






关于不同处理器的函数调用规则
接前面一篇变长参数调用的记录,这次从原理上进行了进一步研究。
不同调用规则对对于编译出来的汇编影响很大的,这里之前的理解比较粗浅,尤其是一般教科书或者网上能看到的内容都比较老,这里记录一下。
这里要重点提醒一下,之前一直以为函数调用是编译器制定的规则,不同编译器的实现不同,但是现在发现这个理解是错的,其实是处理器架构规定的,所以这里和编译器有关系但是不大,编译器也是为了符合处理器规定来做的,只不过编译器有一定的自由度,但自由度不大。
首先是这个网站,里面有具体的说明。
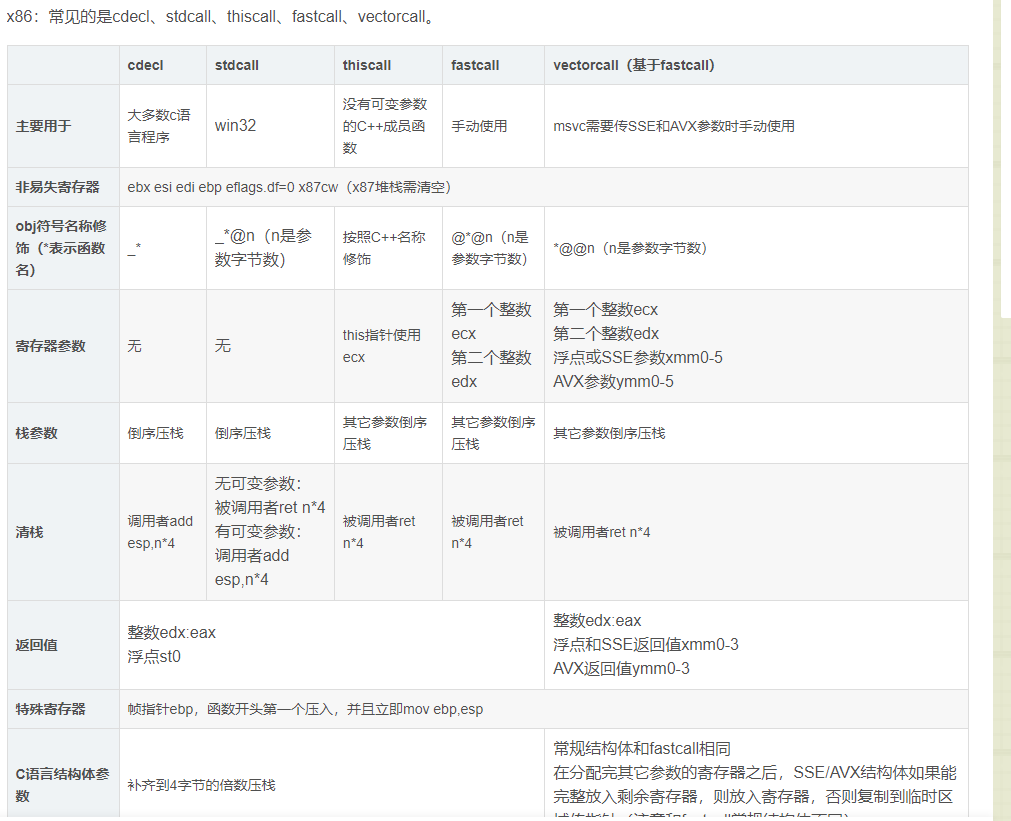
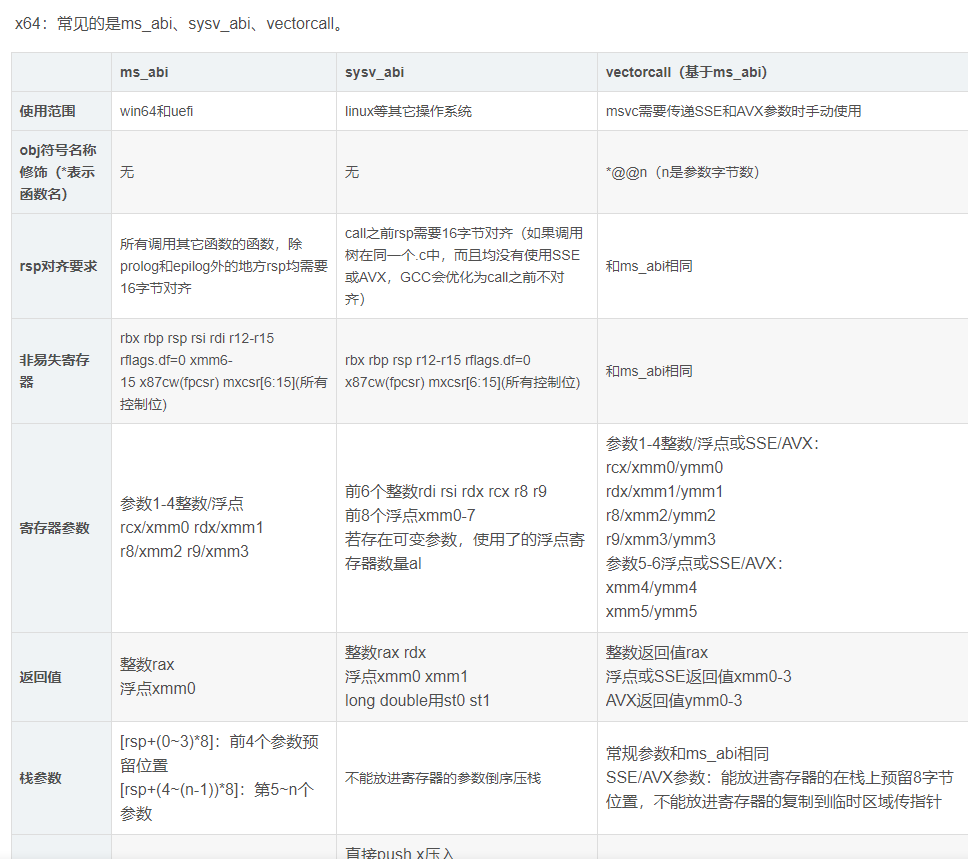

还有很多,这里只是简单的贴两张图以防网站丢失。
