






本章讲述的是如何通过一些安全配置,保障集群中宿主节点和pod的安全,不被其他pod攻击
一、在pod中使用宿主节点的Linux命名空间
namespace的概念存在于很多地方,这里的linux namespace和k8s集群的namespace并不是一个,但是作用都是用来隔离资源的,k8s中namespace可以大概理解为user namespace,用来隔离用户间的资源的。但Linux namespace可以隔离网络、进程、进程间通信(IPC)等
1、在pod中使用宿主节点的网络命名空间
部分pod(特别是系统pod)需要在宿主节点的默认网络命名空间中运行,以允许它们看到和操作节点级别的资源和设备
做法:指定pod.spec.hostNetwork=true
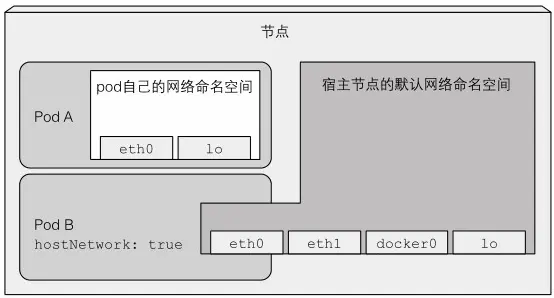
可以通过命令kubectl exec pod-example ifconfig查看podB的网卡详情,发现它与宿主机的相同(本地用kind启动的集群,看的是kind容器的网卡详情,ip address)
podB没有自己独立的网络,意味着这个pod没有自己的IP地址(pod的IP地址和宿主机的IP地址一样),想要访问这个pod,必须把端口暴露出来,映射到宿主机的端口上
2、映射端口到宿主节点上
做法:填写pod.spec.containers.ports.hostPort为宿主节点的端口
注意:与Nodeport类型的Service的区别:
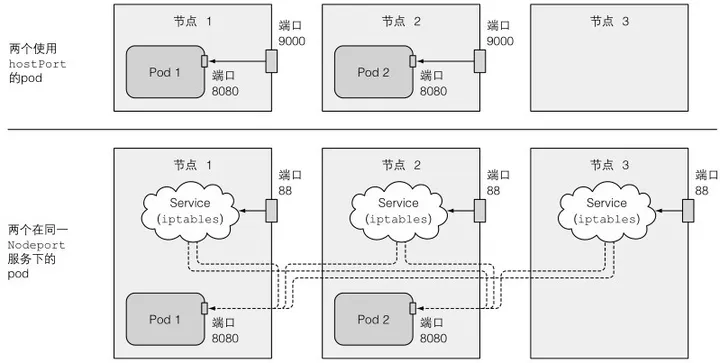
(1)对于使用hostPort的pod,到达宿主节点的端口的连接会被直接转发到pod的对应端口上;然而在NodePort服务中,到达宿主节点的端口的连接将通过Service被转发到随机选取的pod上(这个pod可能在其他节点上)
(2)对于使用hostPort的pod,仅有运行了这类pod的节点会绑定对应的端口;而NodePort类型的服务会在所有的节点上绑定端口,即使这个节点上没有运行对应的pod
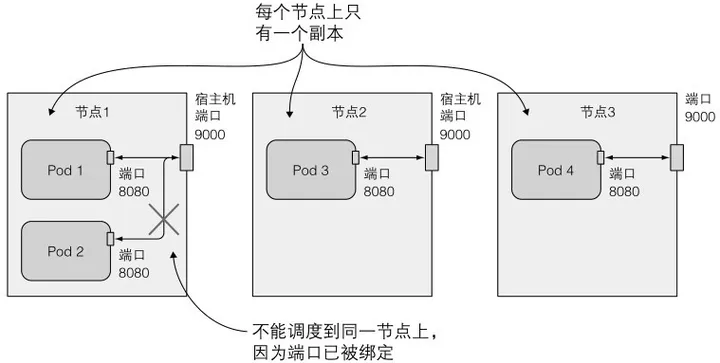
(3)对于使用hostPort的pod,如果两个pod绑定的宿主节点端口是同一个,那会有一个调度不到该节点上,如果集群中每个节点端口都被占用了,那该pod调度失败;而在NodePort服务中,多个同类pod可以运行在一个宿主节点上
3、使用宿主节点的PID与IPC(进程间通信)命名空间
做法:pod.spec.hostPID=true
pod.spec.hostIPC=true
目的:使得pod内的进程和宿主节点上的进程可以通信
验证:kubectl exec pod-example ps aux 查看进程
二、配置节点的安全上下文
在pod或容器中通过securityContext选项来配置与安全性相关的特性
1、使用指定用户运行容器
Dockerfile中可以使用USER命令指定启动容器时使用的用户,如果没有设置,则会以root命令启动容器
kubectl exec pod-example id
uid=0(root) gid=0(root) groups=10(wheel)在镜像无法修改的前提下,可以通过securityContext修改容器启动用户
apiVersion: v1
kind: Pod
metadata:
name: pod-example
spec:
hostNetwork: true
hostPID: true
hostIPC: true
containers:
- image: docker.io/library/alpine:3.12
name: example
imagePullPolicy: IfNotPresent
securityContext:
runAsUser: 405 // 在alpine镜像中,405是guest用户验证结果:
kubectl exec pod-example id
uid=405(guest) gid=100(users)2、阻止容器以root用户运行
攻击场景:pod正常是和宿主节点隔离的,但当宿主节点上的一个目录被挂载到容器中时,如果这个容器中的进程使用了root用户运行,它就拥有该目录的完整访问权限,这时应该禁止root用户运行容器
阻止:
securityContext:
runAsNonRoot: true3、使用特权模式运行pod
如果需要在pod中操作宿主节点,操作被保护的系统设备、使用内核功能
这都是需要特权的,可以不让容器拥有特权
securityContext:
privileged: true验证:
linux文件系统中,/dev目录包含了系统中所有设备对应的设备文件
没有以特权模式运行的pod:
kubectl exec -it pod-example ls /dev
core null shm termination-log
fd ptmx stderr tty
full pts stdin urandom
mqueue random stdout zero特权模式运行的pod:可以列出很多目录
4、为容器单独添加内核功能
特权模式给了操作linux巨大的权限,内核功能细分了更多的权限
举例:修改系统时间
正常pod无法修改系统时间的
添加内核功能:
securityContext:
capabilities: //内核功能
add: //添加
- SYS_TIME //系统时间权限验证结果:
kubectl exec -it pod-example -- date +%T -s "14:00:00" //修改当前时间为14:00
kubectl exec -it pod-example -- date //查看当前时间5、在容器中禁用内核功能
securityContext:
capabilities:
