






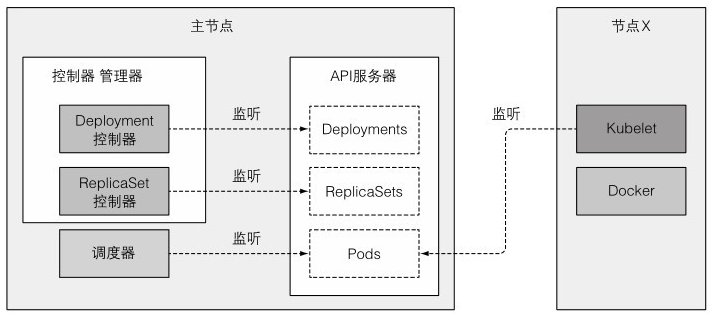
一、架构
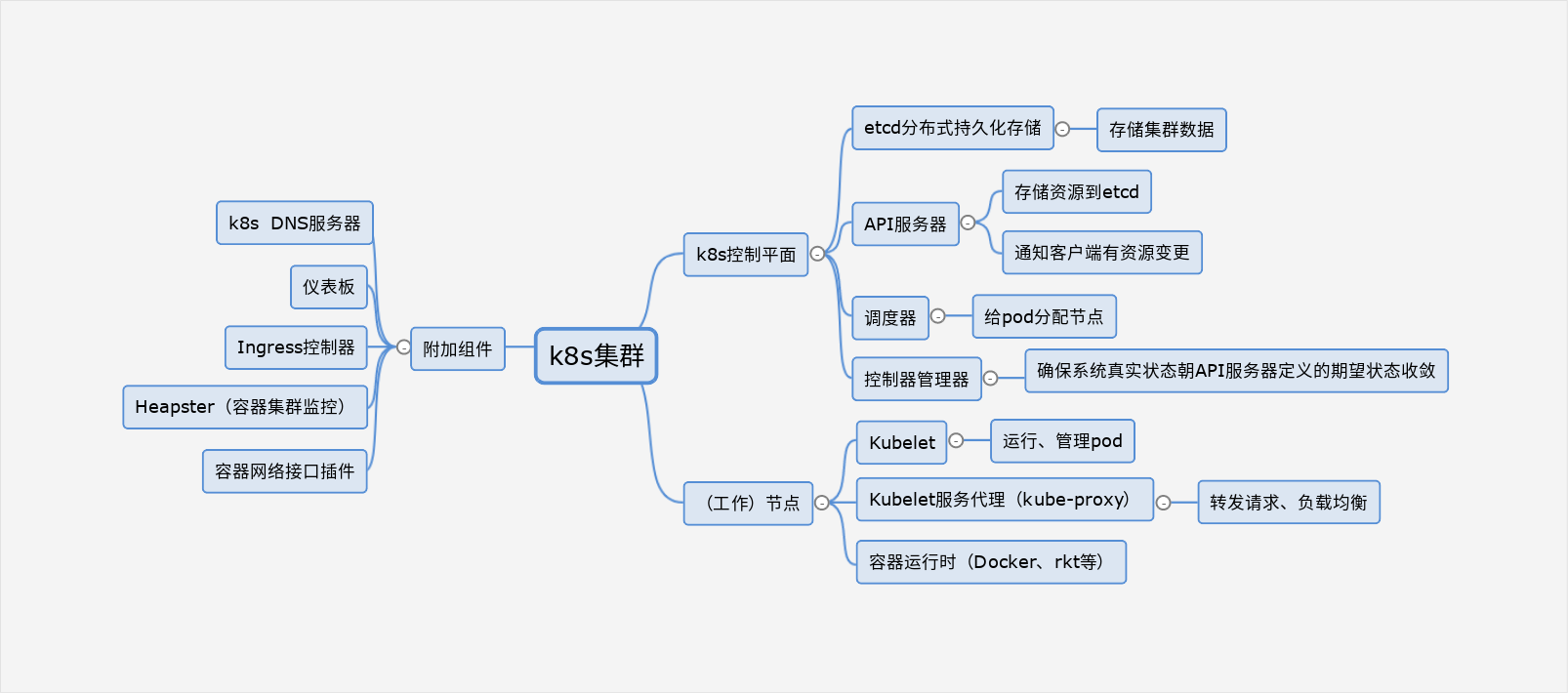
1、组件的分布式特性
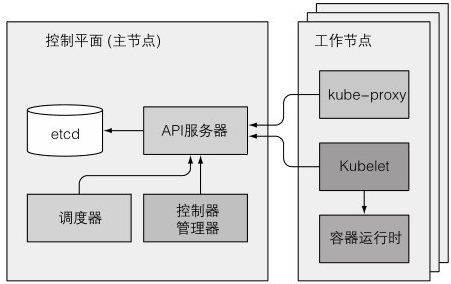
可以通过kubectl get componentstatuses 查看控制平面组件的健康状态
各组件间不直接通信,都是通过API服务器通信
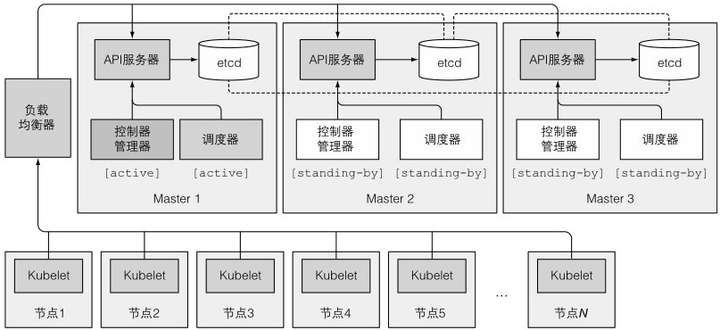
控制平面的各个组件都是多实例的,etcd和API服务器都是多实例并行,调度器和控制器管理器虽然有多实例,但是给定时间内只有一个实例起作用,其他待命
每个组件也是通过pod运行的,kubectl get po -n kube-system可以看到
2、etcd
k8s的数据库,前面章节创建的所有对象需要以持久化方式存储到某个地方,这样它们的manifest在API服务器重启后都不会丢失
唯一能和etcd直接通信的只有API服务器
存储方式:键值对,把key存储在一个层级键空间中,类似于文件系统的文件,来看一下:
etcdctl ls /registry
/registry/configmaps
/registry/pods
/registry/namespaces
/registry/events
etcdctl ls /registry/pods
/registry/pods/default
/registry/pods/kube-system
etcdctl ls /registry/pods/default
/registry/pods/default/kubia-33197431-dscs4
/registry/pods/default/kubia-33197431-24daf
/registry/pods/default/kubia-33197431-54dsf
etcdctl ls /registry/pods/default/kubia-33197431-dscs4
pod的json定义写入数据库的数据一致性由RAFT算法来保证
写冲突由乐观锁即MVCC(多版本并发控制,在数据行后加版本号)来控制,这个在API服务器中做
3、API服务器:存储资源到etcd、通知客户端有资源变动
