






应公司要求,特别写了一个博客,提交给公司,这里也再重发下。
基于hiveserver的Dip-Data-Analyze
一、 hive 简介
hive 是一个基于 hadoop 的开源数据仓库工具,用于存储和处理海量结构化数据。 它把海量数据存储于hadoop 文件系统,而不是数据库,但提供了一套类数据库的数据存储和处理机制,并采用 HQL (类 SQL )语言对这些数据进行自动化管理和处理。我们可以把 hive 中海量结构化数据看成一个个的表,而实际上这些数据是分布式存储在 HDFS 中的。 Hive 经过对语句进行解析和转换,最终生成一系列基于 hadoop 的 map/reduce 任务,通过执行这些任务完成数据处理。
Hive 诞生于 facebook 的日志分析需求,面对海量的结构化数据, hive 以较低的成本完成了以往需要大规模数据库才能完成的任务,并且学习门槛相对较低,应用开发灵活而高效。
Hive 自 2009.4.29 发布第一个官方稳定版 0.3.0 至今,不过一年的时间,正在慢慢完善,网上能找到的相关资料相当少,尤其中文资料更少,本文结合业务对 hive 的应用做了一些探索,并把这些经验做一个总结,所谓前车之鉴,希望读者能少走一些弯路。
Hive 的官方 wiki 请参考这里 :
http://wiki.apache.org/hadoop/Hive
官方主页在这里:
http://hadoop.apache.org/hive/
hive-0.5.0 源码包和二进制发布包的下载地址
http://labs.renren.com/apache-mirror/hadoop/hive/hive-0.5.0/
二、Dip-Data-Analyze的诞生
进入公司以来,就专心研究下hadoop,hive,感觉hive让分析人员分析数据b变的极为方便,通过将日志转成表,像操作mysql的方式去统计数据,无疑是方便很多。但是也带来个问题:分析人员直接操作hive,需要分析人员对hive有比较深得了解 ,而且很多功能像udf之类需要频繁加载,效率低下;对于一些一天跑几次或者定期执行的任务,很多流行的做法是通过脚本加入cron,来调度,这样的结果是随着任务增多,对这些分析任务的管理就会非常复杂,因为管理人员不知道一个脚本具体负责什么,更无法跟踪这个任务做了什么,如果失败怎么恢复,任务结果如何管理等等。
正是基于以上的想法,才产生了dip-data-analyze
三、Dip-Data-Analyze的架构
技术架构:
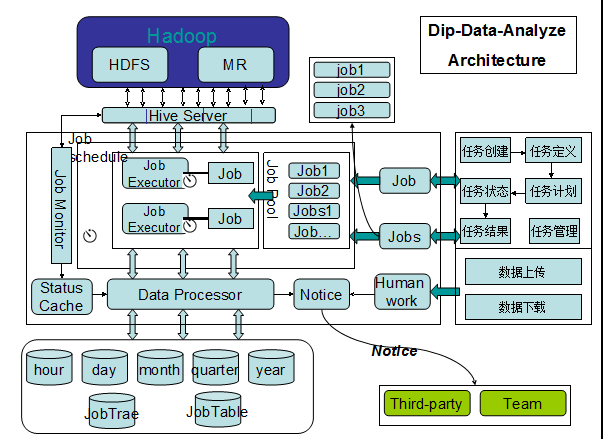
可以看到dip-data-analyze是构建在hadoop\hive之上的系统。用户通过系统提供的界面可以创建分析任务(Job),这些Job有几种类型(暂时包含3种),可以帮助用户完成常见的分析任务。同时系统提供了计划的管理,通过将任务与计划融合,组成计划任务,用户的任务就可以按照计划去执行。
任务提交后由系统的调度系统根据计划调度执行,通过jobcache记录任务的实时状态,并可控制每秒并行任务的个数,以防并行任务过多,对hiveserver压力过大。
任务运行过程中,DataProcessor会产生jobtrace对象,跟踪记录每一个任务运行轨迹,并将jobtrace保存到数据库。Jobtable记录任务产生的表,并为后执行的任务提供数据源。DataProcessor负责从Jobtable获取需要的hive表给依赖于其他任务的任务。最后DataProcessor正确保存任务产生的数据。目前是存在hdfs,未来会支持存入mysql或hbase.
系统提供了友好的报警通知机制,用户既可以采用全局报警也可以对每个任务定义报警。
另外系统提供了非计划任务,支持用户执行一次性任务,并可以通过jobtrace进行重试操作.
四、业务逻辑
Dip-data-analyze总体业务逻辑图