drop:
- CHOWN // 无法修改文件的所有者6、阻止对容器根文件系统的写入
securityContext:
readOnlyRootFilesystem: true进入容器,在根目录下写文件:
touch aaa.txt
touch: aaa.txt: Read-only file system即便root用户登进来也不可以写根目录,但可以在挂载了存储卷的目录下执行写操作
7、给所有容器设置安全上下文:
修改pod.spec.securityContext而不是pod.spec.containers.securityContext
8、容器使用不同用户运行时共享存储卷
在存储卷章节中说到emptyDir可以在容器间共享数据,但那个前提是两个容器对挂载的目录都有读写权限,当容器以不同用户运行时,不一定都有读写权限,这时可以通过pod的安全上下文设置
apiVersion: v1
kind: Pod
metadata:
name: pod-example
spec:
securityContext:
fsGroup: 555 //使在存储卷中创建的文件属于555组
supplementalGroups: [666, 777] //补充组:定义了某个用户所关联的额外的用户组
containers:
- image: docker.io/library/alpine:3.12
name: first
imagePullPolicy: IfNotPresent
command:
- top
securityContext:
runAsUser: 1111
volumeMounts:
- name: shared-volume
mountPath: /volume
readOnly: false
- image: docker.io/library/alpine:3.12
name: second
imagePullPolicy: IfNotPresent
command:
- top
securityContext:
runAsUser: 2222
volumeMounts:
- name: shared-volume
mountPath: /volume
readOnly: false
volumes:
- name: shared-volume
emptyDir:容器first和second以不同用户启动,但挂载了同一个emptyDir卷
进入第一个容器查看登录用户
id
uid=1111 gid=0(root) groups=555,666,777 // gid依然是0,但是组有好几个查看卷的所属组
ls -l / | grep volume
drwxrwsrwx 2 root 555 6 Dec 8 01:46 volume // 属于root用户,但是组是fsGroup指定的555在/volume目录下创建一个文件
echo foo > /volume/foo
ls -l /volume
-rw-r--r-- 1 1111 555 4 Dec 8 01:48 foo // 用户1111创建的,组是fsGroup指定的555在非/volume目录下创建文件
echo foo > /tmp/foo
ls -l /tmp
-rw-r--r-- 1 1111 root 4 Dec 8 01:48 foo // 组是root说明fsGroup只对volume生效
查看用户所属组:
groups
root 555groups: unknown ID 555
666groups: unknown ID 666
777groups: unknown ID 777三、隔离pod网络
有时只允许部分pod之间互相访问或单向访问,这时需要用NetworkPolicy资源来做网络隔离
1、同一namespace下的网络隔离
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: network-policy-example
spec:
podSelector: // 没填就是选中NetworkPolicy的ns下所有pod注意:NetworkPolicy是ns级别的资源
2、同一ns下部分pod的网络隔离
只允许部分webserver的pod访问数据库pod
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: postgres-netpolicy
spec:
podSelector:
matchLabels:
app: database // 目标pod
ingress: // 入向
- from:
- podSelector:
matchLabels:
app: webserver // 入向pod
ports:
- port: 5432 // 目标端口 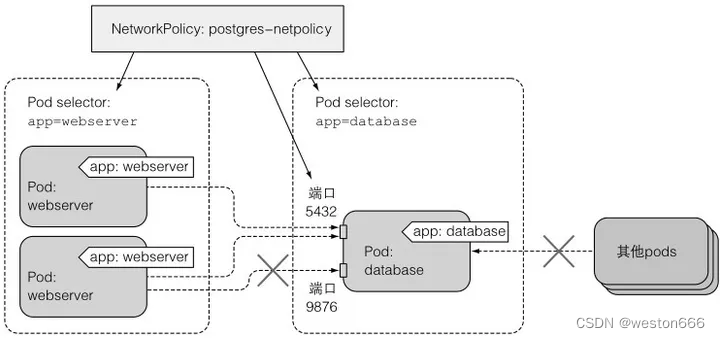
3、跨ns的pod网络隔离
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: postgres-netpolicy
spec:
podSelector:
matchLabels:
app: database
ingress:
- from:
- namespaceSelector: // 直接选择ns,有tenant=manning标签的ns下的所有pod 都可访问 networkPolicy的ns下 有标签app=database的pod
matchLabels:
tenant: manning
ports:
- port: 804、使用CIDR隔离网络
无类别域间路由,指的是一个ip段内的客户端

5、限制pod对外的访问
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









