







 本文总结了深度学习的基础模型发展历程,包括AlexNet、VGG、ResNet、Inception系列、SqueezeNet、MobileNet和DenseNet等,探讨了网络结构优化如残差连接、归一化、分组卷积等技术,以及模型压缩和训练策略的演进。
本文总结了深度学习的基础模型发展历程,包括AlexNet、VGG、ResNet、Inception系列、SqueezeNet、MobileNet和DenseNet等,探讨了网络结构优化如残差连接、归一化、分组卷积等技术,以及模型压缩和训练策略的演进。
目前来看,很多对 NN 的贡献(特别是核心的贡献),都在于NN的梯度流上,比如
- sigmoid会饱和,造成梯度消失。于是有了ReLU。
- ReLU负半轴是死区,造成梯度变0。于是有了LeakyReLU,PReLU。
- 强调梯度和权值分布的稳定性,由此有了ELU,以及较新的SELU。
- 太深了,梯度传不下去,于是有了highway。
- 干脆连highway的参数都不要,直接变残差,于是有了ResNet。
- 强行稳定参数的均值和方差,于是有了BatchNorm。
- 在梯度流中增加噪声,于是有了 Dropout。
- RNN梯度不稳定,于是加几个通路和门控,于是有了LSTM。
- LSTM简化一下,有了GRU。
- GAN的JS散度有问题,会导致梯度消失或无效,于是有了WGAN。
- WGAN对梯度的clip有问题,于是有了WGAN-GP。
说到底,相对于8,90年代(已经有了CNN,LSTM,以及反向传播算法),没有特别本质的改变。注:上述内容来在《浅析Hinton最近提出的Capsule计划》(https://zhuanlan.zhihu.com/p/29435406)

网络结构
-
- 全卷积网络结构
- ReLU Nonlinearity:饱和性问题,速度快
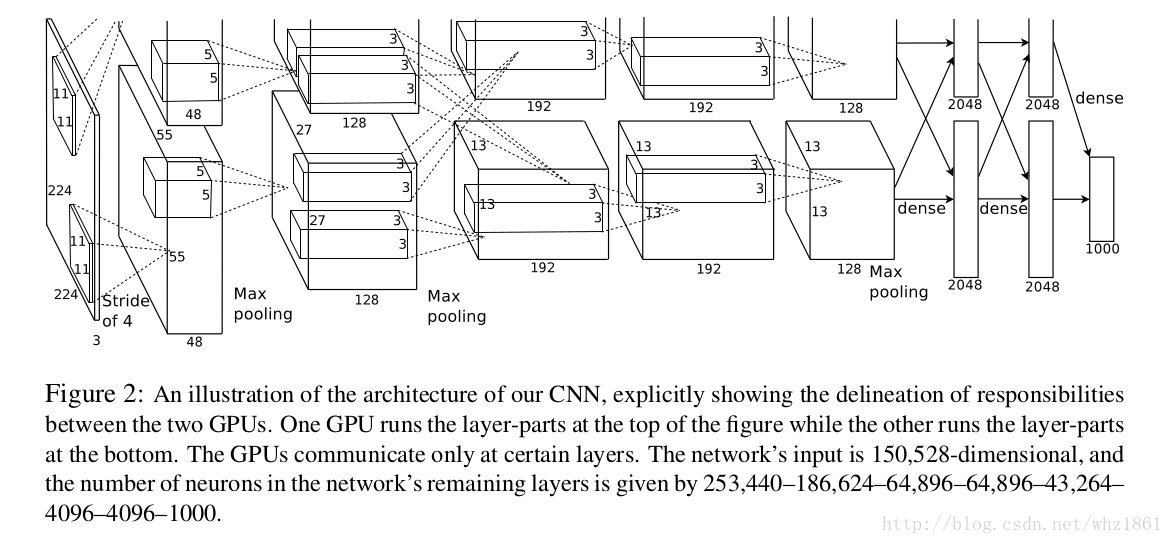
- 多GPU训练
- Local Response Normalization
- Network in Network
- mlpconv:有效提升了局部特征提取能力【结构图】
- mlpconv:有效提升了局部特征提取能力【结构图】

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









