






一.前言
最近在学习spark的过程中发现很多教材和文章都是用的比较老版本的spark,于是博主就花了一些时间下载了相对新一点的版本的spark,感觉跟旧版的spark的集群搭建还是存在差异,下面就让我们一起动手来将搭建spark集群吧
1)spark版本
博主使用的spark是spark-3.3.3-bin-hadoop3(适用于hadoop3.3及以上的预搭建)
需要的可以在官网下载:下载 |Apache Spark(阿帕奇斯帕克酒店)
2)hadoop版本
博主使用的hadoop是hadoop3.3.1版本 的hadoop
3)jdk版本
博主使用的jdk版本是jdk1.8.0-144(可能有点低,自己根据需要下载)
二.Spark搭建
1.hadoop搭建
(1)所需软件
VMware 12、Centos 7 64bit、hadoop 3.3.1、jdk 1.8
(2)linux配置
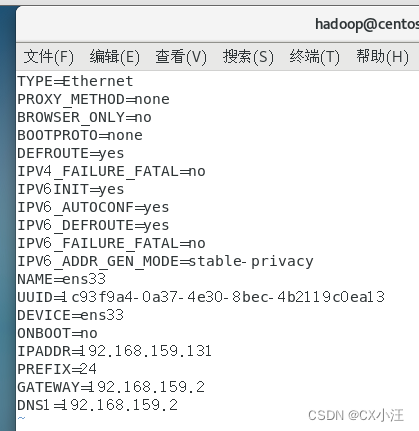
1.配置三个节点的地址

2.配置节点的主机名
vim /etc/hostname
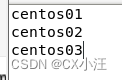
将主机名分别命名为centos01,centos02,centos03
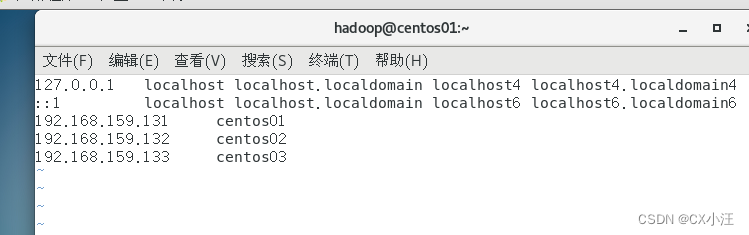
3.配置内网域名的映射
vim /etc/hosts
 4.配置主机之间的ssh免密登录
4.配置主机之间的ssh免密登录
ssh-keygen //从主机上生成key
ssh-copy-id centos02 //复制到centos02中
ssh-copy-id centos03 //复制到centos03中
(2)jdk的安装和配置
在主节点centos01上下载并解压好jdk的安装包
vim /etc/profile //配置环境变量
在profile下面加入
![]()
注意:JAVA—HOME配置的是自己jdk的安装路径
将配置好的profile文件传到其他节点
scp -r /opt/modules/jdk1.8.0_144 centos02: /opt/modules/jdk1.8.0_144
scp -r /opt/modules/jdk1.8.0_144 centos03: /opt/modules/jdk1.8.0_144
(3)安装hadoop
将下载好的hadoop解压后,我们还要将hadoop配置到用户的环境变量中
vi ~/.bash_profile //编辑环境变量
在文件末尾追加下面内容:
![]()
保存退出后,执行命令:
source ~/.bash_profile
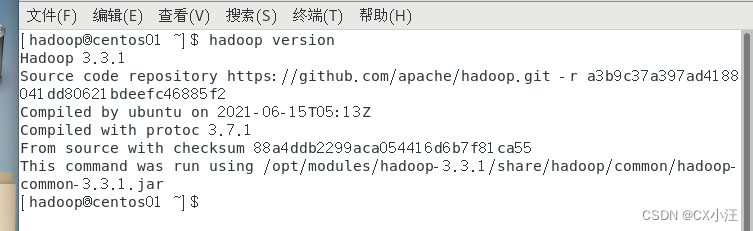
然后输入命令:
hadoop version
查看是否配置成功
(4) 配置hadoop集群
1.修改yarn-env.sh文件
进入hadoop安装目录下的etc/hadoop目录下编辑yarn-env.sh文件将默认的JAVA—HOME参数改为本地安装的jdk