中心组件,其他组件和客户端都会调用它,以RESTful API的形式提供了CRUD的接口,并且完成乐观锁并发处理等
假设现在通过kubectl创建一个资源或pod,其流程如下:
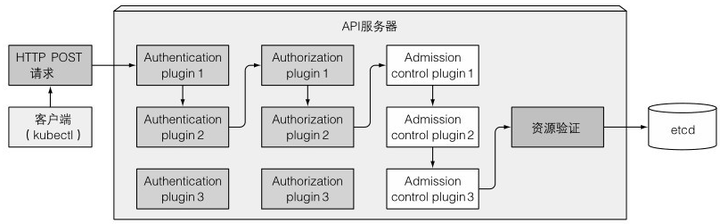
(1)通过认证插件认证客户端
插件从HTTP头或证书中获取客户端用户名、id、归属组等信息,轮流调用这些插件,直到有一个确认了是谁发送的请求,确认之后,后面的认证插件就不会调用了
(2)通过授权插件授权客户端
决定认证的用户是否有权限对请求资源执行请求操作
(3)通过准入控制插件验证AND/OR修改资源请求
增删改的请求需要经过准入控制插件的验证
包括:AlwaysPullImages---重写pod的imagePullPolicy为Always,强制每次部署pod时拉取镜像。
ServiceAccount —— 未明确定义服务账户的使用默认账户
等等
应该就是做一些参数检查
(4)验证资源以及持久化存储
通过所有准入插件后,API服务器会验证存储到etcd的对象,并返回客户端
4、API服务器通知客户端资源变更
客户端订阅,有资源变更时,API通知
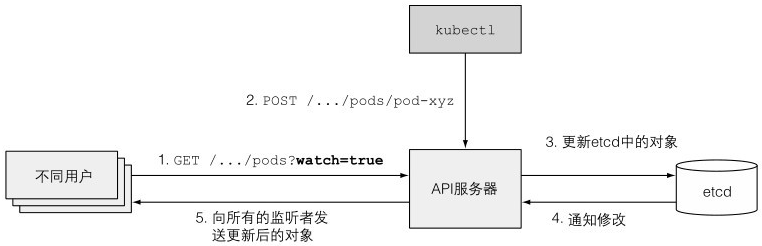
kubectl命令行订阅:kubectl get po -w(--watch)
5、调度器
监听API服务器,等待创建新pod,然后给pod分配节点
调度器不会直接命令某个节点的kubelet去创建一个pod,而是:调度器通过API服务器更新pod定义,kubelet监听到这个pod被调度到自己节点上,kubelet就会创建并运行pod的容器
默认调度算法:如果多个节点都有最高优先级分数,则循环分配,保证均分pod
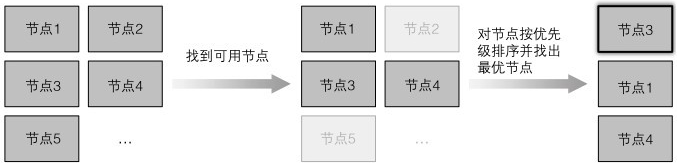
查找可用节点:节点是否满足pod的硬件要求、节点是否耗尽资源、pod是否要求被调度到指定节点、pod要求的主机节点是否被占用、卷是否在这个节点上被定义过等等等等
最佳节点:看业务需要,可能需要均分到集群中所有节点,可能为了节约成本,尽可能调度到同一节点。
6、控制器管理器
每个控制器做了不同的事,互相不冲突,甚至不知道其他控制器的存在,但是它们都是通过API服务器监听了资源变更。
