







dropout可以让模型训练时,随机让网络的某些节点不工作(输出置零),也不更新权重,其他过程不变。我们通常设定一个dropout radio=p,即每个输出节点以概率p置0(不工作,权重不更新),假设每个输出都是独立的,每个输出都服从二项伯努利分布p(1-p),则大约认为训练时,只使用了(1-p)比例的输出,相当于每次训练一个子网络。测试的时候,可以直接去掉Dropout层,将所有输出都使用起来,为此需要将尺度对齐,即比例缩小输出 r=r*(1-p)。
训练的时候需要dropout,测试的时候直接去掉
caffe_copy(bottom[0]->count(), bottom_data, top_data);
如果测试时的时候添加了dropout层,测试的时候直接把前一层的特征赋值到下一层:
dropout层相当于组合了N个网络,测试的时候去掉dropout,相当于N个网络的组合;
二、算法概述
我们知道如果要训练一个大型的网络,训练数据很少的话,那么很容易引起过拟合(也就是在测试集上的精度很低),可能我们会想到用L2正则化、或者减小网络规模。然而深度学习领域大神Hinton,在2012年文献:《Improving neural networks by preventing co-adaptation of feature detectors》提出了,在每次训练的时候,让一半的特征检测器停过工作,这样可以提高网络的泛化能力,Hinton又把它称之为dropout。
Hinton认为过拟合,可以通过阻止某些特征的协同作用来缓解。在每次训练的时候,每个神经元有百分之50的几率被移除,这样可以让一个神经元的出现不应该依赖于另外一个神经元。
另外,我们可以把dropout理解为 模型平均。 假设我们要实现一个图片分类任务,我们设计出了100000个网络,这100000个网络,我们可以设计得各不相同,然后我们对这100000个网络进行训练,训练完后我们采用平均的方法,进行预测,这样肯定可以提高网络的泛化能力,或者说可以防止过拟合,因为这100000个网络,它们各不相同,可以提高网络的稳定性。而所谓的dropout我们可以这么理解,这n个网络,它们权值共享,并且具有相同的网络层数(这样可以大大减小计算量)。我们每次dropout后,网络模型都可以看成是整个网络的子网络。(需要注意的是如果采用dropout,训练时间大大延长,但是对测试阶段没影响)。
啰嗦了这么多,那么到底是怎么实现的?Dropout说的简单一点就是我们让在前向传导的时候,让某个神经元的激活值以一定的概率p,让其停止工作,示意图如下:
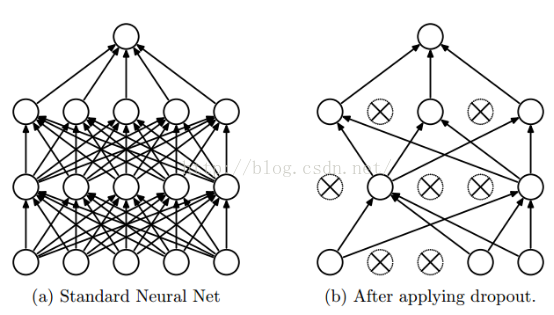
左边是原来的神经网络,右边是采用Dropout后的网络。这个说是这么说,但是具体代码层面是怎么实现的?怎么让某个神经元以一定的概率停止工作?这个我想很多人还不是很了解,代码层面的实现方法,下面就讲解一下其代码层面的实现。以前我们网络的计算公式是:
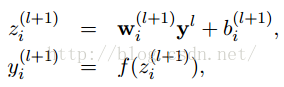
采用dropout后计算公式就变成了:
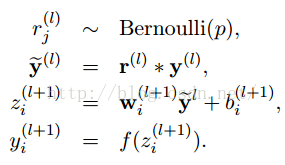
上面公式中Bernoulli函数,是为了以概率p,随机生成一个0、1的向量。
算法实现概述:
1、其实Dropout很容易实现,源码只需要几句话就可以搞定了,让某个神经元以概率p,停止工作,其实就是让它的激活值以概率p变为0。比如我们某一层网络神经元的个数为1000个,其激活值为x1,x2……x1000,我们dropout比率选择0.4,那么这一层神经元经过drop后,x1……x1000神经元其中会有大约400个的值被置为0。
2、经过上面屏蔽掉某些神经元,使其激活值为0以后,我们还需要对向量x1……x1000进行rescale,也就是乘以1/(1-p)。如果你在训练的时候,经过置0后,没有对x1……x1000进行rescale,那么你在测试的时候,就需要对权重进行rescale:
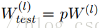
问题来了,上面为什么经过dropout需要进行rescale?查找了相关的文献,都没找到比较合理的解释,后面再结合源码说一下我对这个的见解。
所以在测试阶段:如果你既不想在训练的时候,对x进行放大,也不愿意在测试的时候,对权重进行缩小(乘以概率p)。那么你可以测试n次,这n次都采用了dropout,然后对预测结果取平均值,这样当n趋近于无穷大的时候,就是我们需要的结果了(也就是说你可以采用train阶段一模一样的代码,包含了dropout在里面,然后前向传导很多次,比如1000000次,然后对着1000000个结果取平均值)。
代码解读:
template <typename Dtype>
void DropoutLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
NeuronLayer<Dtype>::LayerSetUp(bottom, top);
threshold_ = this->layer_param_.dropout_param().dropout_ratio();
DCHECK(threshold_ > 0.);
DCHECK(threshold_ < 1.);
scale_ = 1. / (1. - threshold_);
uint_thres_ = static_cast<unsigned int>(UINT_MAX * threshold_);
}
template <typename Dtype>
void DropoutLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
NeuronLayer<Dtype>::Reshape(bottom, top);
// Set up the cache for random number generation
// ReshapeLike does not work because rand_vec_ is of Dtype uint
rand_vec_.Reshape(bottom[0]->shape());
}
template <typename Dtype>
void DropoutLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
unsigned int* mask = rand_vec_.mutable_cpu_data();
const int count = bottom[0]->count();
if (this->phase_ == TRAIN) {
// Create random numbers
caffe_rng_bernoulli(count, 1. - threshold_, mask);
for (int i = 0; i < count; ++i) {
top_data[i] = bottom_data[i] * mask[i] * scale_;
}
} else {
caffe_copy(bottom[0]->count(), bottom_data, top_data);
}
}
template <typename Dtype>
void DropoutLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
if (propagate_down[0]) {
const Dtype* top_diff = top[0]->cpu_diff();
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
if (this->phase_ == TRAIN) {
const unsigned int* mask = rand_vec_.cpu_data();
const int count = bottom[0]->count();
for (int i = 0; i < count; ++i) {
bottom_diff[i] = top_diff[i] * mask[i] * scale_;
}
} else {
caffe_copy(top[0]->count(), top_diff, bottom_diff);
}
}














 659
659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