目前任务支持三种任务类型:LoadDataJob、Base_Analyze、Top_Analyze.
通过系统调度框架执行任务,任务通过系统中的支持并发的CentralJobExecution来执行job.执行过程产生的jobtable、jobtrace及报警信息会及时保存或发送。
五、执行模式
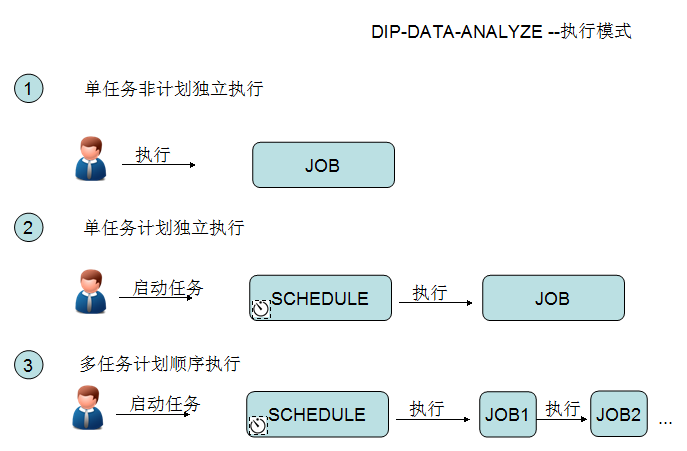
目前任务执行模式大体分为3种,如图所示.
六、系统演示
目前系统为beta版,已经试运行一段时间。
| 系统概况 | |||
| 计划任务: | 共48个, 其中正在运行的42个, 已经停止 6个。 | ||
| 非计划任务: | 共22个, 按类型统计,数据加载任务共 10个, 基础分析任务共 3个, TOP分析任务共 9个 | ||
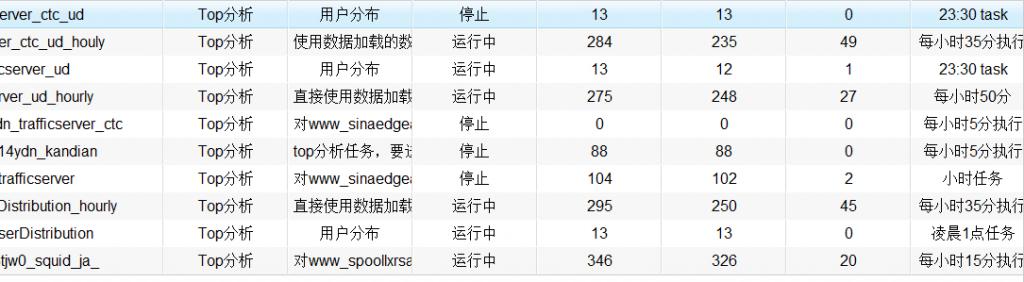
系统截图:
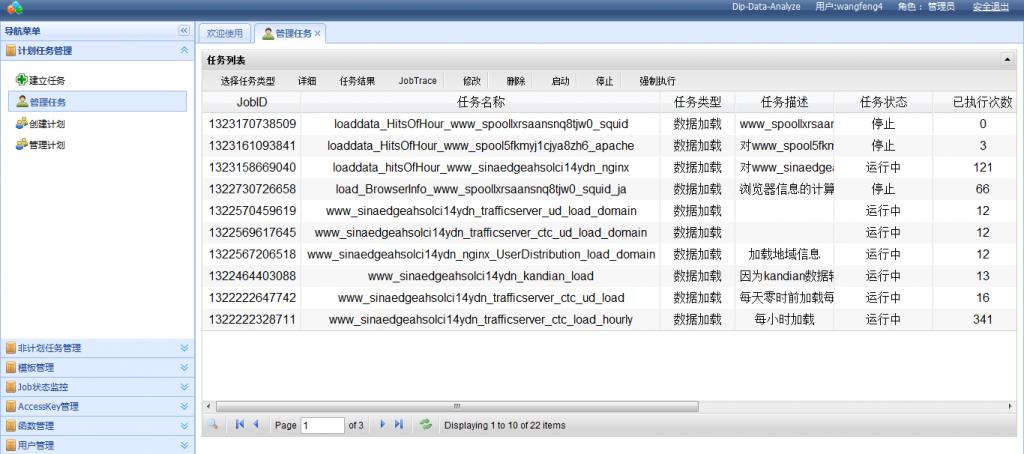
任务监控中完成的任务列表:
wangfeng4@staff.sina.com.cn或wfeng1982@163.com














 6568
6568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