它们会执行一个“调和”循环,将资源实际状态调整为期望状态,然后将新的实际状态写入资源的status部分,可以看看源码
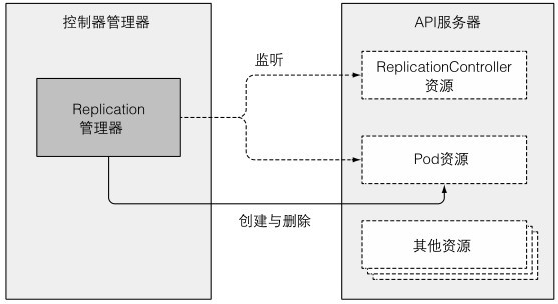
(1)Replication管理器:启动RC资源的控制器
之前说RC的操作类似一个无限循环,比对pod期望数量和实际数量,但控制器实际上是监听pod数量的变更事件,并做出相应动作:增加pod副本时,RC不会直接创建pod,而是创建pod清单,发送到API服务器,让调度器和kubelet完成调度工作并运行pod。
所有控制器都是直接和API服务器交互,并不自己操作pod
(2)RS、DaemonSet、Job控制器
与Replication控制器做了一样的事
(3)Deployment控制器
负责将Deployment的实际状态与对应的Deployment API对象的期望状态同步
(4)StatefulSet控制器
不仅会管理pod,还会管理每个pod的持久卷声明字段
(5)Node控制器
使节点对象列表与集群中实际运行的机器列表保持同步,监控每个节点的健康状态,删除不可达节点的pod
(6)Service控制器
针对LoadBalancer类型的服务,用来在该类型创建、删除时,从基础设施服务请求、释放负载均衡器的
(7)Endpoint控制器
服务不直接连接pod,而是包含ip、端口列表,Endpoint控制器定期根据匹配标签选择器的pod的IP、端口更新端点列表,它同时监听service和pod资源,并操作Endopoint对象
(8)Namespace控制器
namespace被删除时,它负责删除该namespace下所有资源
(9)PersistentVolume控制器
作用:绑定PVC和PV,解绑回收PV
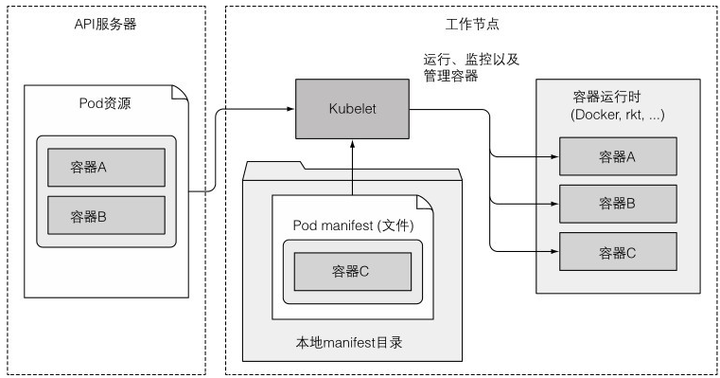
7、kubelet
(1)在API服务器中创建一个Node资源来注册节点
(2)持续监控API服务器,是否把该节点分配给pod,并启动pod
(3)持续监控运行的容器,向API服务器报告状态、事件、消耗的资源
(4)运行容器存活探针
(5)终止容器,并通知API服务器
一般kubelet从API服务器获取pod清单,但对于系统资源,也可以将其放入本地manifest目录,让kubelet运行和管理它们,自定义的也可以放入这个目录