接着修改mapred-env.sh和hadoop-env.sh中的jdk环境变量(直接export即可)
2.修改文件core-site.xml(如下图)

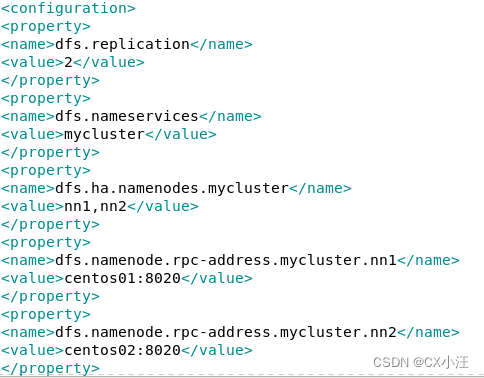
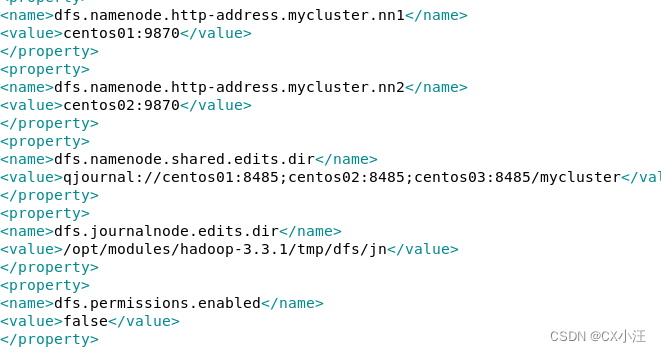
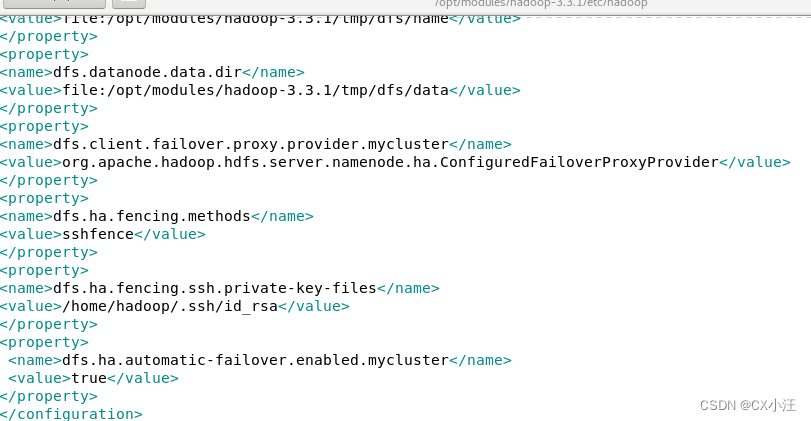
3.修改文件hdfs-site.xml文件(如下图)
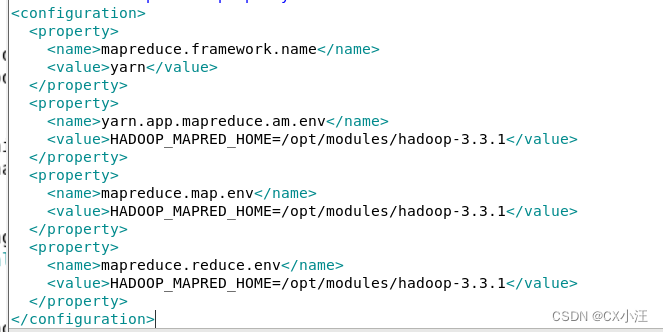
4.修改mapred-site.xml(如下图)
5.修改yarn-site.xml(如下图)
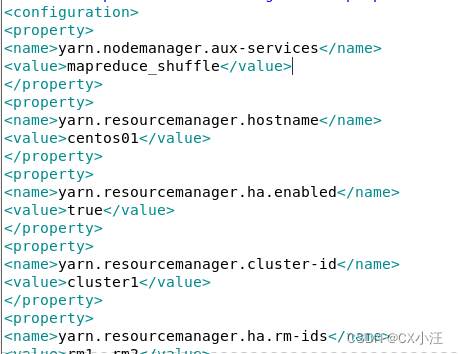
6.修改workers(slaves)文件
7.将修改好的文件分别分法给其他服务器centos02和centos03上(注:完成后还需要分别执行一次source ~/.bash_profile命令)
8.格式化文件系统
hadoop namenode -format
等待出现successfully formatted的内容后表示格式化成功。
9.启动和关闭Hadoop集群
start-dfs.sh //启动所有HDFS服务进程
start-yarn.sh //启动所有YARN服务进程
start-all.sh //一键启动
stop-all.sh //一键关闭
启动后我们输入jps命令来查看服务启动情况,服务器上应该有NameNode、DataNode、ResourceManager和NodeManager四个服务器进程:
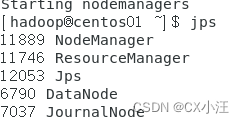
其他两个的结果分别是:

 MJ
MJ
2.spark环境的搭建
(1)确定好spark的安装路径并解压
博主将解压好的spark放入了/opt/modules如下图:

(2)配置conf
我们进入spark中的conf目录中可以找到一个spark-env.sh.template文件如下图:

我们先输入命令复制并将文件重命名为spark-env.sh:
cp spark-env.sh.template spark-env.sh
然后我们打开文件并配置文件
(在其底部加入下面内容)

注意:此时我们只配置好了对应的Hadoop的路径和jdk的路径还有spark的主机的地址,我们还需要配置客机的位置
我们输入命令复制并将文件重命名为workers
cp workers.template workers
接着将客机的地址加入(删掉localhost)如下图:
我这边就暂时用centos02和centos03作为客机使用。
注意:应为版本不同,有的版本的客机是放在slave.template中的所以跟此处差不多的操作,我们将文件复制并重命名为slave,最后在slave中添加也是一样的。
3.启动spark集群
我们来到spark的安装路径下的sbin文件中输入命令
start-all.sh
启动结束后我们输入jps来查看启动的结果如下图:
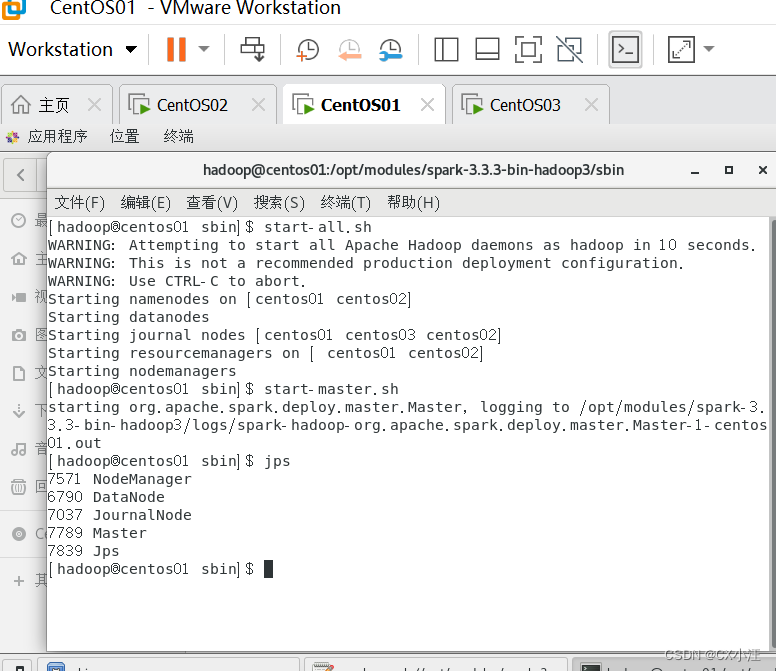
注意:正常情况下输入start-all.sh命令是可以直接启动master和workers的,如果没有启动可以试一下分别用命令start-master.sh和start-workers.sh命令来启动服务
检查节点,如果没有少,那么spark集群就搭建成功
三.最后
都看到这里了,觉得博主写的还可以的,点个赞再走吧,感谢支持!!!
















 4516
4516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