然后是这篇文章,里面说明了asmlinkage宏的定义,其实这个宏在x86平台上才有效,arm平台上没有意义。
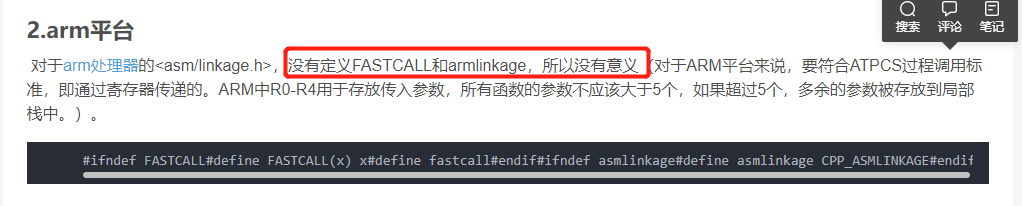
这也和我这两天的实验结果相符,我尝试给函数增加cdecl或者fastcall之类的属性,但是编译器一直会报warning。
warning: ‘cdecl’ attribute directive ignored [-Wattributes]
开始还不理解,现在看来其实是因为编译器选项是arm64,里面没有cdecl这个属性,所以才会报这个warning。
另外关于上面提到的ATPCS规则,这个网页简单的记录了一下,可以作为扫盲。
那么在这个情况下,对可变参数的获取要借助编译器自带的一些内联函数,比如:
__builtin_va_list
__builtin_va_start
__builtin_va_end
__builtin_va_copy