8、kube-proxy
确保客户端可以通过API服务器连接到服务,并负责负载均衡
过去的代理模式:userspace模式
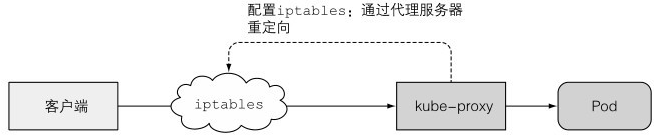
有一个真实的代理服务器,接收所有请求并轮询给pod,请求需要发送到kube-proxy
现在的代理模式:iptables代理模式

通过iptables规则直接重定向数据包到一个随机的pod,不用轮询,数据包也不用发送到kube-proxy,没有实际的代理服务器,数据包只会在内核处理
9、插件
(1)如何部署插件
提交yaml清单到API服务器,这些组件会成为插件并作为pod部署,这些组件通过RC、deployment、Daemoset等等部署
(2)DNS服务器
所有集群中的pod默认使用DNS服务器,使得pod轻松通过名称查询到服务,甚至是无头服务pod的IP地址
kube-dns的pod利用API服务器的监控机制订阅Service和Endpoint的变动,以及DNS记录的变更
(3)Ingress控制器
和DNS作用类似。但运行一个反向代理,根据集群中定义的ingress、service、endpoint来配置该控制器,所以需要订阅这些资源
二、控制器间的相互协作
以创建一个Deployment为例
1、准备
2、事件链
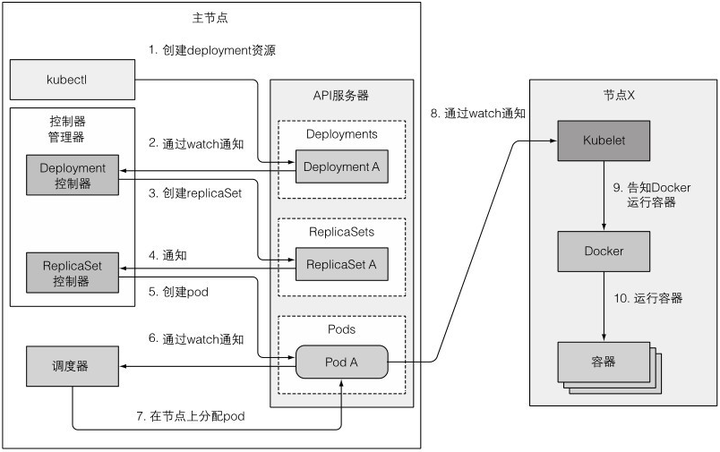
3、观察集群事件
kubectl get events --watch
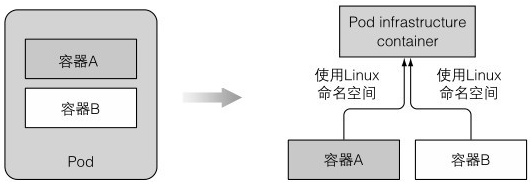
三、了解运行中的pod是什么
登录运行pod的节点上,docker ps看一下运行的容器实际的应用容器可能会挂掉重启,重启后要保证与之前处于相同的linux命名空间,所以基础容器的生命周期和pod一致。
发现除了本该运行的应用容器外,还有一个command是“/pause”的容器,它是一个暂停的基础容器,唯一作用是保存所有的命名空间
四、服务的实现
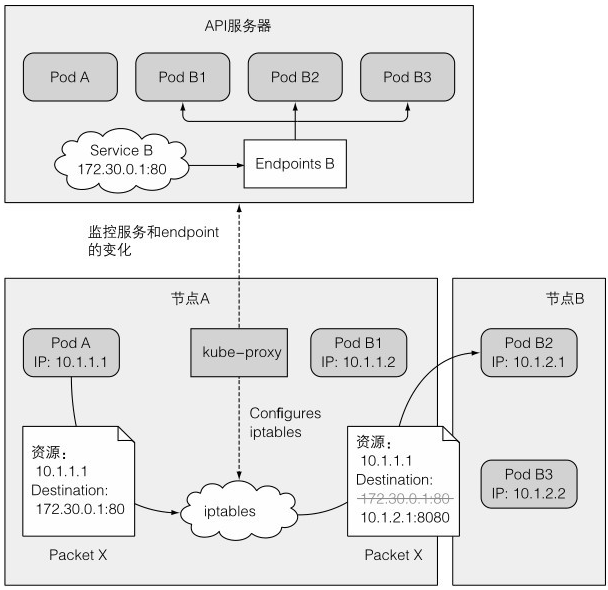
1、kube-proxy
和Service相关的任何事情都由每个节点上运行的kube-proxy进程处理。每个服务有稳定的IP、端口,这个ip是虚拟的,本身不代表任何东西,所以ping不通的
