm <- train(Class~., data=dataset, method="gbm", metric=metric, trControl=control, verbose=FALSE)
# summarize results
boosting_results <- resamples(list(c5.0=fit.c50, gbm=fit.gbm))
summary(boosting_results)
dotplot(boosting_results)C5.0算法的准确率更高,为94.58%
Models: c5.0, gbm
Number of resamples: 30
Accuracy
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
c5.0 0.8824 0.9143 0.9437 0.9458 0.9714 1 0
gbm 0.8824 0.9143 0.9429 0.9402 0.9641 1 0
更多的细节见此处Boosting Models
2、Bagging Algorithms
有以下两个最受欢迎的Bagging 算法:
- Bagged CART
- Random Forest
下面是两种算法的实现,都采用默认参数,没有进行调参。
# Example of Bagging algorithms
## method重抽样方法
## number交叉验证折数or重抽样迭代次数
## repeats交叉验证参数,貌似是参与计算的数据集个数?
## 比如下面的10折,但是随机选取3个子集建模??不清楚呀
control <- trainControl(method="repeatedcv", number=10, repeats=3)
seed <- 7
metric <- "Accuracy"
# Bagged CART
set.seed(seed)
fit.treebag <- train(Class~., data=dataset, method="treebag", metric=metric, trControl=control)
# Random Forest
set.seed(seed)
fit.rf <- train(Class~., data=dataset, method="rf", metric=metric, trControl=control)
# summarize results
bagging_results <- resamples(list(treebag=fit.treebag, rf=fit.rf))
summary(bagging_results)
dotplot(bagging_results)随即森林准确率更高,达到93.25%
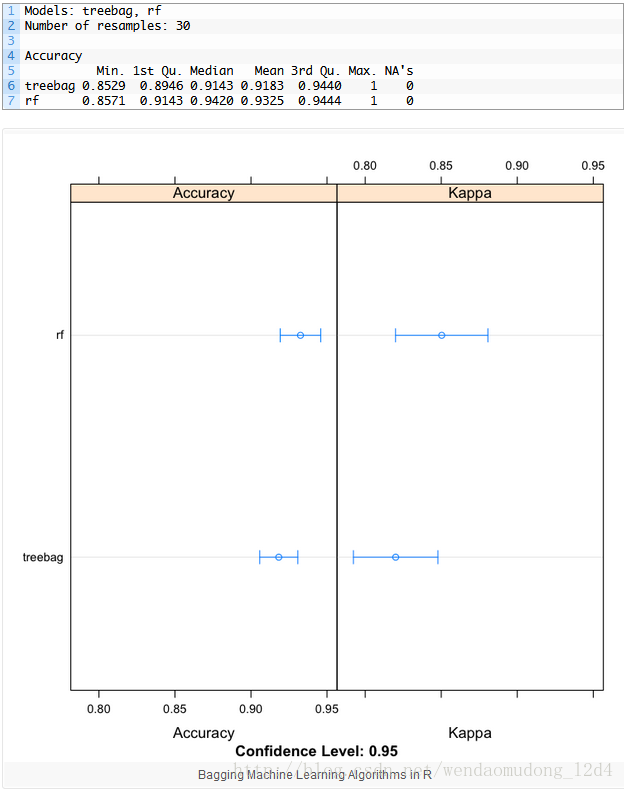
更多的细节见此处Bagging Models
3、Stacking Algorithms
caretEnsemble包能够组合多种caret模型的预测结果。
给定一系列caret模型,caretStack函数能够指定高阶模型(即元分类器)学习怎样组合基学习器,以达到最佳性能。
首先为数据集ionosphere 构建5个子模型(基学习器),详细如下:
- Linear Discriminate Analysis (LDA) [线性分类器,类似的QDA]
- Classification and Regression Trees (CART)
- Logistic Regression (via Generalized Linear Model or GLM)
- k-Nearest Neighbors (kNN)
- Support Vector Machine with a Radial Basis Kernel Function (SVM)
下面的例子创建了5个子模型,注意由caretEnsemble包提供的caretList()函数,用于创建一系列标准的caret模型
# Example of Stacking algorithms
# create submodels
control <- trainControl(method="repeatedcv", number=10, repeats=3, savePredictions=TRUE, classProbs=TRUE)
algorithmList <- c('lda', 'rpart', 'glm', 'knn', 'svmRadial')
set.seed(seed)
models <- caretList(Class~., data=dataset, trControl=control, methodList=algorithmList)
results <- resamples(models)
summary(results)
dotplot(results)SVM准确率最高,达到94.66%。[结果貌似不能复现啊?]
