







基于朴素贝叶斯分类的原理如下:
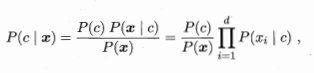
其中c是label中的分类,x是样本。p(c|x)的意思就是,拿到一个样本,这个样本的属性为x1,x2....,在这种情况下,我要求得样本分类为c的概率。
半朴素贝叶斯的分类。
在朴素的分类中,我们假定了各个属性之间的独立,这是为了计算方便,防止过多的属性之间的依赖导致的大量计算。这正是朴素的含义,虽然朴素贝叶斯的分类效果不错,但是属性之间毕竟是有关联的,某个属性依赖于另外的属性,于是就有了半朴素贝叶斯分类器。
为了计算量不至于太大,假定每个属性只依赖另外的一个。这样,更能准确描述真实情况。
公式就变成:
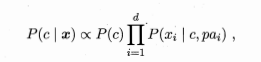
在正式进行计算的时候,将另外一个依赖的属性加进去,计算量不会复杂太多,由于是基于“计数”,所以基本和朴素的计算方式类似。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7833
7833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