过去的userspace模式:kube-proxy确实是一个proxy,等待连接,并转发给pod
现在被iptables模式替代了:kube-proxy维护iptables,请求由iptables转发处理
2、kube-proxy如何使用iptables
当服务被创建时,一个虚拟ip被分配,API服务器通知所有kube-proxy客户端,每个kube-proxy会让该服务在自己节点上可寻址。原理是通过建立一些iptables规则,确保每个目的地为服务的IP端口对的数据包被解析,目的地址被修改为支持服务的一个pod
kube-proxy还监听endpoint的变更
访问过程:podA是请求发起客户端,要访问服务B,数据包中写的是服务B的地址,iptables给解析并修改目的地址为podB2的ip
五、运行高可用集群
高可用指保证运行的服务不被中断,即宕机
1、应用高可用
使用多实例来减少宕机可能性,保证可以水平伸缩,如果只需要1个复制集,也可以用Deployment,设置replicas为1,保证挂了也能自动重启
不能水平扩展的应用可以使用领导选举机制:多实例,保证一个领导,其他都等领导宕机后自己成为领导,只有领导可以执行任务,或者只有领导可以执行写,其他都只能读,读写分离。这种机制不需要集成到应用中,用sidecar容器来执行所有领导选举操作,通知主容器它什么时候可以活跃起来。
2、k8s高可用性
要保证k8s本身没有挂
etcd集群:etcd多个实例,只有一个领导在工作,其他的都是备份,一个挂了也不影响使用
多实例API服务器:API服务器是无状态的,随便运行多少个都可以,通常一个etcd配一个API服务器,这样API服务器只需要和本地etcd实例通信即可,负载均衡也由API服务器做,不用etcd做
控制器和调度器的高可用:多实例会导致执行同一操作时有竞争,所以给定时间内只有一个实例有效就可以了,也是用领导选举机制保证的,
控制器、调度器、API服务器、etcd都是搭配使用,这样都是只和本地通信了
领导选举也是通过乐观锁控制的,谁先写入数据库,谁就是领导















 2067
2067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