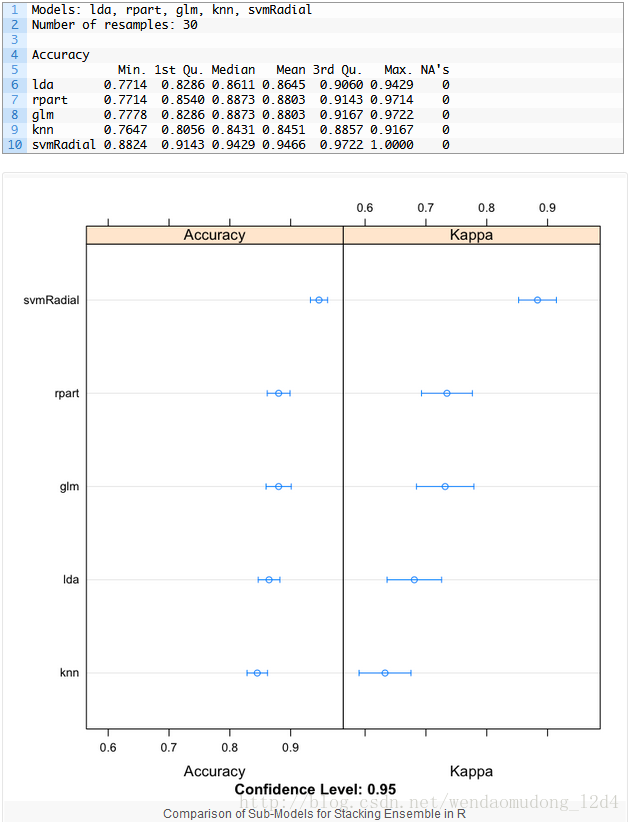
当使用stacking组合不同分类器时,我们希望不同分类器之间是弱相关的。这表明子模型不仅需要高效还得存在差异。(This would suggest that the models are skillful but in different ways, allowing a new classifier to figure out how to get the best from each model for an improved score.不会翻译咯)
如果模型相关性大于0.75,那么这些模型预测结果很可能类似或者相同,从而减弱组合模型带来的准确率上的提升。
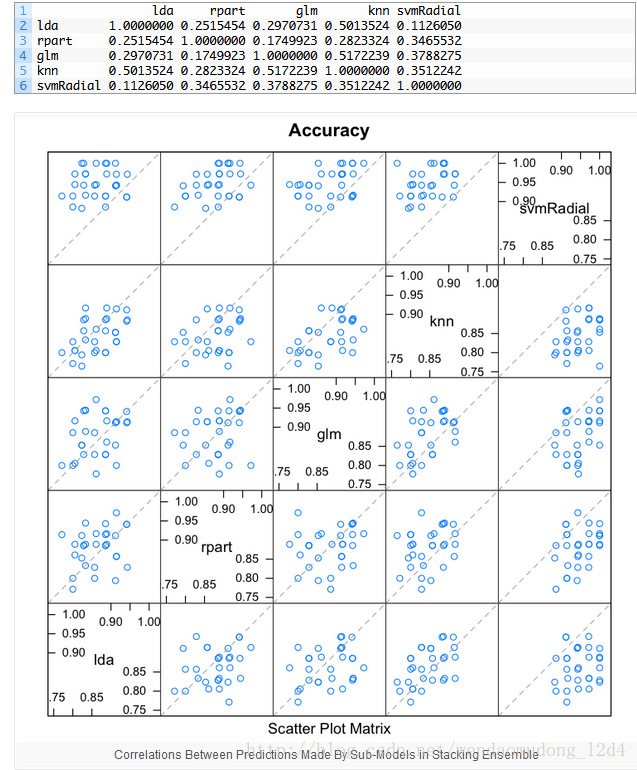
# correlation between results
modelCor(results)
splom(results)上面的代码可以计算不同模型的相关性。所有模型的相关性都比较低。其中LR和KNN相关性最高,0.517,但仍小于0.75
用简单线性模型组合子模型的预测结果
# stack using glm
stackControl <- trainControl(method="repeatedcv", number=10, repeats=3, savePredictions=TRUE, classProbs=TRUE)
set.seed(seed)
stack.glm <- caretStack(models, method="glm", metric="Accuracy", trControl=stackControl)
print(stack.glm)准确率提升到94.99%,略优于svm单模型。也比上文提高的随机森林高。
A glm ensemble of 2 base models: lda, rpart, glm, knn, svmRadial
Ensemble results:
Generalized Linear Model
1053 samples
5 predictor
2 classes: 'bad', 'good'
No pre-processing
Resampling: Cross-Validated (10 fold, repeated 3 times)
Summary of sample sizes: 948, 947, 948, 947, 949, 948, ...
Resampling results
Accuracy Kappa Accuracy SD Kappa SD
0.949996 0.891494 0.02121303 0.04600482当最好使用不同算法时,我们也可以使用更加复杂的算法进行组合预测。下面的列子使用随机森林组合预测。(应该指的是元分类器为随机森林)
# stack using random forest
set.seed(seed)
stack.rf <- caretStack(models, method="rf", metric="Accuracy", trControl=stackControl)