__builtin_next_arg
__builtin_saveregs
这里再贴一个别人实验的图,和我这边自己观察到的现象也完全一样,再aarch64中有名参数和匿名参数在栈中的位置并不是连续的,这一点要格外注意,这次的错误就是由于这里导致的。
这是别人的:
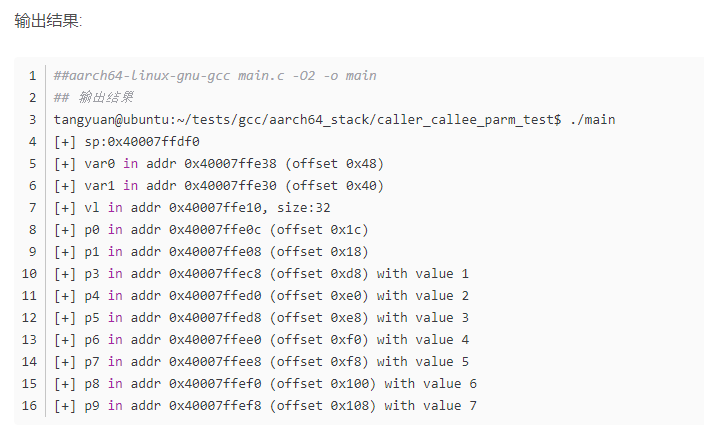
这是我的
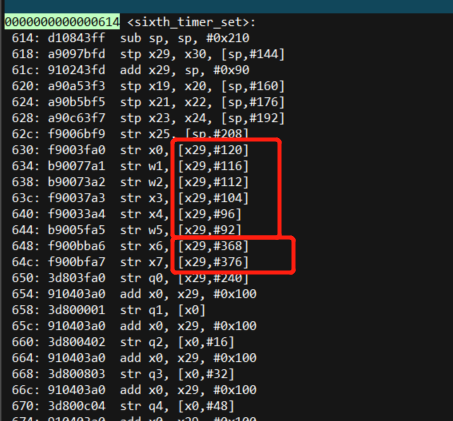
所以其实栈空间的分布就是这样的:
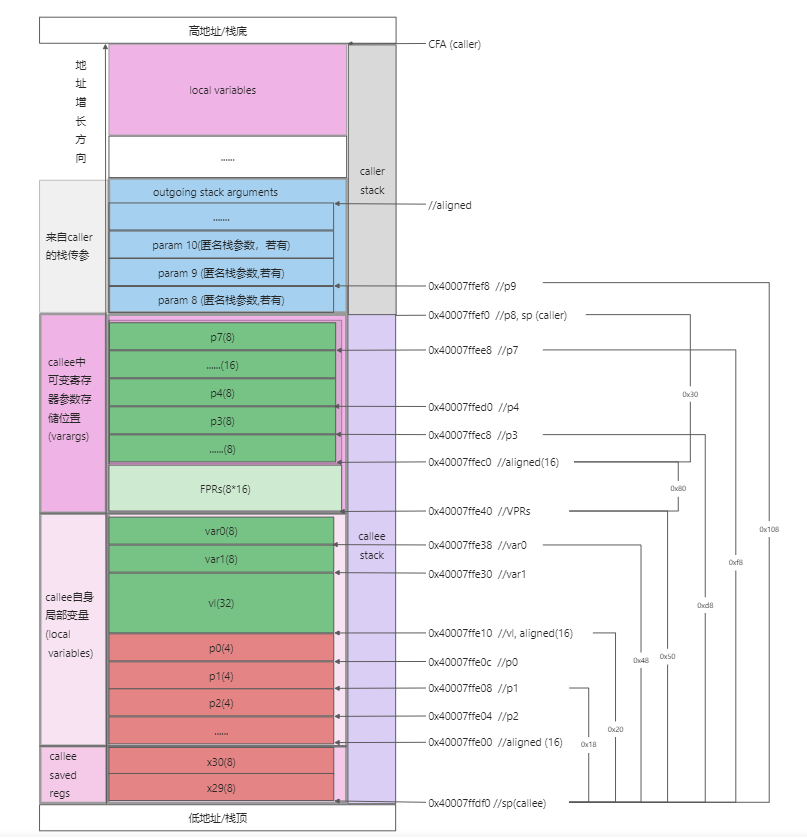
好了,这个问题到这里基本上就结了。















 2129
2129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









