






 本文介绍了Caffe中Forward和Backward的概念及其在神经网络中的作用。前向传播用于根据输入计算输出,而反向传播则计算损失的梯度以进行学习。Caffe通过自动微分实现反向传播,从顶层的损失梯度开始,逐层计算各层的梯度。Net和Layer类提供了相应的前向和后向传播函数,使得Caffe能够高效地进行模型训练。
本文介绍了Caffe中Forward和Backward的概念及其在神经网络中的作用。前向传播用于根据输入计算输出,而反向传播则计算损失的梯度以进行学习。Caffe通过自动微分实现反向传播,从顶层的损失梯度开始,逐层计算各层的梯度。Net和Layer类提供了相应的前向和后向传播函数,使得Caffe能够高效地进行模型训练。
Forward和Backward是Net中的计算本质。

让我们考虑最简单的逻辑回归分类器。
前向传播的部分是根据input来计算output,从而进行inference。在前向中,Caffe通过模型中每个layer的计算组合来计算“function”的值。这个传播从bottom到top进行。
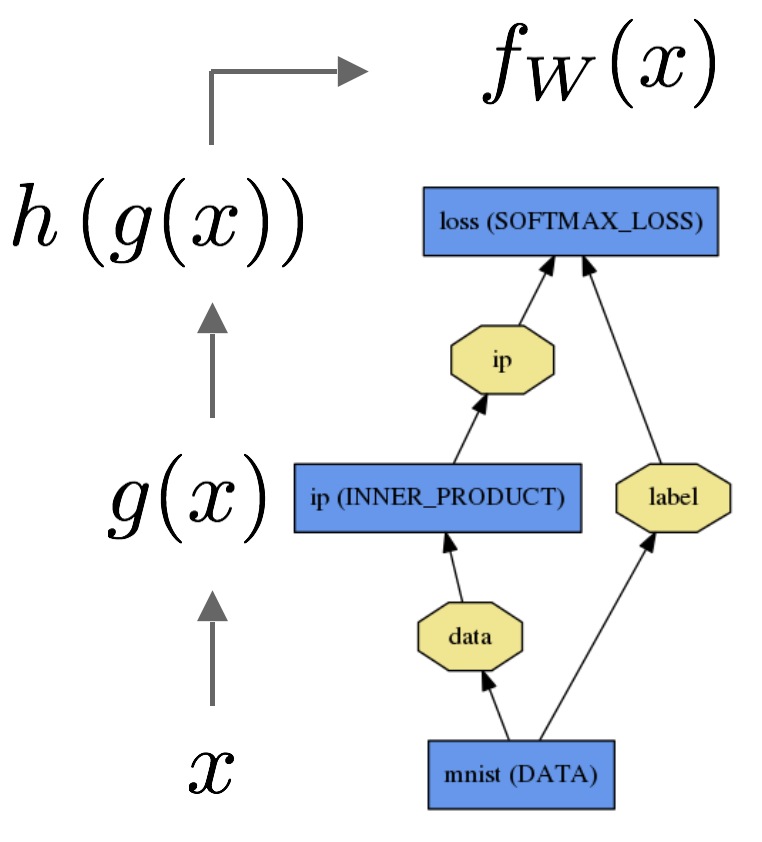
数据x通过inner product layer来得到
g(x)
g
(
x
)
,在通过一个softmax layer得到
h(g(x))
h
(
g
(
x
)
)
,则我们可以得到softmax loss为
fW(x)
f
W
(
x
)
.
反向传播是计算loss的梯度用于learning。在反向传播中,Caffe通过自动微分来计算每个layer的梯度,并用其反向组合来表示整个模型的梯度。反向传播是从top到bottom的过程。

Backward从loss的梯度
∂fW∂h
∂
f
W
∂
h
开始,然后通过链式法则,逐层计算剩余layer的梯度。而layers的参数,如inner product层,其在backward中梯度的含义就是参数的
∂fW∂WiP
∂
f
W
∂
W
i
P
。
这些计算都紧跟在定义model之后:Caffe已经完成了前向和后向的实现。
- Net::Forward()和Net::Backward()函数执行相应的传递,而Layer::Forward()和Layer::Backward()计算每个Layer的具体传递。
- 每个Layer有forward_{cpu, gpu}()和backward_{cpu, gpu}()方法分别计算不同mode的传递。但是由于constraint或convenience,layer也可仅实现其中CPU和GPU一种方法。
求解器首先通过forward来得到output和loss,再通过backward来得到模型的gradient,然后通过梯度来更新weight来使得loss最小化。Solver、Net和Layer的分工,使得Caffe模块化并让开发者进行开发。
有关Caffe的forward和backward的具体细节,由之后的layer catalogue进行描述。















 1523
1523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