print(stack.rf)此时准确率提升到96.26%。
A rf ensemble of 2 base models: lda, rpart, glm, knn, svmRadial
Ensemble results:
Random Forest
1053 samples
5 predictor
2 classes: 'bad', 'good'
No pre-processing
Resampling: Cross-Validated (10 fold, repeated 3 times)
Summary of sample sizes: 948, 947, 948, 947, 949, 948, ...
Resampling results across tuning parameters:
mtry Accuracy Kappa Accuracy SD Kappa SD
2 0.9626439 0.9179410 0.01777927 0.03936882
3 0.9623205 0.9172689 0.01858314 0.04115226
5 0.9591459 0.9106736 0.01938769 0.04260672
Accuracy was used to select the optimal model using the largest value.
The final value used for the model was mtry = 2.你可以用R建立集成学习模型
你不必是R程序员。只需copy相关代码,查询帮助文档。
你不必是机器学习专家。从头构建集成学习系统十分复杂,而caret和caretEnsemble包可以轻松进行模型创建和实验,即使你对模型如何运行并没有深刻的认知。熟悉每一种类型的集成学习方法,以后更好的使用这些算法。
你不必自己写集成学习的代码。许多强大的算法R都能够提供,直接使用就好。现在就开始学习本文中的案例。你总能够调整这些算法以适应特定的数据集或者用自定义的代码实验新的想法
总结
在本文,你能够发现使用集成学习算法能够提高模型的准确率。
在R中能够构建三种集成学习算法:
1. Bagging
2. Boosting
3. Stacking
你可以使用案例中的代码作为机器学习项目的参考样本。
下一步
你是否已经完成案例研究?
1. 启动R
2. copy代码
3. 通过帮助文档,花时间理解每部分的代码
有问题可以留言,我会尽力回答~
翻后感
1、基分类器or子模型是否可以调整参数?怎么调整?
2、元分类器or二级模型是否可以调整参数?怎么调整?
3、基本算法的理论细节还是要掌握,不然都不能愉快地调参咯!
遇到的坑
- 目标变量貌似必须是字符串,因子型。否则会报错
- stacking是的模型对数据集有要求,比如lda要求特征中没有常量,这应该和模型的背景有关吧
- 似乎stacking并没有什么效果哟~或者我调参数调的还是不行吗?















 1052
1052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









