







本论文解决的问题
-
量化数据价值(机器学习模型训练中各个数据点的贡献)
-
避免数据价值受到其所处数据集的影响,使数据点的估值更加稳定、一致
变量假设
假设 D 表示一个在全集 Z 上的数据分布。对于监督学习问题,我们通常认为 Z = X × Y,其中 X 是特征空间的一个子集,Y 是输出,它可以是离散的或连续的。
S 是从 D 中独立同分布抽取的 k 个数据点的集合。
简写:[m]={1, …, m},k ∼ [m] 表示从 [m] 中均匀随机抽取的样本。
U 表示一个取值在 [0, 1] 上的潜在函数(potential function)或性能度量(performance metric)。在本文的背景下,认为 U 表示学习算法(learning algorithm)和评估指标(evaluation metric)。对于任何 S ⊆ Z,U(S) 表示集合 S 的价值。
Data Shapley
ϕ ( z ; U , B ) = 1 m ∑ k = 1 m ( m − 1 k − 1 ) − 1 ∑ S ⊆ B \ { z } ∣ S ∣ = k − 1 ( U ( S ∪ { z } ) − U ( S ) ) \phi(z ; U, B)=\frac{1}{m} \sum_{k=1}^m\binom{m-1}{k-1}^{-1} \sum_{\substack{S \subseteq B \backslash\{z\} \\|S|=k-1}}(U(S \cup\{z\})-U(S)) ϕ(z;U,B)=m1k=1∑m(k−1m−1)−1S⊆B\{z}∣S∣=k−1∑(U(S∪{z})−U(S))
解释如下:
- ϕ ( z ; U , B ) \phi(z ; U, B) ϕ(z;U,B) :表示数据点 z z z 在数据集 B B B 中的 data Shapley 值。
- m m m :数据集 B B B 中数据点的总数。
- U U U :势函数或性能度量,用于评估数据集的价值或模型的性能。
- S S S :数据集 B B B 的任意子集,不包含点 z z z。
- ( m − 1 k − 1 ) \binom{m-1}{k-1} (k−1m−1) : 是从 m − 1 m-1 m−1 个数据点中选择 k − 1 k-1 k−1 个数据点的组合数,作为权重。
- ∑ S ⊆ B \ { z } ∣ S ∣ = k − 1 \sum_{\substack{S \subseteq B \backslash\{z\} \\|S|=k-1}} ∑S⊆B\{z}∣S∣=k−1 :求和符号,表示遍历所有可能的子集 S S S ,这些子集是从 B B B 中除去 z z z 后剩余的数据点中选取 k − 1 k-1 k−1 个数据点形成的。
上式为 Data Shapley 值的定义,只是改变 Data Shapley: Equitable Valuation of Data for Machine Learning 中公式的形式。
ϕ
i
=
C
∑
S
⊆
D
−
{
i
}
V
(
S
∪
{
i
}
)
−
V
(
S
)
(
n
−
1
∣
S
∣
)
\phi_i=C \sum_{S \subseteq D-\{i\}} \frac{V(S \cup\{i\})-V(S)}{\left(\begin{array}{c}n-1 \\ |S|\end{array}\right)}
ϕi=CS⊆D−{i}∑(n−1∣S∣)V(S∪{i})−V(S)
计算差别体现在:D-Shapley 论文中每种 |S| 集合情况下,因为权重相同,所以先求和再乘上权重
C
n
−
1
k
−
1
C_{n-1}^{k-1}
Cn−1k−1,然后求和,最后乘上
1
/
m
1/m
1/m 权重。Data Shapley 论文中,是对于每种 |S| 情况,计算边际贡献后,就乘上对应的两个权重。
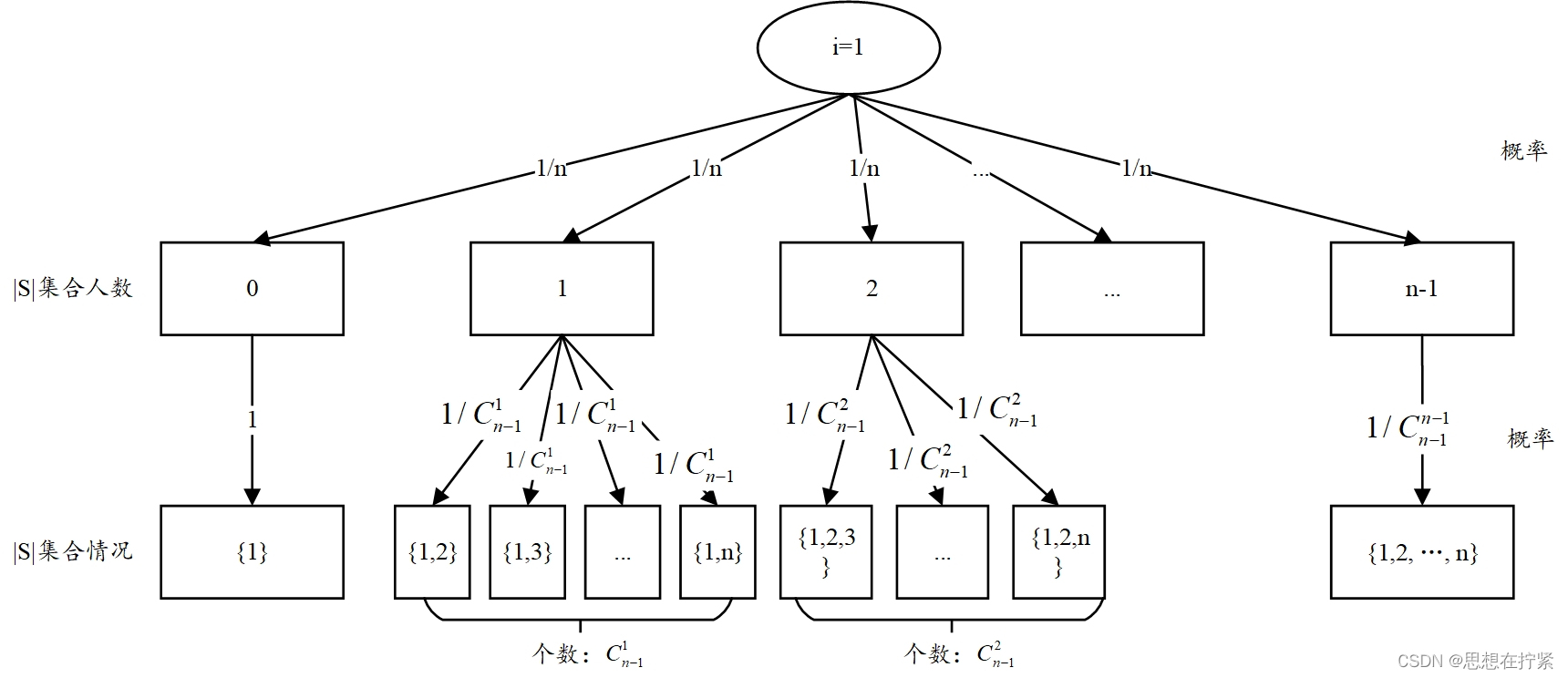
Distributional Shapley Value
Distributional Shapley Value 中数据点 z z z 的数据价值为:
ν ( z ; U , D , m ) ≜ E B ∼ D m − 1 [ ϕ ( z ; U , B ∪ { z } ) ] \nu(z ; U, \mathcal{D}, m) \triangleq \underset{B \sim \mathcal{D}^{m-1}}{\mathbf{E}}[\phi(z ; U, B \cup\{z\})] ν(z;U,D,m)≜B∼Dm−1E[ϕ(z;U,B∪{z})]
上式中的 ϕ ( z ; U , B ∪ { z } ) \phi(z ; U, B \cup\{z\}) ϕ(z;U,B∪{z}) 可视为一个随机变量。其中,数据集 B B B 为从分布 D D D 中随机抽取的,包含 𝑚−1 个数据点的数据集。因为每次抽样会得到不同的数据集 B B B,从而导致 Data Shapley 值的不同结果,但是通过期望就能考虑所有可能的数据集的平均情况,求出数据点的价值。
下面的公式提供了 D-Shapley 值的一个等价表述。
ν
(
z
;
U
,
D
,
m
)
=
E
D
∼
D
m
−
1
[
ϕ
(
z
;
U
,
D
∪
{
z
}
)
]
=
E
D
∼
D
m
−
1
[
1
m
∑
k
=
1
m
1
(
m
−
1
k
−
1
)
∑
S
⊆
D
:
∣
S
∣
=
k
−
1
(
U
(
S
∪
{
z
}
)
−
U
(
S
)
)
]
=
1
m
∑
k
=
1
m
1
(
m
−
1
k
−
1
)
E
D
∼
D
m
−
1
[
∑
S
⊆
D
:
∣
S
∣
=
k
−
1
(
U
(
S
∪
{
z
}
)
−
U
(
S
)
)
]
=
1
m
∑
k
=
1
m
E
S
∼
D
k
−
1
[
U
(
S
∪
{
z
}
)
−
U
(
S
)
]
=
E
k
∼
[
m
]
S
∼
D
k
−
1
[
U
(
S
∪
{
z
}
)
−
U
(
S
)
]
\begin{aligned} & \nu(z ; U, \mathcal{D}, m)=\underset{D \sim \mathcal{D}^{m-1}}{\mathbf{E}}[\phi(z ; U, D \cup\{z\})] \\ & =\underset{D \sim \mathcal{D}^{m-1}}{\mathbf{E}}\left[\frac{1}{m} \sum_{k=1}^m \frac{1}{\binom{m-1}{k-1}} \sum_{\substack{S \subseteq D: \\ |S|=k-1}}(U(S \cup\{z\})-U(S))\right] \\ & =\frac{1}{m} \sum_{k=1}^m \frac{1}{\binom{m-1}{k-1}} \underset{D \sim \mathcal{D}^{m-1}}{\mathbf{E}}\left[\sum_{\substack{S \subseteq D: \\ |S|=k-1}}(U(S \cup\{z\})-U(S))\right] \\ & =\frac{1}{m} \sum_{k=1}^m \underset{S \sim \mathcal{D}^{k-1}}{\mathbf{E}}[U(S \cup\{z\})-U(S)] \\ & =\underset{\substack{k \sim[m] \\ S \sim \mathcal{D}^{k-1}}}{\mathbf{E}}[U(S \cup\{z\})-U(S)] \\ & \end{aligned}
ν(z;U,D,m)=D∼Dm−1E[ϕ(z;U,D∪{z})]=D∼Dm−1E
m1k=1∑m(k−1m−1)1S⊆D:∣S∣=k−1∑(U(S∪{z})−U(S))
=m1k=1∑m(k−1m−1)1D∼Dm−1E
S⊆D:∣S∣=k−1∑(U(S∪{z})−U(S))
=m1k=1∑mS∼Dk−1E[U(S∪{z})−U(S)]=k∼[m]S∼Dk−1E[U(S∪{z})−U(S)]
首先 k k k 是从集合 [ m ] [m] [m] 中进行均匀随机抽样,然后对从分布 D D D 中随机抽取的 k − 1 k-1 k−1 个数据点构成的数据集 S S S,进行期望计算,最后得到的是添加数据点 z z z 到 S S S 后性能度量函数 U U U 变化量的期望。















 270
270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









